基于原型学习改进的伪标签半监督学习算法*
2021-11-25杨雨龙郭田德韩丛英
杨雨龙,郭田德,2,韩丛英,2†
(1 中国科学院大学数学科学学院, 北京 100049; 2 中国科学院大数据挖掘与知识管理重点实验室, 北京 100190)
深度神经网络被应用在计算机视觉和自然语言处理等许多领域,都取得了优秀效果。然而,训练一个深度神经网络需要数以百万计的标注样本和大量的计算资源,而对大量数据进行标注是很困难的。学术界已经研究了几种替代方案来缓解这一问题,如半监督学习(semi-supervised learning,SSL)、无监督学习和自监督学习。
半监督学习方法[1-2]是为解决海量无标签数据和高代价标注工作之间的矛盾而产生的。在半监督学习中,含有大量的未标注数据,只有小部分有标签数据。随着研究的深入,半监督学习算法在图像分类[3-4]、语义分割[5-6]、自然语言处理[7-8]等领域都取得了不错的结果。
本文主要研究基于伪标签(pseudo-labeling)的半监督学习图像分类算法。这类方法用输入图像在训练过程中的历史输出生成伪标签,并将其作为监督信号,然后以有监督的模式进行学习。
现有的伪标签方法存在“认知偏误(confirmation bias)”[9-10]的问题。“认知偏误”,也称为噪声积累,即模型的错误由于使用了自身提供的错误伪标签进行训练而得到加深。这种错误累积是由于伪标签方法仅使用单个样本自身的预测进行监督,一旦模型对样本预测错误,这一错误将被当作监督信号,而这个错误的监督信号无法通过与其他样本的比较得到修正。PLCB[11]通过使用MixUp[12]引入成对图像的信息,在一定程度上缓解了认知偏误。然而,成对图像提供的流形信息有限,PLCB依然会受到认知偏误的影响。
本文提出一种新的特征修正模型,即原型注意力模型,由于和神经网络结合,又称为原型注意力层(prototype attention layer, PAL)。假设在每一类样本的数据流形中存在P个具有代表性的点,即原型,所有样本都可找到某一原型与之相近。通过学习原型,得到数据流形的压缩表示,使得每个样本在训练时都能参考整个数据流形,从而缓解“认知偏误”。在特征空间中随机初始化C×P个向量作为原型,即每类有P个原型。将样本分类到某一原型的过程称为原型分配(prototypes assignment,PA)。把每个样本在当前迭代中的原型分配向量作为下一次迭代的伪标签,通过优化带正则项的交叉熵损失,来训练样本的原型。用学习到的原型合并样本特征,共同构建包括原型向量和样本特征的图,然后通过可学习的图注意力[13]模型来获得更好的特征。将PAL分别应用于2个伪标签半监督学习框架,得到2种使用原型学习改进的伪标签半监督学习算法(prototype attention improved pseudo-labeling, PAIPL):一种应用到软伪标签的自训练(self-training[14])框架,得到PAIPL-S算法;一种应用到伪标签的PLCB框架,得到PAIPL-P。