维度学习探路者算法
2021-11-26孙哲中
孙哲中,刘 昊,陈 洋
(辽宁科技大学 理学院,辽宁 鞍山114051)
元启发式算法分为三类:基于生物群智能[1]、基于物理现象[2]和基于进化的元启发式算法[3]。探路者算法(Pathfinder algorithm,PFA)是基于生物群智能的元启发式算法,由Yapici等[4]于2019年提出。该算法具有简单、易于实现且鲁棒性强的优点,但其收敛速度慢、易陷入局部最优,因此需不断对其进行改进。文献[5]将差分进化算法(Differential evolution,DE)的变异算子集成到PFA中提高收敛精度。文献[6]提出一种基于教学策略的PFA算法,用于求解函数和工程优化问题。文献[7]使用PFA优化分数阶倾斜积分微分控制器,用于多源电力系统的自动发电控制。文献[8]将PFA用于求解太阳能光伏系统在多边之间的优化配置和集成问题。文献[9]使用改进PFA优化混合埃尔曼神经网络(Hybrid elman neural network,ENN),并用于固体氧化物燃料电池模型的评估。
PFA种群在位置更新时不可避免地会产生越界个体,需对这类个体进行越界处理,使超过搜索边界的个体位置重新回到搜索空间。常见的越界处理方法有重新初始化法和边界限定法。重新初始化是将越界个体在搜索空间中重新进行随机初始化。这种处理方法在迭代过程中通常比较粗糙,且无法保留越界个体已经搜索到的历史维度信息。边界限定法则是寻找越界个体中的越界维度信息,将越界维度限制在离其最近的边界上。这种处理方法尽管能够保留越界个体的维度信息,但对越界维度利用率差。
为解决PFA在简单问题中收敛速度慢、收敛精度差以及对维度信息利用不充分的问题,本文提出了一种改进PFA,称为维度学习探路者算法(Dimension learning pathfinder algorithm,DLPFA)。维度学习由限制维度策略和加强维度策略组成。限制维度是针对越界个体的改进策略,将发生越界的维度信息替换为当前领导者个体对应的维度信息。这种策略利用精英个体的领导能力,能够使越界个体回归搜索空间的同时向精英个体方向移动,从而提高算法的收敛速度。加强维度是针对位置更新不成功的个体提出的改进策略,首先,将领导者维度信息的极值作为搜索边界,并在其中随机初始化一个示范个体,随机初始化有利于保持种群多样性,而利用领导者的维度信息作为搜索边界有利于当前个体与领导者的信息交流;其次,在种群中随机选择一个个体作为信息个体,来加强种群之间的信息交流和共享;最后,当前个体通过向示范个体和信息个体双重学习来更新位置。因此,维度学习策略能够有效地利用个体的维度信息,帮助其跳出局部最优的同时提升收敛速度。
1 探路者算法
群居动物通常有鲜明的等级区分制度,PFA模拟群居动物分级方式,将种群分为领导者和跟随者两部分。在规模为N的种群中,选取最优秀的个体为领导者,领导者根据自己以往经验寻找猎物,进行位置更新

种群中除领导者外的其余个体为追随者,追随者位置更新策略

PFA算法流程如图1所示。
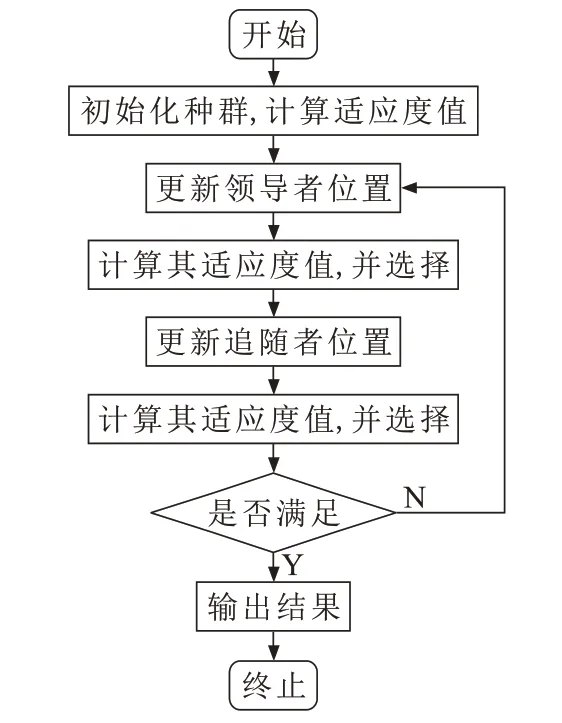
图1 PFA算法流程图Fig.1 Flow chart of PFA algorithm
2 维度学习探路者算法
2.1 限制维度学习策略
种群在位置更新的过程中难免会出现越界个体。为了利用领导者对算法搜索方向的引导,合理利用其维度信息来处理越界个体有利于提升算法的收敛速度。限制维度学习策略旨在让领导者引导越界个体重新回到搜索空间,同时实现越界个体合理共享领导者的维度信息,具体策略为

