EDA 文本增强技术在中英文语料上的差异性分析
2021-11-15靳大尉王雯慧
靳大尉,王雯慧
(陆军工程大学指挥控制工程学院,南京 210000)
0 引言
数据驱动的机器学习模型训练中模型的精度与模型的复杂度往往成正比。但这种正比的前提是要有足够多的训练样本数据,否则很容易造成欠拟合现象。在很多实际的项目中,难以有充足的数据来完成训练任务,为了提升模型的泛化能力,要么寻找更多的数据,要么充分利用已有的数据通过数据增强技术来产生新样本。
在计算机视觉领域,已有旋转、缩放、剪切等通用增强方法。文本数据增强实践中,Jason Wei等人提出了一套简单的用于自然语言处理的通用数据扩充技术EDA[1],并针对其在英文文本上的应用效果进行了研究。为了研究EDA技术在与英文文本差距较大的中文文本上的应用效果,本文选择三种公开中文语料和文本分类任务,在中文数据集上实验并验证了EDA技术的增强效果,并分析了中英文文本语料上EDA增强技术的应用差异,提出了中文数据集中推荐的增强参数,同时验证了EDA技术在以Bert为代表的预训练语言模型上的应用效果。
1 文本增强方法概述
依据文本增强的原理不同,文本增强的技术可以分为面向原始文本的增强方法和面向文本表示的增强方法两种。
面向原始文本的增强方法主要是通过对原始文本中的字词进行操作来进行增强。大部分研究都通过引入各种外部资源来提升增强效果,包括同义词、外部噪声等。除了典型的EDA技术,还包括基于复杂模型的增强方法,如条件BERT(CBERT)[2]和利用RL来选择增强操作[3]。
面向文本表示的增强方法是对原始文本的特征表示进行处理,比如利用在表示层注入随机噪音等方法获得增强后的文本表示。增强后的表示可以再进行解码获得增强文本或者直接用于训练模型。这方面的代表包括Szegedy等人提出的利用标签平滑(label smoothing)来提升模型泛化能力[4];Zhang等人提出的基于Mixup的文本增强方法[5]以及Malandrakis等人提出的受限变分自编码器(CVAE)[6]等文本增强技术。
相对于面向表示的文本增强方法,面向原始文本的增强方式通常是对句子内容进行微调,实现较为简单,增强比例可自由调整,效率更高;能够直接观察增强后的数据内容,具有更好的可读性和可解释性。EDA方法的四种基本操作包括:同义词替换(SR)、随即插入(RI)、随即交换(RS)以及随机删除(RD),较好的代表了原始文本增强方法“多、快、好、省”的特点。
