三维视频跳帧缺帧动态补偿方法仿真
2021-11-17孟凡墨
孟凡墨
(吉林师范大学,吉林 四平 136000)
1 引言
三维视频缺帧、跳帧是指在视频播放过程中存在黑屏或闪屏、卡顿不流畅等现象,极为影响视觉感官,通常会动态补偿方法来弥补缺失。跳帧、缺帧补偿作为三维视频处理的重要领域,其在视频的虚拟图像合成、视频帧率提升和慢速制造等方面都拥有广泛使用。传统补偿方法通过光流场检测完成视频输入聚类匹配,然后使用计算出的匹配数据合成中间帧图像。但因为光流场存在不稳定现象,导致三维视频缺帧补偿后效果不佳,而其它方法在现实应用中经常面临困难,基于此相关研究者提出如下解决方案。
文献[1]通过混入统计特性的高斯噪声,从而提高三维视频缺帧、跳帧补偿精准度,但因为高斯噪声混入需要大量的时间进行实现,导致该方法在补偿效率上并不理想。文献[2]提出了一种基于结构相似的帧间组稀疏表示重构算法研究,该方法首先将三维视频的结构相似度作为匹配的标准,再对其参考帧进行搜索匹配,从而生成相似块组,然后通过相似块组中关键特征实现帧间补偿。但该方法步骤过于繁琐,需要消耗大量的人力、物力资源和时间。文献[3]提出了一种基于特征匹配与运动补偿的视频稳像算法,通过长度不变的SURE对视频进行特征提取,并计算描述符,再引入邻近匹配算法获得匹配点,从而提高对视频帧间的补偿效率。但SURE算法在特征提取的过程中,容易将重要特征当做冗余干扰并实行剔除,导致最后的补偿不够完整,三维视频效果差强人意。
针对上述问题本文提出了一种基于帧间投影的补偿方法,通过对三维视频进行投影,有效提高补偿过程的完整性。根据投影结果获得单独两种的波形,并利用深度卷积神经网络对两个独立波形进行训练,有效缩短视频补偿时间,从而实现三维视频中的跳帧、缺帧进行补偿。实验结果证明,相较于传统方法,本文提出的方法在补偿三维视频帧间的效率上较为突出,并且不会出现补偿遗漏以及补偿不完整问题。
2 三维视频跳帧缺帧动态补偿方法
2.1 三维视频帧间投影
三维视频跳帧、缺帧的实质就是视频帧间的丢失或跳过[4]。预算三维视频帧间的平移运动算法有很多种,比如代表点比较法、匹配算法、边沿识别算法等。本文提出的帧间投影算法,会依据所获得的三维视频总体分布规律来求出当前帧相对于参考帧在水平方向与垂直方向的运动矢量,它拥有计算速度快、效率高等优点。
对于三维视频输入预处理的所有帧来说,通过预处理后,将其帧间运动投影成两个单独的波形,其投影方法表示为

(1)