2.2 加强维度学习策略
种群中的个体在迭代时,由于学习策略的限制,常存在位置不更新的情况。因此,提出一种并行的加强维度学习策略,提高迭代中位置更新的成功率。首先,将适应值改变与否作为判断个体是否发生位置更新的依据,若当前个体的适应值未改变,则执行加强维度学习,具体策略为

随机维度变化的数学模型描述为

式中:randi是从集合{1,Dim}中随机抽取的一个元素,当randi=Dim时,vct是[0,1]区间上服从均匀分布的维数为Dim的随机向量;否则,rand是[0,1]区间上服从均匀分布的随机数。
2.3 DLPFA算法的实现步骤
步骤1初始化参数:种群的规模N、函数评价最大次数FEmax、最大迭代次数Tmax、合作系数αmax=2和αmin=1、吸引系数βmax=2和βmin=1。
步骤2初始化种群并计算对应的适应值;根据适应值排序并确定领导者和跟随者。
步骤3按式(1)更新领导者的位置信息,并用式(7)处理越界个体。
步骤4按式(3)更新跟随者的位置信息,并用式(7)处理越界个体。
步骤5计算所有个体的适应值,若个体位置更新不成功,使用式(8)更新该个体并计算其适应值。
步骤6根据适应值排序并确定领导者和跟随者。
步骤7若不满足终止条件,返回步骤3;否则终止算法,输出最优解。
3 实验结果与统计分析
3.1 测试函数
为了验证改进算法DLPFA的有效性,将其与经典的粒子群优化算法(Particle swarm optimization,PSO)[10]、涡流搜索算法(Vortex search,VS)[11]、树生长算法(Tree growth algorithm,TGA)[12]及PFA进行对比,选择5个经典的Benchmark测试函数,对其进行性能测试。
(1)Step函数
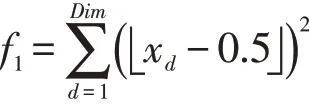
此函数又称阶梯函数,由一系列水平线段组成,在定义域内自变量趋近于无穷时,会在给定的间隔上出现不同的阶跃现象,并且在每个阶跃间会产生大量局部极值,因此,寻优难度大。该函数是不连续的阶梯函数,可以检验算法的收敛精度。
(2)Rastrigin函数

此函数是一个多峰函数,在(x1,x2,…,xDim)=(0,0,…,0)达到全局极小点,在{xd∈(-5,12,5,12),范围内大约有10Dim个局部极小点[13]。该函数局部最优点的数量随维数指数递增,可以检验算法的全局搜索能力。
(3)Griewank函数

此函数有多个局部极小点,局部极小点的个数与函数问题中的维数有关。xd=±kπd(d=1,2,…,Dim)是该函数的极小值。该函数可以检测算法跳出局部最优的能力。
(4)Ackely函数
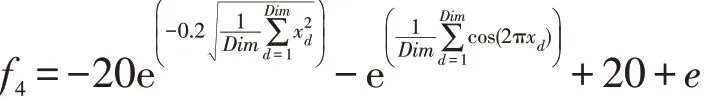
此函数是指数函数叠加适度放大的余弦函数而得到的连续型函数。该函数在一个平坦的区域由余弦波调制成大量孔或峰,易使算法陷入局部最优。当目标函数的维度增加时,该函数局部最优解呈指数递增,最优解的搜索难度大。因此,常被用于检测算法的全局收敛速度和搜索精度。
(5)Rosebrock函数
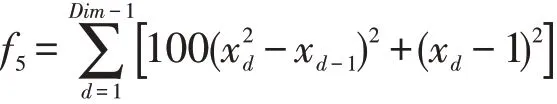
此函数的每个等高线呈抛物线形,全局最小值在抛物线形的山谷中,是一个非凸函数,要找到全局最小值相当困难。该函数为优化算法提供的信息比较有限,算法很难辨别搜索方向,最优解的查找十分困难。因此,该函数常用于检测算法的全局探索能力和局部开采能力。基准测试函数的相关信息详见表1。

