基于时频域特征的人员连续动作分段识别
2021-11-08李华昊耿宏杨李志新周帮文王云良
李华昊,郇 战,耿宏杨,陈 瑛,高 歌,李志新,周帮文,王云良
(1.常州大学 计算机与人工智能学院 阿里云大数据学院,江苏 常州 213164;2.常州机电职业技术学院 信息工程系,江苏 常州 213164)
0 引 言
近年来,随着微型处理器和集成电路的快速发展,计算能力更强、体积更小的传感器和移动电子设备得到了发展。基于传感器和移动设备的应用在智能家居、行为监控、养老和体感游戏等人类日常生活中发挥着重要作用。随着可穿戴技术的飞速发展,基于传感器惯性数据的人类行为识别研究(human activity recognition system, HARS)越来越受到人们的关注[1]。其中,在智能医疗保健应用,例如身体状况检测,老人和残疾病人的健康监测和身体健康状况评估等领域都取得不错的成就[2]。
基于计算机视觉的技术和环境传感器已经被广泛应用于人类步态识别,但是这些方式也有缺点:①由于光照条件、服装类型和背景颜色等原因,视频数据可能会被遮挡,进一步的视频录制会在很多情况下引发隐私问题;②许多环境传感器需要基础设施的支持,例如在监测区域安装摄像机。与其他人类行为数据采集设备相比,惯性传感器体积小,佩戴方便,具有保护个人隐私的功能。
基于惯性传感器的步态识别研究在多个领域取得良好的成绩。文献[3]使用隐马尔科夫模型(hidden Markov model,HMM),结合支持向量机(support vector machines, SVM)对传统的隐马尔可夫模型进行改进,对不同的人类步态类别具有良好的识别效果。文献[4]采用卷积神经网络(convolutional neural network, CNN)进行特征学习的方法相比于基线模型动作分类的速度和效率明显提高。例如文献[5]采用4个加速度计,分别固定在胸、腕、大腿、小腿,对躺、坐等9个动作进行识别。文献[5]提出了一个神经网络模型来分类人类步态类别,利用邻域成分分析的特征选择方法从可用的时间域和频率域参数中选择重要的特征子集,达到了95.79%的分类精准率。文献[6]通过设计一个分类器集成的强度对等物,提出了一个框架来详细识别静态和动态步态类别,根据神经网络训练数据集的输出性能,确定基分类器的权重,达到94%以上的识别准确率。文献[8]分析了基于iPhone加速度计和回转仪的步态特征,提出了一种新的步态识别方法,对数据集进行处理,提取步态特征参数,包括步态频率、对称系数、动态范围和特征曲线的相似系数,并提出了一种基于步态特征参数的加权表决方案用于步态识别。文献[9]提出了一种从RGB数据(一种图像数据格式)中识别人类活动的方法,注意模块学习预测的瞥见序列,共同进行运动跟踪和活动预测,利用外部记忆模块优化空间、时间和特征空间的一致性分类。文献[10]提出了将时空卷积分解为深度可分离的时间卷积和多尺度的时间卷积,降低了三维卷积的复杂度,证明它比2+1D卷积更适合于长期时间建模。文献[11]提出了一种新的池化方法,核化的秩池化,将给定的序列紧密地表示为再现核希尔伯特空间中超平面参数的前像,数据的投影捕捉到它们的时间顺序,并证明了这种池化方案可以被转换为一个顺序约束的核主成分分析目标。文献[12]探讨了智能手机内置的三轴加速度计和陀螺仪在识别人体身体活动方面的能力,提出了一种新的特征选择方法,以选择可判别的特征子集,构建具有较强泛化能力的在线活动识别系统,降低智能手机功耗。
本课题研究内容针对来自惯性传感器的加速度计和陀螺仪的连续行为信号分割和识别,并提出相对应的研究算法。拟解决的关键问题是如何从一段连续多个动作的时间信号中准确地识别出各个行为序列片段。对此关键问题。论文的主要贡献如下。
1)语音信号和惯性信号都是由人类的身体运动产生的,它们有重要的相似之处。从语音信号识别方法引入梅尔倒谱系数特征等频域分析方法,对惯性传感器信号进行人类行为识别,解决时域系统容易忽略的特征和其他内容。
2)计算频域特征的一二阶delta系数,并将其和传统特征进行多组组合,用不同分类器验证不同组合的特征对原特征识别结果的改善效果。
1 相关工作
现阶段大多数基于惯性传感器行为研究已经取得让人振奋的显著成果,但是仍然存在2点主要问题:①这些研究工作主要致力于独立的单个动作识别,例如走、站、坐、跑等,但是,真正的人类日常活动往往是复杂的、连续的;②这些研究局限于惯性传感器时间信号的时域特征和峰度偏度等简单频域特征,没有深入研究时间信号序列的频域特征。例如,文献[13]克服固定滑动窗口分割局限性问题,提出自适应的滑动窗口方法,根据窗口内动作的概率大小自适应地拓展窗口,以提高分类准确性,并取得很好的识别率。该算法需要选定基础的固定窗口,且只能动态放大,如果可以自适应地放大缩小,就可以更加精细地分割动作边界。文献[14]提出了一种利用人体佩戴的无线加速度计的精确活动识别系统,用于患者监测的实际应用,利用单台安装在腰部的三轴加速度计的数据,将步态事件分类为6种日常生活活动和过渡事件,总体准确性约为98%。对每个个体活动的准确性也超过95%。
近几年,出现了越来越多的研究试图弥补这些不足之处,某些研究使用语音识别系统的方法来解决人类行为识别的问题。梅尔频率倒谱系数(Mel-frequency cepstrum coefficents, MFCC)是语音处理中最流行和常用的频率特征之一。MFCC技术将分析分辨率集中在低频上。在较高的频率,特别是在1 000 Hz以上的频率中,人类的语音感知较不敏感。正因为如此,Mel刻度规定了高达1 000 Hz的线性度和高于1 000 Hz的对数度。相关信息包含在信号的静态和动态特性中。因此,在MFCC的基础上,可以计算一阶delta系数和二阶delta系数。
文献[15]提出了一种适用于语音处理的特征,即梅尔频率倒频谱系数(MFCCs)和感知线性预测(perceptual linear prediction,PLP)系数,还考虑和评估了相对光谱(relative spectra transform,RASTA)滤波或delta系数等特性。基于隐马尔可夫模型(HMMs)的人类行为识别和分割(human behavier recognition and segmentation,HARS)系统已经将这些适应性纳入其中,用于识别和分割不同的身体行为。文献[16]提出了一种基于多加速度计的小波行为分类方法,该方法将动态运动分量与重力分量分离,准确率达到98.4%。文献[17]使用的加速度计信号的标准测量值是平均值、相关、信号幅度面积(signal magnitade area,SMA)和自回归系数,采用神经网络作为活动识别的分类器,提出了特征子集选择方法,以确定有效的特征子集和紧凑的分类器结构,并具有满意的精度。
2 模型框架
图1显示了本工作中使用的HARS系统的总体架构。该系统由信号预处理、滑动窗口分割、特征提取和分类器识别4个主要模块或步骤组成。

