卡通风格人脸图像生成研究
2021-11-15董虎胜
董虎胜
(苏州市职业大学计算机工程学院,苏州 215104)
0 引言
卡通画是一种广泛受到人们喜爱的艺术表现形式,尤其是个性化的卡通人脸图像常常被用作QQ、微信、钉钉等社交软件的头像。这些卡通头像并不完全追求造型的逼真,而是适当地借助象征、夸张或神似的艺术化创作手法,达到创作意念与审美艺术的双重表达,在网络上非常受到欢迎。由于创作和真实人脸图像神似的卡通头像需要比较高的美术基础,这就使得利用人脸照片生成卡通化的头像成为现实的需求。
近几年来的图像风格迁移[1]技术为人们获得个性化的卡通头像提供了可行的解决方案。图像风格迁移指的是借助机器学习方法从具有特定艺术风格的图像中学习到内在的风格模式,再将这种风格施加到目标图像上,使其在保持原有内容能够被辨识的情况下呈现出特定的艺术风格。由于这种技术将数字化的图像处理与艺术创作联系了起来,赋予了计算机“自主”地进行艺术创作的能力,为数字图像处理提供了新的思路。因此该技术一经提出后,立即引起了人们的广泛关注,成为当前计算机视觉与机器学习领域中的研究热点[2-4]。
在当前图像风格迁移的方法中,比如Dual⁃GAN[4]、CycleGAN[5]和UNIT[6]等,基本上都借助了生成对抗网络[7](generative adversarial networks,GAN)模型来从图像中学习艺术风格模式,再进一步将这些艺术风格从源域图像迁移到目标域图像上,实现从源域到目标域的映射。尽管这些方法能够取得不错的风格迁移效果,但是也存在图像的背景容易受到影响的问题,给生成的结果带来一些内容上的瑕疵。本文在对GAN模型工作原理做了深入分析的基础上,设计了一种由注意力引导的生成对抗模型,在该模型中借助了注意力来引导GAN中的生成器更多地关注于图像前景内容,从而尽量减少风格迁移对背景内容带来的破坏。将该模型应用于人脸图像到卡通风格头像生成的实验结果表明,该模型能够取得优秀的人脸图像卡通化效果,生成的卡通头像不仅具有很好的卡通化艺术表现形式,同时也具有非常好的视觉质量。
1 GAN模型结构
GAN模型是一种具有很强学习能力的生成模型,在使用训练数据对GAN模型进行训练后,GAN能够生成和真实数据拥有相同属性的数据,完全能够达到“以假乱真”的效果。而且与一般的需要显式表达概率分布的生成模型不同,GAN并不需要显式地表达样本的概率分布,而是通过其内部的生成器与判别器之间的零和博弈来隐式地学习数据内在分布。在经过两者的对抗学习后,生成器与判别器最终将达到纳什平衡状态[7],此时生成器生成的数据就能够表现出与真实数据相同的外观,这样就可以利用其生成图像、文本等不同形态的数据。
GAN模型的工作原理如图1所示,其中包含有生成器G和判别器D两个基本模块。生成器G接收的是服从于分布p(z)的随机噪声向量z,在经过G的处理后将输出与服从pdata分布的真实训练数据x具有相同外观的数据G(z)。G(z)与x都将被送入判别器D中,并由D对它们的标签进行二分类预测。也就是如果输入的样本为G(z),则判别器D应判断其为假的样本,输出的类别标签将为0;倘若输入的是真实样本x,则应判断其为真实数据,给出类别为1的标签。在训练过程中,判别器D需要最大化对x与G(z)的标签预测准确率,而生成器G则努力地让生成的G(z)混杂于真实训练数据x中,让D难以将其分辨出来。这就形成了生成器G与判别器D不断对抗博弈的局面。
在整个训练过程中,G与D的生成与判别能力都会随着迭代对抗不断获得提升。当两者的对抗博弈达到平衡时,这种状态被称为“纳什平衡”。此时,生成器G的输出结果将会与来自真实训练数据的x具有相同的外观属性,判别器D将无法区分出当前的样本是实际存在的训练集数据,还是来自于生成的G(z),因此判别器D对x与G(z)的分类概率都将趋于1/2。这时就可以认为生成器G已经学习到了训练数据的内在分布,在不需要显式地表达数据分布的情况下就可以使用G来生成服从pdata的样本。
