多媒体信息分类中的边缘模糊确定方法仿真
2021-11-17廖小兵
薛 峰,廖小兵
(上海理工大学,上海200093)
1 引言
计算机已成为日常生活和工作中必不可少的一部分。其中,由文本、声音以及图像等多种形式综合而成的多媒体便成为信息时代的代表产物,因其将传输、储存等媒体功能科学化整合,为使用者提供多种形式的信息展现,使得获取到的信息更加生动[1]。与此同时,被动信息传播的出现令人们对冗杂信息产生反感,因此,根据信息内容及性质,对不同种类信息进行有效划分,成为当下数据分析的主要研究对象。
文献[2]为了提高分类精度,提出了基于数据点本身及其位置关系辅助信息挖掘分类方法。首先,根据网络节点连接特征确定节点以及子网络频率,定义节点浓度,使用迭代计算方式计算节点实际影响力;其次,充分挖掘并处理蕴含在数据点关联作用中的信息,将得到的挖掘结果作为数据点物理特征之外的辅助信息,在保证分类精度的前提下,构建基于数据点本身及其位置关系的信息挖掘分类函数;最后,通过人造数据集合真实数据集的仿真验证了所提方法的有效性。文献[3]在海量图像信息中获得想要的有效信息,提出了一种图像场景的独立子空间ISA分类方法。首先,基于ISA网络模型特征,结合空间金字塔匹配模型和支持向量机分类器完成图像场景分类,获取到信息特征变化基元;其次,利用获取到的特征基元获取信息块描述子,使用空间金字塔匹配模型对信息特征进行描述;最后,在场景数据集上与其它方法对比进行仿真,结果表明所提方法具有一定的准确性。
由于上述所提方法存在耗时长、分类计算过程复杂,无法应用于大量多媒体信息中。因此,本文通过边缘模糊方式确定多媒体信息特征,结合边缘点导数变化确定同类信息交叉位置,建立高斯函数边缘模糊算子归纳同类信息得到最优解,仿真结果表明所提方法具有更高的可行性。
2 多媒体信息特征选择
多媒体信息分类中需选取常见特征,主要方法有:选取信息频率、增益信息提取、X2统计、信息互换、信息交叉熵以及文本证据权等方法[4]。针对信息分类中的边缘模糊确定问题,利用增益信息与X2统计两种方法对信息特征进行提取。
增益信息是建立在熵的评估方法之上,在对多媒体信息进行特征选择时,需判定某个关键词的出现频率,以及文本中是否包含其它类型的信息,通常将该种特征提取定义为某一特征函数在文本中出现频率的差值,计算方法如式(1)所示
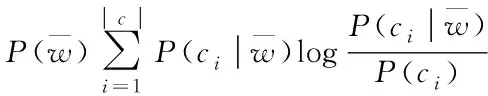
(1)

增益信息特征计算是一种可有效确定信息类型的选择算法,体现在多媒体信息分类中被大面积推广应用,与此同时还可获取到最佳分类结果,并为后续边缘模糊确定奠下良好基础。
3 信息分类中的边缘模糊确定
3.1 边缘模糊确定导数
通过获取到的增益信息特征从而确定归属于边缘的信息节点,边缘模糊计算需借助一阶和二阶导数极值、过零进行判定[5]。边缘点模糊确定导数曲线如图1所示。

图1 边缘点模糊确定导数曲线
在图1中,实线表示点V周围的灰度变化,点划线则代表点H周围的一阶导数曲线改变情况,曲线则表示对应点的二阶导数情况,点A为一阶导数曲线的局部极值,点C为二阶导数曲线的零交叉位置,与y轴相对应的平行线AC代表点A、V、C三点位于同一条直线。