为了更好地使用伪标签,本文还提出相互混合的监督技巧,用于伪标签生成,从而使生成的伪标签既能在早期相对迅速地收敛,又具备了好的流形表示。PAIPL-S和PAIPL-P算法在不增加图像预处理技术、而且训练使用小批量数据情形下,于CIFAR-10与CIFAR-100数据库上取得了很好的结果。本文提出的PAIPL算法架构如图1所示。
本文的贡献主要有以下3个方面:
1)克服了现有半监督学习方法对不同数据之间的关系信息利用不足的问题,提出一种基于原型的图注意力模型来生成特征:即通过训练学习原型,得到数据流形的一个压缩表示,通过图注意力模型,从原型中获得对样本分类有用的信息,合并原有特征,得到参考数据流形修正的特征;
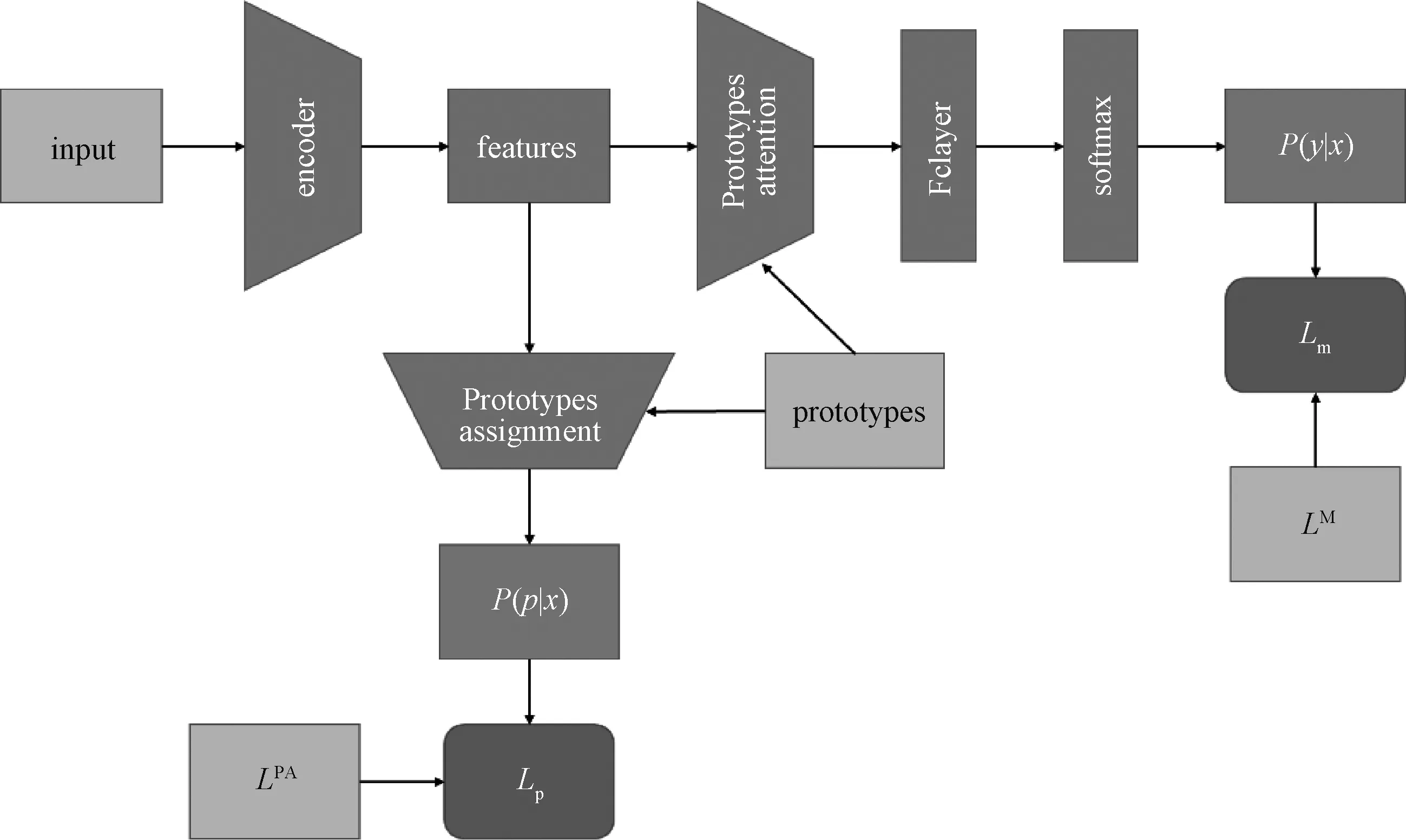
图1 PAIPL算法架构Fig.1 A schema of PAIPL
2) 将原型注意力模型应用到2种伪标签半监督学习框架中,得到2种新的伪标签半监督学习算法:PAIPL-S和PAIPL-P。相对于没有加入原型注意力模型的基线方法,算法的准确率得到显著的提升;
3)提出一种相互混合监督的伪标签生成方法。传统的伪标签生成方法使用同一数据的历史输出作为伪标签,收敛速度快,但存在“认知偏误”问题。单纯基于流形信息的伪标签生成能通过邻域信息校正伪标签的错误,但可能出现过分平滑的现象。本文通过综合二者的优缺点,提出以二者的随机线性组合作为伪标签,使得模型既能获得前期的收敛速度,又能防止后期的过分平滑。同时,融合这2种方式的相互学习也能防止它们各自陷入自己的局部最优解。
1 相关工作
关于深度半监督学习的工作主要有2个分支,即一致性正则化和伪标签方法。在下面的讨论中,将深度神经网络(卷积神经网络)特征提取器记为f(·),它将输入图像映射到一个高维特征向量f(x)。分类器(全连接层后接softmax函数)c(·)将特征向量作为输入,并输出分布向量p(y|x)=c(f(x))。
一致性正则化方法对同一样本的不同数据增广进行预测,并最小化它们之间的差异。之前的研究在无标签数据上大多应用以下一致性正则化损失:
(1)
其中:Aug1(·)和Aug2(·)是2种不同的随机图像增广。π-model[15]应用随机数据增广,要求模型对同一数据在2种不同数据增广下的预测结果相近。在此基础上,为保留更多的历史信息并稳定训练,文献[15]的Temporal Ensemble将历史预测的指数平均作为监督信号,最小化当前预测与历史平均预测的差异。另一种保留历史信息并稳定训练的算法是Mean Teacher[10],以模型的参数的指数平均作为教师模型,用教师模型的预测来指导训练过程。然而,Mean Teacher中教师模型会逐渐收敛到学生模型,使得一致性正则化损失的作用随着训练的进行而减小。