GAN模型的学习目标可以形式化地表达如下
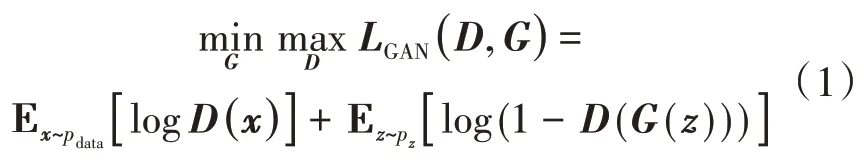
在GAN模型中生成器G和判别器D可以是任何形式的具有生成与判别能力的学习模型。但是由于深度模型具有比传统浅层机器学习模型更强大的学习能力,因此一般在GAN模型中都使用深度学习模型作为生成器与判别器。特别是在处理图像数据时由于卷积神经网络(convolutional neu⁃ral networks,CNN)具有独特的优势,因此一般使用CNN作为判别器,并使用具有转置卷积和上采样结构的CNN作为生成器。
2 使用注意力引导的风格迁移模型
图像风格迁移的主要目的是将源域S中的风格模式迁移并应用到目标域T中,设si∈S与tj∈T分别指代源域与目标域中的图像,当前的风格迁移模型基本上都采用了双生成器与双判别器的组合结构。设G和F为两个图像生成器,Dt和Ds为与它们对应的两个判别器。其中G接收源域图像s并生成具有目标域T中风格的图像G(s),判别器Dt用于对图像来自于G(s)还是T进行判断。生成器F与判别器Ds则完成相反的工作,即F负责由目标域T向源域S的映射,Ds负责辨别F(t)与S中数据的真伪。
为了降低风格迁移中对图像背景内容带来的影响,本文对生成器G和F的映射过程使用了注意力机制进行性能提升。设As、At分别为图像s、t的注意力映射图,将它们添加到图像生成流程后G和F的映射过程将变为G:s→As→G(s)和F:t→At→F(t)。这样的增强使得图像生成过程中将首先使用注意力来定义各个像素的迁移强度,避免了对图像所有像素不作区分地处理带来的不足。
为了获得图像的注意力,本文采用了如图2所示的非局部注意力[8](non-local attention)模型,该注意力模型能够有效地捕捉图像中较大区域范围内像素间的依赖关系,有效地引导模型获得图像的前景内容。非局部注意力模型接收的是通过多层卷积-池化-非线性映射获得的四维特征张量,这里B为一个批次(batch)中的样本数,C为通道数,H与W分别为特征图(feature map)的高与宽。在使用三个1×1的卷积核分别作卷积运算f(X)、g(X)、h(X)后,特征的通道将被压缩为C/2。在这三路分支中,首先对f(X)在H与W两个维度作扁平化,获得形状为[B,C/2,H×W]的输出。对g(X)也作类似的扁平化处理并作通道转置,获得到形状为[B,H×W,C/2]的张量。利用矩阵乘法对它们运算后将得到一个形状为[B,H×W,H×W]的张量,进一步作Softmax运算就可以获得归一化的注意力映射图(attention map)。
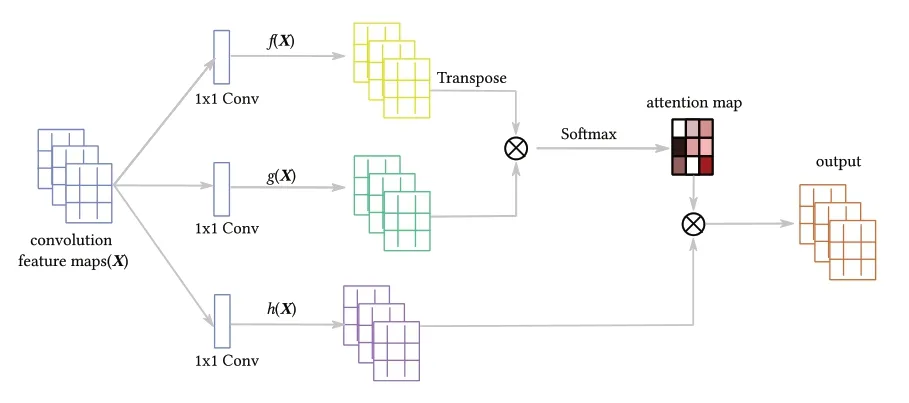
图2 非局部注意力模型
对h(X)也作类似的扁平化与维度转置后将得到形状为[B,H×W,C/2]的张量,将其与注意力映射图作矩阵乘法运算将获得形状为[B,H×W,C/2]的结果张量。再作维度转置与拉伸操作后将获得形状为[B,C/2,H×W]的输出张量。最后对其使用1×1卷积将通道扩展为原始C大小,即获得最终的注意力输出A∈RB×C×H×W。
在生成器G和F中引入注意力模块后,最终生成的结果图像将变为:

式中的β为取值(0,1)间的平衡参数。
在图像风格迁移中,我们希望对于源域中的图像s在映射到目标域T后仍能再次映射回源域S,且映射回的结果与原始图像间尽可能相似。也就是s→G(s)→F(G(s))≈s,类似地,对于映射F有t→F(t)→G(F(t))≈t,这样的约束也被称为循环一致性约束。该约束可以通过对生成器G和F施加循环一致性损失(cycle consistency loss)来获得:
