基于知识图谱元路径的协同过滤算法
2021-11-15潘怀奇覃正优
潘怀奇,覃正优
(1.广西国际商务职业技术学院信息工程系,南宁 530007;2.南宁师范大学计算机与信息工程学院,南宁 530100)
0 引言
随着互联网技术的飞速发展,网络上每天都在产生数以亿计的数据,海量的数据信息在给我们提供更多选择的同时也给我们查找自己所需信息带来了困扰。比如,当我们不能清楚地描述我们需要的东西或者没有明确的需求时,面对海量的数据我们就会无从下手。
推荐系统就是为解决上述问题而诞生的。协同过滤算法(collaborative filtering,CF)是推荐系统中最早出现的,也是最经典的推荐算法。协同过滤算法可以分为基于用户的协同过滤算法(UserCF)[1]和基于物品的协同过滤算法(Item⁃CF)[2]。当使用UserCF算法为用户作Top-N推荐时,首先根据用户历史行为数据为目标用户寻找与其最相似的K个用户,将这K个用户已选择但目标用户没有选择过的N个物品推荐给目标用户。以电影推荐系统为例,假设用户A看过电影《喜剧之王》、《功夫》、《无名之辈》,用户B看过电影《喜剧之王》、《哪吒之魔童降世》、《速度与激情》,当使用UserCF为用户A推荐电影时,因为用户A和用户B都看过《喜剧之王》,所以他们具有一定的相似性,从而推荐系统可以从用户B看过而用户A没有看过的电影:《哪吒之魔童降世》和《速度与激情》这两部电影推荐给用户A。如果对用户A的历史行为进行深入分析,我们可以看出,用户A看过的《喜剧之王》和《功夫》都是周星驰主演的电影,可见用户A很喜欢周星驰主演的电影。但是UserCF算法仅考虑了用户的历史行为,不能发现用户具体的兴趣所在。为了让推荐的产品更好地满足用户的需要,我们必须了解用户的兴趣。为此,本文提出了一种基于知识图谱元路径的协同过滤算法,首先构建领域知识图谱,然后基于知识图谱元路径刻画出用户对物品各方面的兴趣分布,从而可以结合用户的兴趣进行推荐。最近的研究表明,知识图谱能有效地处理推荐算法传统的冷启动和数据稀疏问题,从而提升推荐算法在推荐中的准确率。因此,本文提出基于知识图谱元路径的协同过滤算法(KGUserCF)来增强UserCF算法的推荐效果。本文的贡献可以概括如下:①以电影数据集MovieLens-1M为基础构建了电影领域的知识图谱;②基于知识图谱元路径计算得到用户各方面的兴趣分布;③根据用户的兴趣分布情况结合UserCF算法计算用户的相似性,从多方面为用户做出有效推荐;④在电影数据集MovieLens-1M上,通过实验验证KG-UserCF的有效性。
1 相关工作
1.1 基于邻域的协同过滤算法