Dual Student[16]为解决这一问题,提出分别训练2个学生模型,以在样本点稳定的一个学生模型的预测作为在该点不稳定的另一个学生模型的监督信号。然而,这几种方法的数据增广只使用了常规的图像数据增广,多样性有限。虚拟对抗训练(virtual adversarial training, VAT)[17]应用对抗训练来生成对抗样本,得到与传统图像增广不同的增广数据,并要求模型在对抗样本和原始样本上的预测相似。VAT还使用熵最小化作为额外的正则化,使模型在未标记的数据上做出明确的预测。但对抗样本只集中在数据点的附近,且不能很好地覆盖数据流形。最近,一些研究引入MixUp正则化作为训练信号,ICT[18]和MixMatch[19]要求成对样本的线性插值的预测和其标签(或伪标签)的相应插值之间的一致性。ICT应用Mean Teacher生成伪标签,而MixMatch则使用不同数据增广的预测的均值生成伪标签。在MixMatch中也应用了熵最小化。上述文献只建模成对样本,对数据流形的利用仍然不足。UDA[20]专注于重度数据增广,通过元学习来选择数据增广方法,然后最小化原始样本和增广样本之间的预测差异来实现一致性正则化。但UDA的性能高度依赖于数据增广方法库的合理性和多样性。
伪标签方法通过对未标记的数据生成伪标签,再以有监督学习的形式训练。Lee[21]直接将模型的预测作为伪标签。他们对模型进行预训练,在微调过程中使用伪标签。这种只考虑样本自身历史预测的伪标签算法受到认知偏误问题的严重影响。Self-training[14]首先用有标签数据训练模型,然后用训练好的模型对无标签数据标注,将预测概率最大值大于某一阈值的数据加入有标签数据再次训练,反复如此直至再也不能向有标签数据集中添加数据。虽然通过逐步添加可信样本避免了使用明显错误的样本进行训练,但由于错误数据一经加入有标签数据集后就无法纠正,受到认知偏误的严重影响。还有一些研究考虑了生成伪标签的不确定性[22-23],使用k个最近邻点的距离作为不确定性的衡量标准,通过优化损失来缩小类内距离、扩大类间距离,但这样只能利用局部的流形信息。PLCB[11]引入MixUp,使模型能利用成对数据线性插值的信息。一些研究通过在PLCB中加入dropout[24]、权重归一化[25]、类别分布对齐[26]、熵最小化[27],并在同一批次以固定比例加载有标签和无标签数据,在许多图像分类问题上都获得了显著的提升。然而,PLCB只能使用成对图像的信息,对数据流形整体的利用不足。另有一些学者提出结合基于图的标签传播来获得更好的伪标签[28],此算法交替进行2个过程:1)用有标签数据和伪标签数据来训练模型;2)用从模型中得到的特征来构建最近邻图,并应用标签传播算法来调整伪标签。文献[28]虽然成功利用了整个数据流形,但这种方法需要对所有样本的特征建图,计算量过大,不适用于稍大的数据集。
2 基于原型学习改进的伪标签半监督学习算法
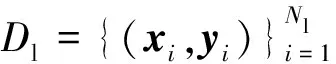
