基于机器学习的交叉覆盖信息捕获算法研究
2021-11-17孟晓静
刘 昆, 孟晓静
(1.中国矿业大学徐海学院,江苏 徐州 221008;2.徐州医科大学医学信息与工程学院,江苏 徐州 221000)
1 引言
数据信息对于现代生产生活至关重要,通过分析挖掘可以从中获得所需的价值信息。随着数据信息的海量膨胀,给采样收集过程带来了巨大挑战。受系统中复杂因素影响,采样收集阶段经常会产生信息的交叉覆盖[1]。交叉覆盖信息一般具有非相关特征或者混杂特征[2],对数据分析形成干扰,导致信息理解偏差。因此,为了提高交叉覆盖信息的利用价值和挖掘精度,改善交叉覆盖信息的捕获性能是关键[3]。一些学者针对特定场景下的交叉覆盖信息捕获提出了相应的解决方法。文献[4]设计了一种MKELM算法,并通过极限学习实现CSP特征分类。此方法缺乏对数据分布的考虑,很容易出现过采样或者欠采样。文献[5]设计了一种ARIRF算法,通过混合采样达到样本训练目的。此方法能够有效解决采样问题,但是对数据非线性处理效果不够理想。文献[6]设计了一种EEGNets算法,通过不同的卷积策略实现神经网络。此算法虽然在一定程度上表现出较好的泛化性和准确性,但是算法初衷存在局限,导致在稳定性和鲁棒性方面表现不佳。
本文针对交叉覆盖信息提出一种基于机器学习的捕获算法。先对交叉覆盖信息采取预处理,筛除其中的非关联属性。再利用互信息良好的非线性处理,提取信息主成分特征。最后设计了基于SLFN的机器学习,根据网络输出加权完成信息分类。通过Acc、F-Measure和G-Mean三个指标进行综合检验,充分证明了算法的有效性。
2 非关联属性筛除
交叉覆盖信息存在很多噪声和缺陷,不利于直接进行数据分析,于是,先将交叉覆盖信息采取预处理,去掉其中的异常特征。对于任意的交叉覆盖信息,可以描述成集合C={c1,c2,…cn},其中ci代表第i个样本。假定ci包含的特征属性数量是m,则ci可以描述成ci={ci1,ci2,…cim},其中cim是对ci的第m个特征属性描述。ci与cj为交叉覆盖信息集合内的数据,它们和某属性t的映射关系可以描述如下

(1)


(2)

(3)
其中,ave(ci)是c所在类的局部均值集;wi是对应的加权系数。基于上述分析,特征属性t对应的加权描述如下

(4)
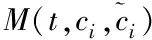
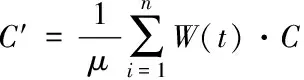
(5)
μ代表集合因子。C′保存了交叉覆盖信息的重要属性,同时筛除了其中的异常属性,更有利于后续分析处理。
3 特征提取
经过预处理阶段的非关联属性筛除后,交叉覆盖信息存在大量的冗余数据,此时直接进行分类处理,不仅会增加很多无益消耗,也会降低信息获取的性能。由于信息熵擅长描述未知信息量,因此这里利用信息熵对预处理后的数据做去冗余操作。非关联属性筛除得到的数据集标记为D,特征分布空间为Ra×b。假定D内任意数据Di=(di1,di2,…dib),dij是描述数据i对应的第j个特征量,引入信息熵可得

(6)

R(Di,Dj)=H(Di)+H(Dj)-H(Di,Dj)
(7)
其中,H(Di,Dj)利用di与dj的联合概率得到。R(Di,Dj)是通过对熵的量化确定特征属性,所以它可以应用于非线性关系场合。对所有数据特征求解互信息,得到矩阵如下
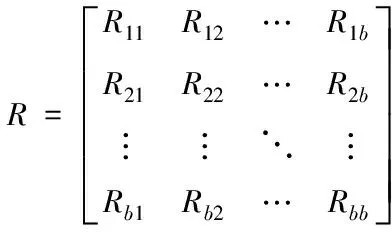
(8)
矩阵R内,R11,R12,…,Rbb为自信息,其余的均为互信息。如果变量间没有关联,则相应的互信息等于零,否则互信息一定大于零。并且,互信息满足交换性,即Rtj=Rji,由此可得R为对称矩阵。假定互信息R的特征值正序集合是r1,r2,…,rb,对应的特征向量是a1,a2,…,ab,则依据R特征值对互信息分解可得:R=A′∧A。Λ代表由r1,r1,…,rb构造的对角矩阵;A代表由(a1,a2,…,ab)构造的矩阵。根据R特征值计算主成分维度,公式如下
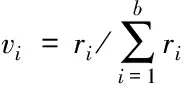
(9)
四种施工方式支护结构受力统计见表3,台阶法初支应力明显较大,其他方法在施加临时仰拱和中隔壁后等型钢后,减小了初支因弯矩产生的应力,型钢受力(见图13)在47.0 MPa~60.1 MPa。台阶法和临时仰拱台阶法,将锁脚锚管焊接于钢支撑上协调受力,能充分利用锚管锁脚作用,而CD法和CRD法的中隔壁分担了上部初支承受荷载,锁脚作用变弱。
4 基于机器学习信息捕获