基于邻域的协同过滤算法分为基于用户的协同过滤算法和基于物品的协同过滤算法。1992年Goldberg等人提出了基于用户的协同过滤算法,该算法的基本思想是,根据目标用户的历史行为记录寻找与其拥有相似历史行为记录的K个用户,将这K个用户有过正反馈并且目标用户没有过行为的N个物品推荐给目标用户。这其中,最重要的是用户之间的相似度计算,传统的相似度计算使用余弦相似度,其公式为:
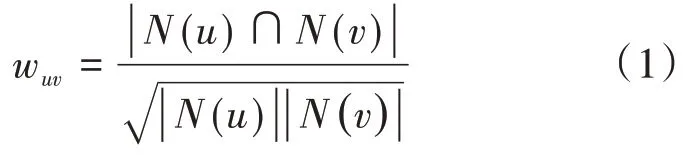
公式(1)中,N(u)和N(v)分别表示用户u和用户v有过正反馈的物品集合。其次,就是计算目标用户对候选列表物品的感兴趣程度。在与目标用户u最相似的K个用户集合中,喜欢物品i的用户越多,并且这些用户与目标用户u的相似度越高,以及这些用户对物品i的评分越高,那么目标用户对该物品i的感兴趣程度就越大。用p(u,i)表示目标用户u对物品i的感兴趣程度,可得到如下公式:
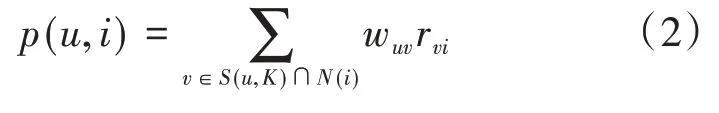
其中,S(u,K)表示与目标用户u最相似的K个用户集合,N(i)表示喜欢物品i的用户集合,rvi表示用户v对物品i的评分。由于基于用户的协同过滤算法简单有效,因此被广泛运用于各种推荐系统当中,但是该算法面临数据稀疏的问题,也不能很好的对推荐结果做出解释。Badrul Sarwar等人提出了基于物品的协同过滤算法(ItemCF),Item⁃CF算法同样是基于用户的历史行为记录计算物品的相似度,其主要思想认为,若两个物品同时出现在越多用户的历史行为记录中,那么这两个物品的联系就越紧密。在给目标用户推荐物品时,ItemCF算法根据目标用户的历史行为记录,找到与目标用户有过正反馈的物品的强关联物品推荐给目标用户,完成推荐。在电商推荐系统中,ItemCF算法的可解释性通常表现为“购买了该商品的用户也购买了某商品”。无论是基于用户还是基于项目的协同过滤算法都是在评分矩阵的基础上计算用户或者物品的相似度,虽然在一定程度上能表示用户或者物品之间的相似度,但是仍然面临数据稀疏的问题。
1.2 隐语义模型
隐语义模型(latent factor model,LFM)[3],也被称作FunKSVD,是FunK S在2006年Netflix Prize大赛中提出的一种机器学习的推荐算法。LFM假设物品有F个隐藏的类别,通过机器学习方法在包含正负样本的数据集上学习获得物品在每个隐类所占的权重以及用户对每个隐类的感兴趣程度。LFM算法的损失函数如下:
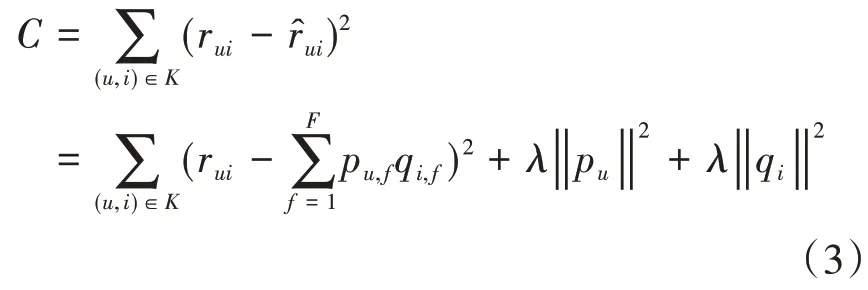
其中,K是包含正负样本的数据集,rui表示用户u对物品i的真实评分,表示算法预测用户u对物品i的评分,通过模型参数pu,f和qi,f计算得到,而pu,f和qi,f分别表示用户对每个隐类的感兴趣程度和物品在每个隐类所占的权重,是模型的正则化项。LFM模型通过不断减小损失学习得到pu,f和qi,f两个参数之后,就可以通过公式(4)计算用户u对物品i的感兴趣程度了。
