基于自适应无迹卡尔曼滤波QAR数据降噪研究
2021-11-17王立新
钱 宇,王立新
(中国民用航空飞行学院,四川 广汉 618307)
1 引言
随着科学技术的不断发展,飞行数据记录设备也在不断更新升级,数据的采集数量与质量都有很大提高。快速存取记录器(Quick Access Recorder, QAR)记载着各种飞行参数, QAR数据分析与挖掘日益受到航空公司及航空监管部门的关注。然而,传感器记录数据难免会受各种因素的干扰,导致译码后数据包含大量异常值。QAR数据有效性分析对航空公司安全运营有着极其重要的影响,为给数据分析与挖掘工作提供更可靠的数据支撑,需要对译码后的数据进行处理,提高QAR数据的可靠性[1-2]。
目前,很多学者在QAR数据处理方面展开深入研究。张鹏等[3]采用时间序列对QAR数据特征进行预测。杨慧等[4]介绍聚类的方法,QAR数据异常点检测问题被有效地解决。陈聪等[5]提出平稳小波法对QAR数据进行降噪噪处理。针对大量飞行数据不能被有效利用的问题,巴塔西等[6]提出采用时间序列法进行故障预测。基于飞机在高海拔机场进近过程的QAR数据,汪清等[7]采用扩展卡尔曼滤波对相关参数进行估计。然而,上述研究存在如下不足:1)聚类法不能有效的剔除野值,时间序列法对非平稳趋势数据预测效果较差。2)小波法、卡尔曼滤波对非线性数据无法起到好的降噪效果,扩展卡尔曼滤波对非线性数据无法精准估计且稳定性较差。3)传统卡尔曼滤波只考虑了高斯白噪声,这样在未知干扰环境噪声[8]的情况下,降噪效果会变差。
研究利用改进拉依达准则和自适应无迹卡尔曼滤波对QAR数据降噪处理。变换贝塞尔公式对拉依达准则改进,提高了数据精度,使自适应无迹卡尔曼滤波对数据降噪免受粗大误差干扰;引入自适应噪声估计器的无迹卡尔曼滤波算法,有效解决了对非平稳数据预测效果差、非线性数据降噪效果差及估计精度低的问题。利用空客A330飞机的两组数据样本对本文提到的方法仿真实验,结果表明该方法可有效解决数据包含异常值的问题。
2 数学方法描述
2.1 拉依达准则
拉依达准则(Pauta)被用来检测数据中的粗大误差,要求数据量大,它以99.7%为参考标准确定置信区间范围并计算标准偏差,凡超越此区间的误差归为粗大误差应被剔除。

1)计算算术平均值
yi=xi+x0
(1)

(2)
由式(1)和(2)得算术平均值为
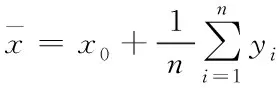
(3)
2)计算标准偏差
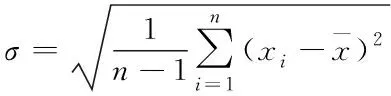
(4)


(5)
2.2 AUKF算法
为提高对非线性系统的滤波效果,Julier等人提出无迹卡尔曼滤波算法[10-11],采用对非线性系统滤波的方法,而非传统的线性化方式。它对线性系统也能起到很好的滤波效果[12]。
1)UKF算法实现
UT变换过程如下:
①产生Sigma点
(6)
②计算权值
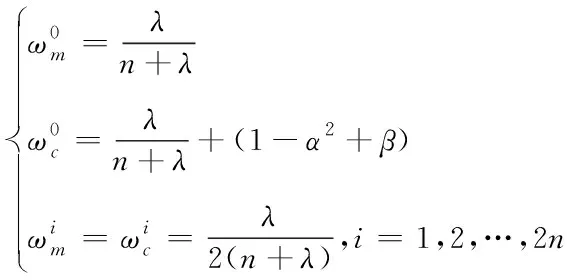
(7)