(10)
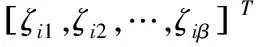

(11)
G是隐层输出;O是理想输出。为了限定网络的复杂性,对(11)引入正则化处理,如下
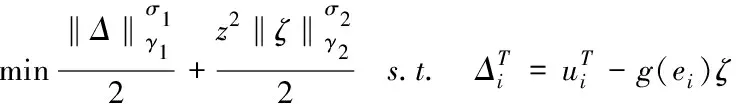
(12)
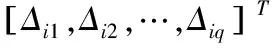

(13)


(14)
如果网络中学习数据量超过N时,则U代表N×N阶矩阵;否则,U代表M×M阶矩阵。
5 算法评价指标
交叉覆盖信息具有非平衡性,为防止捕获算法向多数类偏向,以及其它因素导致评价偏差,选取Acc、F-Measure和G-Mean三个指标来综合检验交叉覆盖信息捕获算法的性能。定义混淆矩阵如表1所示。其中Positive和Negative依次表示待预测的正负类;Positive′和Negative′依次表示预测结果的正负类。
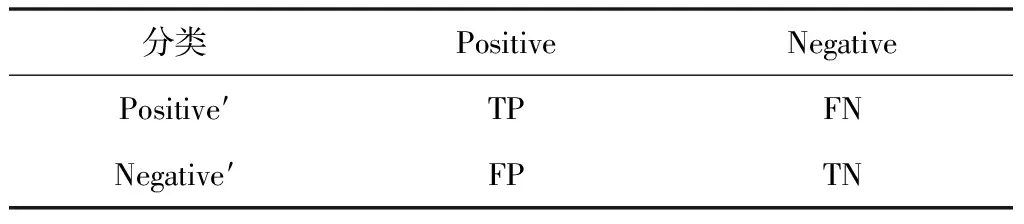
表1 混淆矩阵
Acc用于描述捕获准确率,一般在计算准确率指标时,很多文献只考虑了给定Positive被正确分类至Positive′的概率,忽略了Negative被正确分类至Negative′的情况。所以本文采用Acc,公式定义如下
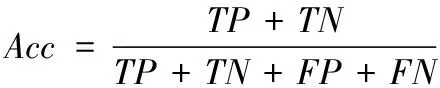
(15)
根据式(15),信息捕获的准确率同时受正负类的结果影响,该评价方式更加合理有效。
F-Measure用于描述捕获精度与召回率的综合性能。该指标不受时间序列影响,其值越大,说明分类效果越好。F-Measure公式定义为
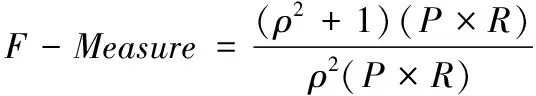
(16)
其中,P=TP/(TP+FP)表示Positive的分类精度;R=TP/(TP+TN)表示召回率;ρ表示加权调和系数。
G-Mean用于描述正负类召回率的综合指标。该指标具有良好的鲁棒性,仅当正负类的R指标均升高时,G-Mean结果才升高,有效防止非均衡数据等因素对Positive单方面的影响。G-Mean公式定义为

(17)
6 实验与结果分析
为有效验证交叉覆盖信息捕获算法的真实性能,采用表2所示的8个数据集,通过对折生成交叉覆盖信息。特征维度最低18,最高1024,涵盖低维和高维情况。为了保证检验的充分性,实验除了采用多数据集,还引入MKELM[4]、ARIRF[5]和EEGNets[6]算法进行比较。

表2 数据集描述
通过仿真得到不同数据下算法的Acc指标结果,如表3所示。可以看出,由于不同数据集的特征维度与类别等参数的差异,给交叉覆盖信息捕获带来的难度也不同,从而给捕获的Acc指标带来一定影响。madelon与GOIL20数据集复杂度相对较高,各方法在这两个数据集下的Acc指标较小。本文算法的最小Acc为0.613,较MKELM、ARIRF和EEGNets分别高出0.142、0.069、0.055。最大Acc为0.982,较MKELM、ARIRF和EEGNets分别高出0.019、0.014、0.016。

