融合信任关系的联合矩阵分解推荐算法仿真
2021-11-17余文森吴清寿
郭 磊,余文森,吴清寿
(1. 武夷学院数学与计算机学院,福建 武夷山 354300;2. 福建省认知计算与智能信息处理重点实验室,福建 武夷山 354300)
1 引言
互联网的发展极大的提高了人们获取信息、交互信息的效率,但也出现了严重的信息过载的问题。推荐算法为人们高效的获取所需网络信息提供了有效的解决方法而受到广泛关注[1-3]。传统的推荐技术主要包含基于内容的推荐技术[4]和协同过滤推荐技术[5],但这些技术主要针对单个用户行为做分析,解决数据稀疏和冷启动的问题效果有限。
近年来,一些学者利用社交网络中用户之间的信任关系作为重要依据进行推荐[6],希望能解决推荐系统中数据稀疏的问题,也取得了一定的成果。Ma等人提出融入信任网络结构和用户-项目评分的SoRec[7]; Jamal对SoRec进行补充,提出了SocialMF[8];郭磊、马军等在信任关系的基础上,加上兴趣偏好,并通过共享特征空间建模,提出了StrengthMF[9],赵海燕等人[10]定义了基于信任出入度的三种信任度量方法,并将其融入社交推荐模型中,取得了较好的推荐效果。但这些算法只是依据项目评分矩阵或者关注、被关注关系计算用户信任,局限性明显。
为了进一步提升推荐算法性能,部分学者研究通过社交网络中的辅助信息,如用户行为、标签等分析用户信任。如Tang[11]等将用户决策过程中受好友影响的因素考虑其中,提出了著名的LOCABAL算法;余永红等[12]研究不同领域的的社交信任关系与社交地位,提出了一种融合用户社会地位信息的矩阵分解推荐算法;潘一腾等[13]在SocialMF算法的基础上,提出了信任关系隐含相似度,并基于评分和社交关系,提出了SocialIT算法; jiang等[14]通过微博发文、转发等行为中计算用户爱好与影响力,并以此计算用户信任关系,提出了contextMF推荐算法。然而,以上研究主要采用社交关系进行信任分析,由于社交关系和评分数据存在人为因素产生的噪声,分析精度受一定影响,以上算法均未充分挖掘社交行为对信任分析的作用,而社交行为更能体现用户真实信任关系,此外,以上算法均未考虑随时间变化,用户偏好改变的问题。
针对以上问题,本文提出了一种基于信任机制和社交行为的联合矩阵分解社会化推荐算法(Joint Matrix Factorization social recommendation Algorithm Based on Trust Mechanism and Social Behavior, TMS-CMF),该算法的优势在于:
1)结合用户网络行为与社交关系,从显示信任与隐式信任两个维度构建用户社交信任度矩阵。其中显示信任从局部和全局两个方面对用户信任度进行度量,隐式信任主要考虑用户传递信任因素,该方法能够有效缓解数据稀疏性问题。
2)为更准确反应用户偏好随时间变化,给出了结合社交行为的时间增强”用户-项目”关注矩阵。通过项目关注度对项目关联关系进行度量。
3)基于联合矩阵分解提出了本文的基于信任机制和社交行为的联合矩阵分解社会化推荐算法。
2 矩阵分解模型
2.1 问题定义
在推荐系统中包含有N个用户组成的用户集合U={u1,u2,u3,…,un}和M个项目组成的项目集合S={s1,s2,s3,…sn}。用户对项目评分的数据矩阵用R=[rij]n×m表示,如果用户u有对项目s进行评分,则rui表示对应评分值,rui=0则表示用户u对项目s未评分。在社交网络中,每个用户均存在若干好友,用矩阵T=[tij]n×n表示用户之间的社交好友关系,tuv表示用户间的信任强度,若tuv=0则表示用户u与用户v没有社交关系。
2.2 矩阵分解模型
由于矩阵R具有严重的稀疏性,为了预测其中的缺失值,矩阵分解模型采用降维的方法把高阶评分矩阵Rn×m分解为两个低维矩阵P和Q,如式(1)所示
R≈PTQ
(1)


