一种新的在线社交网络社区发现算法
2021-11-17何道兵刘小洋
何道兵,刘小洋,丁 楠
(重庆理工大学计算机科学与工程学院,重庆400054)
1 前言
在线社交网络社区发现研究算法,随着时代的发展,已经成为了一个值得深入研究的科学问题。社交网络现在已经成为了人们生活不可缺少的一部分,是对现实关系的一个映射,是基于互联网和通信平台形成的一个大数据网络。对网络数据和结构的认识[1-3],能让人们更好的理解网络上事物发生过程,使人们更好的设计、控制网络。而虚拟社区的发现作为网络科学的经典问题,让众多学者不断地追寻探索[4-7]。研究发现在现实中包含着各种多样的网络,就像社交、技术、生物等方面因某种关系而产生网络,这些网络都具有一个共同特性就是社区结构。同一特性节点以及它们的关系连边所构成的图便是网络社区,不同的社区连接组成社交网络,社区内部连接边比社区之间连接边往往更加稠密。社区结构是社交网络的重要结构特征之一[8-12],它代表了真实网络的异质性和模块化的特点,它在网络的功能和拓扑分析中发挥着重要作用。此外,社交网络通常在社区上会展现出单个节点和整个网络所不具备的特点。因此,对社会网络社区发现算法的研究在很多方面具有重要意义[13-16]。
本文为了克服传统的社交网络社区发现算法仅仅是从数学理论上进行分析的不足之处,采用微博用户数据集和karate数据集上进行社区划分,运用了凝聚思想并引入模块度增量的概念来构建社交网络社区发现算法。
2 相关工作
在最近几年中,复杂网络中社区结构的发现和分析越来越受到社会的重视,已经出现了许多社区发现算法。自Girvan和Newman提出 GN 算法以来由计算机科学、物理学以及数学等多个学科发展出许多社区发现的算法,并广泛应用于各个科学领域的具体问题中[17-19]。
在最开始大家的理解,社区指的是在一个系统中某些个体因为有一些共同点或者相似点,分析而形成在外部稀疏且在内部紧密的连接结构。非重叠社区发现是一种硬划分,其中每个节点只能属于一个社区,社区之间没有交集。非重叠社区研究主要有传统方法的谱方法以及基于模块度的GN算法,对于非重叠社区发现算法的研究主要归功于Girvan与Newman在2002年的开创性研究工作[20-22]。
在真实的社交网络中,人们往往同时属于不同的社区,并且属于多个社区的人。一方面,重叠节点是网络中关键点,重叠社区因此而产生联系;另一方面,重叠社区反映了更加真实的网络结构[7]。因此,对重叠社区进行发现和研究是更符合现实网络的真实性的,更具有社会价值,更应引起研究者的重视和关注。重叠社区发现方法主要有以下几类:基于派系过滤的重叠社区发现算法,基于局部扩张及优化的方法,基于线图/边社区的发现方法。随着近十多年来的研究和发展,社区发现研究的重点一直都在发生改变,根据当前互联网技术驱动的社交网络环境中的网络拓扑和社区结构特征,社区发现的研究仍然面临着若干的挑战性问题[23-24]。
