基于深度学习的汽车车牌识别算法研究
2021-11-23高昕葳
高昕葳
(甘肃林业职业技术学院机电工程学院,甘肃天水 741020)
0 引言
车牌作为汽车外在显著身份信息之一,可以通过车牌获得车辆的行驶路径、类型、司机等信息。车牌识别应用范围较广,在智慧停车、高速公路车辆监测、城市限号等方面广泛使用。然而目前所采用的车牌识别算法对车牌图片要求较高,不能应用于复杂光线、多尺度、高识别率、速度快的识别的要求。车牌识别包含车牌提取、字符分割、字符识别三部分。传统方法实现车牌定位主要依靠人工设计的特征:基于形态学特征的定位法[1-2],基于色彩图像的定位法[3],基于神经网络的定位法[4-5],基于纹理特征的定位方法[6]等。传统的车牌识别算法对车牌图片要求比较高,而影响车牌图片质量的因素较多,如光线、车牌与图像采集设备的距离和角度等。目前的分割算法有基于模板的字符分割算法[7]、聚类算法字符分割[8]等。字符识别作为车牌识别中最重要的环节,其准确率直接影响车牌的准确识别。使用机器学习算法识别字符[9],但是识别时间和识别率还有很大的提升空间。随着深度学习的出现,特征提取不需要依靠人为设定特征,字符识别准确率和速度有了大幅度提升。因此,本文使用基于深度学习Faster-RCNN[10]与VGG16(Visual Geometry Group Network)模型相结合的车牌识别算法,对汽车车牌进行提取、分割和车号识别。
1 基于Faster-RCNN与VGG16的车牌识别
基于深度学习的目标检测算法,按照原理可以将深度学习的目标检测算法分为One-stage和Two-stage两类,本文所用的是属于Two-stage的Faster-RCNN模型。Faster-RCNN是一种应用于目标检测和识别的卷积神经网络,由Fast-RCNN改进而来,实现了端对端的检测。使用该模型进行目标检测任务能够实现检测对象的精确定位,预测图片中的物体种类,克服多角度、多尺度、多类别、多场景的识别缺点,Fast-RCNN流程如图1所示。

图1 Fast-RCNN流程
2 车牌定位
本文使用Faster-RCNN模型对车牌进行提取。Faster-RCNN网络模型首先使用基础特征提取网络提取被检测图像的特征向量。特征提取网络包含13个卷积层和5个池化,特征向量被RPN(Region Proposal Networks)网络和全连接网络共享。RPN网络用于生成目标的建议区域(region proposals),网络结构包含一个3×3的卷积层和两个1×1的卷积网络,其网络结构如图2所示。通过Softmax激活函数,利用Bounding box regression修正anchor框获得目标准确位置。Roi(region of interest)池化层用来得到对应的分类,也得到了概率向量接受特征提取网络输出的特征权值综合proposals,经过一个全连接层和一个Softmax层,得到了概率向量,判定目标类别。

图2 RPN网络
3 字符分割
我国车牌类型多,种类复杂。以普通车车牌为例,小型车的蓝底白字、中大型车的黄底黑字等。根据GA36-2007标准可以得知,车牌由1个文字加6个字符组成,其中第一个文字为车牌所在省份的简称,共31种,其余的字符为字母(去除I、O)和数字组成。首先对Faster-RCNN网络提取的车牌进行图像预处理。图像预处理包括图像灰度图处理、滤波去噪、图像增强、灰度图二值化等。
3.1 图像灰度化
车牌图像以红绿蓝三通道分量来储存图片,图像灰度化的过程是将彩色图像的3个通道转换为只有1个灰度通道的图片。常用的图像灰度化法有平均值法、最大值法、加权平均值法等。因车牌种类多,本文通过图3所示的实验结果对比,选用加权平均值灰度化方法,有较好的鲁棒性。

图3 常用的灰度化方法
3.2 滤波去噪
车牌图像信息在采集中容易产生噪声,常用的图像滤波算法有高斯滤波、双边滤波、均值滤波等方法。虽然这些方法可以较好地去除噪声,但是使车牌字符图像边缘变得模糊。而双边滤波很好地保持轮廓的边缘特征的同时能消除噪声。图4所示为采用不同方法去噪的结果对比,本文采用双边滤波进行对车牌的去噪处理。