(2)

3 社交信任计算算法
基于信任的推荐算法对解决冷启动和数据稀疏问题有较好的效果,但信任值的计算是研究重点,本文结合社交行为等辅助信息,提出了多维度的信任计算方法。
3.1 显示信任度计算3.1. 1 局部信任度计算
局部信任具有非对称、差异化的特点,现有算法大都通过对评分矩阵和社交关系挖掘信息关系,效果不佳,本文结合社交行为,计算局部信任度。
文献[15]的研究认为,社交行为能反映用户更本质的信任关系,算法通过对回复、转发行为的分析来计算用户局部信任度。通常认为,同等条件下,用户交互行为的频率可以较客观反映他们之间的信任度,因此,通过对一定时间范围内的回复频率与转发频率对用户局部信任度进行度量,计算公式如式(3)与(4)所示
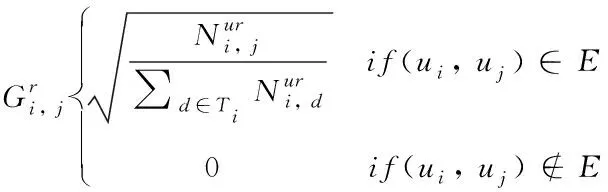
(3)

(4)


(5)
由于用户的交互行为随时间变化较大,式(5)只能够反应一定时间内用户信息关系,本文称它为静态局部信任度。
为避免部分用户在一段时间内网络行为较少导致缺少数据而难以计算周期局部信任度的情况,本算法采用了一种基于用户社会联系公共好友数的局部信任度量算法,一般认为,用户间公共好友数越高,信任度则越高,因此,计算公式如式(6)

(6)

综合两种局部信任度,得到最终局部信任度

(7)
3.1. 2 全局信任度计算
由文献[16]可知,全局信任度反映用户在整个社交网络中的影响力,受越多人信任的用户,全局信任度就越高。本文利用社交网络中节点出入度结构特征定义全局信任度

(8)
其中Idi表示用户ui的入度,Odi表示用户ui的出度。
3.1. 3 显示信任度计算
将局部信任度与全局信任度合并,就可以得到直接信任矩阵,如下
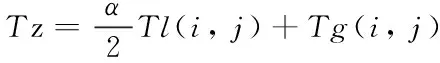
(9)
其中,参数α用于调整局部信任度和全局信任度对推荐算法的影响。
3.2 隐式信任度计算
以上方法仅考虑直接信任的情况,得到的信任矩阵具有较大的稀疏性。考虑到信任存在传递性,间接信任的计算能够有效缓解稀疏性的问题。
两个用户的信任传递过程中通常会同时存在多条路径,大量研究采用计算二者之间的最短路径信任传递值来计算其间接信任值,忽略了其它路径带来的影响。本文整合多条路径传递特性,计算用户间的隐式信任度,计算模型为
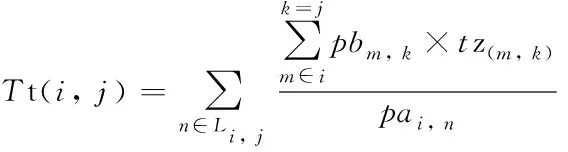
(10)
在式(10)中,Lu, v表示用户ui到用户uj信任传递路径上的用户集合;pai, n表示用户ui到用户un的传递路径总长度;pbi, n表示ui到un各分支路径长度。
该模型可以较全面计算间接信任,但对明星用户或者故意刷关注的情况处理效果不佳,故引入权重惩罚来避免数值虚高的情况。本文使用信息熵来对用户行为进行分析,确定用户信任质量,具体表达式为

