基于多元回归KNN的网络数据库不完整信息填充
2021-11-17赵春霞赵营颖
赵春霞,赵营颖
(河南中医药大学信息技术学院,河南郑州450046)
1 引言
在现阶段,网络数据库数据丢失常常是大数据环境中不可避免的问题,如何处理缺少数据是目前数据分析领域研究的重点。由于在现阶段很多数据分析都要依赖于完整的数据集,因此带来了一些麻烦。为此,寻找一个有效而可行的方法来处理这些缺失的数据是目前急需解决的问题。
当前,已有较多学者开展了关于数据不完整信息填充的研究,文献[1]中,王玮等人提出了不同类别非完整大数据中缺失数据填充方法,该方法主要找出其它类型指标与某一类型指标的相关性,得到数据集,求得权系数,利用相关理论和经验,计算初始数据库的信息熵,确定缺失数据区间的下限,实现缺失数据的填充。但是该方法的缺失数据检测时间较长,导致网络数据库不完整信息填充效率较低;文献[2]中,何丹丹等人提出了分布式数据库用户丢失数据恢复重构方法,该方法主要通过对近邻进行加权计算,得到丢失数据的填充量,完成对丢失数据的恢复与重建。但是该方法的缺失数据预测误差较大,导致缺失数据估计值准确度较低。
针对上述方法存在的问题,本文提出基于多元回归KNN的网络数据库不完整信息填充方法。首先通过对网络数据库不完整信息进行检测与预处理,并采用多元回归KNN方法计算网络数据库中目标数据与完全值数据矩阵中所有数据记录的欧氏距离,获取缺失值,然后对网络数据库不完整信息进行估算与填补。最后通过实验结果可知,此次研究的基于多元回归KNN的网络数据库不完整信息填充方法较传统方法填充效果更好,具备实际应用意义。
2 网络数据库不完整信息填充方法
此次研究的基于多元回归KNN的网络数据库不完整信息填充方法的框架如图1所示。
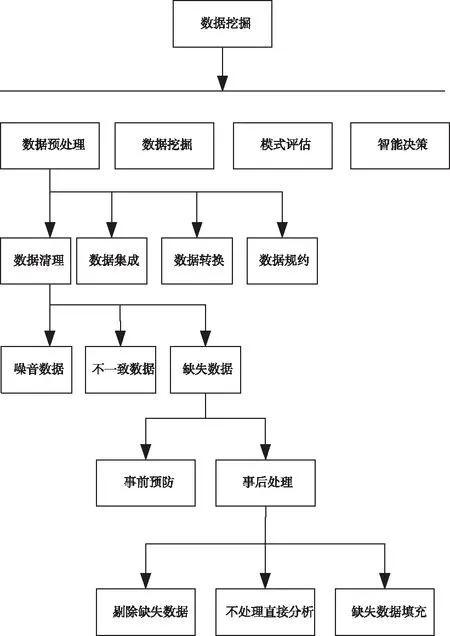
图1 基于多元回归KNN的网络数据库不完整信息填充框架
其中,数据预处理是后续数据挖掘与填充的基础,将直接影响填充结果,为此预先对数据检测与预处理,具体内容如下所示。
2.1 网络数据库不完整信息检测与预处理
在对网络数据库不完整信息填充之前,预先对网络数据库不完整信息检测与预处理[3-4]。假设样本空间中有m个数据对象,每个数据对象中包含n分割属性,将其表示为
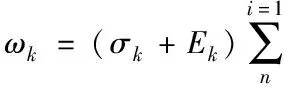
(1)
式(1)中,ωk代表网络数据库中第k个属性值的权重,rik代表第i个属性与第k个属性的相关系数,Ek、σk分别代表数据k的标准差。
为了综合考虑网络数据库中的相关性、冲突性以及离散型特质,首先采用灰色关联度计算方法对数据库中的所有信息进行检测[5-6]。假设给定一个数据库中的数据区域,计算该网络数据库中的数据密度,获取检测到的不完整信息,用下述公式表示
w=ωk(t/n)+vi