与文献[11]类似,在训练时,每个批次中按照固定比例加载有标签数据,其余是无标签的数据,同时优化2个损失:主分支的损失Lm和用来学习原型的损失Lp。
2.1 原型注意力层
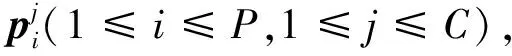
2.1.1 通过原型分配学习原型向量
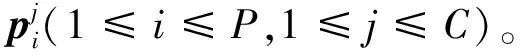
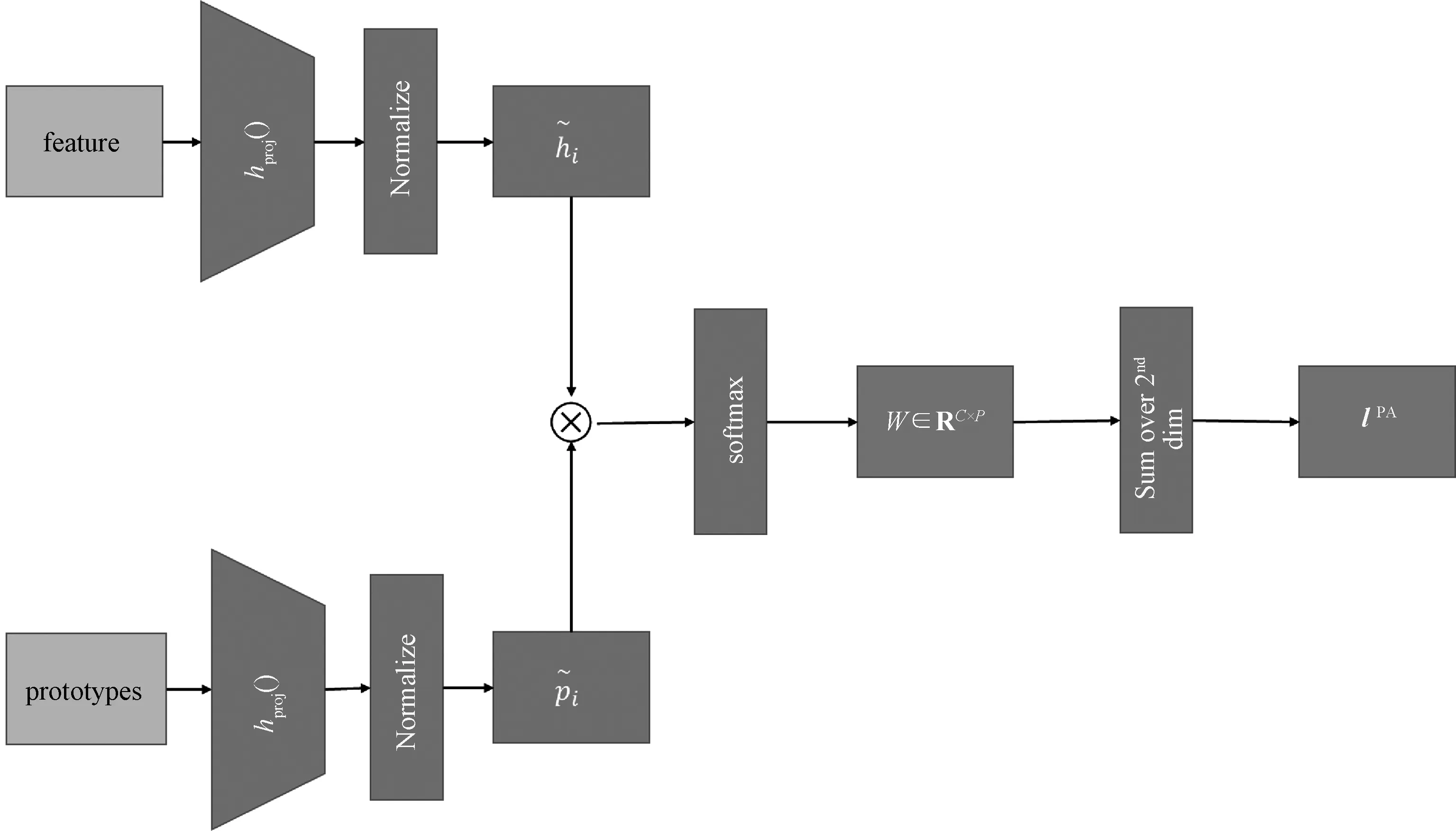
图2 原型分配过程Fig.2 Prototypes assignment
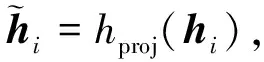
(2)
(3)
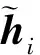
(4)
其中T是温度参数。使用交叉熵损失作为原型学习目标的主要损失
(5)
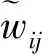
在原型损失中添加2个正则项,类别分布对齐损失RA[26]和熵最小化损失RH[27]。类别分布损失要求无标签样本中的原型分布与先验一致,即每个原型代表了数量均等的样本。熵最小化损失要求模型做出足够明确的判断,即每个样本归属于特定的某个原型。类别分布对齐损失RA为
(6)
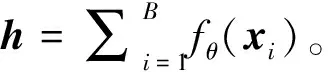
(7)
其中:wij是xi被模型分配到原型Pj的概率。
本文还提出一个损失来匹配原型分配的伪标签和主分支产生的分类的伪标签
(8)
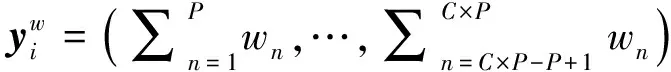
因此,总的原型损失为
Lp=Lprotos+λARA+λHRH+λPMRPM.
(9)
2.1.2 原型注意力层构造
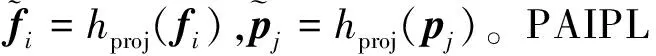
(10)
其中:softmax(·)应用于所有原型的权重向量,a(·)是用于计算未归一化注意力系数的线性映射。用原型向量的加权平均对所有原型的信息进行聚合:
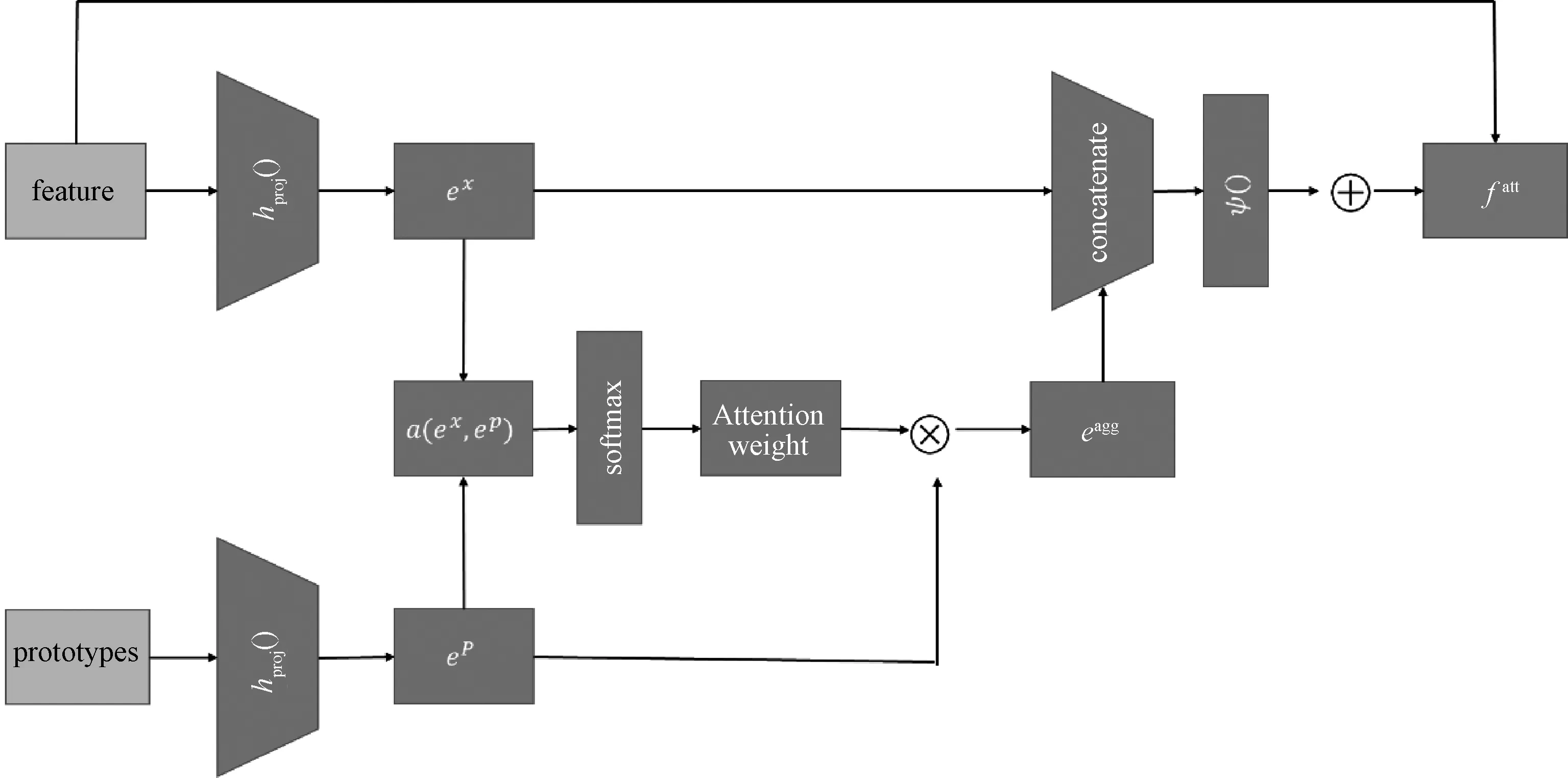
图3 原型注意力层Fig.3 Prototypes attention layer
(11)
将输入图像的嵌入ex和聚合嵌入eagg作为新的特征,投影回原来的低维特征空间:
(12)
其中ψ(·)是一个2层非线性网络。使用了残差块来降低训练难度。
2.2 原型注意力层改进的半监督学习
PLCB使用MixUp缓解“认知偏误”。MixUp使用样本标签对((xp,yp),(xq,yq))的凸组合训练神经网络:
xmix=δxp+(1-δ)xq,
(13)
(14)
其中δ~B(α,α),即参数为(α,α)的Beta分布。于是交叉熵损失变为
(15)
MixUp要求神经网络在训练样本对之间尽量近似于局部线性函数,从而实现决策边界的线性变化以实现更好的泛化。