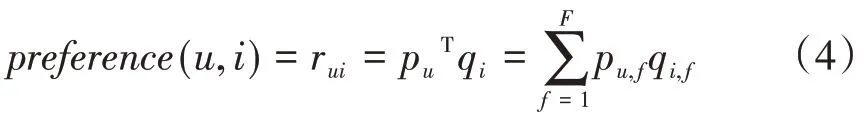
在LFM模型之后出现了许多改进的模型,比较著名的有增加偏置项的BiasSVD[4]和考虑领域的SVD++[5],BiasSVD算法认为用户对物品的评分会受到用户评分标准和物品本身受欢迎度的影响,因此在评分预测中增加了用户和物品的偏置项。这一系列的模型在评分预测这一任务上取得了显著的效果,但是我们并不明确其中每个的隐类f所代表的具体的语义,因此不能对推荐结果做出可解释性。
1.3 基于知识图谱的推荐算法
知识图谱以结构化的形式描述客观世界中的概念、实体及其关系,将互联网的信息表达成更接近人类认知的形式,提供了一种更好地组织、管理和理解互联网海量信息的能力。知识图谱由于包含丰富的实体、属性、概念及其之间的关系,因此被广泛应用于推荐系统中。Yizhou Sun等人[6]将知识图谱视为一个异构信息网络,提出元路径的概念来计算异构信息网络中节点之间的相似性。Huang Z等人[7]针对元路径不能处理异构信息网络中节点之间更复杂的关系提出了元结构来度量节点之间的相似性。此外,还有使用知识图谱结合深度学习的方法,如,Palumbo E等人[8]根据关系类型在电影知识图谱上划分子图,使用node2vec[9]的方法将各个子图的电影实体和用户实体嵌入到低维向量空间中,然后将得到的实体在各个子图中的表示作为实体特征输入LambdaMart排序算法中,最后将排在前面的N个电影推荐给相应的用户。吴玺煜等人[10]针对协同过滤算未考虑物品自身语义信息的问题,提出了基于知识图谱表示学习的协同过滤推荐算法TransE-CF,TransE-CF首先利用TransE[11]模型将知识图谱中的实体映射到低维的向量空间,再融合协同过滤算法做出推荐。
传统的协同过滤算法和隐语义模型都是基于评分矩阵,忽略了物品本身的语义信息;基于元路径或元结构的方法在计算相同类型节点的相似性时,抛弃了原有的用户评分信息;结合知识图谱和深度学习的方法不能很好地对推荐结果做出解释。综上所述,本文提出一种基于知识图谱元路径的协同过滤算法KG-UserCF,在考虑物品自身语义信息的同时也结合了用户-物品的评分矩阵,既能弥补传统协同过滤算法所面临的数据稀疏问题又能够对推荐结果做出可解释性。
2 电影知识图谱的构建
