基于K-Means聚类和集成学习的HTD仿真
2021-11-17芦德钊伍忠东王鹏程
芦德钊,伍忠东,王鹏程
(兰州交通大学电子与信息工程学院,甘肃兰州730070)
1 引言
信息安全是目前全球人类共同关注的热点问题之一,信息安全保护技术与信息安全检测技术的出现,对信息安全起到显著的保护作用[1-3]。恶意入侵者为了持续窃取他人隐私信息,破坏他人系统结构,着力研究多种硬件木马以供窃取应用。硬件木马能够深入信息系统的核心部位,具有多样化、隐蔽性强、破坏力显著的特征,对信息系统存在毁灭性的攻击性,是目前信息安全研究人员重点研究的对象之一。
当下我国的高端、高档集成电路大多来自国外,因供应过程存在不可控性,所以不能保证供应过程里是否具有硬件木马[4]。而我国的国防系统、金融、政府等敏感领域均离不开集成电路芯片、电子设备的使用,如果某些居心叵测的国家在硬件设备里植入硬件木马后,我国相关技术人员并未检测识别,此类硬件木马将长期潜藏在我国各个领域的信息系统里,这对我国信息安全存在致命打击[5]。K-Means聚类在数据挖掘领域中存在较好的使用效果,本文提出基于K-Means聚类和集成学习的硬件木马检测方法,以期实现硬件木马的高精度检测。
2 基于K-Means聚类和集成学习的硬件木马检测方法
2.1 基于信息熵改进的K-means 动态聚类算法
传统K-Means聚类算法在聚类挖掘信息系统的硬件运行数据时,所需计算的数据不仅是各个聚类目标和中心目标的距离,还是中心目标出现变化的聚类均值。如果计算量较大,聚类效果将受到影响[6]。因为K-Means聚类具有动态性,聚类时将存在一些冗余数据,这对聚类精度存在一定影响。所以,本文对K-Means聚类算法进行改进,一方面是降低聚类迭代次数,一方面是降低聚类时的数据量,为此设计基于信息熵改进的K-means 动态聚类算法,实现信息系统硬件运行的有效数据挖掘。