2 实验设计与结果
本实验选择了三种文本分类任务的数据集和两种基本模型框架以及一种预训练模型来研究EDA技术在中文文本上的应用效果,并与英文进行对比。
2.1 数据集介绍
本实验使用了三类中文数据集,涵盖短文本、长文本、二分类以及多分类数据,简要介绍如下:
(1)短文本二分类[7]。采用酒店评价数据集hotel,共7000多条酒店评论数据,分为正面、负面两个类别,其中5000多条正向评论,2000多条负向评论;
(2)短文本多分类[8]。采用今日头条新闻标题数据集tnews,其中训练数据53360条,验证数据约10000条,测试数据约10000条,共分为15个类别,类别数据量相差较大;
(3)长文本多分类[9]。采用复旦大学中文文本分类语料fudan,选取C19、C31、C34、C39四类文档,分别包含2712、2436、3201、2507条数据。
EDA方法对于英文小数据集的增强作用较为明显,本文对于中文数据集采用了相同的方法,将数据划分为不同大小的数据集进行研究,同时改变文本增强百分比、增强句数等参数进行实验验证。
文本增强百分比参数代表一个句子中参与增强的字词所占句子长度的百分比。例如,一个句子长度为100,增强百分比为2%,那么参与增强操作的词最多不超过两个。
增强句数参数表示一句话进行增强操作后新形成的句子的数量。例如,设定增强句子数参数为9,那么一句话分别进行9次增强操作,形成9个新句子参与训练。同时默认的增强操作包括:对句子的30%进行同义词替换操作,进行随机插入操作,插入比例为句子的20%,对句子的10%进行随机交换操作,对15%的句子进行随机删除操作,百分比计算结果均向下取整。
2.2 模型与文本分类任务选择
为了能够反映文本增强技术对于模型结果的影响,不失一般性地采用简单的RNN[10]、CNN[11]和基础的Bert模型。RNN模型包括两层RNN隐藏层以及两层全连接层;CNN模型包括一层CNN层、一层最大池化层以及两层全连接层。Bert模型采用基于Pytorch的Bert-base-chinese模型[12]。
文本分类任务是自然语言处理中的一项基本任务,其评判规则较为明确,能较有效的衡量一个模型的准确率,从而反映出文本增强技术的作用效果。文本分类任务可以分为短文本分类和长文本分类任务,也可划分为多分类任务和二分类任务。本文实验任务涵盖以上各种文本分类任务。