(2)
式(2)中,t代表当前数据查询时间,n代表数据样本数量,vi代表第i样本的数据密度。
同时,对于一个存在缺失数据的网络数据库,若采用较小的区间发现数据与数据之间的关系,会增加该数据库中的信息熵[7]。信息熵是一个具有系统有序化程度的度量参数,其值越大代表计算越混乱,信息熵值越小代表计算越趋于一致,为此将其定义为

(3)
式(3)中,p代表度量参数。
依据上述计算结果,利用信息熵的属性约简算法,对网络数据库中不完整信息进行约简处理[8-9]。当采集的数据间隔更大时,数据间的线性相关就会减少。由此定义的基于时间相关性的线性差分公式如下
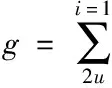
(4)
式(4)中,η代表预测误差,d代表已知数据的距的均值,u代表线性差值样本变量值,其值越大代表计算越精确。
通过上述过程完成网络数据库不完整信息的检测与预处理。
2.2 基于多元回归KNN的不完整信息填充
在上述网络数据库不完整信息检测与预处理的基础上,对网络数据库不完整信息填充。在此过程中,主要采用多元回归KNN方法对网络数据库不完整信息进行填充,其步骤如下所示:
第一,网络数据库数据初始化处理,计算出网络数据库中的分类间隔,其表达式如下所示
(5)
式(5)中,e代表网络数据库中数据与数据的间隔值,b代表最优分类函数,s代表分类的目标函数,xi代表第i个数据的判别函数[10]。
第二,计算网络数据库中目标数据与完全值数据矩阵中所有数据记录的欧氏距离,其表达式如下所示
(6)
式(6)中,zi代表第i个最近邻的最近邻参数,o代表目标数据。
第三,通过上述过程计算出欧氏距离。选出欧式距离最小的数据记录作为目标数据的最近邻,并将其存储到数据矩阵的响应位置中;
第四,分别从完全值数据矩阵中选出与每个目标数据最近邻欧氏距离最小的数据记录,并将其存入数据组中[11-12];
第五,初始化每个目标数据最近邻的近邻重要程度,其表达式如下所示
(7)
式(7)中,R代表近邻重要程度,B代表数据重要程度判断参数。
第六,消除目标数据的最近邻噪声,其具体的判断标准如下所示
(8)
式(8)中,xi代表目标数据记录第i个最近邻的噪声判断结果,M代表噪声消除参数。
依据上述计算判断目标数据的非噪声最近邻,完成对最近邻噪声的消除,获取缺失值,在此基础上通过一个适当的非线性函数将数据由原始的特征空间映射到一个新的特征空间,其表达式为

(9)
第七,在上述数据空间映射完成的基础上,依据缺失值,对网络数据库不完整信息进行估算与填补。在处理过程中,需要注意的是,在大多数情况下数据库内的成分数据不同,即数据库中的数据每一行都是不同的数据,将其表示为
(10)
上述矩阵为观测矩阵,n代表行的个数即样本量,D代表列的个数为成分数据的部分数。
由于数据中每个观测值的定和不同,因此为了填充的准确性,设置调节因子,将其表示为