基于信息熵改进的K-means动态聚类算法的流程如下:
输入:信息系统硬件运行数据对象集,聚类种子初始中心点数量k1。
输出:k个结果簇,设置各个聚类中心点的变动值低于设定值,当信息系统硬件运行数据对象集是空集时停止。
2)通过熵值法运算硬件运行数据目标每个属性的权值。
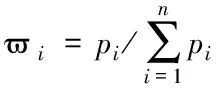
(1)
式中,pi是属性差异性系数;n、i分别是数据数量、数据维数。
3)把硬件运行数据集合均分成k1(k1>k)个子集,在每个子集里任意选择一个硬件运行数据目标,把它设成硬件运行有效数据聚类种子中心。
4)扫描硬件运行数据集合,以它和每个聚类种子中心近似度的大小为标准,把它纳入近似度最大的簇里[7]。
5)运算k1个聚类的赋权标准差βj,j=1,2,…,k1,运算方法是:
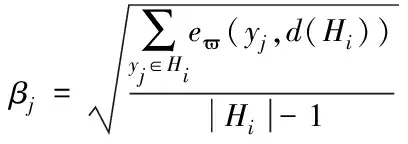
(2)
式中,|Hi|是数据类型Hi的数据量;yj、eϖ、d(Hi)分别是数据属性、欧式距离、数据类型Hi的聚类中心。
同时根据βj值从小到大排列,将前k个βj值所属质心设成初始聚类中心。
6)把硬件运行数据集的各个样本根据欧式距离最短标准将其纳入最邻近的簇里。
7)运算硬件运行数据的质心点。
8)分析聚类中心点的变动值是否符合设定条件,若符合,把它纳入已选特征集,且在硬件运行数据里去除此数据[8]。
9)分析硬件运行数据样本集合是否属于空集,若是便可结束。反之,遍历聚类中心点数目M,若M的值小于k,跳转至第6)步,如果M的值等同k值,进入第10)步。
10)更新聚类中心点。运算信息系统硬件运行的各个数据聚类中心点的变动值是否高于设定值的簇质心,如果是,便把它设成新的聚类中心实施聚类;反之跳转至第6)步。
