基于WLAN大数据和Hive数据仓库的高校人流溯源系统设计与实现
2021-12-09徐悦伟夏凌云
徐悦伟, 夏凌云
(中国石油大学(华东) 1.党委办公室、校长办公室;2.信息化建设处, 山东 青岛 266580)
0 引言
高校作为典型的人群活动和聚集地,人员活动和轨迹具备以下特点。(1)活动区域较为封闭,广大师生的工作生活区域大多都集中在校园内部。(2)人员交流频繁且随机,除了固定的宿舍成员接触外,学生和老师的上课、自习、餐饮、锻炼等时段均可能产生大量的随机人员交流。因此在出现公共卫生事件时,能通过某些方法和机制对人群接触情况和流动情况进行快速追溯和分析对于疾病防控显得尤为重要。
但是当前在高校内部进行人员的快速追溯和分析,还存在着一些问题。尤其是高校内部人员在封闭空间的活动与常见链状活动轨迹有很大的不同,呈现的是宿舍、教学楼等多场所进行活动的网状轨迹。网状轨迹带来的主要挑战有两个:一是难以采样。教学楼和餐厅之类的场所,聚集性和流动性都很高,难以保证手工打卡数据完备性的同时,也不利于正常教学生活的进行;二是分析难。人员在校内的网状活动轨迹的记录将会不停累积海量的位置数据,数据的存储和关联分析的难度非常大。如图1所示。

链状活动轨迹
为此,本文提出一种基于WLAN数据和Hive数据仓库的高校公共卫生事件人流溯源系统,通过校园认证系统和无线网络管理系统实现位置的初步采集[1],并通过Hadoop框架中的Flume、HDFS、MapReduce、Hive等组件,利用分布式计算技术实现对用户海量位置数据的快速同步、存储、建仓和分析。
2 相关技术及系统介绍
2.1 校园无线网定位技术
在前期工作中,我们实现了如何利用校园无线网络中的无线控制器和无线接入点定期捕获用户无线设备MAC地址和位置的对应关系,并对接认证系统找出MAC地址和用户身份的对应关系,形成“身份-MAC-位置”的关联信息,以日志文件的形式保存在无线定位服务系统中[1]。
2.2 Hadoop大数据框架
Hadoop是一个Apache基金会主持的分布式计算基础架构,主要基于HDFS分布式文件系统和MapReduce分布式计算模型,并与各种传输、查询、计算、分析等组件组成的1个海量数据处理的技术框架。整个Hadoop框架具备高效、可靠、成本低等特点,已成为当前大数据技术的首选实现框架[2]。
本系统中主要使用了HDFS、MapReduce、Flume、Hive组件。HDFS、MapReduce作为最常见的基础组件在其他文献已有详细的论述,在此不再赘述。
2.3 CDH发行版
Hadoop作为一个开源生态框架,存在着生态组件分支较多,版本不一的问题。因此对于非大数据底层技术方向的研究人员来说,使用成熟的、便利的第三方发行版本可以使自身更聚焦于业务。本项目选择的CDH发行版[3]是由Cloudera公司发行的较为常用的免费开源版本,能满足大多数情况下的大数据存储和分析需求。
2.4 Hive数据仓库工具
Hive是Hadoop框架中的一个数据仓库工具[4],主要功能如下。
(1) 将存储在HDFS中的半结构化的数据文件映射为数据表,数据分析人员可以直接使用类SQL语句来对HDFS内数据文件进行读取和分析。
(2) 将数据分析人员读取数据时采用SQL语句转化为MapReduce任务来执行,使查询数据过程可以充分和便利地利用Hadoop大数据并行处理优势。
因此Hive的优势是可以很好地利用HDFS和MapReduce的分布式大数据处理能力的同时,沿用关系型数据库的分析方式和经验进行高效的在线数据分析。Hive对数据动态有写入支持不佳、不支持流式数据实时处理的劣势,对只需进行日志数据进行建仓和不定期查找的本项目来说不构成较大影响。