2.3 EDA应用效果
2.3.1 EDA技术应用效果概述
为了能够准确反映出EDA技术的效果,本文分别从三个数据集划分抽样出500、2000、5000条,组成不同大小的数据集,同时保留原始数据集大小,四种大小的数据集分别用tiny、small、standard、full set代表。分别利用随机删除、随机插入、随机交换以及同义词替换操作对其原始文本进行增强,同时文本增强百分比从0逐步增加到1。分别利用增强后的数据集训练RNN、CNN模型,通过预测模型的准确性衡量增强效果。最终将增强后的模型表现分别求平均,得出利用EDA技术训练后的平均模型准确性。多次利用原始数据集训练模型,分别得出其准确性求取平均,得到未经增强操作的模型准确性表现作为基准,与增强后的模型的平均表现对比,最终形成模型准确性数据见表1。
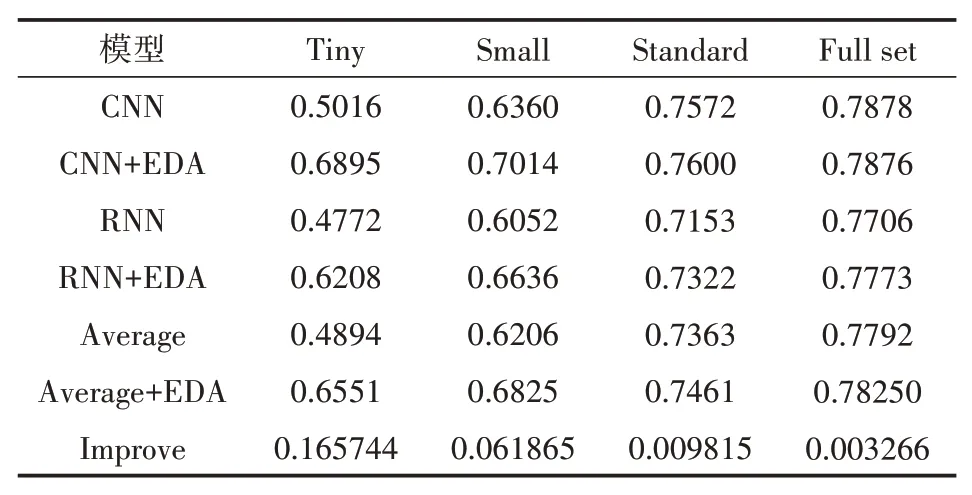
表1 EDA增强后模型平均准确性及原始准确性
表1中数值代表各模型训练后的准确度,最后一行代表模型的准确度提升的平均值。表中的结果显示,虽然RNN模型的表现不如CNN模型,但是EDA技术对两个模型均有一定的提升效果,这种效果相差不大,对RNN模型的提升效果相较而言较好。采用EDA技术,对于所有大小的数据集,模型的准确性均有一定的提升,并且随着数据量的增多,模型的提升效果逐渐减小。当数据集仅为500条时,EDA技术能够有效的提高模型的表现,使得准确率平均提升了大约16.6%;当使用所有的数据集进行训练时,模型平均准确率仍有超0.3%的提升。
2.3.2 不同数据集大小下增强的性能比较
为了更精准的验证不同数据集大小下增强方法的效果,我们在三个数据集上进行随机抽样,分别抽取{1,5,10,20,30,40,50,60,70,80,90,100}不同百分比的数据子集作为训练集,训练了原始模型以及EDA技术增强后训练所得的模型。对于多次实验进行结果平均,图1展示了最终实验的结果。

图1 不同大小数据集下增强方法性能比较
从图1可以看出,使用EDA技术和不使用EDA技术训练所得的模型准确率均出现由低至高的变化趋势,最后两者趋近统一,得到大致相同的最高准确性。总体而言,使用增强技术能可以尽快到达准确度稳定的阶段,即仅使用较少的数据(20%~30%)进行模型训练能够获得较高的准确度。注意到当采用5%~10%的数据的时候,利用原始数据训练模型,模型会在hotel以及fudan数据集上出现模型的准确度的大幅“波动”。此现象在利用EDA技术增强后的数据集进行模型训练时并未出现,说明EDA技术能够增加小数据集上的模型表现稳定性。
