基于改进遗传算法的回归测试用例优先级排序
2021-11-17刘音
刘 音
(北京交通大学海滨学院,河北 黄骅 061199)
1 引言
各种程序系统飞速发展,而其中的回归测试是修改旧代码后,重新测试以确保修改没有引入新的错误或者是致使其它代码出现错误[1]。此过程是软件生命周期内的一个重要组成部分,在整个软件的测试过程内,占有比较大的工作量比重,在进行软件开发的各个阶段都要完成多次回归测试。在以快速迭代的开发之中,新版本的连续发布致使回归测试非常频繁,在终端的编程方法内,更是要求每天都采用若干次的回归测试[2]。所以,为了在给定的进度以及预算下,最大程度上执行效率和有效的回归测试,要利用测试用例进行维护,且选择一定策略对应回归测试包[3]。但是,现阶段传统方法在进行回归测试用例优先级排序时,测试效果较差,且执行效率低,不能够满足实际要求,所以该项技术一直是国内外研究学者的重要挑战。
为此本文提出一种基于改进遗传算法的回归测试用例优先级排序方法,该方法是在传统的遗传算法上引入禁忌算法,通过禁忌方法的记忆能力强优点,在可控范围内择优选取,淘汰劣质个体,同时基于改进遗传算法具有较强的搜索能力,能够有效甄别优质活劣质个体,然后将择优选取的个体代替劣质个体。在回归测试用例优先级排序中,考虑时间和测试成本因素,通常将多元化目标函数运用到用例优先的排序结果评价中,通过时间以及覆盖的角度进行考察,利用有效执行时间以及平均分支覆盖率两个目标来函数评价,该方法执行时间短,平均分支的覆盖率大,所以该序列优良。
2 改进遗传算法分析
2.1 遗传算法原理
通过自然选择与遗传理论作为基本条件,结合群体中染色体任意信息交换机制和生物进化过程内适者生存规则,诞生的搜索方法[4]。
算法具体过程如图1所示。

图1 遗传方法流程图
2.2 改进的遗传方法
在该方法内交配是随机的,不过该随机化杂交方法主要是在初始阶段的寻优方面,需要保持多样化状态,但是在后期的进化方面,大量的个体集中在某一极点上,很容易导致近亲繁衍,致使个体的差异性出现类似的情况,通常获取最佳的局部解所产生的测试用例不能够达到满意的覆盖率。
所以,若使用其它方法来对该情况完成改进。因此本文加入禁忌搜索,利用该方法的较强记忆能力,在规定范围内用优质个体替代劣质个体,完成个体最优转化。遗传方法就有了禁忌方法局部的超强搜索能力,增强了生成最佳解的概率,具体流程如下所示[5]:
步骤一:初始化的参数;种群Pop、禁忌表的长度L、种群大小PopSize。
步骤二:选择操作种群内的个体。
步骤三:利用自适应的变异和自适应交叉来操作种群内的个体。
步骤四:大范围转移VB已经淘汰的个体,且利用生成的新个体来替代被淘汰的个体。
步骤五:生成新一代种群,然后转移到步骤二中。
2.3 禁忌搜索的模块设计
两个个体之间的相似度利用S代表,具体公式如下

(1)
式(1)中,ai表示禁忌搜索中最优点值,aj表示禁忌搜索中参考值。以任意一点当成中心球体,然后以球体内非中心点的任意一点称其邻居[6]。
将禁忌搜索方法加入遗传方法内,使那些利用禁忌检测的个体,被称之为新个体进行接收,同时导致那些有效的基因缺失,不过适应度低于父代个体,就会被禁忌掉。此外,导致那些有效的基因、不过适应度低的个体,具有更多机会参加变异与交叉,以此来避免或者是延缓收敛的情况,
1)选择方式与邻域解集合的大小,对算法的参数性能有很大的影响,目前解领域内将会做最佳选择,如果选择过大,那么计算量也比较大,反之,如果选择过少,那么出现优质解概率,则会变小。因此生成领域的方式,主要是以目前解x来作为中心,然后在利用R来作为半径,生成邻域,具体公式为:
Φ={xx′-x≤R}
(2)
式(2)中:x′代表目前解x任意产生的离散化邻域解。
2)在进行遗传方法的进化过程内,每代完成变异或者较差以后[8],将低于γ的水平个体进行淘汰,把这些淘汰个体设置成ai{ai,a2,…,an},采用禁忌搜索方法完成替代搜索,然后在其邻域附近搜素,其步骤如下所示:
步骤一:对一个解Φnow=ai以及禁忌表进行数据预处理。
步骤二:在β内选择最优的个体Best,且f(Best)>(fΦnow)同时S>ε时,Φnow=Best,Best加入禁忌表L,反之,如果Best∉L,Φnow=Best,要修改禁忌表L。
步骤三:如果满足条件,则终止搜索,反之,需要转移至步骤二中。
2.4 遗传模块设计
具体的改进遗传方法3个基本算子,加入精英保留形式,改进算子具体方法如下所示[9]:
1)算子选取
对适者生存规则进行选择操作,保证种群内个体的分布。采用每一个个体的适应值对群体内最差的个体适应度值相减,将此值作为选择个体的标准。
该方法要优于传统轮盘赌的方式,致使最佳个体被选择之后,显著增加变异和交叉的概率,这样最差的个体,会失去遗传机会,以及整体的收敛速度也会快速增加,具体的概率计算选取方式如下
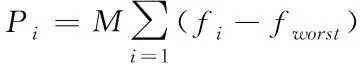
(3)
式(3)中:fi代表被选择的个体适应度,fworst代表最差个体的适应度。
2)交叉与变异
遗传算法交叉率以及变异率是固定不变的,主要是作为随机性的搜索,存在特定的盲目性,很有可能导致存在比较高的适应度个体遭到损坏,因此,需要对损坏的个体进行修复,利用自适应算子,调整个体动态,检查变异的交叉概率是否有效,将以存在的缺陷克服。此具有指导性的进化,存在全局最优解与效率以及更好的鲁棒性,具体的交叉率Pc、变异率Pm,公式如下所示

(4)
式(4)中:fmax代表群体内的最大适应度,favg代表所有群体的平均适应度,f′代表需要交叉的个体内较大适应度,fc1代表需要变异个体适应度值。
3)保存精英方式
把种群内最佳个体,复制到下一代的种群内,成为下一代种群的新个体[10]。
3 回归测试用例优先级排序
3.1 回归多目标测试用例优先排序模型构建
在进行回归多目标测试用例优先排序过程内,时间和测试成本的存在,通常利用多元素目标函数,测试用例有先的排序结果好坏进行评价,在测试用例优先的排序问题内,其通常状况中,在评价指标众多的情况下,要求能达到单一目标的最优解是很困难的,这就要求求解问题的非支配解,具体两个优化目标的非主导解,回归多目标测试用例优先排序模型构建具体如下所示:
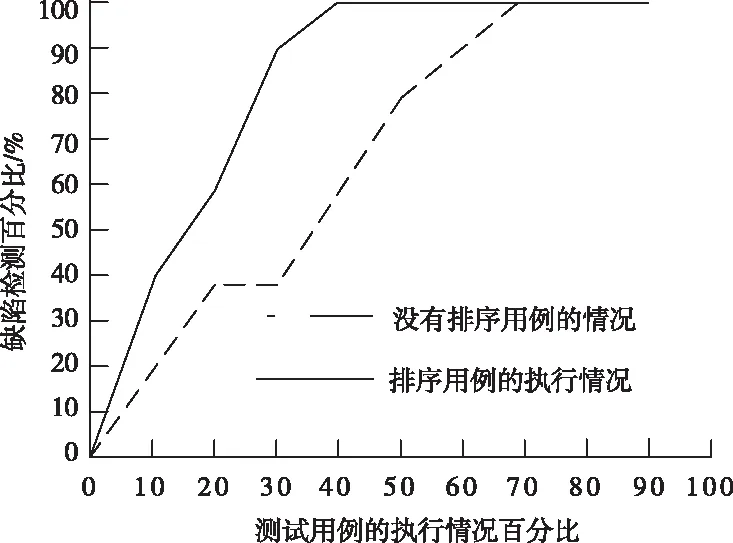
1)如果测试用例的优先排序是排列目标函数f1、f2以上的值都越大越好,则在f1(T1)>f1(T2)且f2(T2)>f2(T1)时,亦或者f1(T1) 2)决定一个测试用例集合中所有测试用例的编号组成了一个全排列,然后在这个测试的用例序列中,用例的上位部分,主要是根据这个全排列形成上面的第一个测试用例段。在测试用例结束时,将所有的测试用例按顺序组成测试用例段,使其达到最大适应值。 不同测试情况用例覆盖不同语句的情况测试用例的序列A-B-C-D相应APSC值如图2所示: 图2 测试用例的序列A-B-C-D相应APSC值 图2是测试用例A、B、C、D对于程序内的APSC值对应情况,测试用例A、B、C、D是在执行期间以A-B-C-D为执行顺序的,随着测试用例逐个执行,它所覆盖的语句的数目也在不断增加,测试使用例C执行结束后,语句的覆盖率可能会达到100%,当测试用例D执行的时,语句的覆盖量不会在增加了,在这种情况下,测试用例A、B、C按顺序形成的有序测试用例,称为上位测试用例段,由此完成回归多目标测试用例优先排序模型构建。 