(11)
其中,M(j)表示用户uj所有历史交互的用户集合,p(m)表达式为

(12)
#|um|表示与用户um有过历史交互的用户数,#|U|表示所有用户数。
通过信息熵对Tt(i,j)进行一定权重惩罚,就得到新的隐式信任度计算模型

(13)
3.3 信任矩阵构建
综合前两节所得的显示信任度与隐式信任度,可搭建信任矩阵,其形式为
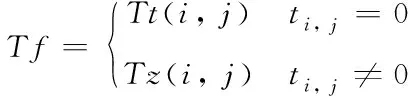
(14)
通过采用隐式信任度对信任矩阵进行填补,可有效缓解信任矩阵稀疏性的问题。
4 社会化推荐模型
“用户-项目”矩阵R不能反映用户随时间推移,对项目的关注程度,也不能反映当前项目在所有项目中的关注度,因此,对关注矩阵进行时间增强有利于提升真实反映用户偏好,对项目关注度评价有利于突出用户感兴趣程度较高的项目。
4.1 带时间增强的“用户-项目”关注矩阵
一般性认为,若用户较长时间未对项目进行回复或者转发,则认为用户对项目的关注程度下降。令tij为用户ui对项目sj最后一次交互发生时间,ti,max和ti,min分别是用户ui在时间范围[ts,te]中的最大值和最小值。定义用户对项目偏好系数
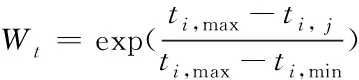
(15)
利用偏好系数Wt对关注矩阵R进行增强,如下
RT=R·Wt
(16)
其中,·是Hadamard内积。
4.2 项目关注度
项目关注度主要是评价某项目在所有项目中的关注程度,项目关注程度越高,说明用户对该项目感兴趣的程度越大。根据文献[17]的研究表明,项目关注度与浏览过该项目的用户数量相关,依此定义项目关注度

(17)
其中,|Nq|表示有对项目q评分的用户数,V表示所有项目的集合。
4.3 社会化推荐模型
根据用户社交行为计算得到用户信任度,通过时间增强对用户偏好情况进行修正,通过项目关注度从全局角度对项目进行修正,提出了基于信任机制和社交行为的联合矩阵分解社会化推荐算法(TMS-CMF)。首先对时间增强修正过的关注矩阵RT进行矩阵分解,得到用户隐含特征矩阵P={p1,p2,p3,…,pn}和项目隐含特征矩阵Q={q1,q2,q3,…,qn},通过最小化损失函数得到式(13)
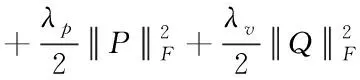
(18)