2.3.3 不同增强方式下增强的性能比较
为验证不同增强方法的提升效果,从三类数据集中分别随机抽取tiny、small、standand和full四个不同数量集合,选择{5,10,20,30,40,50}的文本增强百分比,对基于四种增强操作增强后的模型进行了准确性测试。多次训练模型并且评估模型准确性,进行平均后得到最终实验结果,如图2所示。

图2 不同增强方式性能提高比较
如图2,实验结果证明,四种EDA操作都有利于提高模型的性能,同时对于小数据集的增强效果最为明显,均能够将模型准确率提升30%左右,对于大数据集效果较差,平均仅提升1.5%左右。
具体增强操作上,同义词替换SR操作增强效果较好,提升比例超过35%,随机插入RI增强效果较差,提升比例仅为25%~30%左右。究其原因,同义词替换操作在尽可能保留原始句子信息的情况下进行句子改写,与原句之间的相似度较高;随机插入操作在句子中引入了外部噪声,即有可能较大的改变原句的意思,相似距离较大。随即交换RS以及随机删除RD操作的提升比均在30%~35%之间,进行操作后句子的变化不如随机插入,也对提升模型质量有一定作用。
2.3.4 不同增强句数的性能比较
每个原始句子所生成的增强句子的个数即数据集扩充的大小对实验结果也会产生一定的影响。本文采用不同的增强句数参数,分别对应{1,2,4,8,16,32},比较模型的平均性能。利用CNN和RNN模型以及EDA技术进行了实验,最后结果如图3所示。
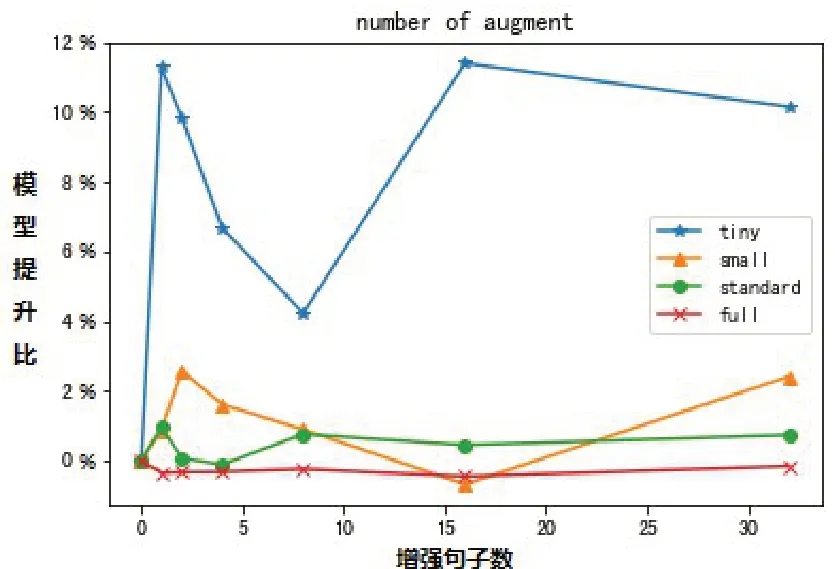
图3 不同增强数量的性能比
由图3可以看出,对于数据量较小的模型,EDA增强句数的大小对结果的影响显著;对于较大的数据集,无论增强句数参数大小也无明显的模型提升作用。所以增强的句数不是越多越好,但是对于小数据集可以适当的增多增强句子数。不准确的增强数据也会对模型表现造成一定的干扰,往往出现应用增强技术之后性能不升反降的情况。
2.3.5 数据增强后分类标签一致性判定
文本数据增强后类标签保持不变是有效增强的必要前提。我们通过增强操作后模型预测的标签一致性来检验EDA操作是否显著地改变了句子的意义。
