基于主成分分析的电网用户分类指标管理体系设计
2021-11-10赵双邓楚然潘徽谢瀚阳江疆
赵双,邓楚然,潘徽,谢瀚阳,江疆
(广东电网有限责任公司,广东广州610106)
在目前的电网用户分类指标中,指标之间相似度过大,导致评价时存在重复指标,因此提出用户分类指标管理。在对指标进行相似度管理时,大多使用的是聚类方法,但聚类方法无法实现对用户指标中的概率变量的分析,为实现电网用户分类指标相似度管理,已有相关领域学者对电网用户分类指标管理体系做出了研究。
文献[1]提出监管视角下的电力市场用户分类指标体系,通过考虑用户需求响应及负荷曲线,构建分类指标体系,对数据降维,滤除无关信息,完成指标结果可视化。文献[2]提出高压企业客户电力信用综合评价体系。构建用户电力信用指标,利用大数据聚类算法构建电力信用评价体系,并通过电力信用等级和信用分计算,验证所设计评价体系的准确性。
主成分分析是一种可以通过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量的一种统计方法。主成分分析可以直接将相关变量转换为不相关变量,而对不相关变量可以直接使用其他方法来进行相似度分析,无需进行变量转换[3-5],因此提出基于主成分分析的电网用户分类指标管理体系设计。
1 系统设计
1.1 量化规则构建
在已有文献的基础上,提出了两级电力用户的分类指标体系,如图1所示。

图1 电网用户分类指标体系
图1中共包括3 个一级指标,20 个二级指标。电压等级B1代表用来衡量电网用户的负荷线路电压,并根据电压的负荷情况划分等级。年用电量B2代表当前电网用户的用电规模,指标采用年用电量来评判。年最大负荷B3表示电网用户在当年内,所有用电设备使用时的最大用电负荷。而在用电情况指标中存在量级差异性,因此文中将上述的电压等级B1、年用电量B2、年最大负荷B3并这3 个指标按照量化规则进行量化[6]。年用电负荷率B4用来衡量年平均负荷以及最高负荷之间的差异度,用电波动率B5表示该用户对用电稳定性的需求程度。而其中B4的量化,根据相关文献提供的数值差别,使用10 000 和年用电量B2的乘积,除以8 760 与年最大负荷B3乘积的值,即为用户在当年的年用电负荷率。设Li为第i个月的用电量,可将B5量化为:

式中,代表i月中的用电量均值。在得出式(1)的值后,对数据中的B5指标取倒数,并使其指标同样具有数值越大越好的性质。而用户功率因数B6反映用户的用电品质,表示为:

式中,d代表当月的平均功率因数,月平均功率因数作为调整力率电费的数值,指标依据为该用户每个月的实用有功电量。式(2)中,d1和d2分别代表月平均功率因数的下限和上限。
1.2 主成分分析分类指标
在保证不同指标可以相同量化后,针对每个方面的候选指标进行主成分分析,得到每个主成分的方差贡献值。以每个主成分中的方差贡献率,作为主成分分析中的权重和候选指标的载荷系数,在方差贡献率绝对值处于指标方差和之间时,对该指标进行计算[7-10]。同时反映实验对象信息的重要水平[11]。将某一指标设为X,指标采用X1,X2,…,Xn来表示,若按照其中某一个指标Xp为例,则Xp的重要水平即:
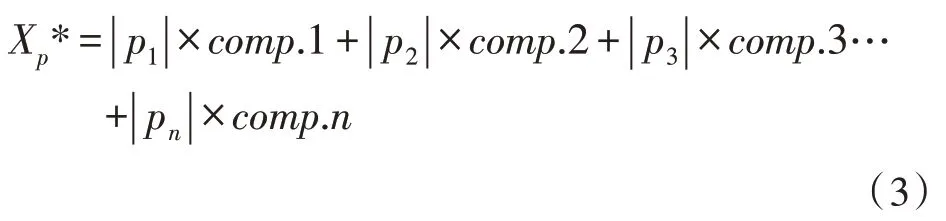
式中,p1,p2,…,pn代表Xp的载荷系数,comp.1,comp.2,…,comp.n作为主成分的方差贡献率,而在数值接近零时则任务指标的重要性较小,并在候选指标里删除,剩余指标进入下一步。而对剩余的候选指标可以使用相关系数法对候选指标之间的相关系数进行检验[12-13]。文中将阈值设置为0.3,也就是说在该指标和其他指标之间的相关系数均小于0.3 时,候选指标可以直接进入最后的用户分类指标中,而剩余指标则进行进一步地分析。对存在相关关系的指标再次使用主成分分析,并分析指标的重要程度,同时对剩余指标进行运算,建立相关系数矩阵[14-15]。
1.3 剩余指标曲线聚类分析
对剩余的指标使用负载曲线聚类进行处理,根据常用的MIA指标对各聚类算法进行比较,其中MIA指标可以代表在各聚类中心与对应聚类中的所有元素中的聚类平均值,MIA指标计算如下:

式中,假设通过聚类分析和分类电网用户类数为K,则CK代表在每个聚类中包含的单位集合,nk代表每个聚类中的单位数目,而在每个聚类中的代表线CTK代表该聚类方法的聚类中心,其中k=1,2…k。d代表剩余指标经过主成分分析后得出的相关系数。而其中:
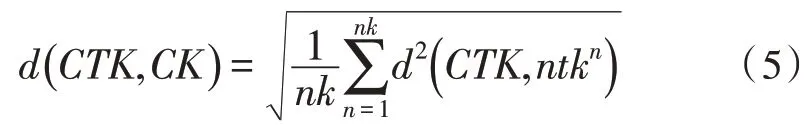
式中,ntk代表在该集合中的所有元素。通过MIA指标来对同一类的负荷曲线之间的聚类进行表示,而其中MIA数值越小则说明该指标类的重要性越高。这里可以参考在主成分分析中的相关系数矩阵表得出全不相关指标,在通过聚类后,要考虑聚类后的指标与全不相关指标是否相似或相关。在定义相似度时则使用曲线聚类分析,将定义相似度作为两条曲线之间的距离s,在曲线中两条曲线之间距离越小,则相似度越大,其中用c来代表48 个时刻点,p总,i与p分,i则代表总负荷曲线和各类负荷曲线所对应的时刻负荷值,即:
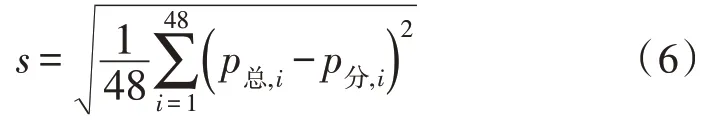
通过公式(6)确立在聚类指标间的相似度,而对两个聚类指标间相似度过高的指标进行修改或移除。而使用曲线聚类处理无法将指标中概率出现的变量相似度进行分析,因此需要使用Helinger 距离分类变量运算法来对指标之间的相似度实现运算[16]。
1.4 指标相似度管理
考虑在被聚类的指标中的变量,而使用曲线聚类分析难以确认分类指标中变量的相似度,因此对已经完成的聚类指标中的变量间的相似度进行计算。文中使用Helinger 距离的分类变量运算,在概率论中,f散度是用来度量两个以概率分布的变量E与Q之间的差异性的函数,设f(t)作为定义在t>0区间上且f(1) =0 的凸函数,这时若指标中的变量E与Q呈现概率分布式,那么E与Q之间的f散度则为:

式中,y为未知的概率出现的变量,而当f(t)=1-时,得出的f散度称为Hellinger 距离,在该情况下E与Q之间的Hellinger 距离的计算公式为:

式中,d2H(E,Q)即为得出的Hellinger 距离,而当指标中出现离散变量时,E与Q之间的Hellinger 距离公式变为:
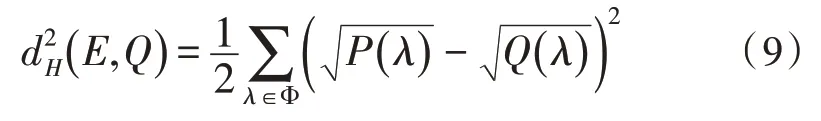
式中,将E与Q在可度量空间上的变量设为λ,根据式(8)和式(9)的计算即可得出两个分类指标中变量的相似度。根据上文的聚类分析与Hellinger 对用户分类指标中的相似度实现管理,提高用户分类的效率[17]。
2 实验论证分析
为了验证该文分类指标管理体系的可行性,使用该文用户分类指标管理体系以及文献[1]中的分类指标管理、文献[2]分类指标和无管理的分类指标进行分类。
2.1 实验算法
实验中,通过对4 种分类指标得出的用户分类指标之间进行相似度计算,得出实验对象的优劣性。实验中使用的相似度计算法为欧式距离系数,如图2所示。

