基于深度学习的移动应用众包测试智能推荐算法
2021-11-13成静王威帅正义
成静, 王威, 帅正义
(1.西安工业大学 计算机科学与工程学院, 陕西 西安 710021; 2.西北工业大学 软件学院, 陕西 西安 710072)
移动应用众包测试是通过互联网面向测试人员发布移动应用测试任务,并由志愿者完成移动应用测试的一种测试方法[]。近年来,移动应用众包测试发展迅速,测试类型已涵盖GUI测试、兼容性测试、性能测试、安全性测试等不同方面,因此对测试人员的专业技能提出了苛刻要求。如何为测试项目推荐合适的测试人员,是保证众包测试质量的关键。
在近年来,国内外众多研究人员尝试将深度学习引入到推荐算法领域[2],其中以基于深度神经网络的协同推荐模型最有影响力[3-4]。该算法主要是利用深度神经网络DNN对高阶特征交互行为的学习能力来实现预测和推荐[5]。虽然DNN算法本身具有优秀的深层特征提取能力和参数学习能力,但是推荐算法领域的输入数据并不是图像和音频领域的那种稠密数据,推荐算法领域数据具有的稀疏性往往导致算法模型陷入局部最优,导致算法模型推荐效能打折。因此针对基于深度学习的移动应用众包测试推荐算法的研究,必须考虑数据稀疏度不同对模型的影响,并避免算法模型陷入局部最优。
本文通过对移动应用众包测试推荐机制进行深度分析,发现解决这一问题的关键在于数据稠密化过程中具有封闭式数据计算能力。而解决这一问题的关键性技术,堆叠边缘降噪自动编码器SMDA[6-7]一方面可以对测试人员和测试项目的输入向量进行无限最大化次数加噪,另一方面计算复杂度低且具有良好的可扩展性。然而,SMDA与DNN模型的结合却面临因此需要解决2个问题:①如何利用SMDA来初始化DNN模型;②通过何种方式将2个模型结合到一起。
针对上述问题,本文提出一种SMDA与DNN相结合的移动应用众包测试任务推荐算法。该算法的解决思路是将深度神经网络 DNN 和堆叠边缘降噪自动编码器SMDA结合,利用 SMDA 的特征提取能力提高数据密度,从而提高 DNN 模型的训练速度。该算法通过 SMDA 算法进行数据加躁降维操作,提高数 据密度,DNN模型在学习这些经过加躁和稠密化处理的数据时,不仅可以提高训练速度还可以提高泛化能力。
1 SMDA-DNN算法模型
移动应用众包测试平台中面向测试人员推荐测试项目,需要将合适的测试项目推荐给测试人员。而测试项目本身具有硬性要求和软性要求2种内在需求。其中测试项目的硬性要求主要包括两部分:①测试应用本身存在的限制条件,例如操作系统等限制;②应用开发商设置的硬性需求,例如测试人员等级等限制条件,利用这些强制条件设计一个项目过滤器来缩小项目推荐集的规模。测试项目的软性需求则是将测试项目推荐给合适的测试人员,而这些非强制性需求就是推荐算法研究内容,通过深度学习算法学习测试用户特征和测试项目特征从而实现推荐。 在SMDA-DNN算法模型中, 首先数据库中的测试项目经过过滤器过滤,将测试对象和过滤后的测试项目的画像特征向量分别输入2个SMDA模型,其次利用加噪函数得到重构输入向量,利用最小方差法计算SMDA原始输入和重构数据的损失,在学到SMDA编码映射矩阵和解码映射矩阵后,将隐藏层学习到的深层特征输出。最后将测试应用和测试人员的深层特征进行链接作为DNN的输入数据,DNN通过学习该输入数据进行预测。SMDA和DNN进行联合训练,当DNN损失过大的时候会回过来调整SMDA参数和DNN参数,从而实现规避局部最优的问题。当完成模型训练之后,将测试用户和测试应用的特征数据输入模型中,按照计算的评分排序预测,从而实现推荐。
2 SMDA-DNN算法设计
2.1 SMDA-DNN工作原理
SMDA本身是一种自动编码器,它通过加噪降噪来实现泛化,通过比较原始数据和输出数据的损失来后向传播。在深度学习领域常用的损失函数有 L1 损失函数、交叉熵损失函数和L2 损失函数等。L1 损失函数也称为最小绝对值偏差,它由于导数不连续,因此可能存在多个解,当数据集出现微笑形状的时候,解会出现一个较大的跳动;交叉熵损失函数主要应用于分类问题;L2 损失函数则也被称为最小平方误差,由于平方运算放大了误差,因此受奇异点的影响更大。SMDA 对移动应用众包测试对象的特征学习本质上是一个回归问题,它希望利用测试用户和测试应用的数据来预测一个值,而这个值就是2个项目的匹配度。因此本文直接排除了交叉熵损失函数,而 L1 因为自身受数据集影响较大, 不稳定的特征也被排除在外,所以本文选择最小平方差作为损失函数计算方法。
边缘降噪自动编码器常用的加噪方式有高斯加噪和无偏掩码噪声2种。高斯噪声常用在处理连续值的环境中,高斯掩码使用范围非常广,也较为常见。而无偏编码噪声主要是在二值环境中使用,无偏掩码噪声加噪的方式是将输入数据中的每一维度以相同概率重置为0,在加噪的时候为了防止噪声偏置,一般会保证没有加噪的维度为数据维度大小的1/(1-q)。 本文选择无偏掩码噪声作为输入数据的加噪方式,使用噪声等级为0.3的噪声对输入数据进行加噪处理。
在SMDA算法中,每层MDA开始训练前该层的输入向量都会经过加噪函数进行加噪,加噪得到的向量经过该层的训练后得到输出向量y。利用最小平方误差作为损失计算方法得到的移动应用众包测试环境下的SMDA损失函数如(1)式。