对社交信任矩阵Tf进行分解,可以得到信任者特征矩阵V={v1,v2,v3,…,vn}和被信任者特征矩阵Z={z1,z2,z3,…,zn},该模型如式所示
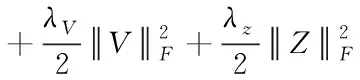
(19)
综上,得到TMS-CMF推荐算法的数学模型
f(P,V,Q,Z)=fs(P,Q)+βft(V,Z)+
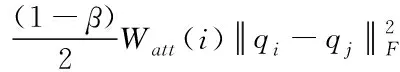
(20)
其中β是信任因子,取值[0, 1],λr是正则化参数。采用随机梯度下降法优化式(15)可得最优解。
5 实验结果与分析
为了验证本文提出的TMS-CMF算法的性能,采用去哪儿网数据集进行测试,设计了3组实验,与4种具有代表性的社会化推荐算法从不同角度进行对比分析。
5.1 数据集
实验使用Python爬虫程序从知乎抓取2018年12月到2019年12月数据,包含ID、帖子列表、评论信息、发帖时间等。用户和项目采用“关注”关系进行连接,用户之间相互关注则认为他们是好友关系,转发、点赞等行为表示存在信任关系。其中去除了关注项目数量小于5的用户,具体如表1 所示。
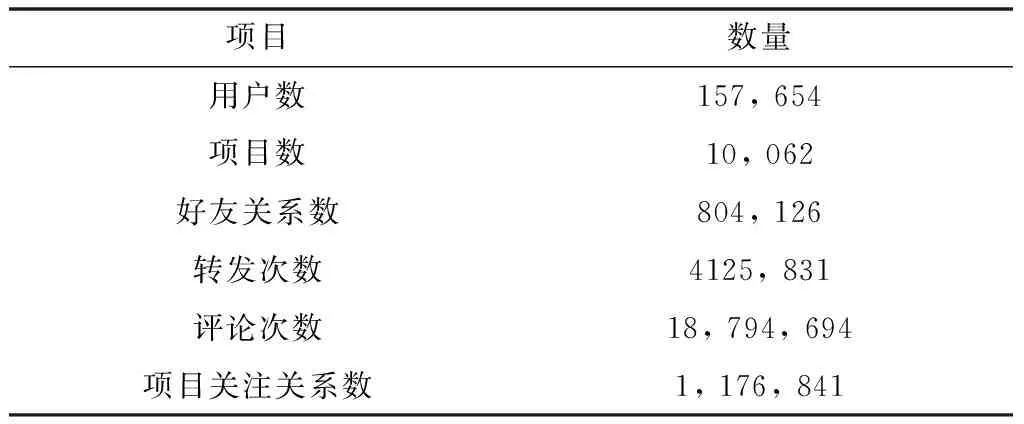
表1 知乎数据集统计情况
5.2 对比算法
为了比较本文提出的TMS-CMF算法的效果,选取了4种算法进行比较。
SocialMF[8]:利用直接社交关系对用户特征矩阵进行优化,综合好友信息与信任机制。
ContextMF[14]:综合社交关系与用户偏好的推荐方法。
TrustMF[18]:将用户映射为信任者与被信任者两个特征。对社交矩阵与评分矩阵进行分解。
SRANS[19]:结合社交信息构建自适应邻居集进行预测与推荐。
5.3 评价标准
实验采用5-折交叉验证法,将以上2种数据集随机分为20次,每次使用其中80%为训练集,剩下20%为测试集,将20次评价结果取平均值做为最终评价数据。
为验证TMS-CMF算法的有效性,本文进行了四类实验,第一类实验主要验证参数α的有效性,第二类实验验证在不同特征向量维度下算法的推荐效果,第三类为在不同比例训练集下的推荐精度,第四类为Top-K推荐能力测试。
为了评价算法性能,本文采用均方根误差(root mean squared error, RMSE)和平均绝对误差(mean absolute error, MAE)作为度量标准,它是针对评分预测常用的度量标准之一,计算公式如下

(21)

(22)
其中N是测试集评分项的总个数,Ri, j表示真实评分值,i, j是预测评分值。
本文采用Precision@K作为度量标准对算法推荐能力进行评价,该指标广泛应用于Top-K指标的实验比较,其反应在所有预测为正的样本中真实为正的样本的概率,可以从推荐精确率角度评价推荐结果与真实结果差异。定义如下
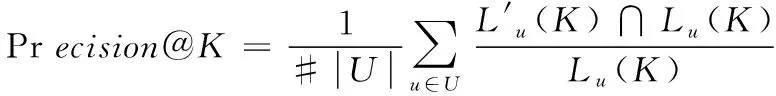
(23)
其中Lu(K)模型预测用户的K维项目推荐结果的集合,L′u(K)是真实的用户K维推荐结果集合。
5.4 实验结果分析
5.4. 1 参数设置的影响
在TMS-CMF算法中,参数β控制了信任关系的影响程度。β=0则算法不依赖信任关系计算,仅考虑项目关注度,β→1则算法高度依赖信任关系进行推荐,不考虑项目关注度。对k=10, 80%测试数据集测试参数β对算法性能影响,具体实验如图1所示。
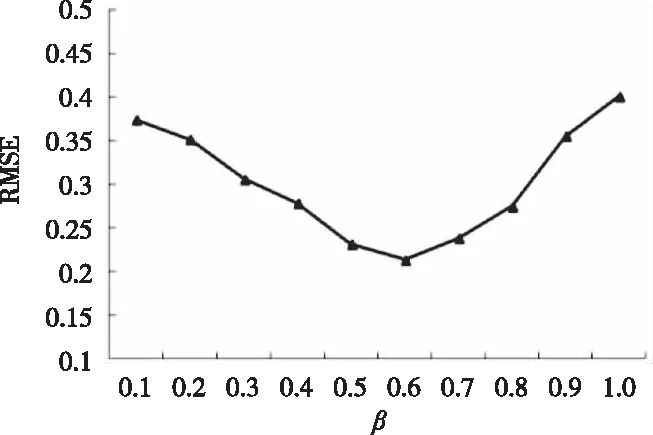
图1 参数β影响
5.4. 2 不同特征向量维度下的实验分析
实验抽取“用户-项目”关注矩阵中的80%作为训练集, 20%作为测试集,分别设置潜在特征维度k=10和k=20,实验过程独立重复5次,取平均值为最终结果。实验参数设置如表2所示。