图2 两用户之间的距离系数
如图2所示,假设实验分类得到的两个用户为S1和S2,在横坐标中的Z1表示其中的特征属性1,纵坐标Z2表示特征属性2,对特征属性来说,期间差异越大则距离越大。分类指标的相似系数计算如式(10)所示:
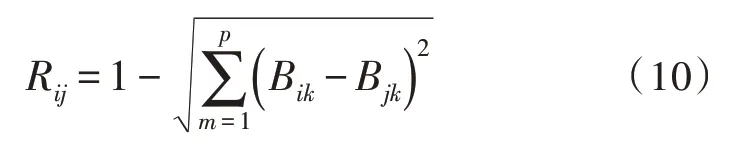
式中,每个分类指标样品中存在有p个变量,而Bik表示在第i个分类指标样品中的第m个指标的标准化数值。而Bjk则代表在第j个样品中的第m个指标的标准化值,其中,在第i个样品和第j个样品之间的欧氏相似系数设为Rij。
2.2 实验结果
实验中使用了4 种分类指标进行管理,并根据电网用户的分类依据,使用上述算法,将所分的每两个指标作为一个指标对比分组,并将指标对比分组使用上述算法进行相似度分析,根据集中指标分组最终得出的平均相似度系数来判断指标管理体系的优劣性。图3是经所提方法、文献[1]方法及文献[2]方法管理后的分类指标之间的相似度。
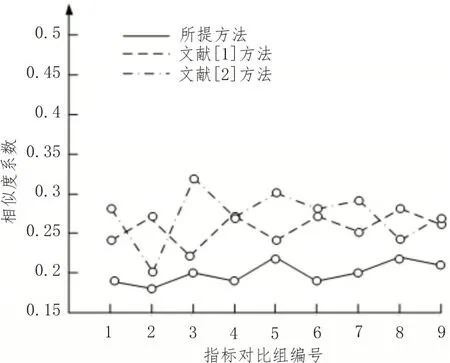
图3 经体系1管理后的指标相似度
分析图3可知,经所提分类指标管理后指标之间的平均相似度为0.197。且每组指标对比组之间相似度系数差距不明显。经文献[1]方法管理后的用户分类指标之间的平均相似度为0.261。因体系管理后,分类指标数不同,因此实验中的指标对比组数量也不同。而仅文献[1]方法管理后的指标相似度之间差别较为明显。在经文献[2]方法管理后的分类指标之间的平均相似度为0.257,且每个指标对比分组之间的相似度系数明显。
为了进一步判断用户分类指标管理的有效性,使用无指标管理的用户分类法来进行指标分类,实验结果如图4所示。
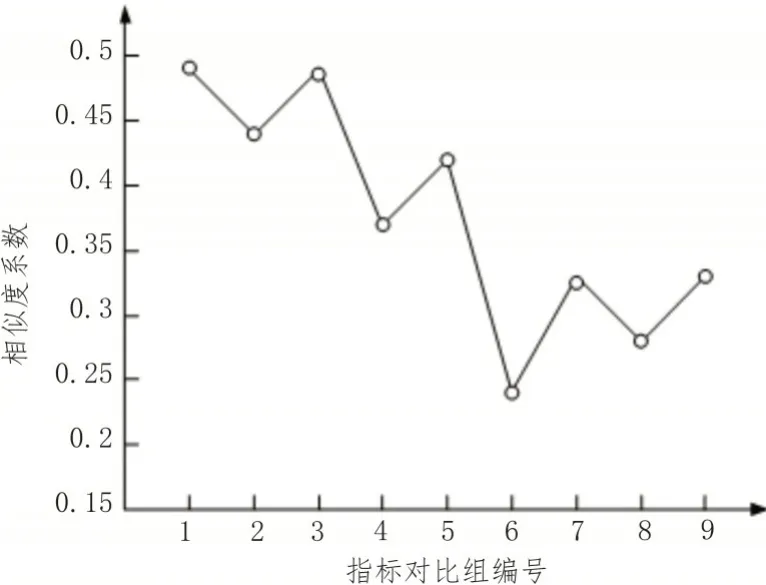
图4 不使用指标管理的指标相似度
分析图4可知,在不使用指标管理情况下的指标之间平均相似系数为0.370。其原因在于不使用指标管理,导致指标之间的相似度系数差别很大,因此存在高相似度的分类指标。经由实验证明,文中设计的基于主成分分析的电网用户分类指标管理体系可以有效地对指标之间的相似度实现管理,具有可行性。
3 结束语
文中对电网用户的分类指标,设计了基于主成分分析的电网用户分类指标管理体系。通过主成分分析的变量转换,并使用Hellinger 距离分类变量运算,实现对分类指标的管理[18]。但在设计中因使用Hellinger 对概率出现的指标变量进行运算,导致运算结构繁琐,运算时间较长,仍需进一步地改进。