(1)


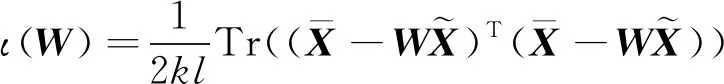
(2)

(3)
式中
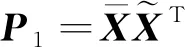
(4)

(5)
2.2 项目过滤器特征的设计
本文设计了一个项目过滤器来过滤测试项目,将待推荐的测试应用数量降到千级别,可以大大提高系统推荐速度。采用的硬性指标有:测试设备操作系统、测试人员等级限制、测试人员学历和测试人员工作场地。
测试设备操作系统条件是测试用户的设备操作系统属性和测试用户的操作系统需要匹配。测试人员等级条件是测试人员等级需要大于等于应用开发商设定值,测试人员学历表如表1所示;测试人员学历条件是测试人员学历需要不低于应用开发商设定学历,其匹配方法如公式(6)所示;测试人员的工作场地需要符合应用开发商的要求。

表1 测试人员学历表
学历匹配方式如公式(6)所示。
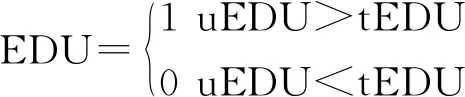
(6)
uEDU为测试用户的学历值;tEDU为测试任务要求的学历值。
2.3 数据处理
移动应用众包测试推荐的测试应用和测试人员的文本数据如何转化为模型能进行运算的数据是开始模型训练之前的必要步骤。通过对词向量工具分析比较后,选用了腾讯开源的词向量工具作为文本向量计算方法。腾讯词向量工具是腾讯AI实验室发布的一款针对中文语境的词向量工具,它覆盖范围广,语料丰富,适合于将测试项目和测试人员文本信息转化成向量。使用腾讯词向量工具将如表2所示的测试人员文本信息转换成词向量表达形式,将其作为提取测试人员深层特征的SMDA的输入数据。
本文使用腾讯词向量工具将如表3所示的测试任务文本信息转换成词向量表达形式,将其作为提取测试任务深层特征的SMDA的输入数据。