电影数据集MovieLens-1M包含6 040名用户对大约3900部电影的1000209条评分。在先前的研究中,Ostuni V C等人[12]已经将电影数据集MovieLens-1M中的3900部电影映射到了开放链接数据DBpedia相应的实体表示,因为并不是每一部电影都能在找到DBpedia相应的实体表示,映射后共得到3226部电影实体在DBpedia中的实体表示。在此基础上,我们利用Sparql查询语言在DBpedia的终端获取这3226部电影实体的导演、主演、编剧、语言、电影类型等相关属性,我们最终获得了其中3226部电影的6100多名演员和1630多名导演。将得到的数据存储在图数据库Neo4j中,形成包含16860个节点和397631条关系的电影知识图谱。
3 基于知识图谱元路径的协同过滤算法
本节将具体介绍基于知识图谱元路径的协同过滤算法。元路径是定义在知识图谱架构层上的路径,节点代表实体类型,边代表关系类型。在图1(a)中,我们示例出了两条元路径P1和P2,P1是从用户到电影再到演员的元路径,P2是从用户到电影再到导演的元路径。在电影知识图谱中为每一位用户匹配P1、P2两条元路径下的具体实例路径,例如,对于用户1我们使用Cypher查询语句在Neo4j中可得到如图1(b)中的具体实例路径,它们分别表示用户1观看过Apollo_13_(film)这部电影,而且这部电影的主演有Tom_HanKs,导演是Ron_Howard。通俗地讲,如果用户1对m部电影有过正反馈,其中的n部电影是演员a1主演的,那么用户1对演员a1的兴趣程度为n/m,通过公式(5)和(6)可以计算得到用户对演员的兴趣分布矩阵wua和用户对导演的兴趣分布矩阵wud。
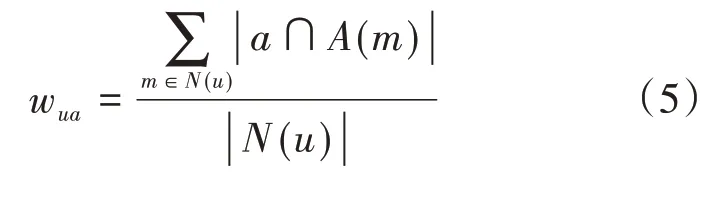
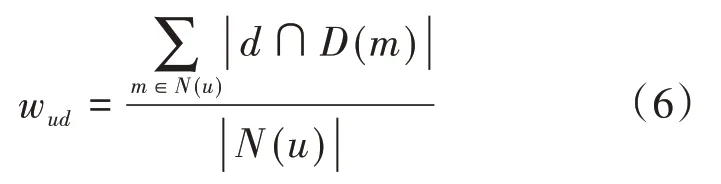
其中,N(u)表示用户u有过正反馈的电影集合,A(m)表示电影m的演员的集合,D(m)表示电影m的导演的集合,a表示演员,d表示导演。
获得用户的兴趣分布矩阵之后,就可以利用UserCF算法分别计算用户在演员方面和导演方面上的相似性。与传统UserCF算法不同的是,KG_UserCF算法不再使用原始的用户-物品评分矩阵,而是使用经过电影知识图谱元路径映射后的用户-演员、用户-导演兴趣分布矩阵,通过结合物品本身的语义信息来详细刻画用户的兴趣所在,从而达到缓解数据稀疏的问题和对推荐结果做出解释的目的。用户之间在演员方面上的相似性可用数学公式可描述如下:
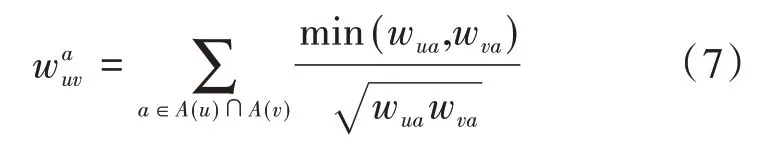
其中,A(u)和A(v)分别表示用户u和用户v有过正反馈的电影的演员集合,min(wua,wva)表示取wua和wva中最小的值。用户之间在导演方面上的相似性计算如下式:
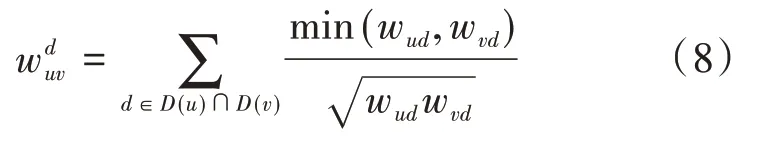