图1 HARS系统的总体架构
2.1 预处理和分割
在利用可穿戴式传感器采集过程中任何轻微的干扰都会对得到的运动数据产生不可避免地噪声和异常值,例如信号传输错误,外界的电磁干扰等[18]。针对信号中存在的噪声,使用 3 阶巴特沃思滤波器去除基线漂移噪声[19]。可以计算传感器惯性信号序列的功率谱密度来选择截止频率[20]。
滑动窗口法用于分割识别,被广泛应用于 HAR 研究,使分割的步行、跑步、站立、坐姿、上楼梯和下楼梯等动作有很好的识别效果[21-22]。使用滑动窗口方式提取6个基本动作信号,然后每个窗口提取若干个统计特征。
2.2 特征提取
2.2.1 传统特征
对每个窗口的 14 组数据中每一组提取包含 5 组时域特征(均值、标准差、最大值、最小值和过零点个数)和 4 组频域特征(均值、方差、偏度和峰度)。
2.2.2 梅尔倒谱系数和一二阶delta系数
在过去的几十年里,语音人员识别、语音内容识别、生物特征识别等方面都有了重要的发展。语音信号和惯性信号都是由人类的身体运动产生的,所以它们有重要的相似之处。①2种类型的信号都包含在频域中的相关信息。目前,绝大多数的语音处理系统都使用从频域[23]得到的特征。从人体运动中提取的惯性信号也包含了相应的频域信息;②2种信号在低频率上有能量集中。这些类型的信号有不同的频率范围,但在语音信号和惯性信号中,信号能量集中在频率范围的低部分。对于人体运动,已经提出了几种频率翘曲方案来考虑在低频率下更高的分辨率[24];③这些信号具有低再现性,即一个人不同时间念同一个句子会产生不同的信号。惯性信号也会产生类似的效果:一个人在不同的时间进行相同的行为(比如行走),会产生不同的信号。基于这些信号的识别系统必须能够在接受某些信号的训练和不同信号(来自相同或不同的人)的测试时正常工作。因此,特征提取模块必须获得灵活的频率模式,以处理训练和测试场景之间的差异。
语音处理中最常用的特征提取方法有梅尔频率倒谱系数(MFCC)、线性预测系数(linear prediction coefficient, LPC)、LPC导数或线性预测倒谱系数(linear prediction cepstrum coefficient, LPCC)和感知线性预测倒谱系数(perceptual linear predictive, PLP)[25]。
预加重是一种补偿快速衰减的语音频谱的方法。但在惯性传感器数据处理过程中,这种补偿可能是不必要的。在惯性信号中,频率范围比语音小。保留了汉明加窗和快速傅里叶变换步骤,因为这2个步骤对任何基于频率的信号处理方法都很重要。
在MFCC特征中加入时间导数可以大大提高语音识别系统的性能[26]。信号导数可以提供信号演化的信息。根据这一想法,修改后的MFCC得到了delta和delta-delta系数的补充。delta系数为
(1)
(1)式中:dt是t时刻的delta系数,由对应的静态系数Ct-n到Ct+n计算得到。MFCC特征只描述单帧的功率谱包络,即MFCC系数随时间的轨迹。delta系数可以通过下面的公式计算。将delta系数补充MFCC向量上得到是长度为原来MFCC向量2倍的一个新的特征向量。delta-delta系数是用同样的方法,由delta计算得到。