UKF非线性系统为:
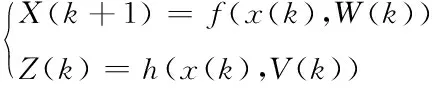
(8)
式(8)中,f为非线性状态方程函数,h为非线性观测方程函数,W(k)和V(k)为协方差矩阵Q和R的高斯白噪声。
UKF的具体推导步骤如下:
①获取采样点并计算权值
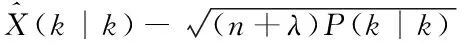
(9)
②计算一步预测
X(i)(k+1|k)=f[k,X(i)(k|k)]
(10)
③计算一步预测及协方差矩阵
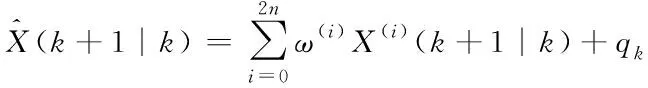
(11)
(12)
④二次利用UT变换,得到新的Sigma点集
X(i)(k+1|k)=

(13)
⑤计算观测量
Z(i)(k+1|k)=h[X(i)(k+1|k)]
(14)
⑥计算系统预测的均值及协方差
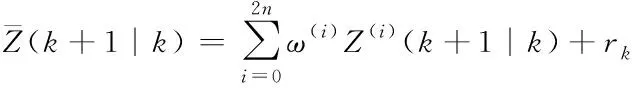
(15)

(16)
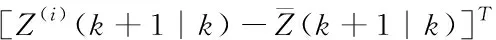
(17)
⑦计算Kalman增益矩阵
(18)
⑧计算系统的状态更新和协方差更新
(k+1|k+1)=(k+1|k)+
K(k+1)[Z(k+1)-(k+1|k)]
(19)
P(k+1|k+1)=P(k+1|k)-
K(k+1)PZkZkKT(k+1)
(20)
由以上步骤可以看出,UKF对非线性滤波是在估计点附近进行UT变换,计算Sigma点集的均值及方差,再对其进行非线性映射,求得状态概率密度函数,无需在估计点处做Taylor级数展开及前n阶近似,计算更为简单。
2)AUKF算法实现
传感器在记录飞行数据过程中,由于各种因素的影响,译码后的QAR数据可能包含其他噪声值,这样势必会增大滤波降噪的偏差。为了解决此问题UKF算法结合Sage-Husa滤波算法构成AUKF算法[13-14],Sage-Husa自适应滤波器可使系统在利用原始数据进行滤波降噪的同时,对系统噪声方差进行实时修正[15-17],大大提高了滤波降噪的精度和有效性。自适应噪声估计器递推过程如下
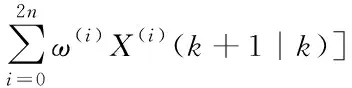
(21)
(22)
(23)

(24)
εk+1=Zk+1-k+1
(25)

(26)