11)停止,硬件运行数据样本属于空集后,输出有效数据聚类的结果簇。
通过上述算法,便可去除硬件运行数据中冗余数据,实现硬件运行数据的有效数据挖掘。
2.2 基于改进旋转森林的集成学习方法
2.2.1 旋转森林算法的改进
旋转森林算法的核心思想为:通过主成分分析法(principal component analysis,PCA)对数据样本实施旋转操作,以此获取存在差异的训练集[9-10]。此类旋转处理的优点是保证文本分类器精度更加优化,但传统旋转森林算法通过主成分分析法转换,对原始样本数据实施转换时,主成分分析法的转换是以样本协方差矩阵为基础,运算过程易遭到数据原始特征的量纲与数量级所干扰。所以本文导入均值化方法,改进旋转森林算法里的PCA转换模式。
设置2.1小节所挖掘的硬件运行有效数据样本数量是m,各个样本特征属性数量是n个,2.1小节所挖掘的硬件运行有效数据样本aij设成矩阵A=(aij)m×n。均值化是将硬件运行有效数据样本的矩阵A里各个有效数据点除以所属列的均值,均值化后的硬件运行有效数据样本训练集xij设成矩阵X=(xij)m×n,则
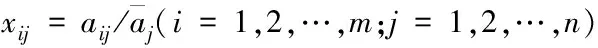
(3)
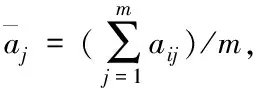
运算矩阵X的协方差矩阵V=(vij)n×n,vij代表协方差。X的各列均值均为1,所以vij是
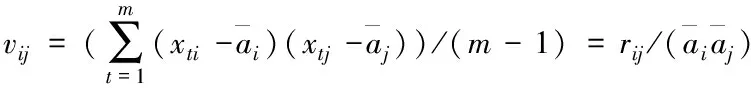
(4)
均值化后的矩阵X里每个硬件运行数据特征的相关系数是
s′ij=vij/(viivjj)1/2
=rij/(riirjj)1/2
=sij
(5)
式中,vii、vjj分别是矩阵X第i行第i列的协方差、第j行第j列的协方差;rii、rjj分别是矩阵X第i行第i列的协方差矩阵元素、第j行第j列的协方差矩阵元素。
