基于局部离群点检测的高频数据共现聚类算法
2021-11-17周志洪夏正敏陈秀真
周志洪,马 进,夏正敏,陈秀真
(1.上海交通大学网络安全技术研究院,上海 200240;2.上海市信息安全综合管理技术研究重点实验室,上海 200240)
1 引言
高频数据就是大数据的简化形式。在高频数据集内存在大量杂乱无章的信息,也存在一些具有规律的信息,准确存储与分析这些高频数据可促进经济发展[1-3]。
离群点检测属于数据挖掘的主要方法,离群点检测负责分析目标数据集,主要找到数据集内异常数据或具有特征的数据信息[4]。叶福兰研究基于离群点检测的不确定数据流聚类算法,提升聚类算法的伸缩性[5];赵建龙等研究一种基于仿射传播的增强型流聚类算法,提升聚类效率[6]。
通过对高频数据研究发现,当高频数据中存在相同或类似数据信息时,通常存在很多和数据信息有关的数据标签同时出现,且出现概率较高,这些数据标签即为高频数据共现。针对高频数据共现,研究基于局部离群点检测的高频数据共现聚类算法,提升高频数据聚类的执行效率与准确性。
2 基于局部离群点检测的高频数据共现聚类算法
2.1 局部离群点检测算法
2.1.1 相关定义
局部离群检测算法是利用一种模糊方式判断高频数据集中是否存在异常高频数据对象,并对其实施挖掘[7]。
定义1:对象x的k距离。在高频数据集D内的任意一个正整数k,对象x的k距离由k-distance(x)代表,对象x与对象o(o∈D)间的距离由e(x,o)代表。若k-distance(x)=e(x,o),那么需要符合的条件如下:
1)最少存在k个对象o′∈D/{x},该对象到对象x的距离e(x,o′)≤e(x,o);
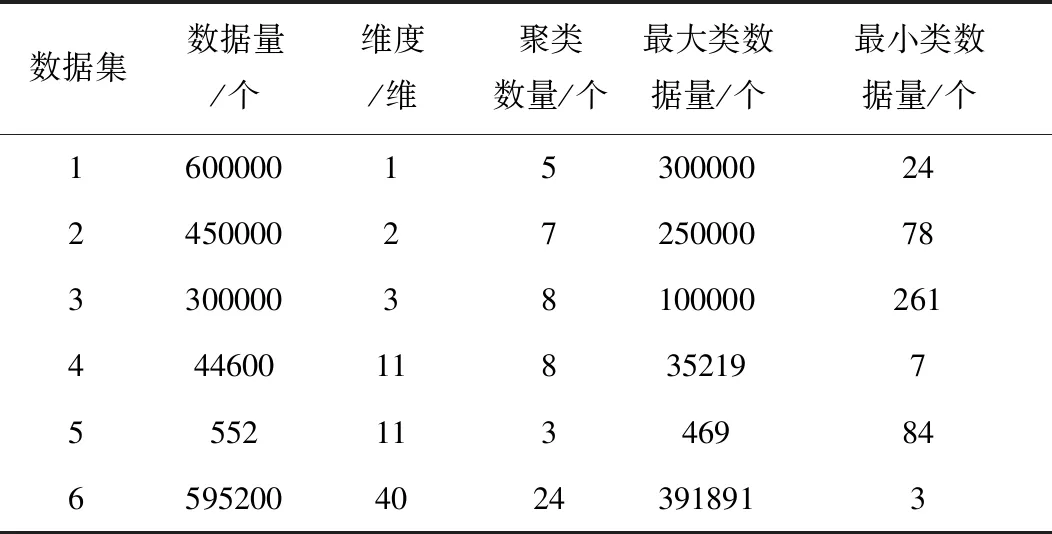
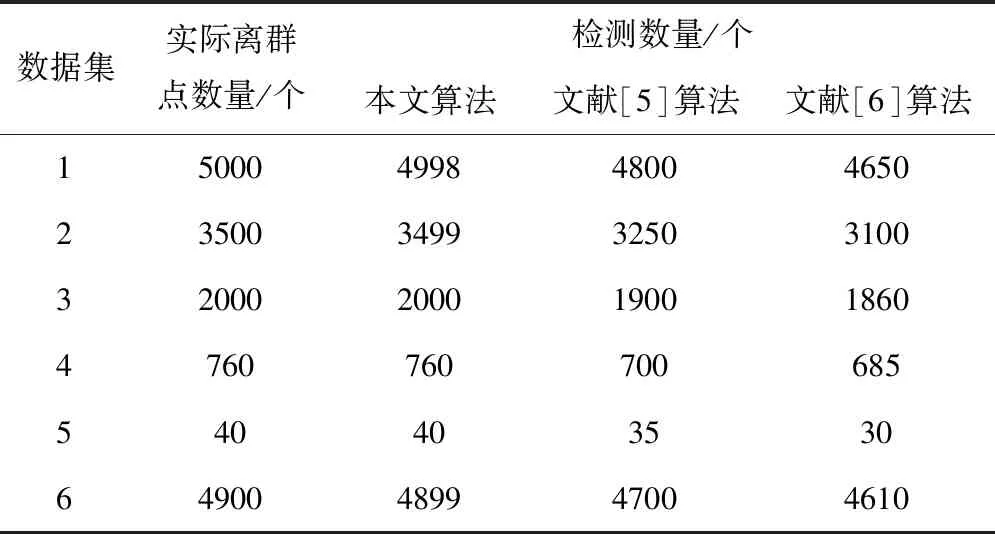
2)最多存在k-1个对象o′∈D/{x},该对象到对象x的距离e(x,o′) 定义2:对象x的k-distance(x)邻域。对象x的k-distance(x)是已知的,高频数据集D内的对象y与对象x间的距离小于k-distance(x)的全部对象集合,公式如下 Ndistan ce(x)(x) ={y∈D/{x}|e(x,y)≤k-distance(x)} (1) 定义3:对象x与对象o间的可达距离。假设k属于一个自然数,定义对象x与对象o间的可达距离公式如下 reach-distk(x,o) =max{k-distance(o),e(x,o)} (2) 根据可达距离定义可知,若x偏离o,那么x与o间的可达距离和x与o间的实际距离一致;若x与o非常接近,那么x与o间的可达距离和o的k-distance(o)一致。 定义4:对象x的局部可达密度。定义对象x的局部可达密度公式如下 (3) 式中,高频数据集内高频数据对象的总数是N。根据式(3)可知,x的MinPts个最近邻居的平均可达距离的倒数是x的局部可达密度。 定义5:对象x的局部离群因子。定义对象x的局部离群因子公式如下 (4) x的离群程度由x的局部离群因子表示。