基于深度神经网络的维语语音关键词检索
2021-11-20张伟涛米吉提·阿不里米提郑方艾斯卡尔·艾木都拉
张伟涛 米吉提·阿不里米提 郑方 艾斯卡尔·艾木都拉

DOI:10.16644/j.cnki.cn33-1094/tp.2021.11.006
摘 要: 语音识别中的一个重要的分支就是关键词检索。虽然在英语上的关键词检索已经成熟,但是低资源的语音,比如维语的语音关键词检索研究缓慢,仍需要更深入的研究。文章在维吾尔语语数据集thuyg20上,先在GMM-HMM(Gaussian Mixture Model Hidden Markov Model)声学模型,DNN-HMM(Hidden Markov Model Deep Neural Network)声学模型,LSTM-HMM(Long Short-term Memory Hidden Markov Model)声学模型解码产生的网格lattice上捕捉关键词,将DNN-HMM和LSTM-HMM解码产生的网格进行融合,再在融合的网格lattice上进行关键词检索。实验结果表明,融合后的结果在准确率和召回率方面要优于DNN-HMM和LSTM-HMM模型的检索性能。
关键词: 维吾尔语; 低资源; 语音关键词检索; 深度神经网络
中图分类号:TP391.1 文獻标识码:A 文章编号:1006-8228(2021)11-21-04
Uyghur speech keyword retrieval based on deep neural network
Zhang Weitao, Mijit Ablimit, Zheng Fang, Askar Hamdulla
(College of Information Science and Engineering, Xinjiang University, Urumqi, Xinjiang 830046, China)
Abstract: An important branch of speech recognition is keyword retrieval. Although keyword retrieval in English has become mature, the research on low-resource speech,such as Uyghur speech keyword retrieval, is slow and still needs more in-depth research. On the Uyghur language data set thuyg20, the keywords are captured on the lattice generated by decoding with the acoustic models of GMM-HMM (Gaussian Mixture Model Hidden Markov Model) acoustic model, DNN-HMM (Hidden Markov Model Deep Neural Network) acoustic model and LSTM-HMM (Long Short-term Memory Hidden Markov Model), merge the lattices generated by the DNN-HMM and LSTM-HMM decoding, and then perform keyword search on the merged lattice. The experimental results show that the fusion result is better than the retrieval performance of the DNN-HMM and LSTM-HMM models in terms of accuracy and recall.
Key words: Uyghur; low resources; speech keyword retrieval; deep neural network
0 引言
虽然在维吾尔语的语音识别ASR系统有了许多研究成果[1],但是关于维吾尔语的语音关键词检索却比较缓慢,缺乏深入的研究。在如今移动终端以及多媒体信息爆炸性增长的年代,多语言语音信息的检索研究在社会发展、网络安全、舆情分析等多个领域有很重要的现实意义,所以应进一步推进低资源语言语音检索的研究。
首先对维吾尔语语音声学单元建模,进行连续语音识别,再在此基础上进行维吾尔语语音关键词的检索。由识别和索引两部分组成[2],关键词检索的方法通常都是用关键词的模板,在连续语音流中进行匹配查找,比如DTW(Dynamic Time Warping)方法和DTW的不同变体等[3]。表示关键词模板的方法有GMM模型[4-5]、HMM模型[6]、DNN[7-8]等,他们对各种特征进行匹配,这些特征包括Speech spectrum、MFCC、PLP、LPC[9]等等。但是这种用关键词模板匹配的方法适用于较小的数据量进行关键词检索,并且用不同的模板去表示关键词有很大的不同。影响关键词检索准确的因素有标记错误,噪声,信道不同等[10]。随着大词汇量连续语音识别准确率和效率的不断提高,可以在连续语音识别的基础上进行语音关键词检索,通常比DTW模板匹配的结果较好,所以连续语音关键词检索具有很好的应用价值[11]。