均值化后,硬件运行数据特征之间相关系数不存在变动,代表均值化后未曾破坏硬件运行数据原始特征,对下文文本分类器的精度不存在影响[11]。
2.2.2 文本分类器建立
输入:训练集A=(aij)m×n、硬件运行数据特征向量G=(bm1,bm2,…,bmM)、文本分类器数量M、特征集合分类数E。
输出:文本分类器集合F=(f1,f2,…,fm)。
1)对矩阵A实施均值处理,获取数据矩阵X。
2)把G任意分成M个子集,各个子集Gim里存在的特征数是N=n/M。
3)针对第m个子集Gim而言,在X里提取和Gim相应的数据样本Gim,在Gim里任意提取75%的硬件运行数据,设成G′im。
4)将G′im实施PCA转换,获取N个特征值,运算特征向量G获取特征矩阵Bim=Bm1,Bm2,…,BmM。
5)合并Bm1,Bm2,…,BmM建立第M个文本分类器相应的旋转矩阵Bi:
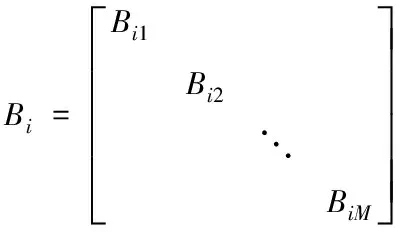
(6)
6)根据训练集X里硬件运行数据特征每列位置,将Bi实施排序,设成B′i,以此获取新的训练集Xi。
7)在训练集Xi里生成一个文本分类器。
8)结束。
2.2.3 动态加权投票集成方法
文本分类器建立后,多数投票法属于一类操作难度低、使用效率高的集成模式,投票判决过程里,各个分类器的权值和分类精度存在一定联系。因为信息系统硬件运行时数据存在动态性,需检测木马数据也存在变化。所以各个文本分类器对木马数据的检测性能也存在变动性,最合适的加权方法必须可以分析目前需检测木马数据的统计特征分布和训练集之间的关联性[12]。
本文使用基于实例动态选择的加权投票策略完成集成分类。
1)运算需分类的硬件目标数据A和M个簇中心的距离,选取距离最小的M1个簇。
2)依次统计各个文本分类器对M1个簇中全部硬件运行数据样本的分类精度φM,归一化后的值就是投票权重:
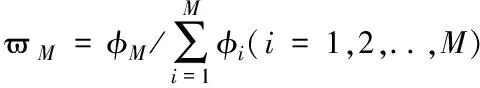
(7)
式中,φi是文本分类器第i次分类精度值。
3)各个文本分类器均输出A的分类结果,使用投票权重完成硬件运行数据中木马数据的分类。分类阈值按照真实的信息系统运行环境设置,通常将分类结果高于0.5的数据判断成木马数据,此数据所在硬件即存在木马行为。
3 实验结果与分析
为了测试本文方法有效性,在MATLAB仿真软件中,仿真某信息系统硬件遭到木马入侵,使用本文方法对其实施木马检测,检测环境如图1所示。
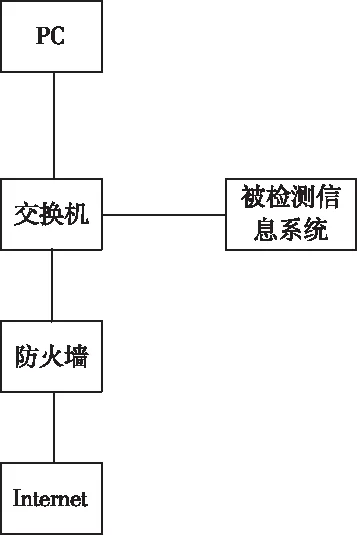
图1 仿真环境
如图1所示,使用PC系统和交换机相连,交换机属于被检测信息系统与PC系统的连接桥梁,将本文方法使用在PC系统中,在防火墙和Internet的协助下,检测本文方法的使用效果。
使用入侵领域常用指标测试本文方法对硬件木马检测的效果。检测指标依次是检测率、误报率。检测率、误报率的计算方法是
E1=n1/n2
(8)
E2=nt/nm
(9)
式中,n2表示木马数据总数量;nm表示不存在木马的硬件运行数据;n1表示被准确检测为木马数据的数量;nt表示被误检测为木马数据的数量。
将所检测的信息系统硬件电路程序所运行数据量依次设成10GB、20GB、30GB、40GB、50GB、60GB,此条件下本文方法对该信息系统硬件木马检测的检测率、误报率如表1、表2所示。
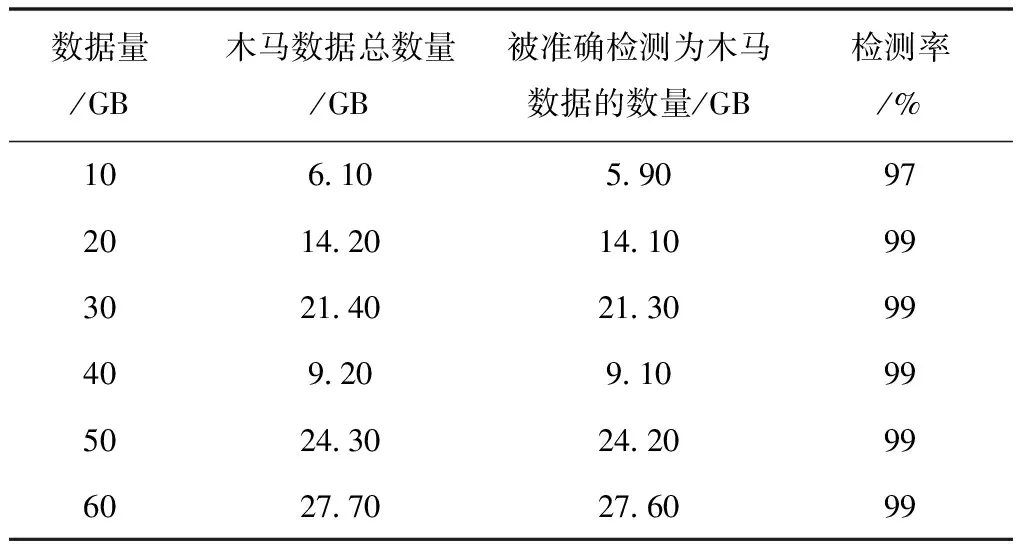
表1 本文方法检测率测试结果
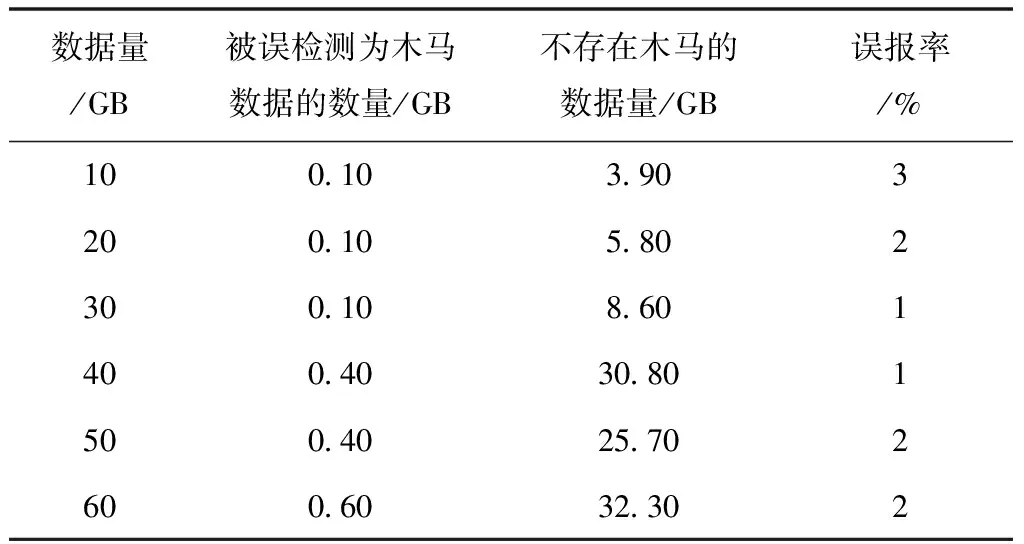
表2 本文方法误报率测试结果
