基于Kubernetes的海量网络数据存储方法研究
2021-11-08闫娟雅
闫娟雅
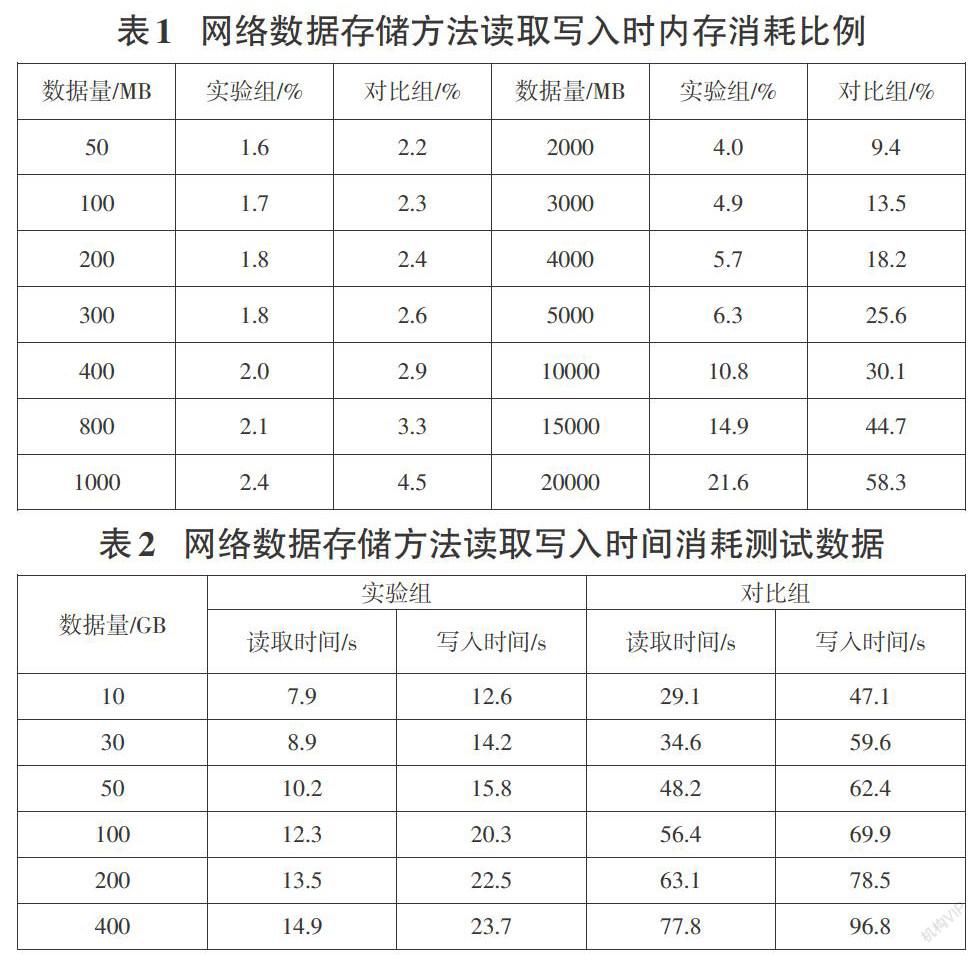
摘要:针对传统的集中式网络数据存储方式存储数据效率低的问题,研究了基于Kubernetes的海量网络数据存储方法。对海量网络数据动态合并处理后,设计Kubernetes集群并部署外部上传端与Kubernetes服务的访问过程,从而实现对海量数据的存储。对比实验结果显示,该存储方法相比能够减少约62%的运算内存占用,并且存储操作速度快,更能满足实际需求。
关键词:Kubernetes;海量数据;网络数据;数据存储
中图分类号:TP392 文献标识码:A
文章编号:1009-3044(2021)27-0028-02
Kubernetes是用于管理云平台中多个主机上的容器应用部署方式[1]。相比于传统系统绑定并通过插件、脚本或者沉重的虚拟机来安装应用的应用部署方式,Kubernetes可以通过部署互相隔离的存储容器的方式,在避免不同数据进程互相干扰的同时,还能利用容器各自的文件系统有效区分计算资源。将Kubernetes应用于网络海量数据存储中,能够改善集中式数据存储方法并发率低的问题。因此,本文将研究基于Kubernetes的海量网络数据存储方法,并对该方法的可行性进行验证。
1 基于Kubernetes的海量网络数据存储方法研究
1.1 海量网络数据动态合并处理
网络海量数据因网络的互联互通特殊性,网络中的数据大多存在一定的相关性。为节省数据存储过程中占用的内容,需要对网络海量数据进行动态合并处理。在本研究中,使用子集检测的频繁项挖掘算法,找出存在关联关系的网络数据,从而实现网络海量数据的动态合并,提高网络海量数据的访问速度,减少数据存储过程中的输入输出次数[2]。
网络海量数据不仅数据量大,而且数据更新累加速度极快,为提高数据的存储效率采用并行化算法实现海量网络数据动态合并处理,具体处理步骤如下:
1)统计在某一时间段T内,需要存储的网络海量数据个数。找到该时间段内数据个数的最大值K,并设定该值为需要动态合并的数据数量。
2)扫描网络数据记录日志,得到数据对应的IP地址、时间、数据量等信息,并建立对应时间段的网络数据子集。
3)统计输出所有时间段的网络数据子集的数量。如果时间段的网络数据子集的个数大于设定的阈值,并且子集项在大于K的子集项中没有出现过,将所有子集输出。
对于大小为K的网络数据子集,将子集中的前K项初始化为1,后N-K项初始化为0。按顺序扫描子集中所有元素,将排序为“10”交换为“01”。判断在所有时间段的网络数据子集中,k个标记为“1”的元素全部移动到子集序列的最右端,则停止处理。对每一组的网络数据进行分片,以逗号分隔元素,獲取所有大小为K的网络数据子集,并且输出[3]。重复上述过程直至将所有时间段的网络数据子集都完成动态合并。海量网络数据动态合并后,设计部署数据存储容器的Kubernetes集群。