3 传统社区发现算法
3.1 采用分裂思想的算法
在2002年由Girvan和Newman提出的分裂算法,现如今已经成为了社区发现算法的一大经典算法,就是GN算法[25-26]。众所周知,社区与社区之间的联系相对来说较为稀疏,这也就代表着社区与社区之间的沟通渠道相对较少,因此一个社区与另一个社区需要通过这些沟通渠道中的至少一个。如果能够从中找到这些较为重要的沟通通道并且进行移除的话,那么网络就自然而然地会进行社区划分。Girvan和Newman提出了使用边介数来对每条边的网络连通重要性进行记录,在对网络结构进行社区发现过程中,分析时需要关心网络图是有向边还是无向边,是正权边还是负权边,顶点是否存在自环的可能。边介数指的是网络中的顶点间的最短路径经过该边的次数,对于无权图,最短路径是顶点之间数量最少的边,而有权图中为两点之间权值和最少的连边。边介数的数学公式定义见式(1)。

(1)
其中的σst(v)表示的是从上s→t最短路径上经过了节点v的最短路径数,σst表示了s→t上的最短路径数。每次需要找到s节点到v节点的最短路径上v的前驱节点集合,因为s到v的最短路径上一定会经过v的某前驱节点。在计算最短路径上。可以对无权图调用BFS广度优先遍历算法,对有权图调用Dijkstra算法[26-27]。
该算法使用一个队列来存放每次遍历的节点,使用visited数组记录该节点是否访问过。初始时所有节点都未被访问过,灰色节点为即将访问的节点,先从第一个结点v1开始进行入队操作并将该节点visited置为1表示已经访问过。由于v1为队头元素,所以v1出队并且邻节点全部为待访问节点,直到最后队列为空退出循环,此时所有节点均已访问过。
而Dijkstra只能计算单元最短路而且权值必须为正,该算法是基于贪心的思想。对每个节点进行一次遍历就可计算出该节点到其它节点的最短路径,通过集合S存放已找出的最短路径,U集合存放还未找出的最短路径的节点。每次通过在U集合中找出最短路径的点然后加入S集合中,同时U集合进行更新。循环到遍历结束后,U集合为空就得到该节点到每个连通节点的最短路径。GN算法的基本流程如下。
1)根据网络图结构采用有效的最短路径算法,计算出所有节点间的最短路径,得出网络中每条边的边介数。
2)找出所有边介数中的最大值,当边介数最大值唯一时将该边介数进行移除,当边介数最大值不唯一时,可以随机选择一条边断开,也可以同时将所有边介数最大值的边断开。