图4 常用的滤波方法
3.3 图像增强
图像增强主要解决图像的灰度级范围较小造成灰度对比度较低的问题,目的是增强图像的灰度对比度,使得图像中的细节对比更加分明。几种常用的方法有线性变换、分段线性变换、直方图正规化、局部自适应直方图均衡化等。本文采用了一种伽马变换算法来增强车牌图像的对比度,效果较好,有助于后续的处理。
3.4 图像二值化
二值化主要为了减小计算量,其原理为:设定一个值T为阈值,将二值化图像的像素灰度值与T比较,小于T,该像素值点设成0,即白色,否则该像素点值为255,即黑色。整个图像呈现出黑白两种效果。其中阈值的选取是二值化效果的关键,Otsu法统计整个图像的直方图来实现全局阈值T的自动选取,该算法简单、稳定,是常用的一种方法,本文使用Otsu法对图像增强后的车牌图像进行了二值化处理,其过程如图5所示。

图5 图像二值化过程
3.5 字符分割
本文采用基于垂直投影的字符分割算法,其原理是对预处理后的车牌图像进从左到右进行扫描,统计车牌字符的每列像素点个数,可以得到一幅垂直投影图像,根据车牌字符像素统计特点:波谷就是字符投影,波峰是字符间隙投影,选取所有波峰的中心位置,把车牌图像分割成单个独立的字符图像,该方法简单、速度快、效率高,分割效果如图6所示。

图6 字符分割
4 字符识别
传统的车牌字符识别的方法是模板匹配和传统BP(Back Propagation Neural Network)神经网络等方法。卷积神经网络可以对复杂的图像自动提取特征和分类,受外界环境干扰较小,其鲁棒性和自适应性比较好,因此本文采用了基于卷积神经网络的VGG16网络模型进行车牌字符识别。其模型包含了13个卷积层、5个池化层、3全连接层,模型如图7所示。在模型中加入Dropout层,直接作用是按比例减少中间特征数量,从而减少冗余权值,增加每层各个特征之间的正交性,提升模型泛化能力。本文以CCPD数据集为基准,对字符分割后的字符图片进行统计、分类,制作字符识别的数据集。数据集包含的种类有31种文字,去除I、O的剩余24个字母,10个数字,其识别车牌问题转换为65种字符分类问题。数据集包含汉字图片3 100张,字母图片2 400张,数字图片1 000张。在Keras平台中运用深度学习理论搭建VGG16神经网络模型进行训练。将分割的二值化图片长宽统一为224的图片送入输入层,损失函数使用relu,优化器选择adam,epoch为200,进行训练识别。图8(a)所示为训练精度与迭代次数关系,由图可知在迭代到第100次时,准确率达到99.2%;图8(b)所示为损失率与迭代次数关系,由图可知,在迭代到100次左右时,损失率降到最低并趋于稳定,在迭代到200次时,其识别准确率为99.2%。
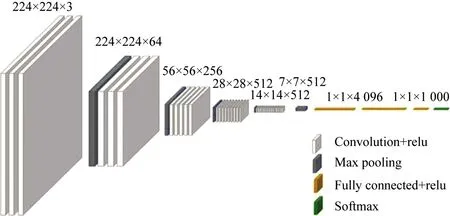
图7 VGG16结构

图8 识别训练
5 结束语
本文使用Faster-RCNN和VGG16模型对车牌进行定位和识别。通过Faster-RCNN对车牌定位,使用VGG16模型进行识别,在车牌数据集进行训练和测试,实验结果表明本文使用的方法能够有效地提取车牌图像并且识别车牌号,检测正确率高达99.2%。相比传统的车牌识别算法,虽然模型训练时间较长,但可以得到更高的准确率和更高的识别效率。由于样本图片数量有限,车牌图片质量影响因素较多,若添加更多的样本,使其数据更加丰富,模型的识别准确率会相应提高。