由表1、表2测试结果显示,所检测信息系统电路程序运行数据量依次是10GB、20GB、30GB、40GB、50GB、60GB时,本文方法对硬件木马数据检测率高达99%,误报率最大值仅为3%,本文方法可准确检测信息系统硬件木马。
为测试本文方法检测性能,设定该信息系统电路存在2种类型木马,在2种不同类型木马影响下,该信息系统的电路的信号变化如图2所示。
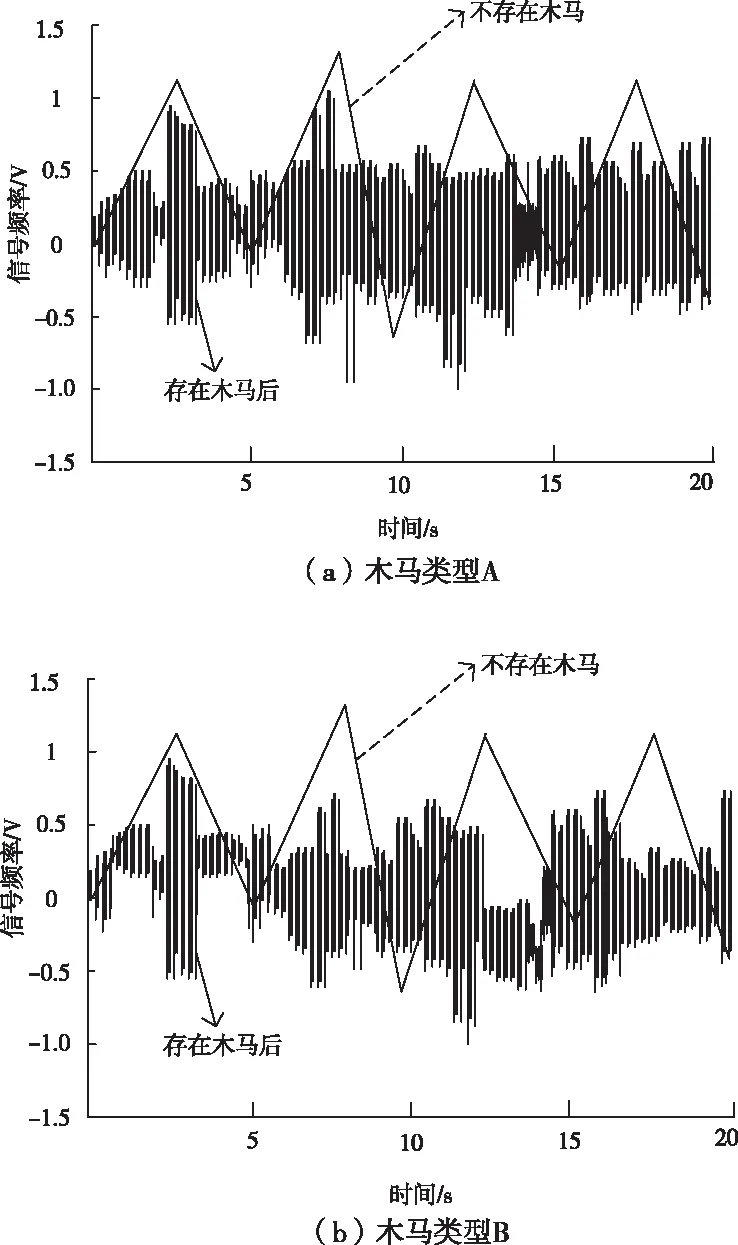
图2 不同类型木马影响下电路的信号变化
以文献[4]所提出的基于转换概率分析的硬件木马检测方法、文献[5] 所提出的基于随机森林的硬件木马检测方法为对比方法,这两种方法虽然被验证对硬件木马的检测效果符合应用需求,但为了测试本文方法检测性能是否存在优势,本文在此对比三种方法对两种木马入侵下的检测效果,检测效果以电路木马数据检测结果的均方根误差RMSE体现。均方根误差RMSE是检测值和实际值之间偏差的平方和与观测次数之比的平方根。三种方法均方根误差测试结果如图3、图4、图5所示。
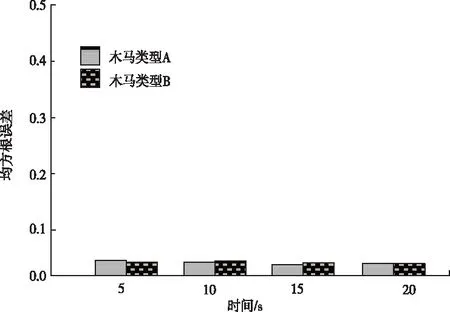
图3 本文方法均方根误差测试结果
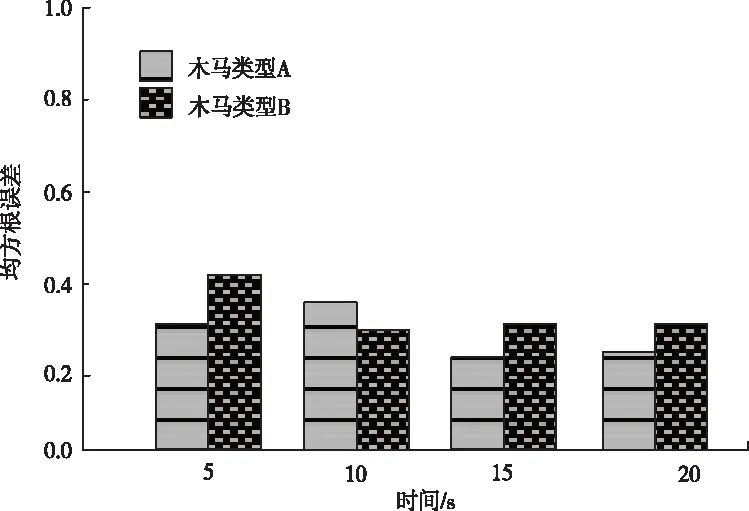
图4 基于转换概率分析的硬件木马检测方法均方根误差测试结果
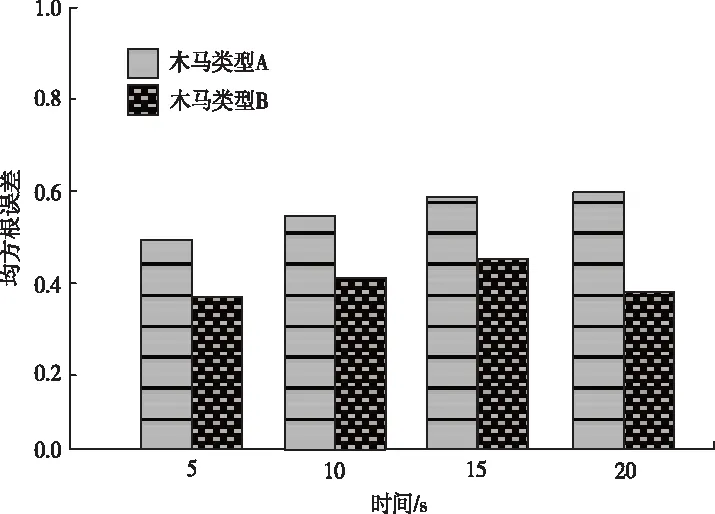
图5 基于随机森林的硬件木马检测方法均方根误差测试结果
由图3、图4、图5测试结果显示,两种木马入侵下,本文方法检测结果的均方根误差最大值为0.04,基于转换概率分析的硬件木马检测方法、基于随机森林的硬件木马检测方法检测结果的均方根误差大于0.2,显著大于本文方法。对比之下,本文方法检测结果精度最大。
测试三种方法对硬件木马检测实时性,结果如表3、表4所示。
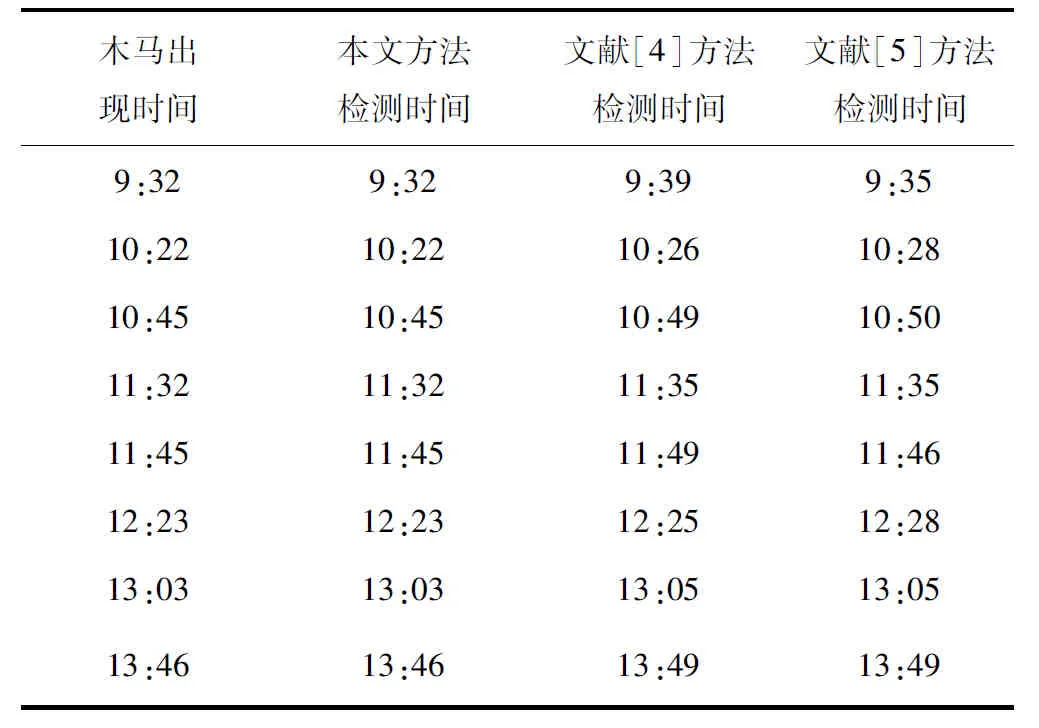