(2)
式中,Gk(i)和Gk(j)分别代表为k帧视频第j列和第i行,Gk(i,j)表示第k帧视频上的(i,j)的位置。经过分别匹配行、列的投影矢量,就能求得在水平方向和垂直方向的运动矢量。因为投影匹配算法可以把三维视频转化为两个一维的矢量,因此很大程度上提高了计算效率。
分别将参考视频和当前视频分成若干的子区域,当子区域划分较少时,会省略旋转运动,使用投影匹配算法可以精准的求出子区域在垂直方向和水平方向的局部运动矢量。
如何确准子区域的大小是一个非常重要的问题。如果区域划分的越多,理论上最终实现的视频旋转补偿精准度就越高,如果区域选择过大,那么区域的旋转运动则不能忽略,同时会缺失一些局部运动信息[5-6]。考虑到现实的应用,对一些分辨率为650*490像素的三维视频来说,能够选择子区域的大小为6*65像素,即将一帧三维视频分成25个子区域,对于分辨率为353*289像素的三维视频来说,能偶分成17个子区域,子区域的大小则选为51*65像素。
因为三维视频上存在的背景和景物不同,区分以后,有的区域会产生不明显变化,不具有足够的信息量,尤其是航摄三维视频[7]。比如,某一个区域只存在帧间单一的景物,出现该区域,能够使用各子区域运动矢量的均衡值作为该区域的运动矢量[8]。
2.2 视频的仿射变换
三维视频几何变换就是视频中点和点之间的空间投影关系,这属于初始图像和其变形之后图像中所有各点间的投影关系函数,可表示为
[x,y]=[X(u,v),Y(u,v)]
(3)
或
[u,v]=[U(x,y),V(x,y)]
(4)
式中,[u,v]代表输入三维视频中像素的坐标,[x,y]代表输出视频中像素的坐标。X、Y、U、V代表唯一确准的空间变换函数,就是它们定义了输出视频和输入视频中的全部点间几何对应关系,X、Y把输入投影到输出,叫做向前投影,U、V把输出视频投影到输入,叫做逆向投影。
仿射变换是一种常见是平面投影方法,但其转化方式比较特殊,表达公式为

(5)
逆变转化能够限制三维视频的旋转、平移与基础的变形,减少后续补偿的干扰向量。
2.3 深度卷积神经网络设计
相对于传统的深度神经网络,构建用于三维视频跳帧、缺帧动态补偿的深度卷积神经网络需要对下述三个问题进行考虑:
1)和仅为目标分类概率的目网络不同,本文的任务是为了将输入视频分辨率和输出视频分辨率进行相同的匹配,从而融合出完整一帧[9-10]。
2)考虑到三维视频中使用场景的视频长度比,经常会各不相同的情况,用于三维视频中跳帧、缺帧补偿的卷积神经网络,需要拥有处理不同长度视频的能力,提升方法适用性。
3)设计出的卷积神经网路需要拥有视频细节处理能力,并且还要考虑在视频中帧数较多的情况下,如何使用优化卷积神经网络降低帧分散现象,使得卷积神经网络能够对帧间进行优质的训练,提升跳帧、缺帧补偿效果[11-12]。
本文提出的三维视频跳帧、缺帧动态补偿深度卷积神经网络总体构造如图1所示。

图1 深度卷积神经网络结构示意图
对于给定的一幅图像,第1次卷积选取5个卷积核,经过遍历输入图像,经过采样处理,得到下采样特征图,下采样层一般采用均值处理,每6个像素进行平均;第2个卷积层再次使用卷积核,再经过2次卷积处理后,和最终的输出层实现全连接。
利用初始卷积神经网络构建反卷积模块,通过激活卷积层和函数层进行三次重复交替,训练模块最后在融入池化层内组合。本文深度卷积层的设定跨步尺寸和内部边距为1,3,1。启用函数层使用参数修正现单元作为激活函数,池化层的预感跨步为1,尺寸为3。
2.4 训练及跳帧缺帧补偿
如上文所述,本文可以使用现有的三维视频对上节建造的深度卷积神经网络进行训练,并且去掉了人工标注环节,在节省了大量时间的同时,减少人力物力资源的浪费。因为三维视频中含有时序一致性,就是在短时间内可以对拍摄物体与摄像机进行快速运动,所以建造的深度卷积神经网络较为适合对本文三维视频进行训练。
本文使用Durian来建造训练样本,其中原始数据是KITTI。KITTI是三维视频中安放在汽车上的摄影机,它是公开的数据集,可以对自动驾驶、像视觉里程计算、Stereo、光流场计算和图像分割等进行应用。相较于KITTI和Sintel数据,本文只使用起始的三维视频数据对训练样本进行提取。
KITTI数据集包含58个视频序列,总计15942帧图像。在全部序列中,使用三帧连续的图像建造为一个训练样本,第一帧和第三帧当做输入视频,第二帧则表示为运动插值视频的真值。并且对事项中包含上下翻转、左右翻转迹象的方式通过训练来构建新的样本,同时该样本一共生成了123517个训练样本。对三维视频,还是使用65个视频序列进行采集,序列中含有5891帧图像。使用和KITTI数据类似的方法建造36541个训练样本。对KITTI数据的输入图像采样为280*248,对Sintel数据,使用的视频尺寸为275*137。
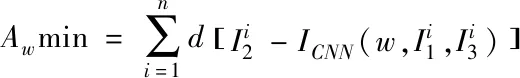
(6)