表3 Acc指标结果
通过仿真得到不同数据下算法的F-Measure指标结果,如表4所示。可以看出,数据集特征维度与类别等参数的差异同样会给捕获的F-Measure指标带来影响。在madelon与GOIL20数据集下各方法的F-Measure指标明显较低。但是本文算法的最小F-Measure为0.571,仍然较MKELM、ARIRF和EEGNets分别高出0.125、0.046、0.020。最大F-Measure为0.991,较MKELM、ARIRF和EEGNets分别高出0.046、0.019、0.018。结合Acc与F-Measure结果,表明在各实验数据集下,本文算法的捕获准确率和召回率较其它算法都更具优势,受数据集参数影响相对更小。
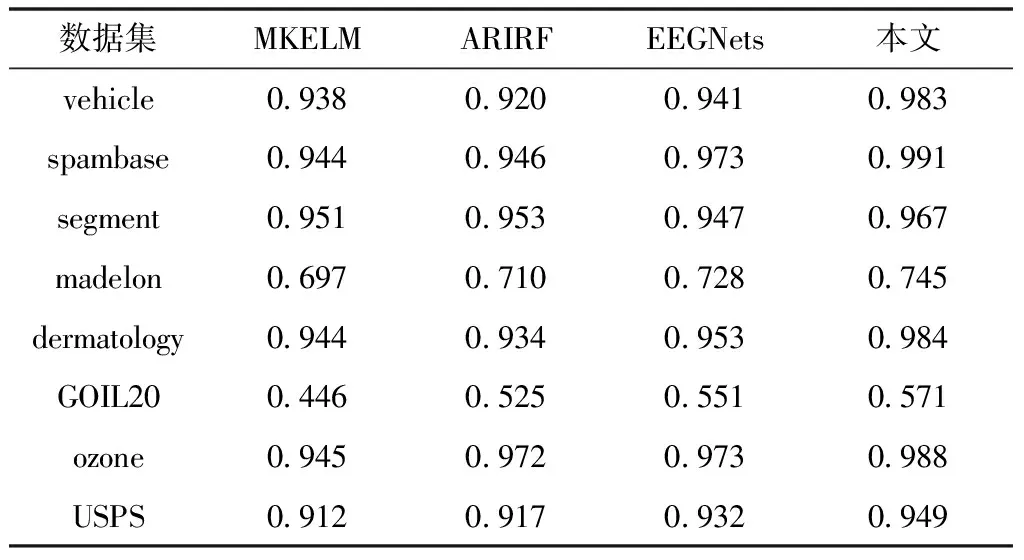
表4 F-Measure指标结果
不同数据集下的G-Mean指标结果如表5所示。可以看出,MKELM的G-Mean值波动范围是0.799~0.968;ARIRF的G-Mean值波动范围是0.855~0.941;EEGNets的G-Mean值波动范围是0.880~0.972。本文算法的G-Mean值较MKELM、ARIRF与EEGNets波动范围更小,更加稳定,且大部分情况下优于其它方法,鲁棒性更好。

表5 G-Mean指标结果
基于实验结果,本文算法在spambase数据集具有最好的综合捕获性能,于是基于spambase数据集,向其中添加噪声数据,得到不同信噪比时的捕获准确率Acc指标,结果如图1所示。可以看出,各算法的Acc曲线走势基本一致。本文算法在信噪比为30dB之前,捕获准确率受噪声影响严重,过了30dB,捕获准确率快速上升,当信噪比为37.5dB时准确率达到最高。而其它Acc曲线上升时机都迟滞于本文算法,表明本文算法的抗噪性能更好。

图1 Acc与信噪比关系曲线
7 结束语
为提高交叉覆盖信息的捕获效果,本文提出了一种基于机器学习的捕获算法。首先对交叉覆盖信息采取预处理,去掉其中的异常特征。然后根据信息熵对预处理后的数据做去冗余操作,并利用互信息矩阵提取主成分特征。最后设计了机器学习网络模型,通过求解网络输出加权确定数据分类,实现信息捕获。基于不同数据集的仿真,得到本文方法的平均Acc为0.895,平均F-Measure为0.897,平均G-Mean为0.939,各项指标均优于对比方法。表明本文算法具有更好的准确率和召回率,鲁棒性和抗噪性得到显著提升。