若要判断一个文本信息是否属于边缘点时,可沿一类像素点的梯度方向进行二阶导数零交叉方式,如图2所示。
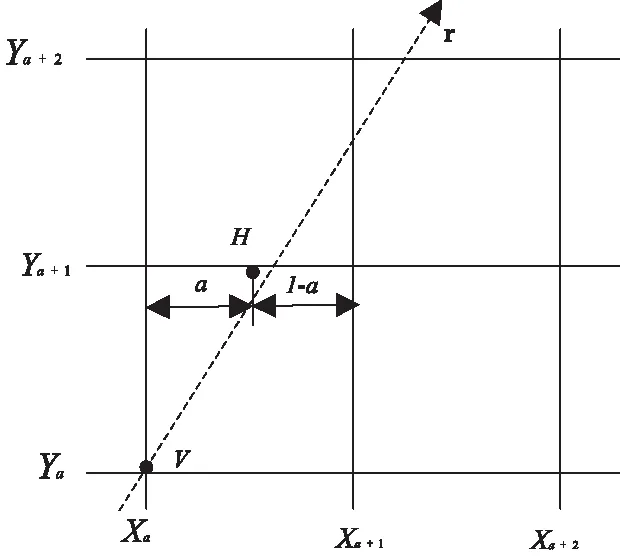
图2 边缘梯度插值图
为了清楚描述点V是否为边缘点,需将点V区域的像素点描绘成一个网格图,此时点B的梯度方向线r与网格相交点H是B在梯度方向中的最近点[7]。但点H或许不是B的最近像素之一,因此,结合线性插值方式将H的一阶和二阶导数进行如下定义
rH1=(1-α)r1(xV,yV+1)+αr1(xV+1,yV+1)
(2)
rH2=(1-α)r2(xV,yV+1)+αr2(xV+1,yV+1)
(3)
式(2)和式(3)中,r1和r2分别表示坐标(xV,yV+1)和(xV+1,yV+1)相对应的导数值。假设点V和点H的二阶导数出现由正至负的变化,则可确定两点间存在零交叉点[8]。
3.2 边缘模糊确定信息分类计算
基于由上述边缘点函数,结合高阶函数的一阶导数,可建立出边缘模糊确定算子[9]。
将设θ(x,y)的平均值设为0,高斯函数方差为σ2,则可得到θ(x,y)的尺度转变方程
θ(x,y)=(1/s2)θ(x/s,y/s)
(4)
其中,s为信息伸缩变量,则
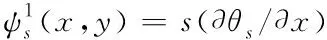
(5)
以及

(6)
通过式(5)和式(6)可看出在信息伸缩变量s上,可将信息函数f(x,y)的小波分类变化定义为

(7)

为了确定多媒体中的边缘候选位置,选取n个邻近的整数范围,将s=m,m+1,…,m+m-1,m∈Z*视作模糊尺度,经计算得到各边缘模糊算子。需分类信息与模糊算子进行卷积[11],局部范围内最大数值点即为确定分类的候选边缘。将边缘幅度阈值用Ts表示,幅度数值大于Ts的候选点作为边缘确定点。对阈值小于ls的边缘范围进行删除,令确定出的信息类型有更高的可信度,一般情况下,ls的数值设为20。结合实际情况选取m和m+1数值,同时要满足最小尺度下分类信息最为准确,其它外在因素对边缘确定影响最小、尺度最大时信息边缘失真最小[12]。
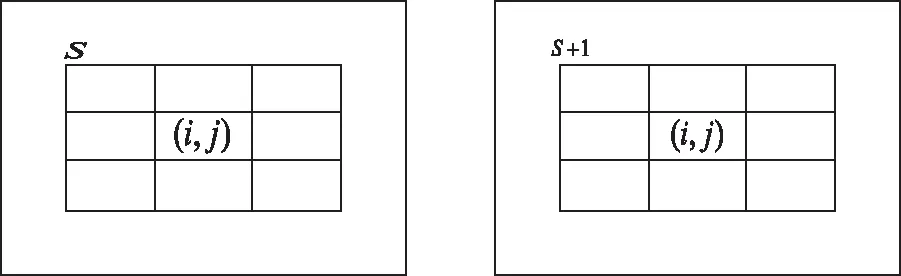
图3 邻近信息空间模糊确定边缘点
如图3所示,信息伸缩变量s的集合为M,s+1区域内的边缘点为(i,j),表示为Fs,s+1(i,j)。使用Cs,s+1(i,j)表示变量s空间位置(i,j)与s+1区域内的关联性,可描述为
Cs,s+1(i,j)