图2 计算MFCCs和提取传统特征的主要步骤
2.3 分类器
本文选取随机森林(random forest)分类器。随机森林具有算法清晰,实现难度低,节约计算成本等优点,同时性能良好。运行流程程如下:①从样本集中利用有放回的重采样,采集出a个样本;②从所有的特征属性中随机选用k个属性,并且选择最佳分割属性并且建立CART决策树;③重复步骤①,②,共重复b次,建立起b棵CART决策树;④b棵CART决策树形成随机森林,并且通过投票法决定数据所属于的类别。
3 实验及结果分析
3.1 数据集介绍
论文的实验数据来源于加州大学欧文分校机器学习存储库中的“使用智能手机进行人类活动识别(HARuS)”数据集。该数据集包含30位年龄段在19—48岁的志愿者,每一位志愿者在腰间佩戴智能手机(三星 Galaxy S II)进行连续的6个活动(步行,上楼梯,下楼梯,坐,站,躺)。使用其嵌入式加速度计和陀螺仪,以 50 Hz 的恒定速率采样 3 轴线性加速度和 3 轴角速度。数据集包含 13 182 s的记录,包括来自 30 个用户的 60 个传感器数据样本[27]。
3.2 分类训练
3.2.1 数据预处理
首先计算HARuS 数据集中的动作数据的功率谱密度(PSD),如图3,给出了加速度X轴信号和角速度X轴的PSD曲线,可以看出,信号能量主要分布在0~15 Hz,大于15 Hz的部分逐渐趋于0,所以截止频率设置为15 Hz。

图3 X轴功率谱密度曲线
针对信号中存在的噪声,使用 3 阶巴特沃兹滤波器去除基线漂移噪声,截止频率设置为15 Hz,滤波效果如图4。图4显示某一个样本的一段加速度序列,其中,虚线为惯性传感器初始某一轴序列,实线为该轴经过滤波后的序列。