表3 木马类型A
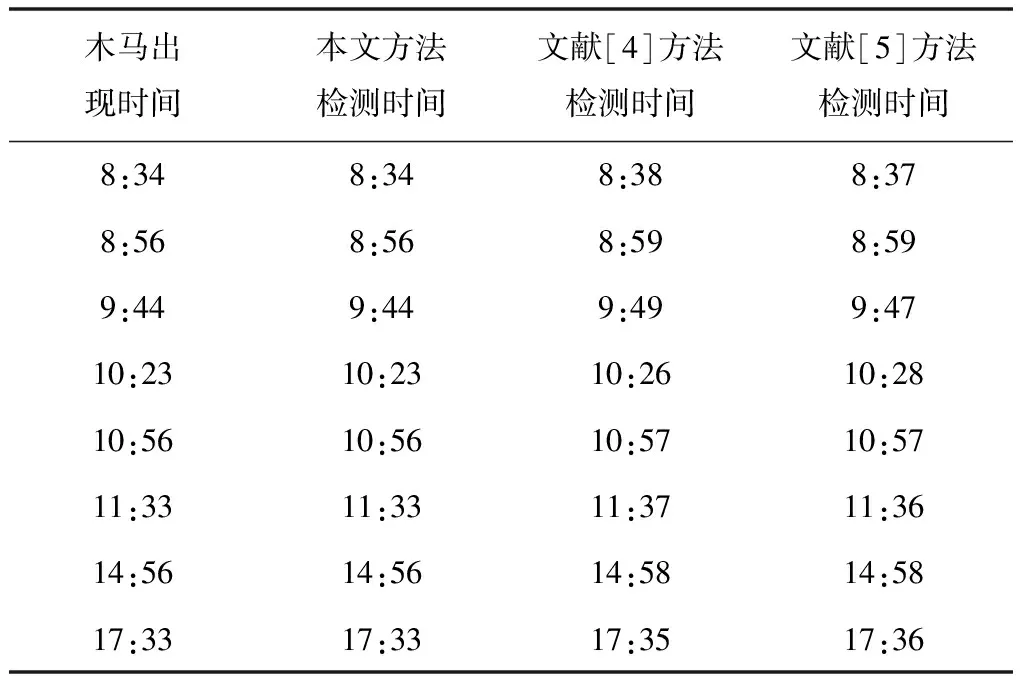
表4 木马类型B
由表3、表4测试结果显示,两种木马出现时,本文方法可实时检测出硬件木马,不存在时延;基于转换概率分析的硬件木马检测方法、基于随机森林的硬件木马检测方法检测实时性较差,对两种木马检测时间存在一定延迟情况,对比之下,本文方法对硬件木马检测实时性更为显著。
测试本文方法使用基于信息熵改进的K-means 动态聚类算法前后,对信息系统电路程序中木马的检测效率,以此判断基于信息熵改进的K-means 动态聚类算法对本文方法整体检测实时性的影响。结果如表图6所示,图6仅显示使用前的检测时延最大值,将图6结果分别与表3、表4中所显示本文方法检测时延最大值进行对比,表3、表4中本文方法不存在检测时延。
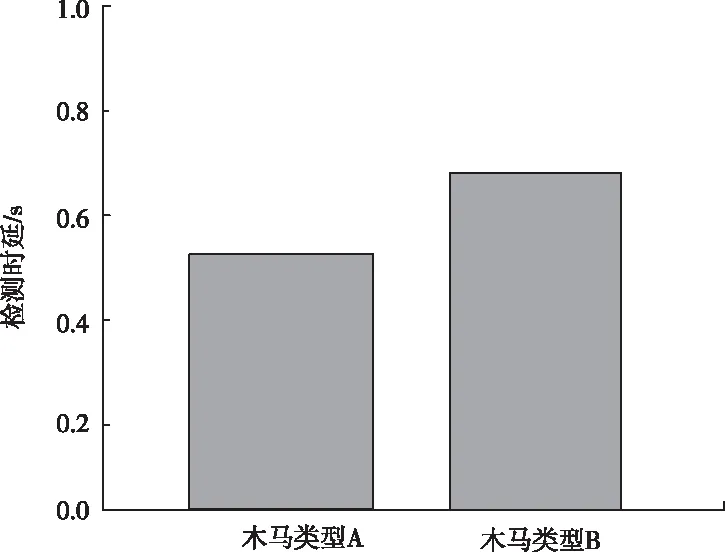
图6 本文方法聚类环节应用价值
将图6结果分别与表3、表4中所显示本文方法的检测时延最大值进行对比可知,本文方法使用基于信息熵改进的K-means动态聚类算法前,对硬件木马检测时延最大值分别是0.55s、0.70s,使用后的检测时延为0s,由此可见,基于信息熵改进的K-means 动态聚类算法的使用,对本文方法检测效率存在优化作用。
4 结论
文中提出基于K-Means聚类和集成学习的硬件木马检测方法,该方法具有检测率高、误报率小的优势,且不同类型木马入侵下,本文方法检测精度、检测实时性明显大于基于转换概率分析的硬件木马检测方法、基于随机森林的硬件木马检测方法,这归功于本文方法中引入了基于信息熵改进的K-means 动态聚类算法,该算法能够有效去除信息系统硬件运行数据中冗余数据,避免出现无效数据检测情况,提升本文方法对信息系统硬件木马的检测效率。