3)移除边后,对网络中剩余的边依据步骤1思路重新进行边介数的计算。
4)对步骤2、3进行循环,当为网络中所有的边被移除时算法进行终止。
对GN算法使用karate数据集进行社区划分后,对每次迭代后的模块度进行统计,得到了图1表示了GN算法过程中边数量与模块度值的关系。
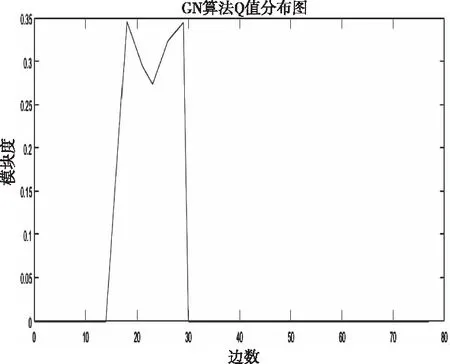
图1 GN算法社区划分Q值分布
可以看出,当迭代到23次时才开始出现了划分,因为前面每一次迭代边划分可能出现正好划分成独立社区,社区之间的相连边均被删除的情况。当迭代至29次时出现了社区模块度巅峰值,取该模块度下的社区划分情况即为GN算法对karate数据集的最佳划分。
图2为在Q值分布中选择了最大模块度时的社区划分情况,即为GN算法发现的社区划分。可以看出,由于GN算法是删除最大边介数,在移除边的过程中,会优先移除孤立点的,这也导致划分过程中产生了较多的孤立点,如3.6中一共有21个社区存在,其中19个社区都是孤立社区。
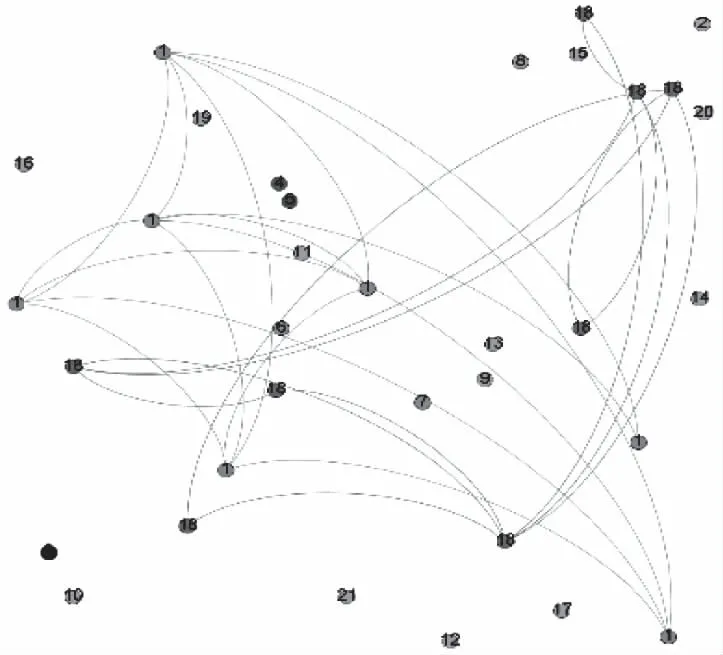
图2 GN社区划分结果
3.2 采用聚合思想的算法
GN算法是针对全局性的,是对整体网络结构进行划分,而在现实的网络结构中,全局性网络数据是很难实现的,通过对局部网络的分析才是更有效的社区发现算法。所以Newman基于贪心思想提出了基于模块度最大化的贪心算法FN算法,该算法将全局的最优化分解成了局部最优化问题,通过找出每个小块的局部最优值,最后将所有的局部最优值整理一起,变成全局的近似最优值。
贪心算法意味着在解决问题时始终做出当前时刻的最佳选择。也就是说,并不会去考虑整体的最优性,从某方面来说,它是对局部最优解的选择。并不是所有的问题都可以通过贪心算法得到整体的最优解,局部还是整体的最优关键还是进行贪婪算法时进行的策略选择。要确保选择的贪婪策略必须没有后遗症,也就是说某一状态一定只和当前的状态有着联系,而并不会影响到未来的状态[18]。贪婪的选择意味着可以通过一系列局部最优选择,即贪婪的选择来实现对所寻求问题的整体最佳解决方案。贪婪的选择是自顶向下连续地进行迭代选择。每次做出贪婪的选择时,问题就会减少到一个较小的子问题。贪婪算法的基本思想是从问题的初始解决方案一步一步地进行,根据优化措施,每个步骤必须确保可以获得局部最优解。每个步骤只考虑一个数据,但是该选择要能够满足获得局部最优解的条件。如果下一个数据和部分最优解决方案不再是可行的解决方案时,则在枚举完所有数据之前将数据添加到部分解决方案中,或者无法再添加的时候进行算法终止。FN算法最开始初始化的时候,将网络中的所有的节点都看成一个单独的社区,然后对所有的两两有联系的社区合并进行考虑,计算出每次社区合并会导致的模块度增量ΔQ。由贪心算法的原则可知,每次划分只对模块度增量的最大值和最小值的两两社区进行社区合并,一直迭代到当所有的节点都合并成为一个社区。FN算法的具体步骤如下所述。