表1 基准测试函数信息Tab.1 Parameters of benchmark functions
3.2 实验结果
为了方便对比,五种算法均取最大函数评价次数FEmax=30 000,最大迭代次数Tmax=600,种群规模N=50,取最大函数评价次数和最大迭代次数为终止条件。同时,为了减少随机数对算法性能的影响,每种算法在每个测试函数上均独立运行30次,取30次的实验结果进行统计分析。实验结果详见表2。实验将均值、标准差和最优值作为评价指标。均值和最优值能评价算法的收敛精度,标准差反映算法的鲁棒性。取均值为排名依据,均值越小,排名越高,均值相等时,排名相同。

表2 五种算法的比较结果Tab.2 Comparison between five algorithms
对于f1,DLPFA、PSO以及PFA找到了最优值0,但DLPFA标准差最低,均值也取到最优值0,说明其具有更好的稳定性。对于f2,相比于其他算法,DLPFA均值和最优值都最低,具有更好的收敛精度。对于f4和f5,DLPFA均值和标准差远低于其他算法,具有更好的收敛精度和稳定性。对于f3,相比于其他算法,DLPFA仍取到最小均值,最优值和标准差仅稍逊于VS。综上,DLPFA在维度学习策略下的收敛精度有所改善,鲁棒性也有提升。
五种算法对于5个测试函数的收敛曲线如图2所示。对于f1和f5,DLPFA和PFA收敛速度相似,但DLPFA收敛精度明显优于PFA。对于f2、f3和f4,DLPFA的收敛曲线均位于其他算法下方,且能快速收敛到全局最优附近。这表明DLPFA对于其他算法收敛速度和收敛精度有着明显优势。

图2 五种算法的仿真结果Fig.2 Simulation results of five algorithms
3.3 Wilcoxon符号秩检验
Wilcoxon符 号 秩 检 验(Wilcoxon rank sum test,WRST)是一类非参数检验方法,它不对数据分布作特殊假设,适用于复杂数据两两比较的假设检验。为了进一步检验DLPFA算法的收敛性能,对五种算法的实验结果进行WRST非参数检验,结果见表3。“H+”代表正的秩和,“H-”代表负的秩和;P值(Probability value,P_value)用于检测两个算法是否有明显差异,当P_value>0.05时,说明两个算法无明显差异;获胜者(winner)用于记录DLPFA与其他对比算法的差异情况,当P_value<0.05,且H+<H-时,表示在5%的显著性水平下DLPFA相比于其他算法的收敛性能有明显优势,winner记为“+”;当P_value<0.05,且H+>H-,表示在5%的显著性水平下DLPFA的收敛性能弱于对比算法,winner记为“-”;P_value>0.05表示两种算法在5%的显著性水平下无明显差异,winner记为“=”。

表3 五种算法的WRST对比结果Tab.3 WRST comparison between five algorithms
对于全部基准测试函数,DLPFA的P_value均低于0.05,且H+均小于H-,表明DLPFA在5%的显著性条件下的收敛性能相比于其它对比算法都有明显优势。
4 维度学习策略的推广
PSO是经典的启发式算法,将维度学习策略用于PSO验证其是否具有普适性,改进后的算法称为维度学习粒子群优化算法(Dimension learning particle swarm optimization,DLPSO)。CEC2017基准测试函数集用于验证DLPSO的有效性,测试函数的相关信息见表4。设种群大小为50,维度为30,惯性权重从0.9线性递减到0.4,学习因子c1=c2=2。PSO与DLPSO两种算法在每个测试函数上独立运行30次,均值的统计结果见表5。