(11)
式(11)中,xjk代表不同观测值的平衡成分,c代表调节因子,V代表缺失值。
通过上述过程调整后能够保证数据库内的成分数据的一致性。最后对网络数据库不完整信息填充,其表达式为
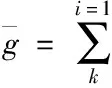
(12)

不断迭代上述步骤,直到所有的网络数据库不完整信息检测与填充完毕,以此,通过上述过程完成对网络数据库不完整信息的填充。
3 实验分析
3.1 实验准备
为验证此次研究的基于多元回归KNN的网络数据库不完整信息填充方法的有效性,进行实验对比分析,并将文献[1]提出的不同类别非完整大数据中缺失数据填充方法、文献[2]提出的分布式数据库用户丢失数据恢复重构方法与此次研究的方法进行对比。此次实验硬件平台配置为 CPU-INTEL CORE i7-8700K 3.7GHz6-Core等,软件平台基于Py Charm 利用sklearn和jupyter notebook 进行图表绘制。
此次实验研究共分为两个实验进行,在实验1中,设置网络数据库中的数据缺失率为5%,主要对比三种方法的缺失数据检测时间、缺失数据估计值准确度与网络数据库不完整信息的填充时间。在实验2中,设置网络数据库的数据缺失率为10%左右,在该实验中主要对比三种方法的缺失数据的预测误差与信息填充时间。
3.2 缺失数据检测时间
实验1中,对比基于多元回归KNN的网络数据库不完整信息填充方法与文献[1]提出的不同类别非完整大数据中缺失数据填充方法、文献[2]提出的分布式数据库用户丢失数据恢复重构方法的缺失数据检测时间,对比结果如图2所示。
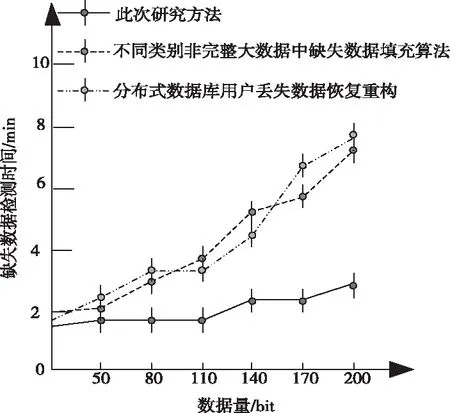
图2 缺失数据检测时间对比
分析上图可知,随着数据量的不断增加,此次研究方法与不同类别非完整大数据中缺失数据填充方法、分布式数据库用户丢失数据恢复重构方法的缺失数据检测时间也呈线性增加。经过对比可知,此次研究的检测方法较传统方法的检测时间少。
3.3 缺失数据估计值准确度
缺失数据估计值准确度的计算公式如下所示
(13)
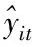
以缺失数据估计值准确度为实验指标,进行对比分析,对本文研究的基于多元回归KNN的网络数据库不完整信息填充方法与文献[1]提出的不同类别非完整大数据中缺失数据填充方法、文献[2]提出的分布式数据库用户丢失数据恢复重构方法的缺失数据估计值准确度进行对比分析,对比结果如图3所示。
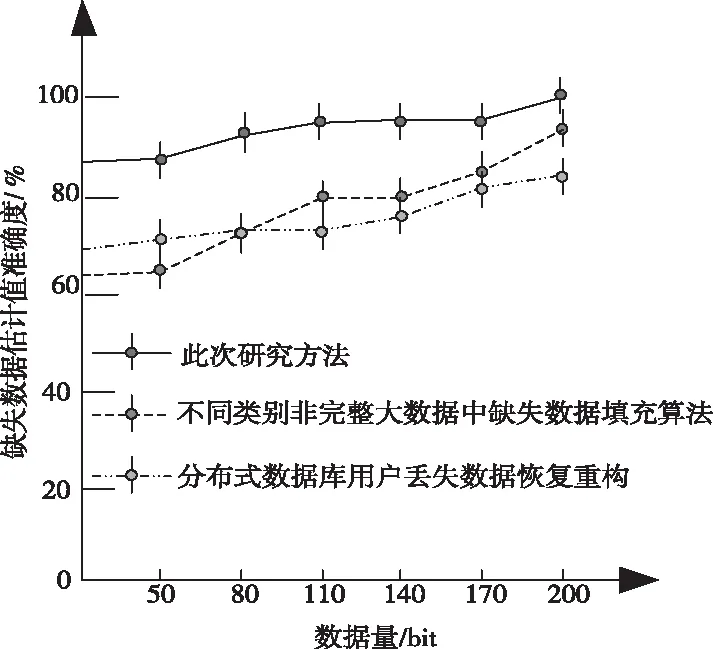
图3 缺失数据估计值准确度对比