1)网络结构初始化,删除掉网络结构中的所有连接边,然后将每一个节点都看作是一个独立的社区。
2)将网络中存在的有连通关系的节点划分为一个社区。对于还没有加入的网络连通边都重新添加回网络结构中,若在网络边加入后,对两个社区之间进行了连接那么对两个社区进行合并,然后计算新的网络结构进行社区划分后的模块度增量。每次只选取合并模块度增量中的最大值或者减量中的最小值的两个社区。
3)一直对步骤2进行循环迭代,直到社区划分的社区数量值为1时。
4)对所有社区划分模块度值进行遍历,寻找选择具有最大模块度的社区作为网络的最佳划分。
在FN算法的计算过程中,要注意每次进行模块度计算的时候,都必须要在完整的网络拓扑结构上,也就意味着在拓扑结构上包含了网络中所有的边。对FN算法使用karate数据集进行运算后,记录每次添加边后的Q值,分布结果如图3所示。
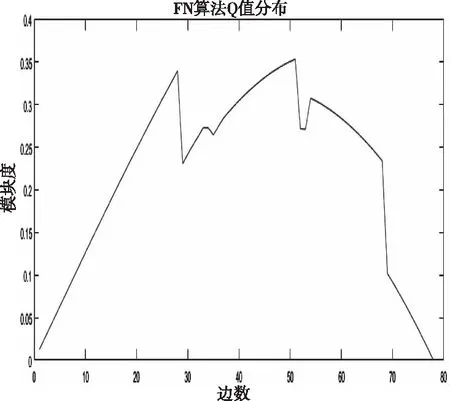
图3 FN算法社区发现Q值分布
从图3的Q值分布图可以看出,最开始将所有点看作单独的社区此时模块度为0,到最后所有节点在一个社区模块度为0。该算法在每次迭代对所有可能边进行添加,根据模块度的增量增加最大减少最小原则,从而达到了社区分布的收敛。图3中的Q值巅峰值就是社区划分得最好结果,由图可知,此时边数添加为53条,根据结果记录得到添加边1和0时,得到53条边的最优结果。取出最优解进行数据可视化,得到图4。
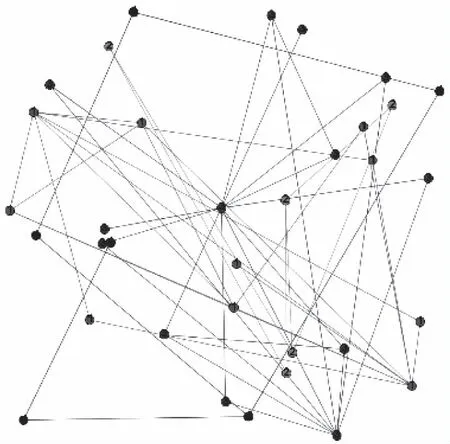
图4 FN算法结果示意图
从可视化图中可以很好看出,每种颜色为一个社区的划分,karate数据集经过FN算法分为四个社区,此时是FN算法的最优解。对比前面GN算法的运行结果,存在许多的孤立点,FN算法的运行结果明显更加可靠,而且运行时间更低,FN算法的步骤理解以及算法的实现都比GN算法更容易。
4 提出的MICDA算法
在MICDA算法中,新加入了一个模块度增量ΔQ的概念,在对模块度进行初始化的时候应该满足式(2)。
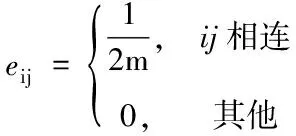
(2)
式中,eij表示i、j社区边连接的比例,初始所有节点单独一个社区时,所有社区不相连,得出初始模块度为0。在对模块度增量进行初始化的时候,元素数据应该满足下列数学式(3)。