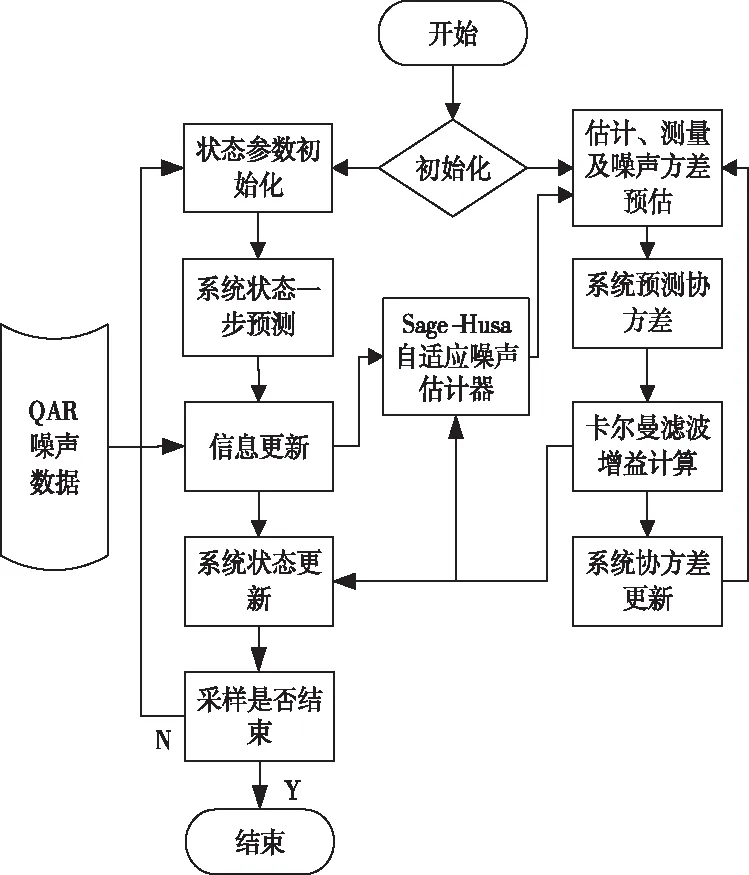
图1 自适应无迹卡尔曼滤波降噪流程图
3 仿真算例
研究采用空客A330飞机某次飞行任务的两组QAR译码数据作为样本数据,分别选择真空速、偏流角各150个数据,验证算法的可行性。
3.1 样本数据检测与剔除
采用改进拉依达准则检测并剔除粗大误差数据之前,需要检验数据是否满足拉依达准则的适用条件,要求数据大致符合正态分布、数据量充分大。仿真实验数据量分别为150,满足数据量要求;根据QAR数据精度高的特点,由于QAR数据精度比较高,选择2倍标准偏差作为判断标准,|gi|>2σ时,xi为粗大误差剔除,|gi|≤2σ时,xi为正常值保留。此时概率区间为95%,两组样本数据95%置信区间图如图2。