表2 参数设置值
实验结果表3所示。

表3 维度分别为10和20的实验结果
实验表明,本文的TMS-CMF算法与其四个算法相比较,在RMSE值和MAE值上都有一定的提升,说明在社交信息的基础上融合社交行为可以进一步提升推荐算法的预测精度。
5.4. 3 不同比例训练集度的实验分析
为测试不同比例训练集下的算法效果,将训练集比例设置为20%到80%,图2给出了在k=10的时候的实验结果。
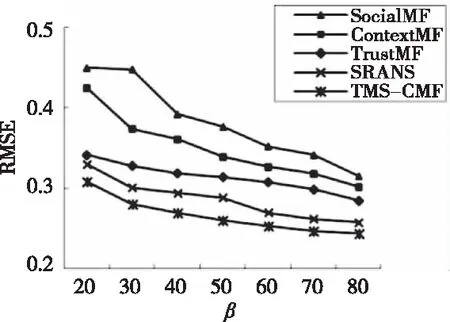
图2 不同评分稀疏度对比
图2可知,测试集中TMS-CMF的RMSE误差明显小于其算法,尤其是在矩阵非常稀疏的情况下,实验表明TMS-CMF算法能够通过社交行为判断获取不错的推荐准确度,明显优于其它算法。
5.4. 4 Top-K推荐实验分析
实验参数设置不变的情况下,在20%测试数据集上进行Top-K推荐能力测试,图3是不同推荐列表维度K的Precision@K的指标变化。
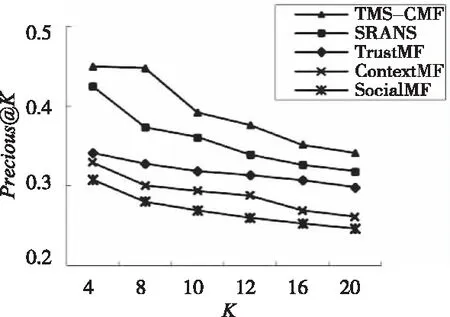
图3 Top-K推荐能力比较
由图3可知, TMS-CMF算法在Top-K的推荐准确度上有明显优势。
通过以上三个实验可知,结合社交行为的TMS-CMF算法在推荐精度和Top-K推荐能力方面比其四个算法由一定优势,其中SocialMF和ContextMF均通过社交关系和评分矩阵进行计算,实验证明社交关系能够有效提升推荐效果,而TrustMF对考虑了隐式的信任关系,对算法的稀疏性与推荐效果均有较好的改善;本算法对社交关系特征进行更深入挖掘,并对信任矩阵进行多维度纠正,进一步提升了推荐的效果
6 结束语
本文提出了一种结合社交行为与项目关注度的联合矩阵分解社会化推荐算法,通过矩阵分解模型对信任数据进行分解计算特征模型,在此基础上,结合用户社交行为,综合显示信任度与隐式信任度,构建用户信任矩阵;通过对项目关注度的计算,得到基于信任机制和社交行为的联合矩阵分解社会化推荐模型。实验结果表明,本文算法在推荐精度、Top-K推荐能力等明显优于其算法,在后续的工作中,将继续研究如何把标签、地理位置等情景信息融合本文模型,以期进一步提高推荐算法准确度。