(8)
式(8)中,As(i,j)表示s边缘点(i,j)的梯度关系,α为边缘点阈值差,设为30°。若Cs(i,j)=1,则表示在信息伸缩量s中边缘点(i,j)与s+1边缘点为同一类型,反之则不属于一类。
3.3 边缘模糊确定计算结果
3.3.1 边缘模糊确定分类最优解
假设多媒体信息集合X={x1,x2,…,xn}中每类信息有m个特征,即xi={xi1,xi2,…,xim},再将X按照边缘点阈差分成N类,此时得到N的分类中心为V={v1,v2,…,vn},其中
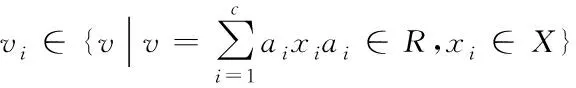
(9)
即
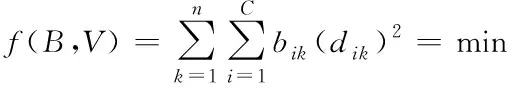
(10)
据式(10)可得到最佳信息划分矩阵表示为B,其中
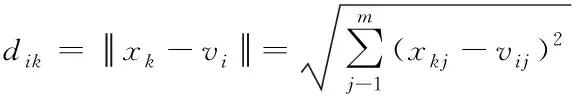
(11)
多媒体信息特征在模糊空间中使用μAn(Fi)表示,称其为Fi类型对信息集合的隶属度,也被称为隶属函数,如图4所示,为隶属函数和模糊空间关系图。

图4 隶属函数和模糊空间
隶属度表达了一种信息类型属于某一个模糊概念程度。若隶属度越大,说明该信息属于该种类的相似程度越高。以多媒体信息中心的文本内容为例,描述为{青年,中年,老年},以年龄21岁的人为例,可使用μ青年(x,20)=1表示此人为青年类型。
综上所述,可将边缘模糊确定描述为
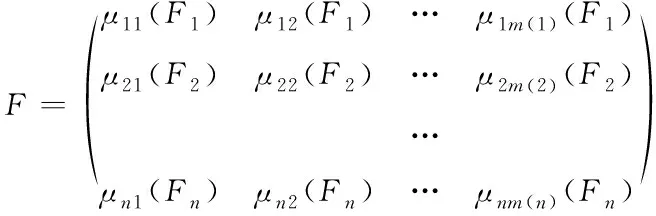
(12)
式(12),m(i)表示第i个信息用边缘模糊集合时的语义关系数量。例如,m(i)=3体现边缘模糊点至信息类型的映射。
3.3.2 信息分类中的边缘模糊评价
当单因素边缘模糊确定结果仅代表一种因素对分类对象产生的影响,为了得到更精准的分类结果,将所有影响因素综合,即
=(b1,b2,…,bt)
(13)
上式(13)中,L为边缘综合模糊分类集合,bt表示综合考虑所有影响因素后,分类对象对文本集合中第t类对象的影响程度。由此可见,集合L也可被称为分类集合的模糊子集。
通过得到的边缘模糊确定导数,可解决分类方法计算复杂的问题,并提高分类结果的准确率。边缘模糊确定方法在计算流程方面从定性角度进行简化推理及分析,得到简洁、可靠和快捷的分类方法,令算法更实用。
4 仿真研究
4.1 仿真条件
假设一个多媒体信息库,将分类条件设为“年龄25岁左右,身高在175cm上下”的人,使用本文所提边缘模糊确定分类方法计算步骤如下:
1)将年龄为25,身高为175设为分类中心条件,对信息进行边缘模糊化导数处理,因身高的确定程度高于年龄,确定分类条件设为Q={0.74,0.24,0,0.7,0.1},将该类特征确定为ω1=1/3、ω2=2/3。
2)确定多媒体信息中的各种几率,计算出边缘模糊距离以及相似程度。
4.2 仿真结果
通过仿真条件,使用文献[2]和文献[3]提出的方法对多媒体信息进行分类检索,在相同实验背景下,使用本文所提边缘模糊确定方法的准确率与以上两种方法进行对比,分类结果如图5所示。