分析上图可知,在数据量少于数据量多的情况下,此次研究的基于多元回归KNN的网络数据库不完整信息填充方法的缺失数据估计值准确度都较高,初始准确度稍低,原因是在初始分析时,辅助信息较少,随着信息量的增加,误差随之减小,并逐渐呈平衡的趋势。经过对比可知,此次研究的填充方法较传统的两种方法估计准确度高。
3.4 缺失率为5%时的不完整信息填充时间
当网络数据库的数据缺失率为5%时,对三种方法的不完整信息填充时间进行对比,对比结果如图4所示。
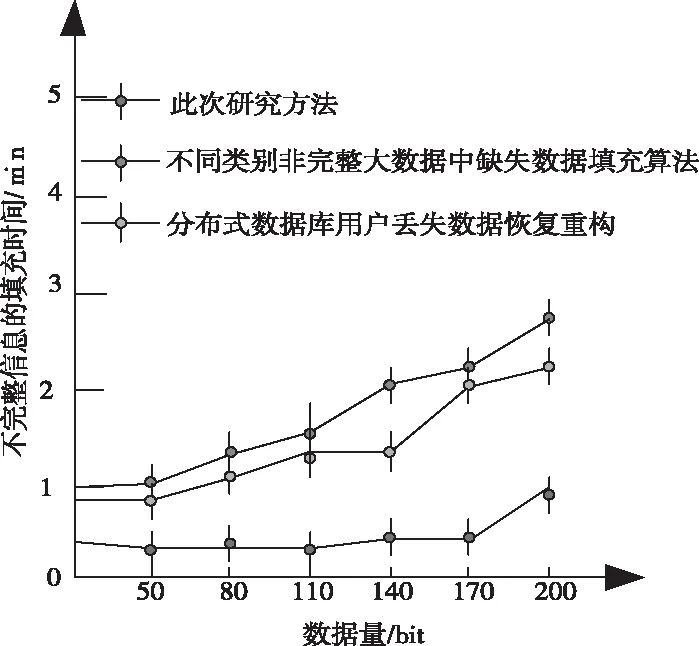
图4 缺失率为5%时不完整信息的填充时间
分析上图可知,此次研究的基于多元回归KNN的网络数据库不完整信息填充方法在情况不完整信息的填充上,花费的时间较少,对比可知,此次研究的方法比传统两种方法的不完整信息填充花费的时间少。
3.5 缺失数据的预测误差
对不同类别非完整大数据中缺失数据填充方法、分布式数据库用户丢失数据恢复重构方法与此次研究的基于多元回归KNN的网络数据库不完整信息填充方法的缺失数据的预测误差进行对比分析,对比结果如图5所示。

图5 缺失数据的预测误差
通过图5能够看出,随着确实数据量的增加,不同类别非完整大数据中缺失数据填充方法和分布式数据库用户丢失数据恢复重构方法的预测误差也随之增大,并且变化幅度较大,对比可知,没有此次研究的填充方法的预测准确度高。
3.6 缺失率为10%时的不完整信息填充时间
当网络数据库的数据缺失率为10%时,对三种方法的不完整信息填充时间进行对比,对比结果如图6所示。

图6 缺失率为10%时不完整信息的填充时间
从填充时间上对比可知,随着数据量的不断增加,三种方法的不完整信息填充时间也在不断的增长,但是可以看出,此次研究的填充方法运行时间上升幅度较小,不完整信息填充时间最短,不同类别非完整大数据中缺失数据填充方法与分布式数据库用户丢失数据恢复重构方法花费的时间都较多。
综上所述,此次研究的基于多元回归KNN的网络数据库不完整信息填充方法较传统的两种方法的缺失数据检测时间少、对缺失数据估计值准确度高、预测误差低与信息填充时间少,充分验证了此次研究方法的有效性。原因是因为此次研究的填充方法预先对网络数据库中不完整信息进行了检测与预处理,并采用多元回归KNN方法对其进行了填充,从而获得了较好的填充效果,满足填充方法设计需求。
4 结束语
本文设计了一个基于多元回归KNN的网络数据库不完整信息填充方法,该方法能够通过系数的调整有效消除缺失数据带来的噪声对填充结果的影响,更好的解决了因缺失数据噪声带来填充结果偏差大的问题,通过观察实验结果可知,此次研究的网络数据库不完整信息填充方法较传统两种填充方法填充速度快,对于网络数据库不完整信息检测花费的时间也少,证明此次研究的方法较传统方法应用效果好。
但是此次研究的方法也存在一定的不足,对缺失数据补全之后得到的重组矩阵秩的确定是不唯一的,如何找到最优的秩仍需要进一步研究,从而提高数据库不完整信息填充效果。