按照式(4)可知,x越偏离MinPts个邻居以及离群因子越大,那么x的局部可达密度越小以及MinPts个最近邻居的局部可达密度越大。 局部离群检测算法的输入的是高频数据集D与离群点数目n;输出的是指定的N个离群点集合。具体执行步骤如下: 步骤1:利用上述公式分别计算已给的高频数据集内的随机记录x的局部离群因子值; 2.1.2 基于可变网格划分的局部离群点检测算法 在局部离群点检测算法中引入可变网格划分,通过划分网格空间确定聚类区域,不需浪费时间搜索聚类区域,提升局部离群点检测算法的执行效率[8]。可变网格划分方法首先等间距划分高频数据空间的各维度,再合并与该维相似的区间段,最后形成网格空间。 步骤2:获取相邻区间段的相似性。等间距划分各维度后,两个相邻区间段的相似性εr由这两个相邻区间段的全部高频数据点数量比值代表,其中r=(1,2,…,k-1)。两个相邻区间段的相似性εr计算公式如下: (5) 步骤3:按照顺序对比第i维内相邻区间段的相似性εr。若阈值Ti(0≤Ti≤1)小于εr,那么代表这两个相邻区间段属于相似的;若阈值Ti(0≤Ti≤1)大于εr,那么代表这两个相邻区间段属于不相似的;完成对比后,合并相似的区间段。 步骤4:从步骤1到步骤3循环计算高频数据集各维的相似区间段,并合并相似区间段,输出网格空间。 2.1.3 设置参数 在构建网格空间过程中,各维度等间隔划分的区间段数量是k。假设d维度中存在N个高频数据对象的高频数据集,按照式(6)设置参数k,可防止网格数量跟随维度与网格划分粒度出现提升的情况,参数k设置公式如下 (6) 针对任意维度,其维度上需合并的区间段数量由Ti值确定。若采用一个固定的相似性阈值实施合并操作,便不能准确描绘高频数据集在空间的分布情况[9]。因此,对于第i维,需按照高频数据的实际分布状况决定Ti的取值,参数Ti的取值公式如下 (7) 根据式(7)可知,通过任意维度的全部相邻区间段相似性的平均值获取Ti,利用式(7)设置相似性阈值,提升合并区间段的合理性。 2.1.4 算法执行步骤 基于可变网格划分的局部离群检测算法输入的是目标高频数据集D、密度阈值MinP与离群点数量n;输出的是前n个比较大的离群因子值对象。具体执行步骤如下: 在实施局部离群点检测后的高频数据集中,经常出现不一样的数据标签记录同一个数据集的现象[11]。如果数据标签t1与数据标签t2记录同一个数据集,那么这种情况叫作t1与t2共现。若两个数据标签经常记录同一个数据集,则这两个数据标签可能存在相似的语义。利用两个数据标签一起标记同一个数据集的次数表示这两个数据标签间的相似度。两个数据标签记录同一个数据集次数与这两个数据标签的相似度成正比。 数据标签ta与数据标签tb的相似度计算公式如下 sim(ta,tb)= (8) 式中,数据标签ta与数据标签tb的相似度是sim(ta,tb);数据标签ta记录数据集ww的次数是fw,a;通过式(8)能够计算s个数据标签两两间的相似度,便能获取数据标签相似度矩阵Ts×s,Ts×s矩阵内元素的值就是式(8)内的sim(ta,tb)。 