从时间和覆盖角度出发,将有效执行时间和平均分支覆盖率这两个指标作为评价函数,主要用于衡量一个测试用例的优先次序好坏,用C表示平均分支的覆盖率,具体一个测试用例的优先排序序列平均分支覆盖率公式如下所示 (5) 上式(5)中:n代表测试用例个数,m代表被测程序内的分支个数,cm表示首要覆盖程序中的第i个分支测试用例在该测试用例优先顺序,有效时间利用T代表,一个测试用例的优先排序序列有效执行时间,利用以下公式表示 T=t1+t2+t3+…+tn (6) 式(6)中:tn表示执行测试用例的优先次序中的第i个测试用例所花的时间,由此证明这个序列具有一定层次,其原因是一个测试用例序的优先顺序C越大,T顺序越小[12]。 为证明本文方法的有效性,首先选择某一个文件的传输软件Ti(i=1,2,3,4,5,6,7,8,9,10)来进行分析和实验,该软件的要求,需要设计10个测试用例Fi(i=1,2,3,4,5,6,7,8,9,10)。在进行第一次测试发现,该软件内的测试用例检测错误如表1所示。 表1 测试用例的检测软件错误状况 表1中的CT是代表用例的执行时间。 该软件的错误级别以及类型量化值如表2所示。 表2 软件内错误等级以及类型的量化值 表2中,fd代表错误等级所相应的量化值,fs代表错误类型所对应的量化值。 通过以上表1和表2内的错误类型以及等级的量化值。在进行回归测试的时,第一次测试所执行的是没有排序测试的用例,而第二次是通过本文方法进行排序测试用例之后在执行的,利用算法TRG,获得回归测试用例的优先排序集{T5,T9,T8,T4,T6,T2,T1,T10,T3},没有排序测试的例集APFD如图3所示。 图3 没有排序测试的用例序列APFD 排序之后的测试用例集APFD,如图4所示。 图4 排序之后的测试用例序列的APFD 测试用例没有排序与排序之后的错误检测,如图5所示。 图5 测试用例没有排序与排序后的错误检测情况图像 通过以上实验分析能够看出: 1)没有排序的测试用例集APFD数值是0.68,而排序之后的测试用例集APFD数值是0.84。其排序之后的测试用例值大于没有排列测试用例的值,以此可以说明,排序之后的测试用例错误检测速度要远快于没有排序测试的用例检测错误速度。 2)通过以上测试用例的没有排序与排序之后的错误检测图像能够看出,排序之后的回归测试用例在执行40%用例时,就能够检测出软件内所有所有错误。而没有排序回归的测试用例,在执行70%用例才达到相同测试效果。 以此可以证明,本文方法具有很好的测试有效性,且测试效率较高。 1)对于一个软件开发项目来说,项目的测试组在进行测试过程内,会把开发的测试用例保存至测试用例库内,且对其进行维护与管理。采用正确的回归测试来对回归测试效率以及有效性进行选择,回归测试要用到人力、经费以及时间来进行管理、实施与计划。 2)本文方法在传统的遗传算法上,加入的禁忌算法进行改进,使其具有禁忌方法的局部超强搜索能力优点。 3)在利用多个目标函数对回归测试用例优先级排序评价,经过时间以及覆盖的角度考察,执行时间较短,平均分支较大,说明该序列优良。 4)本文方法的测试效果较好,执行效率高。
3.2 多目标回归测试用例的优先排序评价标准
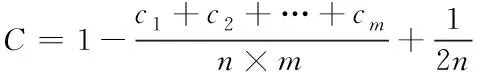
4 实验分析




5 结束语