汉语、英语等大语言相关研究很多,如汉语语音关键词检索,在文献[12]里检索达到了80.76%的准确率。由于在实际环境中,噪声、个性化、情绪等众多因素的影响,检测正确率还会大幅降低。
1 系统总体框架
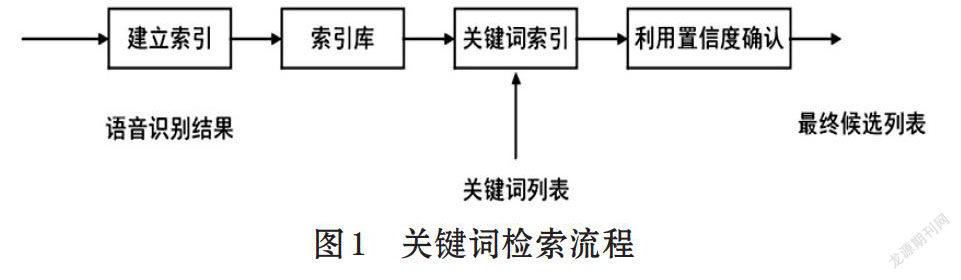
维语音关键词检索的总体流程是,首先进行维语语音识别,解码产生相应的lattice,再进行语音关键词检索。其实lattice只是在语音识别的过程中产生的中间结果,是一个由测试集生成的网格,网格里面包含测试集的每条句子的每个候选词;由每条测试集句子解码并联起来的一个庞大的网格;网格是以加权有限状态转换器形式的存在,检索的时候也需要将检索的关键词转换成加权有限状态转换器的形式在网格上进行索引,进而在lattice进行语音关键词检索,通过置信度判断是否是关键词,关键词检索的流程如图1所示。
本文建立GMM,DNN,LSTM,HMM等各种LVCSR系统模型。GMM-HMM模型如图2所示,DNN-HMM模型如图3所示,LSTM-HMM模型如图4所示。GMM,DNN,LSTM都在拟合同一个观测序列的概率分布,然后作为HMM的观测状态概率矩阵;从HMM指向GMM,DNN,LSTM的箭头是指HMM的某个状态的观测概率由某一个GMM,DNN,LSTM的某一个输出节点决定;最主要的的差别是利用DNN和LSTM代替了GMM实现了状态概率的输出;后验概率可以看作是有监督学习,根据观测值去求状态值,而DNN和LSTM是根据观测值逆向传播的过程,属于有监督学习;另外经过softmax输出,就能得到后验概率了。
在图2 GMM-HMM中,HMM的每一个状态的概率分布由GMM拟合。一个状态X由一个GMM表征,同时相邻的GMM之间没有很强的相关性;GMM模型输出的似然概率就是HMM状态的输出的观测概率P(Y|X)。
在图3中,HMM的每一个状态的概率分布由DNN拟合。DNN一个输出节点对应一个状态,为了考虑上下文相关信息,通常送入DNN的是2n+1帧;DNN作为判别模型是直接对给定的观测序列Y后状态的分布进行建模,也是监督学习,网络的输出P(X|Y)表示不同音素的后验概率,根据贝叶斯公式需转换为不同音素的似然概率P(Y|X)。
在图4中,HMM的每一个状态的概率分布由LSTM拟合。LSTM一个输出节点对应一个状态,为了考虑上下文相关信息,通常送入LSTM的是2n+1帧;LSTM作为判别模型是直接对给定的观测序列Y后状态的分布进行建模,也是监督学习,网络的输出P(X|Y)表示不同音素的后验概率,根据贝叶斯公式需转换为不同音素的似然概率P(Y|X)。
相同点,HMM的状态初始概率和转态转移概率都不变,HMM仍然是对时序进行建模。
2 实验数据准备
实验中,维吾尔语语音关键词检索所使用的语音语料包括,训练集有7600条音频和文本句子,验证集有400条音频和文本句子,测试集有1468条音频和文本句子[13]。语料库的数据集如表1所示。
3 实验结果及分析
维语语音识别词错误率和维语的关键词检索结果,分别如表2和表3所示。维语语音在不同的声学模型中识别词错率的情况和关键词检索性能。本文发现,维吾尔语DNN-HMM比mono识别率提升了28.54%;LSTM-HMM比mono识别率提升了31.24%,与DNN-HMM识别率相比提升了2.7%;LSTM-HMM模型对于维语的语音关键词检索准确率达到了90.53%。
3.1 基于DNN-HMM声学模型
使用DNN-HMM声学模型做语音关键词检索;维吾尔语实际总的关键词词数1602,用F4DE获得,检出正确的关键词数为1444,检索到的关键词数为1616,虚警数为172,由关键词检索的评价的公式可得,召回率为90.14%,准确率为89.36%,虚警率为10.74%。
3.2 基于LSTM-HMM声学模型
使用LSTM-HMM声学模型做语音关键词检索,维语实际总的关键词数为1602,使用F4DE获得,检出正确的关键词数为1463,检索出总的关键词数为1616,虚警的关键词数为153,根据关键词检索出系统性能评价指标得,准确率为90.53%,召回率91.32%,虚警率为9.55%。
通过实验对别发现在不同的声学模型上,维语的关键词检出的查准率,虚警率,召回率都有所不同,但是在LSTM-HMM模型上的性能最佳,维吾尔语达到了90.53%,相比于单音素而言提升34.28%。 相比于高斯混合模型而言,LSTM网络更能拟合数据的分布,进而提高关键词检出的准确率。
4 基于系统融合的维语语音关键词检出
据文献[14]所得,语音识别系统性能相近的结果,可以进行系统融合从而提高系统的识别性能,本文的LSTM-HMM和DNN-HMM语音识别系统性能较近且较好,借鉴文献[15]的网格合并的方法融合系统。
网格融合是将两个网格的开始节点合并到一个新的开始节点,从而可以将两个网格合并到一个拓扑结构中,合并后的网格增大了对正确内容的覆盖率。词图合并的方法如图5所示。