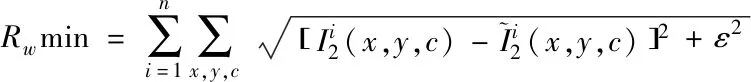
(7)
式中ε为0.2。
3 仿真研究
3.1 实验环境
仿真环境为:操作系统为Windows7Ultimate,处理器为Intel T6400,内存为2GB,仿真软件为Matlab7.8a。
3.2 不同方法三维视频补偿效率
为了更好的检验本文方法的性能,采用文献[1]的方法和本文方法进行比较,因为MPEG-1输出三维视频码率是固定的1.3MBIT/s,所以标准的MPEG-1三维视频编码器拥有码率控制能力。在进行视频补偿仿真过程中,取消了码率控制,并定义量化参数,对IP于B帧都固定为Q=30,其中,运动估值使用的是全搜索算法,下表给出实验比较结果。

表1 不同方法的对比结果
从表1能够看出本文方法较比文献[1]在三维视频补偿效率上要高出很多,分析其原因,本文方法使用了帧间投影算法,通过简单的投影就可以节省大量时间,较比文献[1]通过特征提取来分类三维视频要快。
3.3 三维视频跳帧缺帧动态补偿完整性
首先为了检验方法补偿完整性,将本文方法于文献[2]、文献[3]的方法进行对比,使用常见的Comer Planes与Punctured Sphere模型,如图2所示。