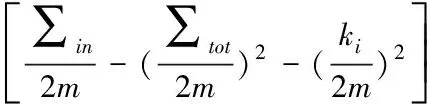
(3)
式中,ki,in表示的最新构建图i节点在社区C的权重之和,∑tot表示与社区C相连节点的边的总权重,ki表示了i节点的总权重值。该公式比较复杂,对公式进行简化后得到式(4)。
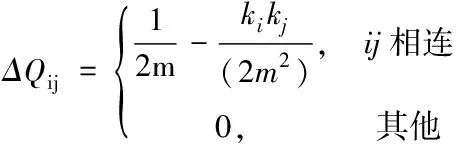
(4)
ki表示节点i的度,kj表示节点j的度,m表示网络中当前结构所有边的数量。提出的MICDA算法1如下。
算法1:提出的MICDA算法
Step1:对所有节点进行数据初始化,将每个节点i置于单独的社区i中。
Step2:第一节点开始进行选择,找到该节点的所有邻居节点,根据式(4,3)计算出当该节点加入每一个邻居社区时的ΔQ,如果ΔQ取值大于0就将邻居节点划分到当前节点社区中,否则保持原社区不改变。
Step3:对step2进行循环,迭代直达当前节点所在社区为稳定值。
Step4:每个社区划分后,构建一个新的图结构,将在同一个社区的节点全部看作一个新节点。新节点内部节点与节点之间的权重,看作新节点自环产生的权值。新节点与邻居节点的权值为内部所有节点对该邻居节点权值。完成新图的构建后,重复step2直到模块度Q取值最大时终止。
算法1中对步骤2、步骤3的一个节点迭代过程如图5所示,对步骤4中新图结构的构建如图6所示。
图5为MICDA算法的迭代示意图,最初五个节点是独立的五个社区,在经过步骤2的完全迭代后,发现2节点属于1节点所在社区。此时进行新图的构建,将节点1和节点2压缩为一个新节点1,这时图中只有四个节点存在。继续对步骤2进行迭代,以此发现了节点3、4、5都可以归到新节点1中,进行了三次新图的构建后,得到全图只有一个社区1存在,节点1、2、3、4、5都属于社区1中,此时不再有节点社区发生改变结束迭代。
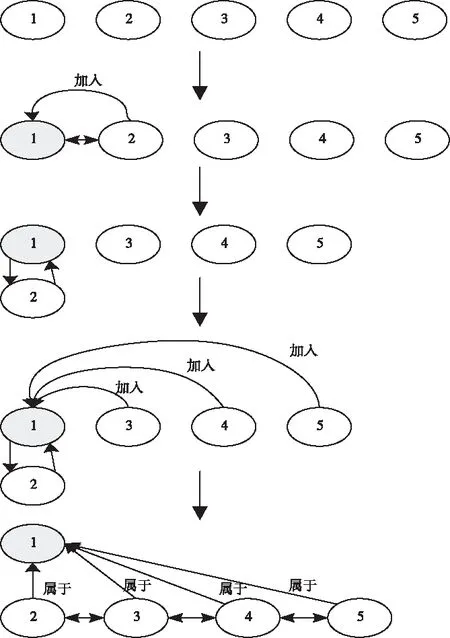
图5 MICDA迭代过程图
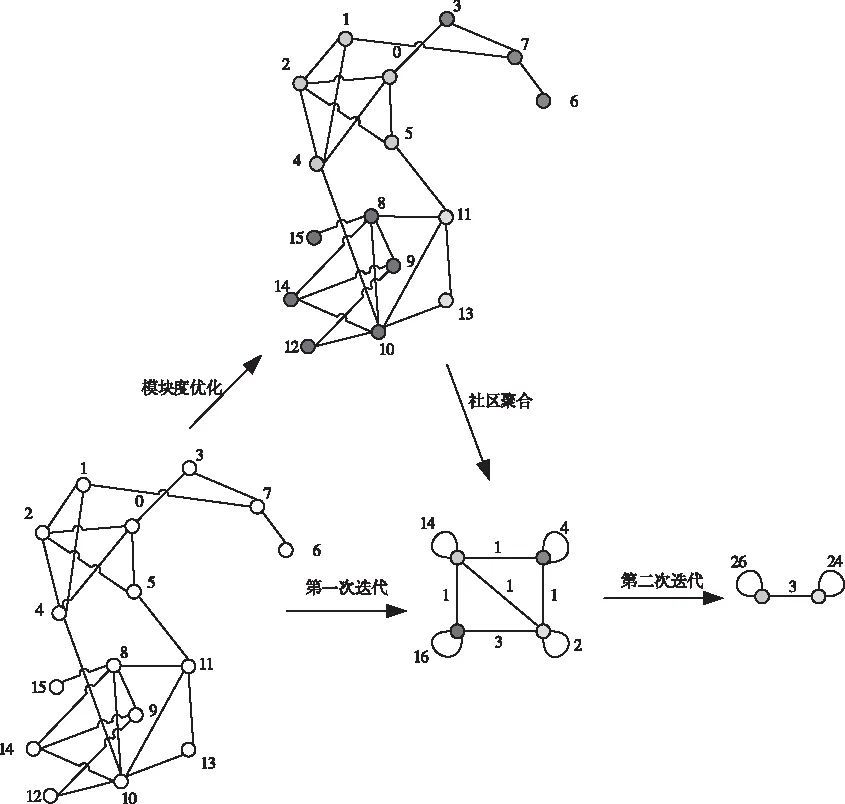
图6 MICDA算法过程示意图
图6更详细的解释了MICDA的新图的构建和权值的重新计算,MICDA算法的一次迭代分为模块度优化和社区聚合两个大步骤。模块度优化为找到当前节点的所有邻居节点,将模块度增量大于0节点加入当前节点社区,上图节点优化后分为了四个颜色社区。社区聚合就是将所有相同颜色节点归为一个新节点,如红色节点全部看作16号新节点,新节点自环权值为所有红色节点权值。从图4.2可以看出整个算法中最重要的一步就是社区聚合,将节点融合成新节点,并通过初始边关系计算新的节点与边权值。该方法的伪代码如算法2。