2.5 Flume日志收集工具
Flume是CDH发行版中常用的日志收集工具[3],可将各业务系统的文件通过采集、聚合、传输、写入的流程写入到HDFS文件系统内,供其他Hadoop组件读取和调用。
3 系统实现
3.1 系统总体框架设计
系统的总体框架如图2所示。
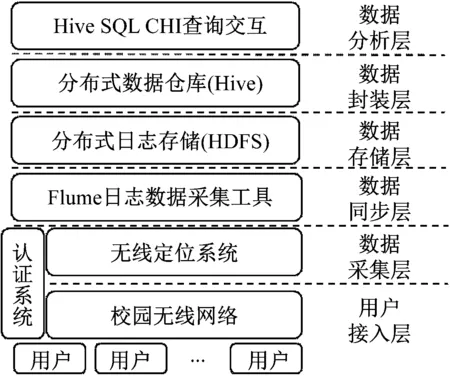
图2 系统总体框架设计
(1) 用户接入层:所有用户在该层接入校园无线网络,并不断产生并更新接入设备(MAC)和位置(AP)的对应关系。
(2) 数据采集层:该层通过定期采集用户接入层的MAC-位置对应关系数据,对接校园网认证系统中的“MAC-学工号”关系,将数据关联为“学工号-位置”的数据记录,实质就是用户位置信息表。每条数据加上采样时间后,以文本文件的形式存放于定位系统的日志文件中。
(3) 数据同步层:该层通过Flume将数据采集层作为数据源,HDFS作为保存节点,通过定时任务将定位日志数据定期汇总采集到HDFS中进行存储。
(4) 数据存储层:本层利用HDFS文件系统对不停同步过来的位置日志数据进行分布式存储,同时HDFS也是后期进行数据分析的基础文件系统。
(5) 数据封装层:数据封装层使用数仓工具Hive,将所有日志文件封装为支持类SQL查询的数据表,以便后期查询[5]。
(6) 数据分析层:分析人员可以按传统模式设计查询的SQL语句,并通过命令行方式输入查询语句,Hive会将SQL语句自动解析为MapReduce语句去读取封装好的数据仓库数据,并返回最终期望的查询结果。
3.2 系统部署与配置
系统中的用户接入层和数据采集层已在前期完成了部署和使用[1],并将位置信息存放在固定文件夹,文件采用“,”符号分隔不同数据项,用“ ”符号作为数据条目间的划分。本系统的部署和配置还有以下关键步骤。
3.2.1 CDH的安装
CDH提供了一个官方的自动化部署和运维工具Cloudera Manager,具备完善的CDH集群的自动安装、集中管理基于集群的监控和告警功能。通过Cloudera Manager安装CDH主要分为3大步骤。
(1) 服务器和操作系统准备:主要内容包含准备3台安装好的Linux系统服务器,并配置好服务器时间服务、Hosts域名解析、相互的免密码登录、防火墙和SELinux等基础配置。
(2) 安装Cloudera Manager:在服务器上安装MySQL数据库、Oracle JDK1.8、Httpd服务,以便安装者通过Web浏览器图形化操作Cloudera Manager。通过Yum安装Cloudera Manager,并在各台服务器配置启动项配置,启动Cloudera Manager服务。
(3) 安装CDH:通过Cloudera Manager的Web管理端在图形化界面上按提示输入安装参数。由于我们本项目需求的组件比较少,因此仅需选择核心Hadoop服务组合即可,包含Hadoop框架最常用和必须的HDFS、YARN(内含MapReduce2)、Zookeeper(分布式组件协调)、Oozie(Hadoop工作流调度引擎)、HUE(Hadoop图形化UI)以及Hive组件进行自动安装直到结束。
3.2.2 Flume安装和配置
安装好集群后,需要分别在Hadoop集群和无线定位系统服务器上安装FlumeAgent来实现数据同步。在CDHHadoop集群的“集群”-“操作”下选择“添加服务”,按提示选择在主节点安装Flume组件。在无线定位系统服务器端可直接使用Flume安装包来安装FlumeAgent。