表3 测试应用特征
2.4 模型训练及参数学习
当SMDA对移动应用众包测试测试对象和测试人员进行完深层特征挖掘之后,接下来就是利用DNN对测试用户和测试人员的深层特征数据进行学习。使用的DNN网络结构如图1所示。
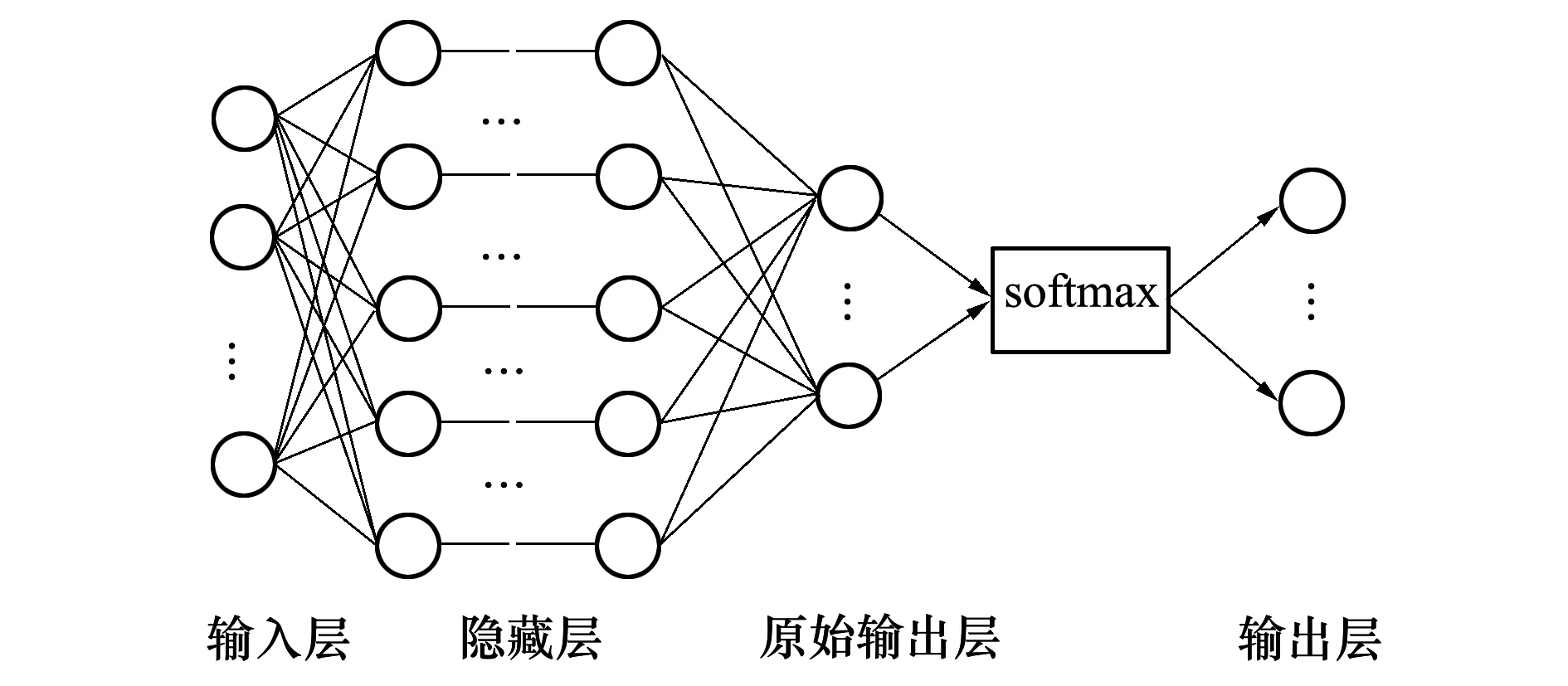
图1 DNN结构图
本文设计面向移动应用众包测试领域推荐的DNN,主要解决以下问题:①DNN学习目标;②激活函数选择;③损失函数定义;④DNN与SMDA的联合训练;⑤学习率的选择。下文将会针对上述问题的具体细节进行说明。
1) DNN学习目标
将推荐算法作为一个多分类问题,通过DNN网络结构学习到一种可以实现测试用户-测试项目数据到交互评分的非线性函数,其表达式如(7)式所示。
f(Zij)=softmax(σL(HL…σl(HlZij+bl))))
(7)
式中:Zij为测试人员i和测试项目j经过训练后得到的深层特征链接向量;softmax为DNN模型softMax层函数;σl为第L层的激活函数;Hl为第L层的权重向量;bl为第L层偏置。
2) 激活函数的选择
激活函数在DNN网络结构中是一个驱动单元,在DNN网络结构中采用非线性的激活函数可以将DNN的原本的线性变换进化成非线性变换,让DNN的表达能力更强。常用的激活函数有Sigmod、tanh和ReLU等。其中,Sigmod存在饱和让梯度下降函数失效、输出不是以0为中心和指数运算耗时等问题。tanh 改进了 Sigmod,解决了以0为中心的问题,但仍存在过饱和使梯度下降函数失效和指数运算耗时问题。ReLu是非饱和函数,可以避免梯队下降函数失效问题,并通过设置合理学习率避免神经元失效。通过分析对比,这里选择ReLU作为DNN框架的激活函数,其公式如(8)式所示。
f(x)=max(0,x)
(8)
3) 损失函数的定义
损失函数在深度学习中用来衡量模型的期望输出与模型的实际输出之间的差距。采用广泛使用的最小方差作为面向移动应用众包测试的DNN网络的损失函数,其公式如(9)式所示。
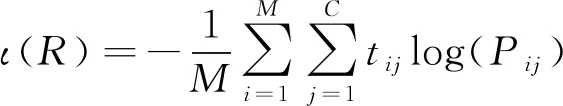
(9)
式中:M为样本数量;C为测试对象和测试项目交互评分类别数;tij为样本i在one-hot映射集中第j个元素的值;Pij为DNN模型预测样本i在one-hot集合中第j个元素的值。
4) DNN的训练
本文设计的SMDA-DNN框架中的DNN在计算完损失函数后会对SMDA模型进行微调的同时也对自身的参数进行调整。向后传播则是利用损失函数(10)调整DNN超参数。采用随机梯度下降算法来实现,其公式如(10)式所示。