图2 实验中使用的两种模型
求三维视频模型的缺帧、跳帧补偿误差结果,对比结果如图3所示。其中曲线InvErr是文献[2]的补偿结果。
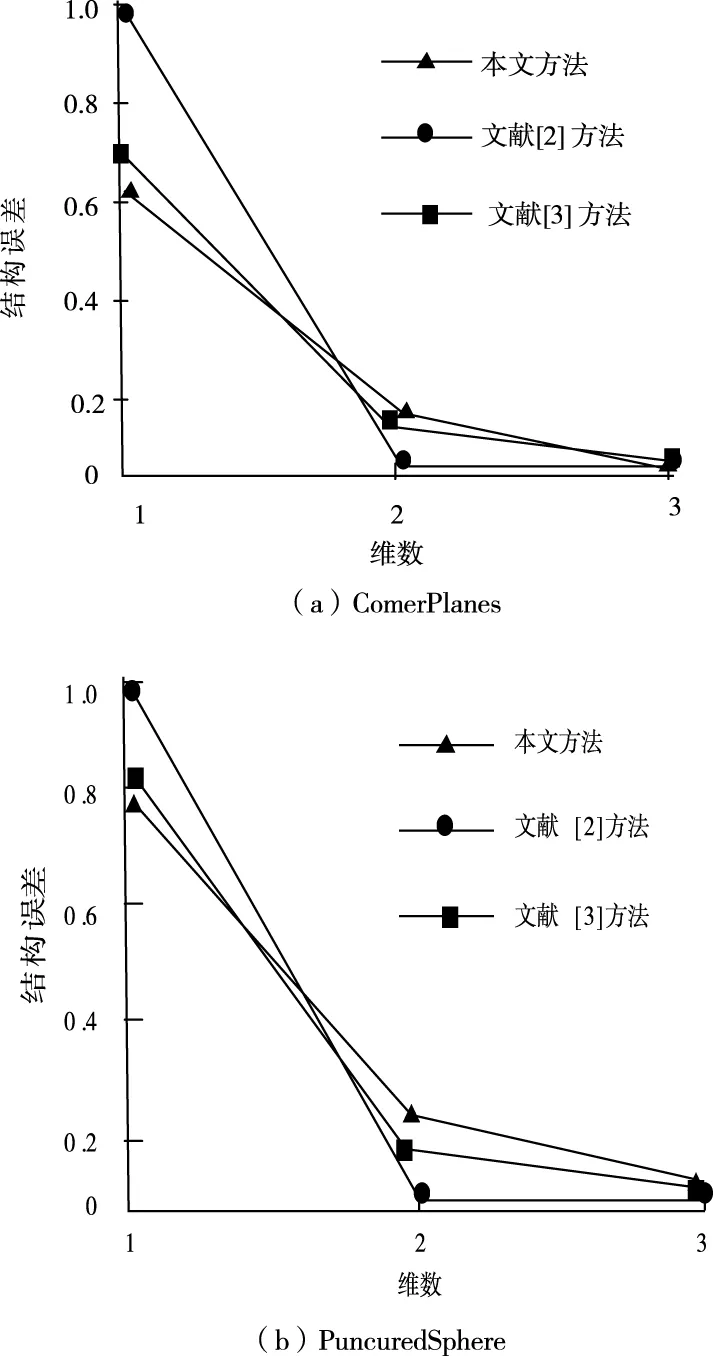
图3 不同方法相同模型的误差图
从图3能够看出,其中本文的结果对于帧间误差不大,这代表邻近图能够用来更好的模拟高维数据低维流形结构。文献[2]、文献[3]中因为邻近图使用的顺序为搜索策略,留下的是完全满足条件的数据点,但满足部分条件的有效点被删除,所以比较降维前后邻近图中相似性时会出现一定的偏差,使补偿误差大幅度增加,三维视频补偿后视觉效果差。
然后构建最优质的映射矩阵,考虑到三维视频和数据在时间上存有联系,同时也是为了尽量保持三维视频的流行结构,使用镜头样本来获取映射矩阵。首先来获得三维视频镜头的最优质维度数,建造邻近结构矩阵。通过在实验中对不同方法进行降维处理,获得了降维前后的流行结构误差图,如图4所示。

图4 两种方法的完整性对比
通过图4能够看出,本文方法比较文献[2]方法的补偿完整度更高,主要原因是,深度卷积神经网络在分类两种波形时拥有具体的分类形式,不会出现检测遗漏波形,所以本文补偿三维视频的跳帧、缺帧时不会出现传统方法的遗漏现象,从而更加完整的补偿三维视频的帧间运动。
从上述可以看出本文提出的方法在三维视频跳帧、缺帧方面拥有非常好的性能,并且效率更高。
4 结论
为了解决三维视频缺帧、跳帧补偿的效率过慢,补偿不完整问题,提出了一种通过帧间投影和深度卷积神经网络的补偿方法。通过仿真结果证明,所提方法具有良好应用性能,可以在该领域得以广泛应用。但三维视频帧间补偿是一种非常复杂的程序,需要涉及到很多种学科问题,由于作者的水平限制,研究时间较短,虽然在三维视频的跳帧、缺帧补偿方面小有成就,但以下问题仍然没有做到满意:
1)动态补偿方法还没有成熟。动态补偿可以从理论上解释三维视频帧间治理、视频资源提取思想,但针对三维视频动态补偿模式研究还不够成熟,会限制实际使用。
2)如何改进算法使其进一步提高三维视频跳帧缺帧补偿性能也是未来需要研究的方向。
3)本文中的补偿研究大部分都是围绕着跳帧、缺帧进行的,但三维视频中出现的问题不止是跳帧和缺帧,还有很多的问题等待的广大学者的研究。