算法2 MICDA构建新图
输入:cluser节点社区数组
输出:聚合后新节点组成的图结构new_edge
function rebuildGraph()
int[n] change
change_size ← 0
boolean[n] vis
for i=0→n do
if vis[cluster[i]] then
continue
vis[cluster[i]] ← true
change[change_size++] ← cluster[i]
end for
int[] index ← new int[n];
for i=0→change_size do
index[change[i]] ← i
end for
int new_n ← change_size;
for i=0 → global_n do
global_cluster[i] ← new_global_cluster[i]
end for
top ← new_top
for i=0 → m do
edge[i]=new_edge[i]
end for
for i=0 → new_n do
node_weight[i] ← new_node_weight[i]
head[i] ← new_head[i]
end for
n ← new_n
init_cluster()
end function
通过算法1和式(4)可以实现MICDA算法。对karate数据集使用MICDA算法后,得到MICDA算法的模块度随着迭代次数的分布情况如图7所示。
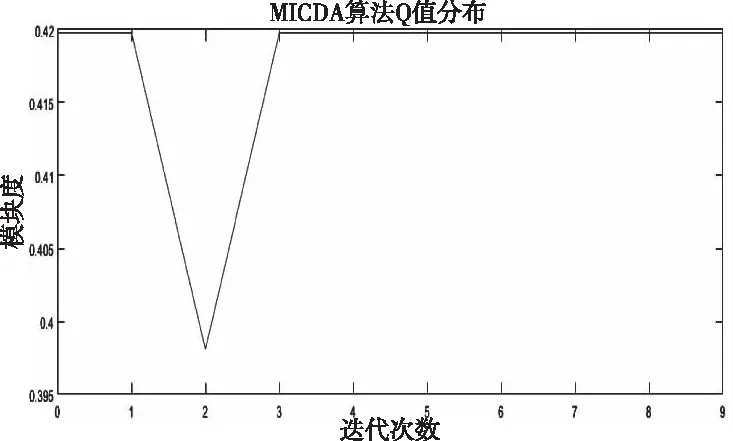
图7 karate社区划分结果
图7为每次迭代后当前模块度值,由于MICDA算法每次添加边不止一条,所以不像GN和FN算法可以曲线波动大,MICDA结果更加简洁易于理解,根据模块度峰值取社区划分最佳情况,进行数据可视化得到图8。
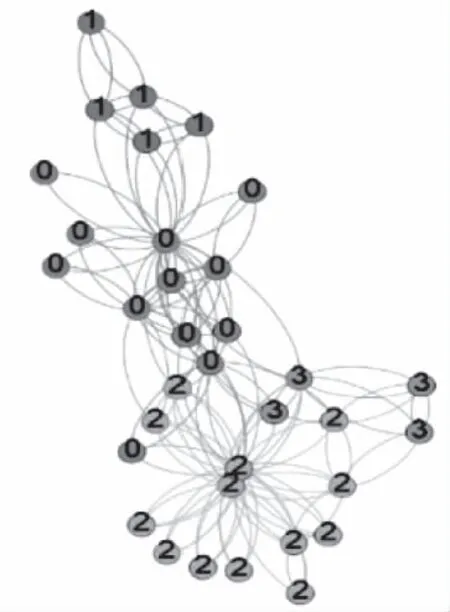
图8 MICDA社区划分结果图
5 仿真结果与分析
5.1 时间复杂度
当存在用不同方法的算法去解决一个相同的问题的时候会有时间复杂度的分析,因为不同的算法好坏是会影响整个程序的效率的,而进行算法分析的意义在于选取合适的算法以及对劣质算法进行一定改善。对于算法,时间复杂度是定性地描述运行时间的函数,一般用大O符号进行表述。
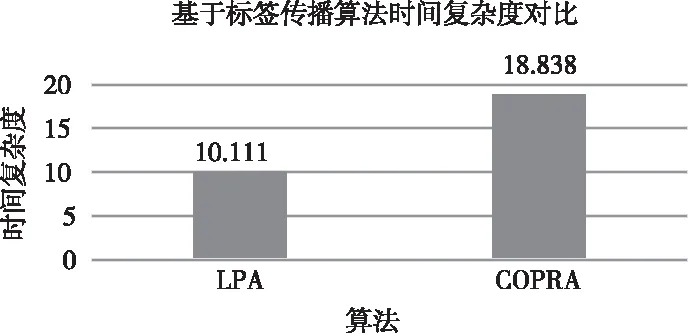
图9 微博用户数据集社区发现时间复杂度比较