(10)
由于推荐算法领域数据集稀疏度高,深度学习在推荐算法应用最容易出现过拟合现象,因此DNN模型中采用了dropout技术,每次迭代的过程中都丢失一部分神经元;而且为了加快模型收敛速度,防止参数震荡,还采用动量技术来调节梯度下降,另外输入数据也分成一个个的小批量数据,提高模型拟合度。
DNN和SMDA的联合训练则通过损失函数来反向调整SMDA的层数,让SMDA重新训练最开始的测试对象和测试项目数据。
5) 学习率设计
学习率作为DNN 模型中控制参数更新的速度控制器,选择合适的学习率可以有效地提高模型的收敛速度,而因为选择ReLU激活函数,选择过大的学习率则会导致模型中很多神经元失效。因此学习率设置的相对保守为0.08,选择指数衰减来调整学习率,使学习率随着训练轮次的增加而降低。
3 测试结果及分析
为了评估基于堆叠边缘降噪自动编码器的神经网络推荐算法在实际环境中的效果,利用某个移动众包测试平台的真实数据进行试验和分析。使用的数据集是针对获取到的某个测试平台实际数据通过表2~3的特征工程进行构建的标准数据集,并且经过数据清洗,得到了适合进行算法性能验证的实验数据集。移动应用众包测试项目和测试人员都有详细的结构化数据,但是无论是测试项目数据还是测试人员数据都是离散数据,因此采用词向量工具来实现测试项目和测试人员的词向量表达。此外,用户行为记录数据中可能存在隐性反馈,即当一个用户对一个项目打分为0的时候,可能是系统根本没有向该用户推荐过这个项目,可能是用户不喜欢这个项目,还有可能是用户忘记给这个项目打分,因此在设计实验数据集的时候设置了项目评分必须超过3个的限制条件,因此实验数据集设计如表4所示。
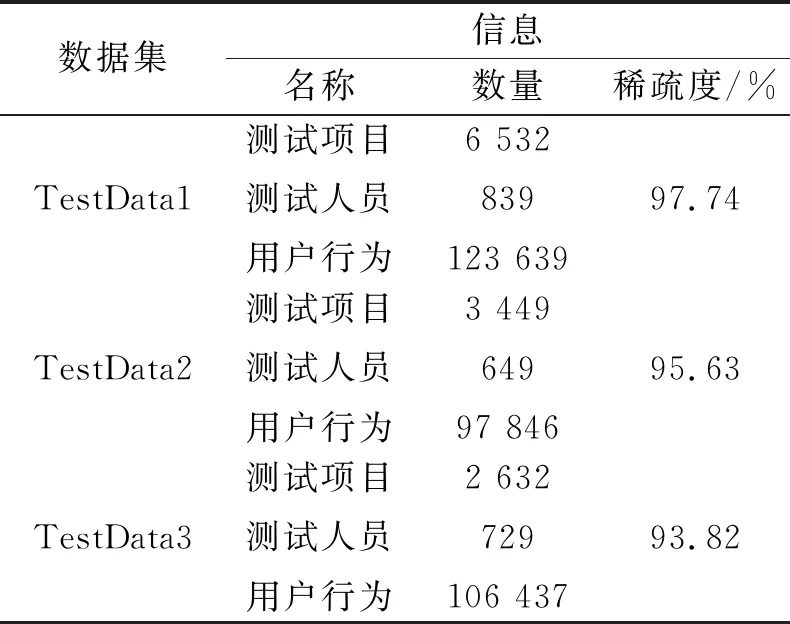
表4 试验数据集规模
实验硬件环境如表5所示,算法实现采用TensorFlow框架实现,TensorFlow框架版本为2.0,操作系统采用Ubuntu 18.04,使用的python版本为3.7.0。
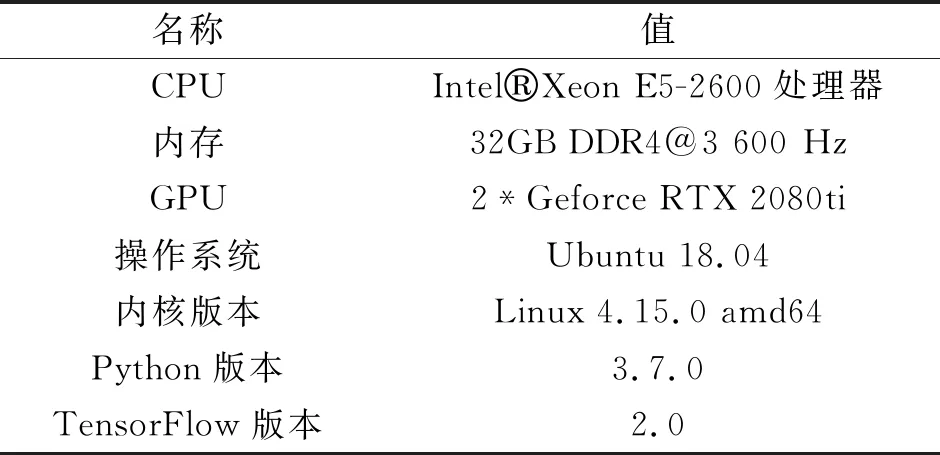
表5 实验硬件环境配置表
采用准确率和召唤率作为算法性能指标。准确率是描述算法预测结果与实际结果之间的差距,采用均方根误差(ERMS)计算算法的准确率,ERMS值越小,模型的预测能力越强。其计算公式如(11)式所示
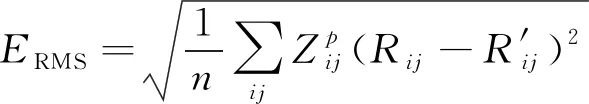
(11)
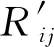
召回率越高表示该算法得到的测试结果越精确。召回率的计算公式如(12)式所示。