每个FlumeAgent都分为3个部分:Source、Channel、Sink。Source代表数据流的源头;Channel代表数据传输的缓存和管道;Sink代表数据传输的终点。可以通过将一个Agent的Sink和另外一个Agent的Source进行来实现多个Agent之间的数据流串联同步。我们在无线定位服务器端和Hadoop集群端分别安装FlumeAgent,并将无线定位服务器的Sink和Hadoop集群的Source通过Avro的网络RPC方式进行串联,实现普通Log数据文件到Hadoop分布式文件系统的传输。实现方案和配置[6]如图3所示。
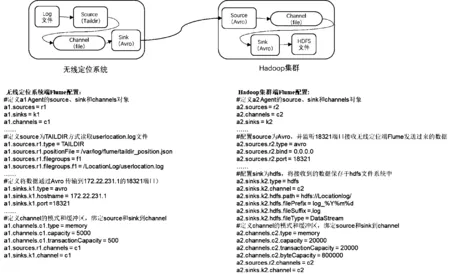
图3 通过Flume实现数据同步
3.2.3 Hive建仓
完成上述配置后,在定位服务器和Hadoop集群上启动Flume进程,即可开启数据同步。随后的Hive建仓和查询需要在HiveShell内进行,过程如下。
(1) 创建数据仓库search
hive>create database search;
(2) 创建外部数据表lbs,包含3个数据项:user、ap、time,同时指定数据项之间分隔符为逗号,数据行之间分隔符为回车符。
hive>create EXTERNAL table lbs(user string,apstring,time string,)
>ROW FORMAT DELIMITED
>FIELDS TERMINATED BY ','
>LINES TERMINATED BY ' '
>stored as textfile;
(3) 将hdfs://Locationlog/下的所有Log文件与Lbs表进行关联
hive>LOAD DATA INPATH 'hdfs://Locationlog/' INTO TABLE lbs;
至此,使用SQL语句“select * from lbs”,即可发现日志数据已加载至Hive中Search数据库的Lbs数据表中。
3.2.4 分布式查询
我们可以通过SQL语句来指定各种查询条件和关联条件,Hive将会把SQL语句自动转换为MapReduce语句,在海量的日志数据中进行分布式查找并返回结果。最终实现诸如“查找某个时间阶段内处于同一个AP下的所有用户”,或者“追溯某些用户、空间或时间的关联性”等系统设计目标。
3.3 应用效果
根据以上方式搭建的Hive数仓,结合前期的“AC-AP-位置”管理模块和Echarts图表模块,在实际中得到了很好的应用。在Hive数仓基础上搭建的WLAN终端轨迹记录和分析系统,实现了根据采样时间点显示人员聚集热力图,以及按人快速搜索查询同AP下汇集人员功能,如图4所示。
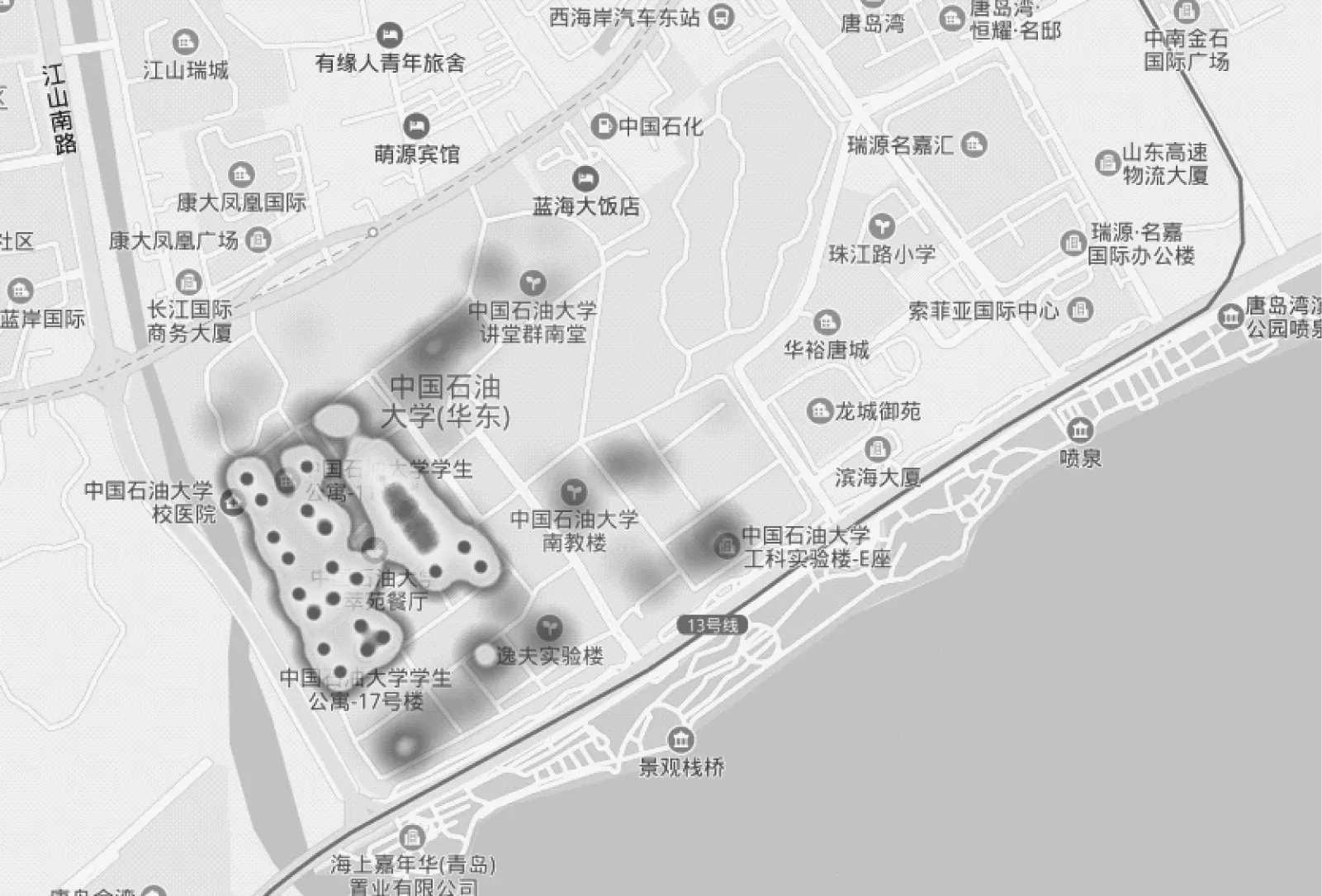
图4 人员聚集热力图
4 总结
本方案提出了一个通用可行的系统设计和实现方法,将海量的位置数据导入Hadoop并建立数据仓库,实现分布式、并行的数据查找和分析,使高校内部人员流动的数据化溯源的快速实现成为可能。其中大数据框架搭建和数据同步与建仓的方法,也可以推广到其他非实时流式数据处理的海量数据挖掘和分析的场景。在下一步工作中,我们还需优化Hive中数据的分区加载和使用,以提高数据查找和分析效率,同时优化和丰富人流追溯的SQL语句,来实现更完善的和更个性化的查找需求。