首先,不应用EDA技术在原始完整数据集上训练了一个RNN。然后将EDA技术应用于测试集,每个原句生成9个新句子,采用数据集介绍中的默认增强操作。这些增强后的句子和原始的句子一起被送入RNN,统计增强后的句子标签预测情况与原始句子标签预测情况是否一致,最后以此检验增强操作是否会改变句子的原始标签。
以Hotel数据为例,测试集大小为671,增强后的数据有6039条。根据表2可以看出,EDA操作基本不改变增强句子的情感色彩,增强导致标签更改的样本的占比仅为1%。

表2 EDA增强标签一致性统计表
3 EDA技术在中文预训练模型的应用
Jason Wei等人猜想EDA技术在该类预训练语言模型上可能不会发挥作用,甚至出现反作用[1]。本文利用中文Bert预训练语言模型[12],结合EDA技术验证其对于该类模型是否能提升其下游任务的表现。
最终实验结果如表3和图4中所示,EDA技术在预训练语言模型的基础上仍有其提升空间,能够有效提升模型最终预测的表现,并且与基本模型对不同的数据集的作用规律基本表现一致。但因数据集过小的影响,使用Bert模型的分类效果普遍不及RNN或CNN模型。
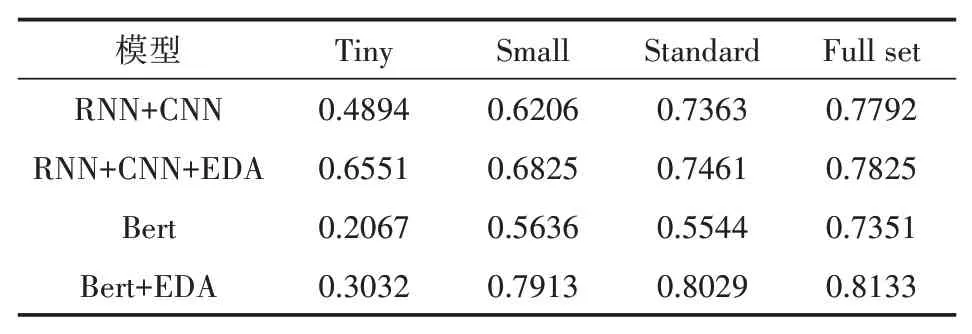
表3 EDA技术在预训练语言模型上的表现
图4给出了通过对于不同操作在Bert模型上的提升,随机插入操作与随机删除操作对于模型的影响基本一致,同义词替换操作以及随机交换操作基本一样。前两者主要是在句中加入噪音,后两者涉及到语言学的部分变换,语言学的变化会导致部分的信息损失。同义词替换操作以及随机交换操作在增强比例到达0.2左右就开始下降,0.3时下降到最低点。当增强百分比继续增加,损失效果出现抵消,提升比转为上升趋势。
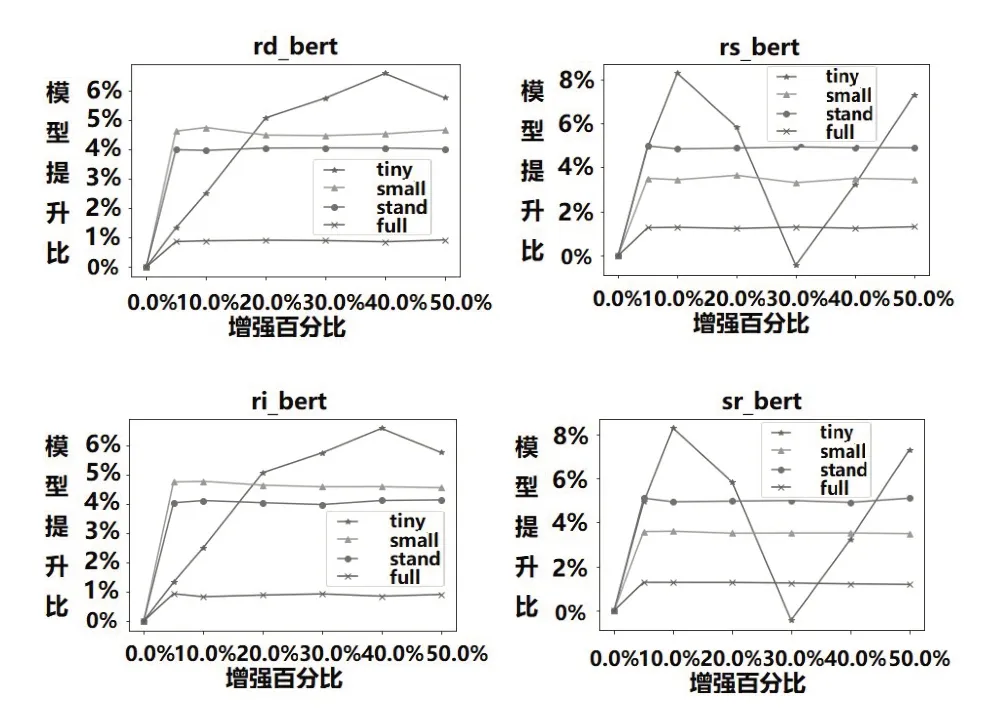
图4 Bert模型上不同增强方式性能提高比较
4 中英文数据集的不同对比
中文文本与英文文本特点具有较大的不同,导致EDA技术在中英文数据集上的表现有差异也有相似。语言信息熵[13]相关理论指出,中文每个字提供的信息量大于英文数据量,字与字之间的关联更小,这可能会导致增强技术的效果不同。