(12)
参与准确率对比实验的推荐算算法模型如下:
1) CDL。CDL是由香港理工大学研究人员提出的一种融合堆叠降噪自动编码器(简称SDA)和CTR混合的推荐算法框架[8],SDA和CTR通过贝叶斯图的方式结合,它是推荐算法领域最推崇的紧耦合推荐算法模型。
2) AutoSVD++。AutoSVD++同样是一种耦合模型,将自动编码器和奇异值矩阵分解技术结合,利用自动编码器学习项目的深层特征,利用奇异值矩阵实现推荐[9]。
3) SDMA-DNN。本文提出的基于堆叠边缘降噪自动编码器的移动应用众包测试任务推荐方法。
在开始对比实验之前先采用交叉验证的方法对各个模型就行参数优化,在各个数据集进行对比实验。图2~4是3种对比模型在3个数据集上的均方根误差值随着迭代次数变化曲线。

图2 数据集TestData1的不同迭代次数的实验结果对比 图3 数据集TestData2的不同迭代次数的实验结果对比 图4 数据集TestData3的不同迭代次数的实验结果对比
由图2可知,3种模型经过450轮迭代之后收敛,其中SMDA-DNN模型迭代次数最少,耗时25小时23分钟完成训练,而AutoSVD++虽然耗时比SMDA-DNN多,但是它比CDL更快。而且SMDA-DNN的均方根误差比另外2种模型都要低,代表它在数据集TestData1上的推荐精确度更高。
由图3可知,3种模型经过400轮迭代后收敛,其中SMDA-DNN模型迭代次数最少,耗时8小时40分钟完成训练。AutoSVD++不仅耗时比SMDA-DNN多,它也比CDL更慢。SMDA-DNN的均方根误差比另外2种模型都要低,代表它在数据集 TestData2 上的推荐精确度更高。
由图4可知,3种模型经过300轮迭代后收敛,其中SMDA-DNN模型迭代次数最少,耗时4小时53分钟完成训练,而且在数据集4上SMDA训练速度明显比另外2种有更大的优势,AutoSVD++训练速度和推荐精度最差。SMDA-DNN的均方根误差比另外2种模型都要低,代表它在数据集TestData3上的推荐精确度更高。
从图2~4可知,SMDA-DNN模型在3种数据集上迭代次数都最少,耗时也更短,训练速度明显比另外2种有更大的优势。
针对SMDA-DNN的召回率进行对比实验,通过与不同的模型在不同数据集上的召回率对比实验验证推荐算法的有效性。
参与对比实验的推荐算法模型如下:
1) HRCD。HRCD模型是一种混合推荐模型,它利用自动编码器挖掘物品深层特征信息,利用带有时间感知特性的SVD来实现分类[10]。
2) CTR。CTR模型是融和模型,它利用主题回归模型将项目信息中的主题信息提取出来,通过概率矩阵分解算法实现评分预测[11]。
3) CDL。上文已经介绍的推荐算法领域最推崇的紧耦合推荐算法模型。
4) AutoSVD++。上文已经介绍的一种耦合推荐算法模型。
5) SDMA-DNN。提出的一种基于堆叠边缘降噪自动编码器的移动应用众包测试平台的推荐方法。
同样在开始对比实验之前先采用交叉验证的方法对各个模型进行参数优化,在各个数据集上进行对比实验。表6~8是5种对比模型在3个数据集上的召回率值随着迭代次数的变化曲线。

表6 模型在数据集TestData1上的Recall@M统计表 %

表7 模型在数据集TestData2上的Recall@M统计表 %
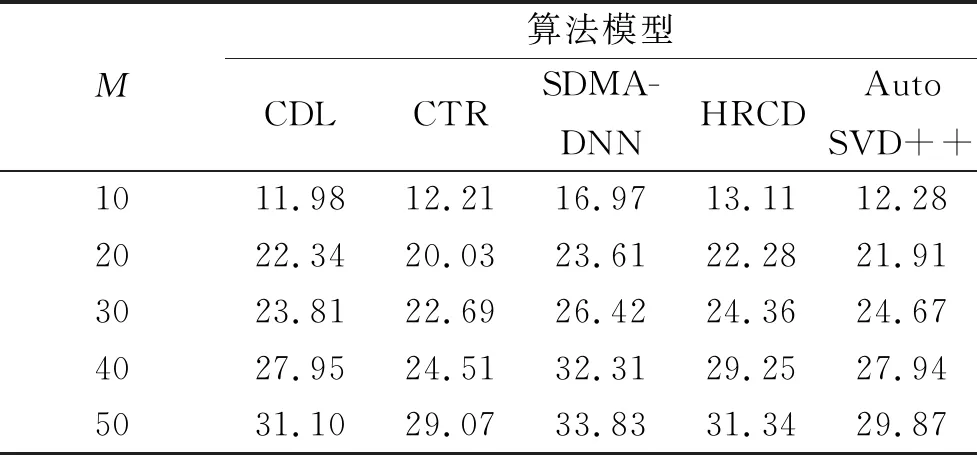
表8 模型在数据集TestData3上的Recall@M统计表 %
通过3个数据集的综合对比发现CTR的召回率数值明显不如其他的模型,这说明深度学习在推荐算法领域的确有较大的优势,SMDA-DNN本身是为移动应用众包测试平台设计,采用了SMDA对输入数据进行加密,因此在这3个数据集的表现明显具有优势,在Recall@M指标中相同M时相比较其他算法模型均有明显优势,因此提出的SMDA-DNN模型具有现实可行性。
综合上述2种指标的对比实验可以发现,提出的SMDA-DNN模型无论是在准确率还是召回率都比对比模型表现更好,训练时间也更短,因此算法模型设计符合提高模型训练速度和性能的设计预期。
4 结 论
随着移动应用众包测试平台的发展,平台用户对推荐精确度提出了更高的要求,本文提出了一种基于堆叠边缘降噪自动编码器的深度学习推荐算法。首先针对测试任务和测试人员进行特征分析,分别设计了一套特征体系,利用腾讯开源词向量工具将测试任务和测试人员的特征文本信息转化成数学表达形式,其次将得到的测试人员和测试任务特征数据作为堆叠式边缘降噪自动编码器输入数据,最后将SMDA学习到的测试项目和测试人员的深层特征数据结合作为深度神经网的输入,利用DNN的学习能力进行预测。实验表明,提出的SMDA-DNN算法相较于CDL和AutoSVD++性能更优秀,相较于HRCD、CTR、CDL及AutoSVD++等召回率表现更好。