图2 样本数据置信区间图
由图2可以看出,两组数据基本都分布在95%概率区间内,验证了数据大致符合正态分布,满足拉依达准则的适用条件。研究分别采用传统和改进拉依达准则检测两组数据中的粗大误差,并对其进行标记及剔除,处理结果如图3。
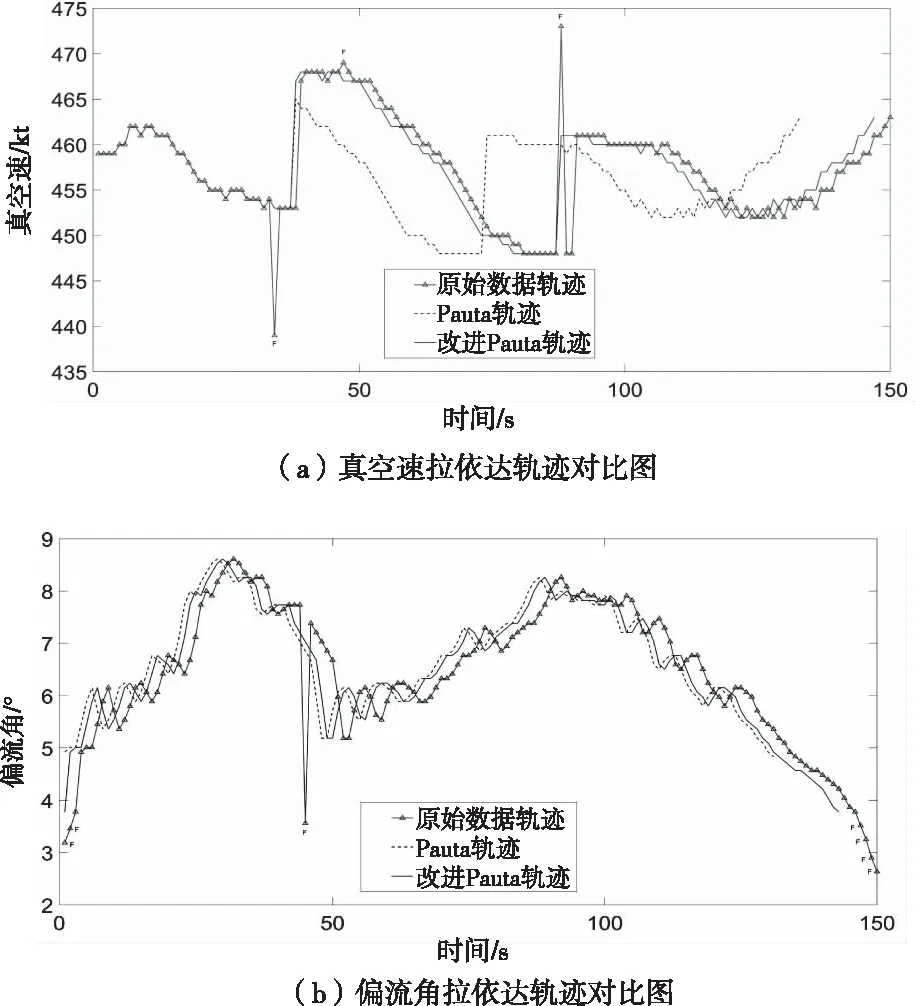
图3 拉依达轨迹对比图
由图3可以看出,传统及改进拉依达准则都能有效检测并剔除误差数据,传统拉依达准则循环剔除粗大误差后,积累误差增大,这样会剔除一些随机误差数据,而改进拉依达准则在剔除粗大误差数据的情况下,保留了更多有用数据,避免丢失更多数据信息。传统和改进算法处理后的数据量信息见表1。
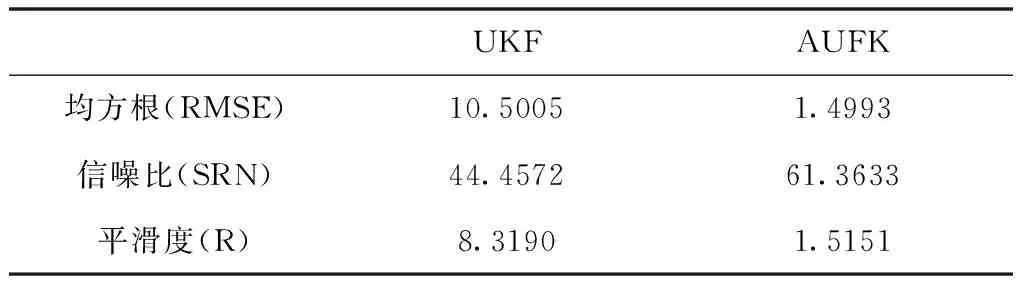
表1 拉依达准则处理前后数据量对比


(27)
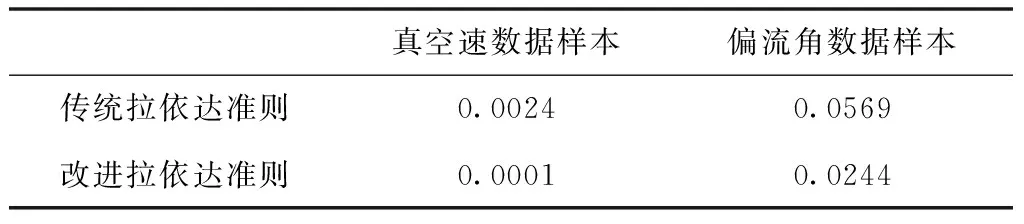
表2 样本数据相对偏差对比
从表2的数据可以看出,采用改进拉依达准则处理的两组数据相对偏差更小,说明改进比传统算法处理数据的准确性更高,验证了改进算法的有效性。
3.2 AUKF与UKF降噪对比
两组数据样本经改进拉依达准则处理,提高了数据的可靠性。然而传感器在记录数据的过程中,可能受到各种因素影响,导致译码后数据包含噪声,运用AUKF算法对QAR数据进行降噪处理,更能提高数据的可靠性。
AUKF较UKF优势在于加入了自适应滤波器,在实际应用中数据包含的噪声不一定是高斯白噪声,噪声值也可能会实时的发生变化,传统的UKF降噪的效果就会变差。根据两组数据的实际情况,Q=0.01,R=0.25,遗忘因子b=0.96,这样滤波降噪效果更好,两组数据UKF滤波、AUKF滤波拟合曲线及滤波偏差对比如图4和图5。