如表4所示,不论中英文数据,EDA技术针对小数据集上训练的分类模型准确性的提升作用更为明显;EDA技术在中文数据集上的平均应用效果高于英文数据集上的效果;当数据集大小超过5000条之后,模型的提升作用基本不发生变化,中英文均趋于平缓。同时,在中文文本中,由于中文文本信息熵较大,应用EDA技术对于原始文本进行改变之后增加、改变或者删除的信息量较大,模型的泛化效果得到提升,导致在中文文本上的增强作用强于英文文本,最好的增强结果可以达到英文增强效果的十倍。
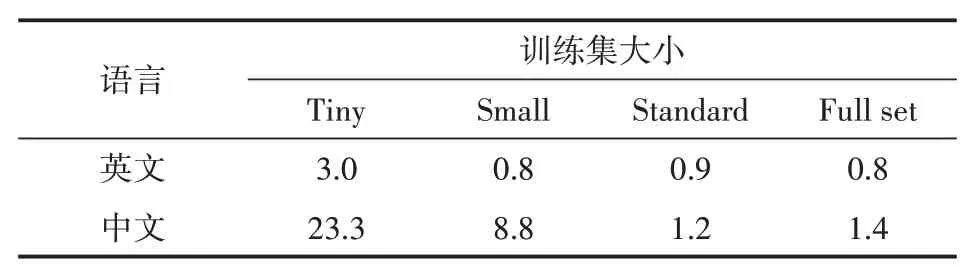
表4 中英文不同大小数据集EDA技术的平均提升度对比
通过上文对于不同增强方式、增强比例以及增强句数对于模型准确性提升的影响的研究,可以得到中文数据集推荐的经验增强参数,最终形成表5,其中文数据来源于Jason Wei等人的实验结果[1],且均以在中文实验设备上进行了验证。
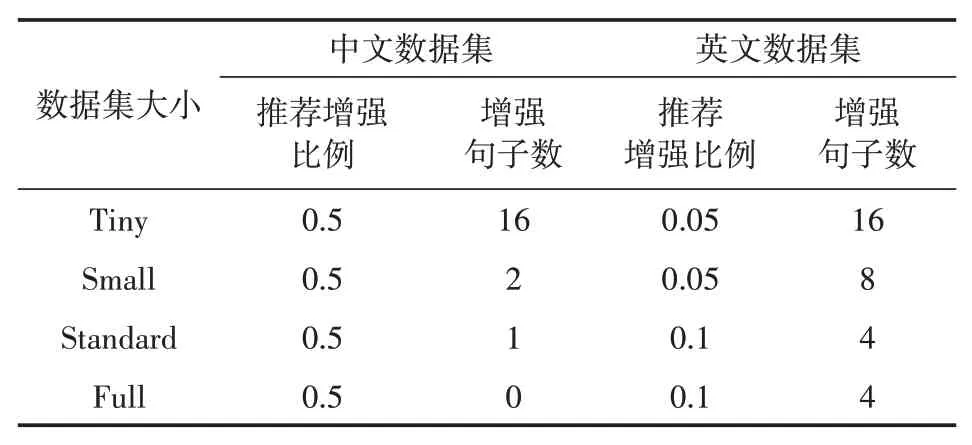
表5 中英文推荐增强参数对比
根据表5,中英文在不同数据量上增强比例与增强句子数对比,可以发现中英文数据集在小数据集上推荐的增强句子数均较大,之后随着数据集的增大逐渐减小,中文减少的速度更快。
文本增强技术通过改变句子的表述,扩充训练数据集以提高模型训练的效果,但是为了保证数据的真实有效不可过分改变句子的意思,所以本文推荐将句子的增强比控制在0.5之内。根据上文所述不同增强方式下增强的性能比较实验中,各增强方式增强效果随增广比例的上升均出现一定的上升,同时数据增强后分类标签基本保持一致。所以推荐的中文数据集增强比均为效果较好的0.5。
中文文本上下文关联性比英文文本小,当增强百分比较小时,增广后的句子基本与原句保持一致,所含信息熵以及表述方式较为类似,无法较好起到扩充原数据集实现数据增强的效果,所以中文文本中的推荐增强比较英文数据集相比均取值较大。
5 结语
本文的研究结果表明,EDA技术包含的四项基本文本增强技术可以提升中文文本分类模型的准确率,在对文本增强的有效性上,具有中英文的适用性。EDA技术采用不同增强方式的增强效果不尽相同,但平均效果还是比较明显的。由实验可知,随机删除操作以及近义词替换操作可能会损失原句的信息,建议搭配随机交换与随机插入操作进行信息弥补,以减少句子信息的损失做到有效的增强。
此外,实验证明EDA技术除了在基本的RNN、CNN语言模型上能够有效的提升模型的表现,在Bert等预训练语言模型上也有其用武之地。在数据集较大的情况下,Bert模型配合EDA技术能够有更好的表现与提升效果。