1.2 Kubernetes 集群设计
根据Kubernetes的理论,若存储大量的网络数据,需要设计集群,通过对Kubernetes集群的部署,保持网络数据状态信息的同时,避免单存储点方式故障造成的数据存储停滞。
在Kubernetes集群中,利用分布式键值数据库Etcd组件保存Kubernetes集群上的应用信息、配置参数以及管理存储对象的时间状态信息。在对多个Etcd组件部署时,利用Raft算法产生分布式键值数据库Etcd组件的Leader节点处理所有组件对数据的管理操作信息提交。若Etcd组件的Leader节点失效,Kubernetes集群集群会自动重新选举Leader节点从而保障Etcd数据存储服务不受故障影响,实现高可用的目的[4]。根据Raft算法的处理原理,选举的Leader节点通常为奇数节点,因此按照以下具体过程对Etcd集群部署:
1)在Kubernetes集群中下载和分发分布式键值数据库Etcd组件安装文件。
2)创建Etcd组件各节点的TLS证书,证书用于加密数据上传与Etcd集群和Etcd集群间的通信。
3)创建分发分布式键值数据库Etcd组件的systemd unit文件,并根据数据存储目标配置Etcd组件的服务参数。
4)检查Kubernetes集群工作状态。
在Kubernetes集群部署过程中,分发分布式键值数据库Etcd组件集群确保了与Kubernetes集群部署运行相关操作信息数据的可靠存储。而利用Kubernetes集群中的 Master节点可以为接入集群的上传设备提供集群入口和所有资源管理接口的API Server、管理集群资源的Controller Manager、负责集群调度的Schedule三个重要组件。为满足网络海量数据存储时,Kubernetes集群的部署需求,以及保证各个组件不会因单独的故障而影响集群的稳定运行,采用分别在多个集群Master节点上部署操作副本即可[5]。与Etcd组件各节点相类似,通过竞争选举机制产生leader节点,当leader节点不可用后,剩余Master节点再次进行选举,从而产生新的leader节点从而保证kubernetes集群服务的可用性。
1.3 实现海量数据存储
采用Kubernetes集群对网络海量数据进行存储容器部署时,由于Kubernetes集群中的应用服务无法直接对外服务,因此,为保证网络海量数据能正常接入Kubernetes集群,需对Kubernetes集群由内部向外部服务接口暴露出来,从而实现网络数据的访问存储。
考虑到接入网络海量数据的服务数量较多,采用Ingress方式设计Kubernetes集群设计网络外端口访问。Ingress可以通过定义了外部URL请求到内部服务的转发规则,具体转发实现由Ingress Controller完成将对外界服务请求的响应转换为Kubernetes集群内部服务。