数据标签ta和通过s个数据标签聚类成的类cs的相似度计算公式如下 (9) 通过式(9)能够获取数据标签和类间的相似度,然后获取数据标签和类的相似度矩阵H1,H1矩阵内的元素就是式(9)内的sim(ta,cs)。 通过v个数据标签聚类形成的类cv与通过s个数据标签聚类形成的类cs的相似度计算公式如下 (10) 通过式(10)能够获取类和类间的相似度,然后获取类和类的相似度矩阵H2,矩阵内的元素就是式(10)内的sim(cv,cs)。 高频数据共现聚类算法的基本思想是:对高频数据集D实施局部离群点检测挖掘高频数据对象,计算挖掘后高频数据对象内数据标签t间的高频数据共现相似度sim(ta,cs),再结合层次聚类算法完成高频数据共现聚类。 为验证本文算法实施高频数据共现聚类的执行效率与准确性,以某大学的高频数据集为实验对象,从中选取6组高频数据集,共分为人工数据集与UCI(University of Californialrvine,标准测试数据集)数据集两种类型,其中数据集1-3属于人工数据集,数据集4-6属于UCI标准数据集。通过Matlab工具箱内自带的函数生成人工数据集;在http:∥archive.ics.uci.edu/ml/内获取UCI标准数据集。6组数据集的具体信息如表1所示。 表1 6组数据集的信息 利用本文算法与文献[5]算法、文献[6]算法检测6组数据集中离群点数量,文献[5]算法是基于离群点检测的不确定数据流聚类算法研究,文献[6]算法是一种基于仿射传播的增强型流聚类算法。三种算法的离群点数量检测结果如表2所示。 表2 三种算法的离群点数量检测结果 根据表2可知,在不同数据集中,本文算法对6组数据集离群点检测的数量和实际数量最大差值是2,其余两种算法检测的离群点数量与实际数量差距较大。实验证明:本文算法检测离群点数量的准确性更高。 利用本文算法与文献[5]算法、文献[6]算法对6组数据集实施高频数据共现聚类,三种算法分别用a、b、c表示,三种算法分别实施3次实验,避免随机初始化导致的误差,执行时间测试结果如表3所示。 表3 三种算法高频数据共现聚类处理的执行时间 根据表3可知,本文算法与文献[5]算法、文献[6]算法相比,本文算法对6组数据集实施3次高频数据共现聚类处理的执行时间均高于其余两种算法,原因是本文算法加入可变网格划分方法可对原始数据集实施一定程度上的约简,提升高频数据共现聚类处理的执行效率。实验证明:本文算法高频数据共现聚类的执行效率更快。 利用F-measure评价高频数据共现聚类的准确性,F-measure综合了准确率P与召回率R。F-measure的计算公式如下 (11) 其中,高频数据共现聚类是c,类标记是u。 高频数据共现聚类的总体评价指标F-measure通过加权求和所有聚类结果得到,F-measure值与高频数据共现聚类效果成正比,即F-measure值越高,聚类准确性越高,L为矩阵行数,计算公式如下 (12) 利用本文算法与与文献[5]算法、文献[6]算法对6组高频数据集实施高频数据共现聚类,三种算法分别实施3次实验,避免随机初始化导致的误差,三种算法实施高频数据共现聚类的F-measure值测试结果如表4所示。 