在图5中,词图网格L1用A表示,词图网格L2用B表示,词图网格L1和词图网格L2的融合用用A U B表示,不同网格单元之间的转移关系可以用(x:y/w)表示,x为输入,y为输出,w为权重,eps为空符号。在网格A中,网格单元0到网格单元1的转移中,输入为b,输出为p,权重为3,词图网格L1和词图网格L2的融合,就是将词图网格L1的起始节点和词图网格L2的起始节点合并成一个共同的起始节点0。不同网格之间的转移关系可以用(eps:eps/0),其他的网格单元之间的转移关系不变;然后按顺序改变每个词图单元网格的编号,合并后的词图网格上部分为词图L1,下部分为词图L2,通过对比发现只是原始词图网格的编号发生了变化,网格单元之间的转移关系没有发生变化,合并后的词图网格,可以提高正确识別的概率。
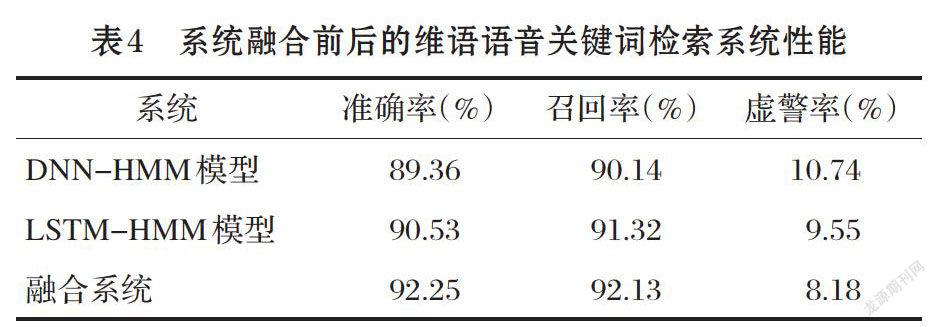
系统融合前后的维语语音关键词检索系统性能比较,如表4所示。将LSTM和DNN解码产生的网格进行融合,融合后将会产生一个大的网格图,可以增加对正确识别内容的覆盖率,所以对于LSTM-HMM声学模型的关键词检出系统,维语的准确率提高了1.72%;对于DNN-HMM声学模型的关键词检出系统维语的准确率提高了2.89%,可将融合后的系统用于关键词检出准确率要求较高的应用场景。
5 结束语
本文在kaldi中搭建了完整的语音关键词检索系统,使用thuyg20数据集,使用了不同的声学模型,在语音识别解码产生的网格lattice上进行语音关键词检索。实验结果表明,DNN-HMM和LSTM-HMM模型的检索性能好于GMM-HMM检索性能,与GMM相比DNN和LSTM更能准确的拟合语音数据的不同分布情况;为了增大对正确识别内容的覆盖率,将DNN和LSTM的解码网络进行融合,产生更大的网格进行语音关键词检索,网格融合后的效果要好于DNN-HMM和LSTM-HMM模型的检索性能。为了进一步验证网格融合系统性能的有效性,可以将该方法用于哈萨克语,柯尔克孜语语音关键词检索。
参考文献(References):
[1] 沙尔旦尔·帕尔哈提,米吉提·阿不里米提,艾斯卡尔·艾木都拉.基于词干单元的维-哈语文本关键词提取研究[J].计算机工程与科学,2020.42(1):131-137
[2] 李娜,葛万成.语音关键词识别系统的模型训练及性能评价[J].信息通信,2020.3:8-10
[3] 侯靖勇,谢磊,杨鹏等.基于DTW的语音关键词检出[C].全国人机语音通讯学术会议,2015.
[4] Manish Gupta,Shambhu Shankar Bharti,Suneeta Agarwal. Gender-based speaker recognition from speech signals using GMM model[J]. Modern Physics Letters B,2019.33(35).
[5] GMM Estimation of Non-Gaussian Structural Vector Autoregression[J]. Journal of Business & Economic Statistics,2021.39(1).
[6] 冯怡林.基于HMM和DNN混合模型研究的语音识别技术[D].河北科技大学,2020.
[7] Sun M, Snyder D, Gao Y, et al. Compressed Time Delay Neural Network for Small-Footprint Keyword Spotting[C].conference of the international speech communication association,2017:3607-3611
[8] Chen G, Parada C, Heigold G, et al. Small-footprint keyword spotting using deep neural networks[C].international conference on acoustics,speech,and signal processing,2014:4087-4091
[9] 罗元,吴承军,张毅,黎小松,席兵.Mel频率下于LPC的语音信号深度特征提取算法[J].重庆邮电大学学报(自然科学版),2016.28(2):174-179
[10] 张舸,張鹏远,刘建,颜永红.基于动态时间规整的语音关键词检索算法[J].网络新媒体技术,2019.8(1):18-23
[11] 李宝祥.语音关键词检索若干问题的研究[D].北京邮电大学,2013.
[12] 侯云飞.中文语音关键词检出技术研究[D].南京理工大学,2017.
[13] 艾斯卡尔·肉孜,殷实,张之勇等.THUYG-20:免费的维吾尔语语音数据库[J].清华大学学报:自然科学版,2017.57(2):182-187
[14] 李伟.基于内容的汉语语音检索技术研究与系统实现[D].清华大学,2011.
[15] 李鹏,屈丹.基于得分归一化和系统融合的语音关键词检测方法[J].数据采集与处理,2017.32(2):346-353