表4 CEC2017测试函数信息Tab.4 Parameters of CEC2017 benchmark functions
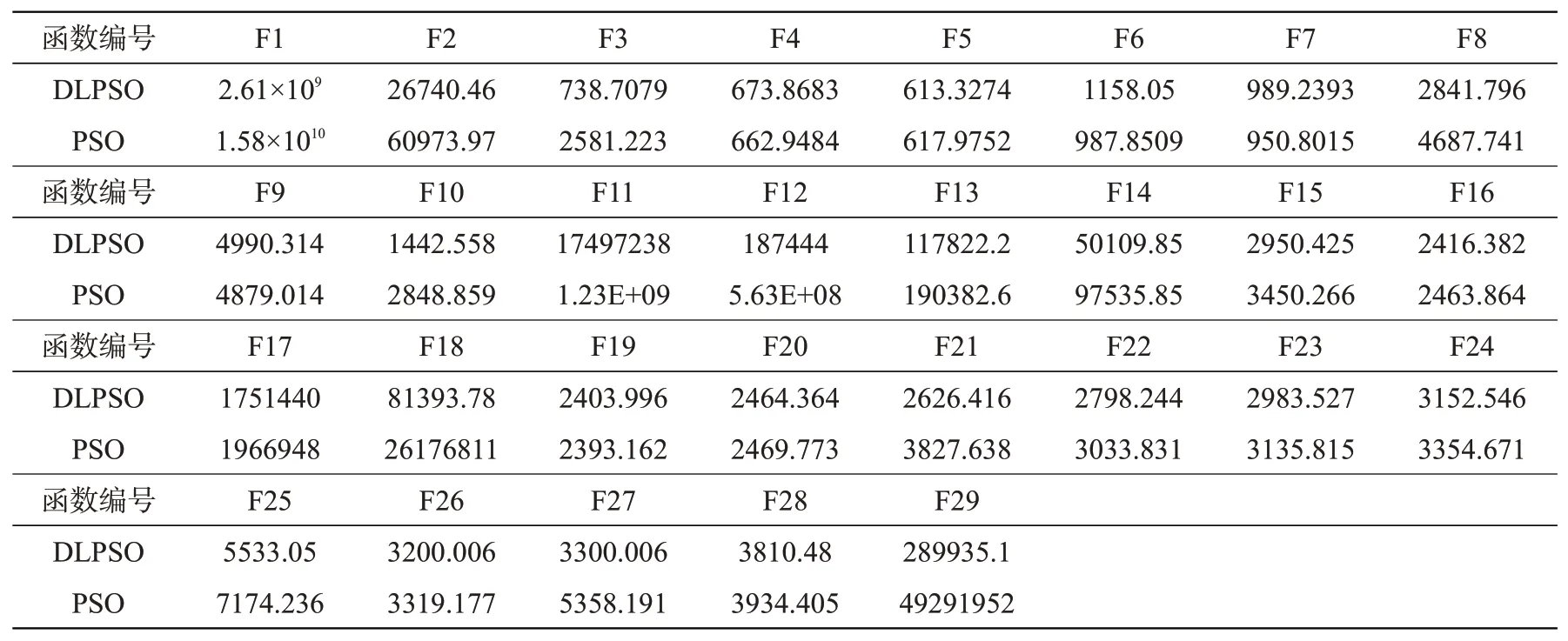
表5 两种算法的比较结果Tab.5 Comparison between two algorithms
在29个测试函数中,DLPSO在24个测试函数上的收敛性能明显强于PSO;仅在5个测试函数上的收敛性能弱于PSO,分别是F4、F6、F7、F9及F29。将维度学习策略应用到PSO中,提高了算法跳出局部最优的能力,收敛速度与精度也明显提升。表明该策略是有效的,且能应用于其他算法。
5 结论
提出一种基于维度学习的探路者算法DLPFA。为了克服PFA的缺点,使用限制维度策略进行越界处理,该策略具有很强的维度信息共享能力,能提高算法的收敛速度。在位置更新阶段融入加强维度策略,利用领导者生成的示范个体和种群中随机选择的个体进行位置再更新,充分发挥精英个体的领导能力,同时加强与种群的信息交流,增强种群多样性,进而帮助个体跳出局部最优。5个经典的Benchmark测试函数实验结果表明,DLPFA明显优于其余四种算法。维度学习策略在PSO算法上的成功应用表明该策略具有普适性。