图9为基于标签传播的LPA算法和COPRA算法时间复杂度对比图,两个算法均是对微博用户地区数据集进行社区发现。由上图可以看出由于LPA是非重叠社区发现算法,因此COPRA的时间复杂度比LPA更高。根据之前第三章得到的LPA和COPRA迭代次数图,LPA的收敛性明显更快COPRA。因此LPA的时间复杂度性能更好,但作为社区发现,COPRA是对重叠社区发现更具有实际意义。

图10 karate数据集社区发现时间复杂度对比
图10对COPRA算法、GN算法、FN算法以及MICDA算法的算法时间复杂度对比图,以上算法采用源数据均是karate数据集。由上图可以看出,GN算法的时间复杂度最高,MICDA算法时间复杂度最低。MICDA算法的时间复杂度性能得到了大大的提升,不管是对比基于模块度最大化的经典算法还是基于标签传播的经典算法。
5.2 模块度Q
一个适用性高的算法应该能够识别良好的社区结构[19]。人们常用的对良好社区结构划分得度量标准是模块度函数,模块化是目前常用的对网络划分稳定性进行度量的方法。模块度最早是由Newman提出的一个适用性高的算法应该能够识别良好的社区结构。人们常用的对良好社区结构划分得度量标准是模块度函数,模块化是目前常用的对网络划分稳定性进行度量的方法。模块化计算的意义在于,连接网络中两个不同类型节点的边缘比例的预期比率减去在相同社区结构下任意连接两个节点的边缘比例[20]。在对划分社区后进行当前社区结构的模块度计算,如果当前社区结构的模块度值越高,表示了该算法在当前划分情况下是最可取的。
在进行模块度计算的过程中,由于大多数的网络结构是未知的,不会需要使用网络已知的社区结构进行对比,因此模块度用来作为社区划分的评价指标是适用最广泛的。
图11为基于模块度的GN和FN算法与改进后的MICDA算法分别对karate数据集进行社区发现后,模块度分布图中出现的巅峰值。可以看出,三个算法的划分都在0.3~0.7之间取值正常,而GN算法发现的社区结构是比较差的,而改进后的MICDA算法发现的社区结构是最良好的。

图11 算法模块度对比
6 结论
本文针对社交网络的社区发现进行了深入研究,将模块度引入到社区发现检测算法中,提出了一种改进的社交网络社区发现算法。其主要工作有:①运用凝聚思想,从微博社交网络中的节点开始,按照社区划分的标准自底向上的凝聚成一个大社区;②新引入了一个模块度增量的概念;采用微博社交网络用户数据集和karate数据集上进行社区划分,并与传统的社区发现算法GN和FN进行对比分析。③提出的算法使得代码更易于实现,时间性能更高;提出的新算法在时间复杂度大大降低,降低为12%左右。
下一步将对社交网络中的重叠社区进行分析和研究。