图4 UKF与AUKF轨迹对比图
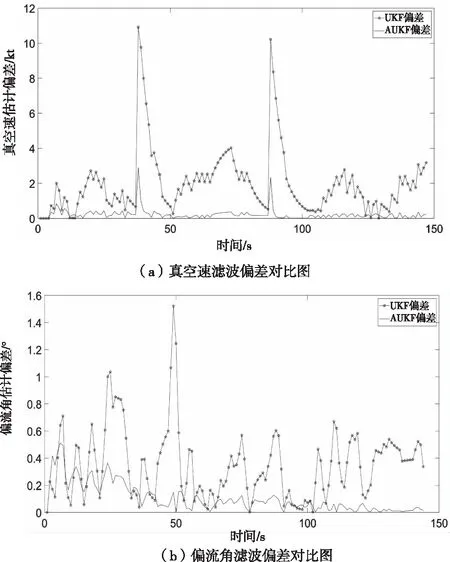
图5 UKF与AUKF滤波偏差对比图
从图5可以看出,滤波后的曲线更加平滑,说明UKF和AUKF对数据降噪处理是有效的,UKF滤波曲线比AUKF滤波曲线更偏离原始数据轨迹;从图6可以看出AUKF偏差更小,说明经AUKF处理的数据更接近于真实值,更可靠。下面利用均方根误差、信噪比及平滑度指标对UKF和AUKF滤波降噪效果进行评估,两种算法的对比评估具体见表3和表4。
表3 真空速UKF、AUKF降噪效果评估
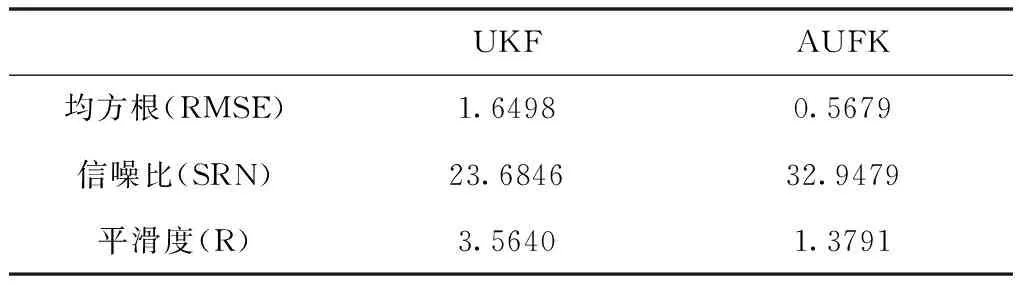
表4 偏流角UKF、AUKF降噪效果评估
根据表3和4可知,两组数据UKF得到的信噪比小于AUKF,均方根误差大于AUKF,说明AUKF对原始数据的处理保留了其更多的有效信息而抑制了更多噪声;从平滑度指标来看,两组数据UKF滤波后平滑度均大于AUKF,说明UKF滤波处理后的数据波形比AUKF滤波更加平滑,但这也从侧面反应经过AUKF处理过的数据相比UKF处理过的数据而言更逼近原始数据,提高了数据的可靠性。
4 结论
1)QAR数据降噪前,需要剔除误差数据,避免其影响降噪效果。传统拉依达准则不能精准剔除粗大误差数据,改进算法在高效、精确剔除误差数据的前提下,保留了更多数据信息。
2)AUKF较UKF加入了噪声估计器,可在线估计系统噪声协方差,抑制初始值偏差及系统噪声特性未知对滤波降噪稳定性的影响,估计误差值更小,原始数据的数据信息被最大限度的保留。
3)AUKF收敛速度更快,通过两组数据仿真结果证明了AUKF更适用于QAR数据降噪,为数据分析提供了更加可靠的数据基础,这种数据处理方法也具有一定的现实意义。