PLCB在MixUp损失的基础上同样增加了类别分布对齐损失RA和熵最小化损失RH。值得注意的是,由于PLCB使用的数据经过了MixUp变换,RA和RH中所用到的模型fθ(xi) 都是对线性组合后的样本xi的预测。但在模型预测线性的假设下,2个正则项的假设仍然成立。
故正则化MixUp的总损失函数为
Lm=Lmix+λARA+λHRH,
(16)
其中λA和λH是超参数。
除了使用MixUp以外,PLCB还应用了以下技巧:在每批次样本中同时加载有标签和无标签数据。每个批次中固定比例的样本是有标签的,而其余的是无标签的。在PLCB中,对于不同有标签数据数量的不同数据集,每个批次中有标签数据的比例是一个重要的超参数,对模型的结果有不小的影响。这是为了防止有标签数据的采样过度和采样不足。为了获得无噪声的伪标签,生成伪标签时不引入随机性,即不做图像增广且不使用dropout,而训练时使用图像增广和dropout。
将原型注意力层应用在PLCB上:1)在特征提取过程加入了原型注意力层,改变了特征提取器hθ(·);2)加入了原型学习训练损失Lp。总损失为
L=Lm+λLp,
(17)
其中λ为超参数。
使用软伪标签的自训练模型是经典的伪标签半监督算法之一。对于有标签数据,模型使用交叉熵损失进行有监督训练。而对于无标签数据,模型使用软伪标签,用交叉熵损失进行训练。软伪标签由模型上一次迭代的预测得到。
(18)
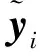
在此基础上,同样增加了类别分布对齐损失RA和熵最小化损失RH。
正则化软伪标签自训练的总损失函数为
Lm=LCE+λARA+λHRH,
(19)
其中λA和λH是超参数。
将原型注意力层应用在软伪标签的自训练框架上:1)在特征提取过程加入了原型注意力层,改变了特征提取器hθ(·);2)加入了原型学习训练损失Lp。总损失为:
L=Lm+λLp,
(20)
其中λ为超参数。
2.3 相互混合监督学习
为进一步提升模型性能,本文提出相互混合监督学习的技术。为了同时使用伪标签和相互学习[30]的方法,将2个分支的伪标签进行随机线性组合。一个分支是使用原型注意力层修正的传统神经网络,另一个分支是基于规范化余弦相似度的原型分配,详见2.1.1。当得到2.1.1中的原型分配wij后,PAIPL通过将每个原型向量分配到某个类中,将来自同一类的所有原型的概率相加,得到分类预测lPA,如图2所示。采用线性预热(linear warm-up)的方式,每一个分支在一开始的时候都会注重于来自自己分支的监督,以达到训练初期较为迅速的收敛。在预热过程结束后,用2个分支的监督的随机线性组合对每个分支进行训练。具体来说:
δ~U(0,1),
(21)
(22)
α=δ, (i>warm),
(23)
(24)
(25)
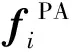