在得到用户之间在演员方面和导演方面上的相似性之后,分别选取与目标用户在演员方面上最相似的K个用户和在导演方面上最相似的K个用户,再将这2K个用户有过正反馈且目标用户未观看过的电影作为两个候选列表,接着通过公式(9)和(10)对候选列表分别进行排序:
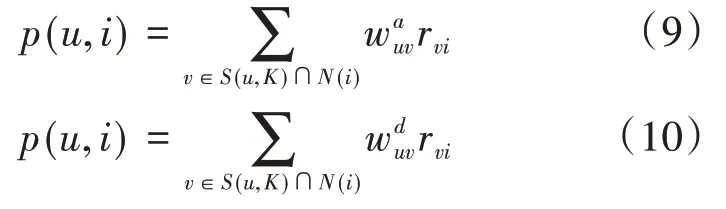
选取排序靠前的N个物品生成推荐列表,最后融合基于用户对演员兴趣生成的推荐列表和基于用户对导演兴趣生成的列表得到最终的推荐列表。整个KG_UserCF算法流程如图2所示。

图1 元路径与实例路径
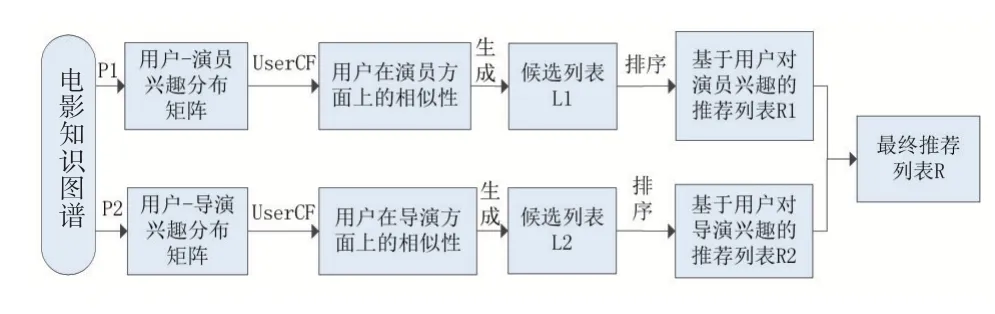
图2 KG_UserCF算法流程
4 实验与结果分析
4.1 数据集介绍
本文使用电影数据集MovieLens-1M作为实验数据,该数据集包含6040名用户对大约3900部电影的1000209条评分。我们通过将3900部电影实体映射到开放链接数据DBpedia后获得了其中3226部电影共6100多名演员和1630多名导演。以此构建的电影知识图谱包含用户、电影、演员和导演4种实体类型以及feedbacK、starring和di⁃recting 3种关系类型,共16860个实体节点和397631条关系。
4.2 评价指标
本文最终主要是给用户作Top-N推荐,因此采用推荐系统中常用的准确率(precision)、召回率(recall)和F1-score作为评价标准。准确率表示在电影推荐列表中用户有过正反馈的电影数量占推荐列表总电影数的比例,本实验取推荐列表的长度N=10。准确率的公式如下:
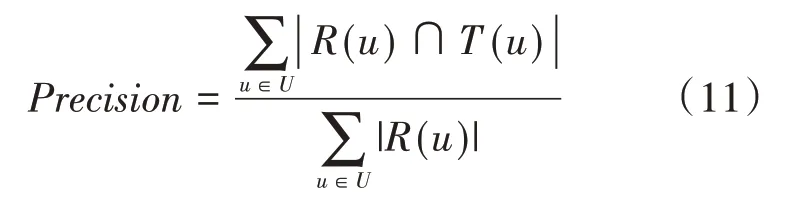
其中,R(u)是根据用户在训练集上的行为给用户u做出的推荐列表,T(u)是用户u在测试集上的行为列表。召回率描述的是推荐列表中用户有过正反馈的电影数量占测试集中电影数的比例。其公式如下:
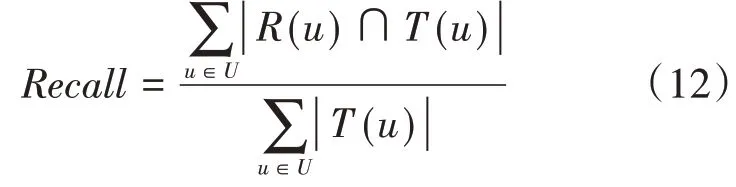
而F1-score则综合了准确率和召回率来衡量推荐效果的好坏,的值越大表示推荐的效果越好。其公式表示如下:

4.3 实验对比
KG_UserCF作为传统UserCF算法的改进,我们将UserCF、ItemCF、最近邻算法ItemKNN,以及隐语义模型系列的LFM、SVD、NMF模型作为对比。此外,为了验证KG_UserCF融合了用户多方面兴趣特点的有效性,我们还对比了仅考虑用户对演员单方面兴趣时的推荐方法KG_User⁃CF_BoA和仅考虑用户对导演单方面兴趣时的推荐方法KG_UserCF_BoD。
4.4 实验结果分析
4.4.1 实验参数设置