图5 本文方法与文献方法对比
分析图5中的实验结果可看出:在参与分类的15个信息特征中,本文提出的边缘模糊确定方法要明显优于文献两种方法,使用所提方法,分类性能更优。

表1 与{25,175}的最佳分类结果
采用边缘模糊确定方式对多媒体信息进行划分,得到如表1所示的各类型信息的模糊距离及相似度,分析计算结果可知:{24,173}、{26,177}都是与{25,175}最为相似的,而{21,168}就没有{25,175}的相似度高。
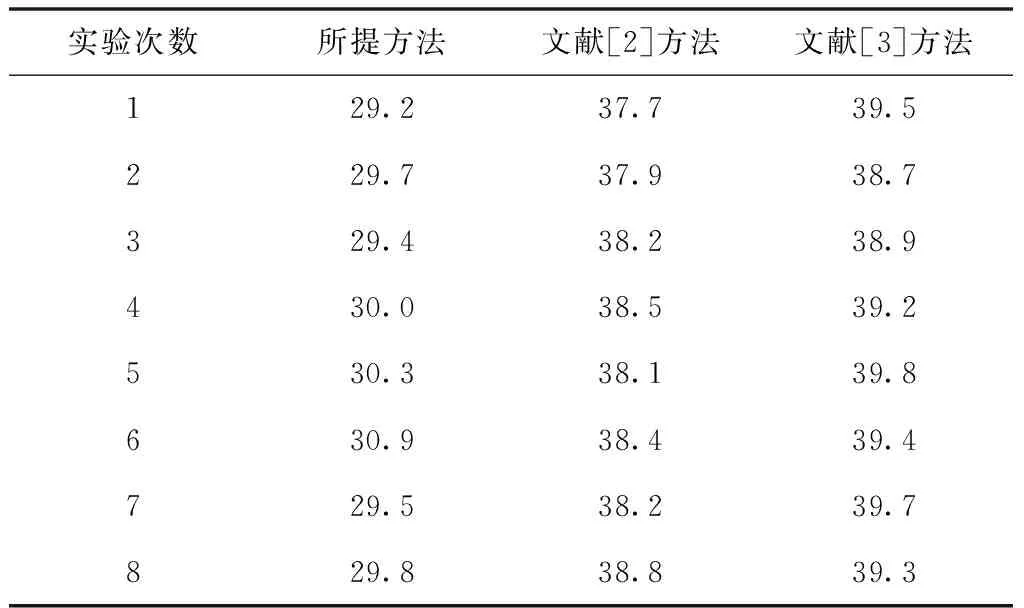
表2 分类过程中不同方法宽带利用率/%
根据实际经验可知,网络宽带的利用率越低说明网络运行速度越快,当网络宽带的利用率低于35%时,信息分类计算方式对网络运行速度的影响程度可忽略,从表2中可看出:边缘模糊确定方法在多媒体信息分类中的宽带利用率在29.2%~30.9%之间,相比其它两种方法对网络运行的影响程度较小,确保了多媒体信息分类的效率。
5 结论
针对多媒体信息内容复杂、发展迅速的特点,为了提高信息分类效率,本文提出多媒体信息分类中的边缘模糊确定方法仿真。经与文献[2]和文献[3]方法的仿真结果对比表明:采用边缘模糊确定方法进行多媒体信息分类效果更好。因为其考虑了不同信息存在的特征差异,并在分级计算过程中为不同类型特征信息提供不同的阈值,使得分类结果更为准确,可被应用于其它分类模式中,有广泛应用推广价值。
目前存在着多种多样的信息分类方法,如何高效识别出信息特征,便于更有效地达到多媒体信息分类的目的,成为当下分类研究中的重要问题。多媒体信息是有一定粒度的,结合多媒体中图像或文本含义的力度将信息由上而下确定出边缘模糊特征,通过某种映射关系按特征进行归类。随着各行各业更加垂直细分的应用出现,“大杂烩”式的信息分类也会逐渐被淘汰,只有进行掠夺式的信息变现,才能在下一个转型中放手一搏。因此,只有进一步提高信息分类效率、提高信息分类的准确程度,才能在信息庞杂中取得一定成绩。