本文将加入原型注意力层和相互混合监督技术的伪标签半监督学习算法称为PAIPL。将其在PLCB和软标签自训练上的应用分别称为PAIPL-P和PAIPL-S。
3 实验
首先在几个标准的半监督学习基准上评估算法PAIPL,包括各种不同有标签数据比例的CIFAR-10和CIFAR-100。PAIPL比原始框架PLCB表现更好,并且较性能优异的一致性算法MixMatch也有显著的提升。
3.1 数据集和训练细节
对2个常用的半监督学习数据集CIFAR-10和CIFAR-100进行实验。PAIPL在不同数量的有标签数据下进行了测试。CIFAR-10和CIFAR-100分别是10类和100类的自然图像数据集。CIFAR-10包含50 000张训练图像和10 000张测试图像,大小为32×32,平均分布在10个不相交的类上。CIFAR-100包含50 000张训练图像和10 000张测试图像,大小为32×32,均匀分布在100个不相交的类上。与文献[11]类似,我们为CIFAR-10和CIFAR-100都留出了5 000个样本作为验证集来调整超参数。而在与其他方法进行比较时,使用所有的50 000个训练样本。
实验使用不同比例的有标签数据。在CIFAR-10中,Nl=250,500,1 000,4 000。在CIFAR-100中,Nl=500,1 000,4 000,Nl+Nu=50 000。Nl表示标记样本的数量,Nu表示未标记样本的数量。采用“13-CNN”[31]来提取特征,以便与前人的研究进行比较。
PAIPL只使用非常简单的图像预处理:图像填充、颜色扰动、随机裁剪、水平翻转、图像归一化和高斯噪声。首先添加2个像素的边缘填充,并裁剪回原尺寸,得到2个像素的随机平移。然后进行颜色扰动,以增加数据的多样性。再以0.5的概率对图像进行水平翻转。用整个数据集的平均值和标准差对所有图像进行归一化。最后,加入均值为0,标准差为0.15的高斯噪声。
使用随机动量梯度下降优化器训练模型,动量为0.9,权重衰减为10-4。所有实验在对整个训练集进行训练之前都会进行预热。首先在有标签数据上预训练模型,只用10次迭代来获得后续训练的初始权重。训练了400次迭代,在250次和350次迭代时进行学习率衰减。
本文没有对正则化权重λA和λH进行大量的调参,只按照文献[11]设置为0.8和0.4。使用了dropout,并在所有网络中使用权重归一化。
3.2 实验结果
首先展示在CIFAR-10和CIFAR-100上不同数量的有标签数据集的结果,见表1。PAIPL-P比目前最好的基于伪标签的方法PLCB有明显的改进,并且准确率比一致性方法MixMatch更高。
将PAIPL-S和PAIPL-P与它们对应的基线方法比较,结果显示,PAIPL-S和PAIPL-P相较于软伪标签自训练和PLCB都有明显提升。这说明PAIPL对2种伪标签半监督学习框架都是有效的。
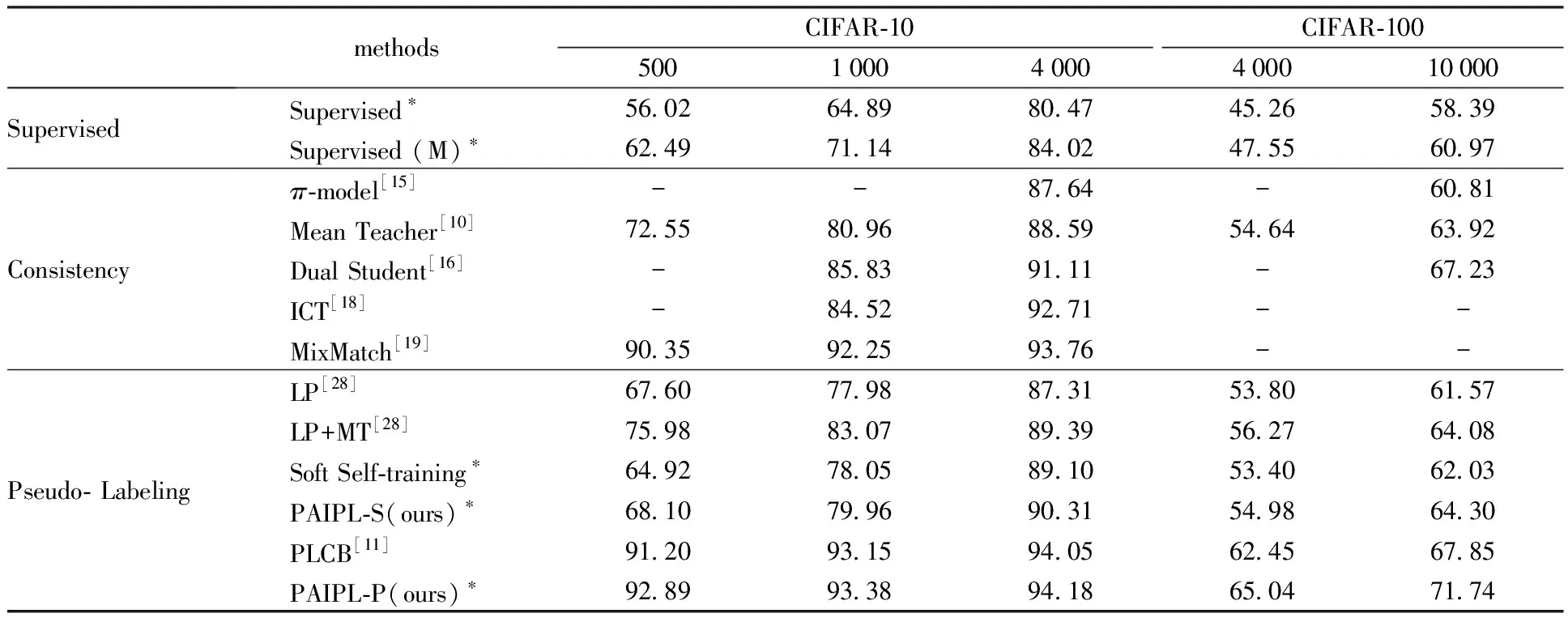