我们将原始的1000209条评分数据按8∶2的比例随机划分为训练集和测试集。推荐列表的长度N=10。为了确定相似用户的数量K最佳取值,我们以10为步长,从[20,80]中选取不同的值进行实验,得到不同K值下的准确率、召回率和覆盖率,分别如图3、图4和图5所示。从图3中可以看出当相似用户数量达到50后,准确率的上升趋势减缓;而图4中的召回率整体变化不大;但是在图5中,当相似用户数量到达30以后,覆盖率就明显下降,这说明选取的相似用户数量越多,推荐的结果就越趋于大众化,因此,综合考虑,我们在对比其他算法时统一选取相似用户数量K=50,在确保较高的准确率的同时又不至于导致覆盖率太低。
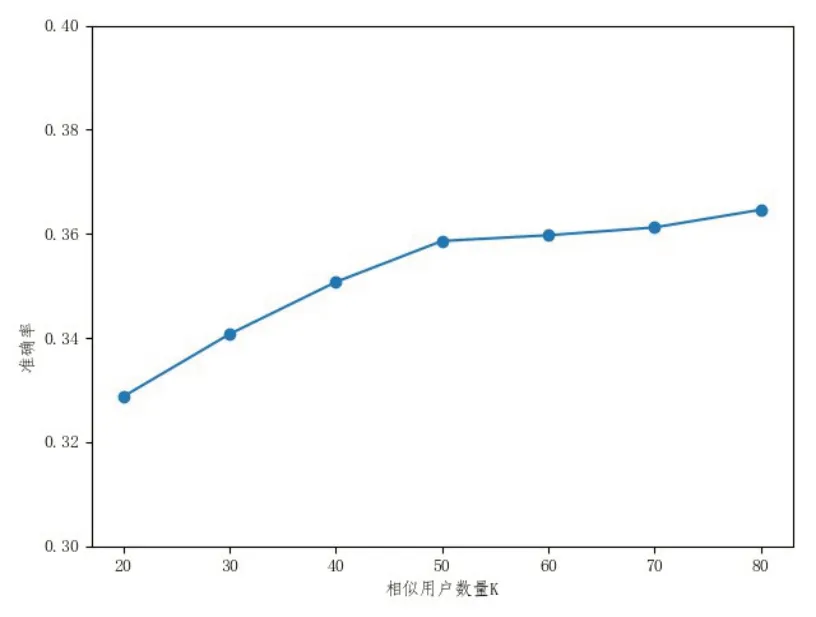
图3 不同K值的准确率

图4 不同K值的召回率

图5 不同K值的覆盖率
4.4.2 算法对比
对于隐语义模型(LFM),隐含类别F=100,学习率α=0.02,λ=0.01,正负样本的比率ratio=1。为了避免实验的偶然性,每种算法的结果都是通过10次实验取平均值,最终得到的实验结果如表1所示。从结果中,我们可以看出,隐语义模型系列的算法LFM、SVD、NMF相对于传统的协同过滤算法,在各种指标上都相差巨大,原因是隐语义模型系列的算法虽然能够在评分预测任务上较好地预测用户对物品的评分,但是在大量评分高的候选集当中,隐语义模型系列的算法并不明确目标用户的兴趣所在,因此,从大量评分高的物品候选集中选出少量的物品推荐给用户时,推荐效果不理想。对比基于邻域的两个算法ItemCF和UserCF,KG_UserCF算法在准确率上分别提升了2.77%和2.10%,说明通过元路径在知识图谱上统计分析能够准确的掌握用户的兴趣的分布情况,从而更能针对用户的兴趣进行推荐,推荐效果更加个性化、精确化,具有一定可解释性。对于综合用户多方面兴趣的KG_User⁃CF,很显然效果要好于仅考虑用户单方面兴趣的KG_UserCF_BoA和KG_UserCF_BoD,验 证 了KG_UserCF融合用户多方面兴趣特点的有效性。
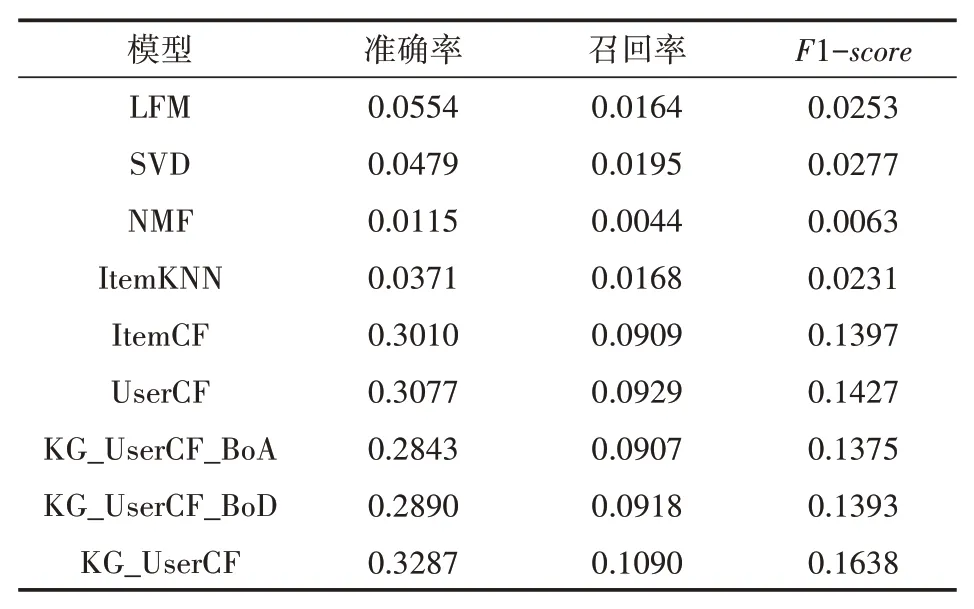
表1 多种模型在MovieLens-1M数据集上的准确率、召回率和F1-score
5 结语
本文提出了一种基于知识图谱元路径的协同过滤算法,在知识图谱的辅助作用下获得物品的语义信息,使用元路径的概念统计分析了用户的兴趣分布情况,根据用户的兴趣分布再结合基于用户的协同过滤算法,综合考虑用户多方面的兴趣为用户作出了个性化的推荐,通过实验验证了算法的有效性。不足的地方是本文只融合了用户在演员和导演两方面的兴趣。在未来的工作中,将不断丰富电影知识图谱,结合知识图谱中更多的语义信息,使用深度学习方法增强推荐效果。