表4 三种算法F-measure值测试结果 根据表4可知,对于6组不同数据集本文算法实施高频数据共现聚类的准确性明显高于其余两种算法。实验证明:本文算法的高频数据共现聚类效果更好。 为进一步验证本文算法的准确性,以数据集1为例,测试本文算法与文献[5]算法、文献[6]算法在不同k值与top-n作用下高频数据共现聚类的聚类精度(聚类精度=聚类到的高频数据共现数量/全部高频数据共现数量)。三种方法在不同k值作用下高频数据共现聚类的聚类精度与执行时间分别如图1与表5所示。 图1 在不同k值作用下三种方法的聚类精度 根据图1可知,随着k值的不断提升,三种算法的聚类精度均有所提高。在k值为30个时,三种算法的聚类精度均处于最高值,在k值逐渐增加时,本文算法的聚类精度明显高于其余两种算法,本文算法的聚类精度变化比较平稳,在k值大于30个后,聚类精度趋于稳定;其余两种算法的聚类精度变化幅度较大,表示文献[5]算法与文献[6]算法对k值非常敏感,聚类精度受k值影响较大。表明本文算法加入的可变网格划分方法可有效降低k值对聚类精度的影响,提升高频数据共现聚类的准确性。实验证明:在不同k值作用下,本文算法高频数据共现聚类的准确性更高。 表5 不同k值作用下三种算法的执行时间 根据表5可知,随着k值的逐渐增加,三种算法的执行时间均不断提升,本文算法的执行时间明显低于其余两种算法,原因是本文算法中加入了可变网格划分方法,能够降低时间复杂度,提升高频数据共现聚类的执行效率。实验证明:在不同k值作用下,本文算法的高频数据共现聚类的执行时间更短,有效提升高频数据共现聚类的执行效率。 研究基于局部离群点检测的高频数据共现聚类算法,利用可变网格划分的局部离群点检测算法挖掘高频数据共现对象,提升高频数据共现聚类的执行效率。该算法虽在实验中取得了很好的实验结果,但还需不断完善该算法。例如实施可变网格划分时需要计算高频数据集内的各个维度,在维度较高的情况下,该算法的计算量也相对较大,以后可以在该算法中加入降维等技术,进一步加快算法的执行效率。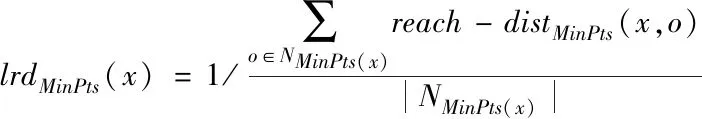

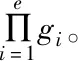
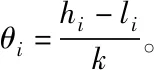

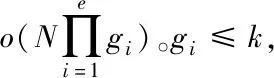



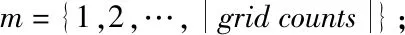
2.2 高频数据共现聚类算法



3 实验分析
3.1 离群点检测性能分析
3.2 聚类的执行效率分析

3.3 聚类的准确性分析

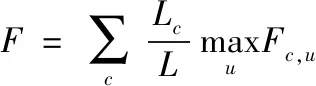

3.4 在不同k值作用下的聚类精度与执行效率分析


4 结论