表1 与其他方法的精度比较Table 1 Accuracy comparison with previous methods
我们将PAIPL-P与在CIFAR-10和CIFAR-100中使用13-CNN[31]架构的其他方法进行比较,尽管只使用小的批次以及基本的数据预处理和简单的预热策略,PAIPL-P仍然取得了优异的结果。ICT和MixMatch通过引入MixUp,缓解了半监督学习中的认知偏误。PLCB不仅引入了MixUp,还加入了类别分布对齐和熵最小化等许多额外技术。PAIPL引入了更复杂的流形信息,从而获得更好的性能提升。这表明本文提出的算法有效地缓解了伪标签学习的认知偏误问题。
3.3 消融实验
通过消融实验(ablation study),测试PAIPL的不同模块的效果。表2展示了PAIPL-P在CIFAR-100上的使用4 000和10 000个有标签数据的实验。由于PAIPL-P是基于PLCB改进的,本文将实验结果与PLCB进行比较。在PLCB的基础上,增加了2个模块:原型注意力层(PAL)和相互混合监督(MM)。
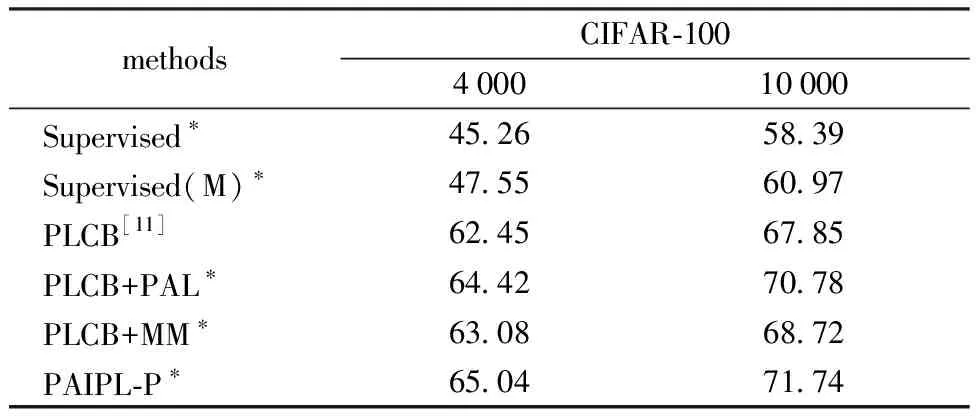
表2 消融实验结果Table 2 Results of ablation study
由于提供的数据非常有限,有监督学习(Supervised)只能得到较低的准确率。在有监督学习中加入MixUp后(Supervised(M)),由于MixUp的正则化要求边界更平滑,结果得到了改善。PLCB加入了无标签数据,形成半监督学习框架,与有监督方法相比,准确率有较大的提高。本文通过增加原型注意力层(PLCB+PAL),可以获得比PLCB更高的准确率。这是由于原型注意力层提供了更复杂的流形信息,而不仅仅是成对数据的信息。加入相互混合监督(PLCB+MM),结合了2个分支的优点,比PLCB准确率有所提升,但相对原型注意力层带来的提升效果较弱。将2种结构同时加入后(PAIPL-P)得到了最好的结果。
4 实验结果分析
首先展示PAIPL的有效性。图4比较了PLCB和PAIPL-P精度曲线和损失曲线。PLCB的训练损失持续下降,测试精度在学习率第2次下降前持续上升,而在学习率第2次下降后,测试精度反而下降了,而PAIPL-P的精度不断提高。这说明在训练后期PLCB出现了过拟合问题,这意味着PAIPL-P提供了比PLCB更充分的正则化。
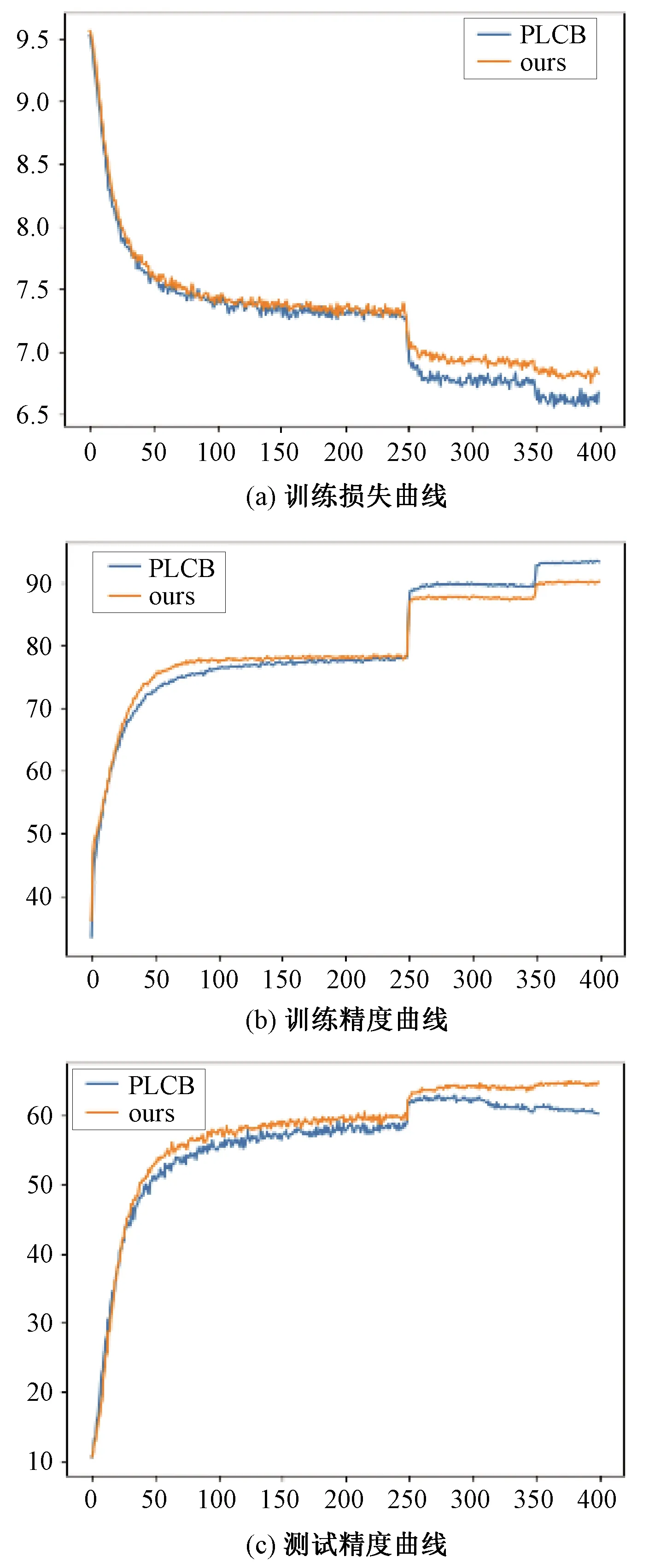
实验在4 000个有标签数据的CIFAR-100上进行。图4 PLCB和PAIPL的曲线对比Fig.4 Comparison curves between PLCB and PAIPL (ours)