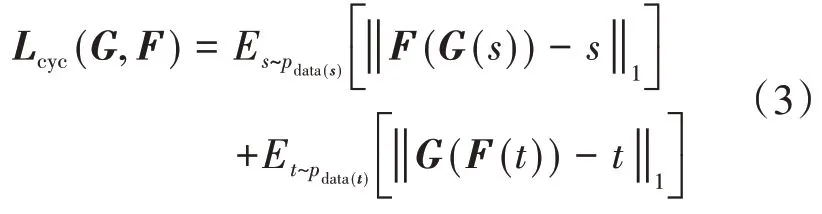
式中pdata(s)与pdata(t)分别指代图像数据s和t服从的概率分布。
在对整个风格迁移模型进行训练时,需要考虑生成器G与判别器Dt之间的GAN模型损失LGAN(G,Dt)、生成器F与判别器Ds之间的GAN模型损失LGAN(F,Ds)、生成器G和F之间的循环一致性损失Lcyc(G,F)。因此最终的损失函数可以表达为:
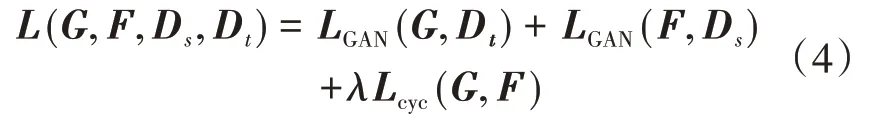
式中λ为根据经验设置的平衡参数。使用训练数据通过对L(G,F,Ds,Dt)进行优化后,获得的生成器G和F即可实现对图像风格的迁移,生成目标风格图像。
3 实验
实验中在selfie2anime数据集上进行了卡通风格人脸图像生成测试,selfie2anime数据集由slfie与anime两个数据集混合获得。其中selfie数据集中共有46386张个人自拍头像,anime数据集中总计包含有69296张卡通动漫头像。在实验中从selfie与anime数据集下均选择了3400张图像用作为训练数据,另外各选择了100张图像用作为测试数据,这些选中的图像均被统一到256×256的像素大小。anime数据集中图像被用作为目标域图像,需要从其中学习出风格模式;selfie数据集中的真实人脸图像用于生成卡通头像的源数据。本文图像风格迁移并不需要对目标域与源域中的图像进行配对,只需要从目标域图像学习风格模式应用到源域图像内容即可。
实验在Ubuntu 18.04环境下采用了PyTorch深度学习框架进行。本文的风格迁移模型中生成器主体采用了与CycleGAN相同的编码器-解码器结构,但在编码器中添加了非局部注意力模块。模型中判别器使用了70×70的PatchGAN[9]的分类模型,与一般的卷积神经网络结构相比,PatchGAN分类器中的参数量要少很多,而且可以接收任意大小的图像。实验使用了学习率为0.0001的Ad⁃am优化器,优化器的参数β1与β2均采用默认值;在训练阶段对模型作了200个epoch的迭代优化,再将其用于动漫插画风格图像的生成测试。在硬件上使用了NVIDIA-1080GPU配合CUDA10进行加速。

图3 卡通风格人脸图像生成结果
图3给出了本文模型的卡通风格人脸图像生成结果,其中最左侧为原始自拍人脸照片,第2列为生成器的注意力映射图的可视化图像,第3、4、5列分别为使用CycleGAN、UNIT与本文模型生成的卡通风格头像。从图中可以看出几种模型都能够实现卡通风格的迁移,生成的头像都在保持与原始内容整体相似的情况下添加了卡通风格。但是CycleGAN生成的图像中会混入一些其他内容,给图像内容带来了一些破坏;UNIT模型生成的头像中不仅头发部分与原图轮廓的差异比较大,人脸部分的轮廓线条也比较生硬,整体质量差强人意。与它们相比,本文模型生成的卡通头像人脸前景与原始图像轮廓相似且表现自然,背景部分在内容保持不变的情况下表现出良好的卡通风格,图像的整体视觉质量最为优秀。
4 结语
本文对基于对抗生成网络的卡通风格人脸图像生成进行了研究。为了避免风格迁移时对图像内容造成的破坏,在生成器网络引入了注意力机制,使得模型能够更多地关注于图像前景内容。在使用selfie2anime中的人脸与卡通图像数据进行训练后,本文方法能够生成具有优秀视觉质量的卡通风格头像。与CycleGAN和UNIT等模型生成的图像相比,在图像风格与图像内容上达到了比较好的平衡。