然后展示PAIPL-P的t-SNE[32]降维可视化结果。在500个有标签样本的CIFAR-10上训练模型,并将所有测试样本映射到特征空间。特征向量和原型向量都用t-SNE映射到二维空间。图5显示了t-SNE的可视化结果。所有的原型都位于它们所属的真实聚类中,并且较为均匀的分布在整个聚类区域。这表示学习的原型能用很小的成本,较好地表达大部分的数据流形。PAIPL利用学习到的原型捕捉到数据流形的全局压缩信息,而基于MixUp的方法,如MixMatch和PLCB,只能使用成对数据信息。
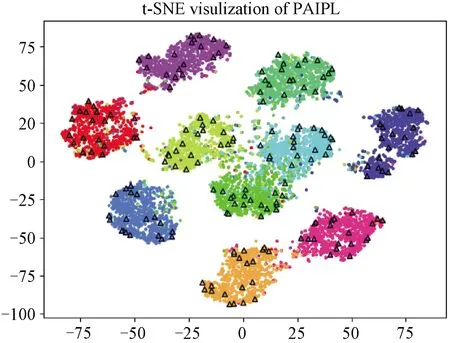
不同颜色表示不同的类别,三角形表示学到的原型。图5 测试样本特征的t-SNE可视化结果Fig.5 Visualization result of t-SNE of test sample features
图6展示了飞机这个大类中,不同特征空间中原型附近的样本图像。首先用带500个有标签数据的CIFAR-10上训练模型,并将所有测试样本映射到特征空间。每个原型的2个近邻样本被挑选出来,每个原型周围的图像非常相似,而不同原型周围的图像,虽然来自同一类,看起来差异更大。这表示PAIPL学到的原型可以看作是子聚类的中心,原型注意力层可以看作是细粒度分类。这对于更复杂的数据集更加重要,所以PAIPL在CIFAR-100的改进比在CIFAR-10上的改进更加明显。

图6 飞机图像部分原型近邻样本Fig.6 Images near different prototypes of airplane class
最后讨论相互混合监督学习的作用机理。PAIPL中有2个分支,主分支是加入原型注意力层的传统的前馈神经网络,在训练早期,该分支会在伪标签的监督下快速收敛。然而,随着训练的进行,它将受到认知偏误的影响。另一个分支是原型分配,在训练早期,由于原型尚未充分训练,该分支使用质量较差的原型进行预测,结果较差。随着训练的进行,原型会得到更好的训练,该分支会变得更强。但训练后期若只使用原型分配分支又会出现预测过于平滑的现象。所以本文使用线性预热来获得伪标签。在训练初期,每个分支更倾向于受到来自该分支的监督。而在预热过程结束后,用2个分支预测的随机线性组合对每个分支进行训练。
5 结论
本文提出一种新型的特征修正模型PAL。这种特征修正模型可以广泛应用在伪标签半监督学习框架中,并与相互混合监督结合,得到基于原型学习改进的伪标签半监督学习算法。PAIPL包含2部分:1)用于改善特征的可学习的原型注意力层;2)用于结合修正特征伪标签和原型分配伪标签的相互混合监督。本文将PAIPL算法应用到2种不同的伪标签半监督学习框架上,软伪标签的自训练框架和伪标签的PLCB框架,得到2种新的伪标签半监督学习算法PAIPL-S和PAIPL-B。实验结果显示PAIPL-P优于最新的伪标签方法和一致性正则化方法。根据本文的研究可以看出伪标签方法可以和一致性训练方法一样,在半监督学习中起到重要作用。未来的工作可以使用更大批量的数据和更强的图像预处理来获得更好的效果,也可以考虑将自监督学习的成果移植到半监督学习中。