图4 滤波前后对比
3.2.2 滑动窗口分割
使用若干种不同长度的滑动窗口,以 50%重叠的方式提取6个基本动作信号,然后每个窗口提取若干个统计特征。60组样本经滑动窗口分割后得到一万多个窗口片段。
3.2.3 特征提取
通过对原始数据求导得到新的 6 组数据(包括加速度和角速度的每一轴信号),其次,对原始加速度和角速度数据求欧几里得范数得到新的 2 组数据。因此,总共获得 14 组数据(包括 6组原始数据和 8 组新的数据)。
对每个窗口的 14 组数据中每一组提取包含 5 组时域特征(均值、标准差、最大值、最小值和过零点个数)和 4 组频域特征(均值、方差、偏度和峰度),这样每个滑动窗口可以获取 126 组传统特征。
在每个窗口,从每个惯性信号中提取N组MFCC系数,得到14×N组系数的特征。delta系数和delta-delta系数个数同为14×N组。
3.3 实验设置与结果分析
3.3.1 评价方法
论文所要解决的问题是精准地检测每个窗口的活动类型,验证梅尔倒谱系数特征和delta系数对识别系统的积极影响。评价分类器性能的指标一般是分类准确率(accuracy),其定义是对于给定的测试数据集,分类器正确分类的样本数和总样本数之比。对于二分类问题常见的评价指标是精确率(precision)与召回率(recall)。通常以关注的类为正类,其他类为负类,分类器在测试数据集上的预测或正确或不正确,4种情况出现的总数分别记作:
TP——将正类预测为正类数(true positive)
FN——将正类预测为负类数(false negative)
FP——将负类预测为正类(false positive)
TN——将负类预测为负类数(true negative)
各个指标定义如下[28]
(2)
(3)
(4)
3.3.2 实验结果
本实验的实验平台是在搭载了Intel®CoreTMi5-10300H 2.5 GHz CPU 和 NVIDIA GeForce®GTX 1650Ti 4G GPU 的 ASUS 笔记本电脑上进行,操作系统是Windows 10.0,使用编程软件Matlab 2018测试。
梅尔倒谱系数提取个数N对分类器识别率结果有非常大的影响,不同的分类器分类结果一般不一致。
首先对比得出最佳固定窗口长度和梅尔倒谱系数提取个数N最优的取值。不同分类器下不同窗口时间的准确率如表1,当滑动窗口长度为 2.56 s 时分类识别效果最好,总体识别率高达 96.12%,对于每个动作的识别率比其他窗口时间高。设置固定窗口长度为2.56 s,由于采样频率为50 Hz,所以分割得到的窗口包含128个采样点。对14轴每个窗口的时间序列片段计算不同个数N的梅尔倒谱系数。表2显示在不同的N取值下,N取10时,梅尔倒谱系数识别率最高。6类动作混淆矩阵如表3。

表1 不同分类器下不同窗口时间的准确率

表2 不同个数N的梅尔倒谱系数,随机森林分类器下某5个测试样本的准确率

表3 六类动作混淆矩阵
在126组传统特征和140组MFCC系数基础上,增加delta系数,delta-delta系数或者二者的组合。随机森林(RF)分类器对特征分类效果明显好于k近邻(KNN)和朴素贝叶斯(NB)分类器,如表4。随机森林分类器识别结果如表5。引入delta系数和delta-delta系数能够改善。系统平均识别率最高达到98.19%。

表4 不同分类器下不同特征选择组合的准确率

表5 随机森林分类器下某5个测试样本的准确率
3.3.3 实验结果对比
本论文提出的方法在前人研究基础上进行一定程度的改进。对比的研究都是在HARuS数据集上运行的。
文献[13]使用 AW-TD 算法,由于不同动作序列各自的特定概率,建立多元高斯函数来自适应地调整窗口大小。文献[14]提出GD算法,提出了一种基于人体佩戴式无线加速度计的精确活动识别系统,并将其应用于病人监护的实际应用中。文献[13-14]只对6类连续动作中的走、坐、站动作进行分割识别。表6和表7显示,2种分割识别方法表现出很好的效果,AW-TD 算法对3种动作的分割精确率达到了 95%以上,召回率也是高于 90%,两者高于 GD 算法。论文所提方法对站动作的分割精确率高于 AW-TD 算法表现,召回率也是达到 98%以上,高于 AW-TD算法和GD算法。
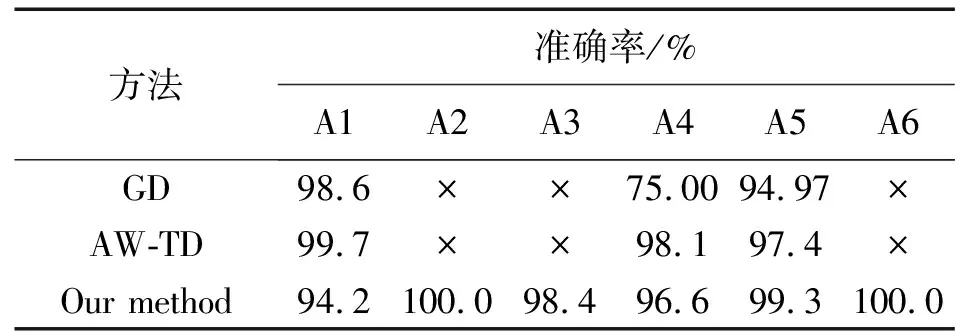
表6 提出的方法与其他方法精确率的对比
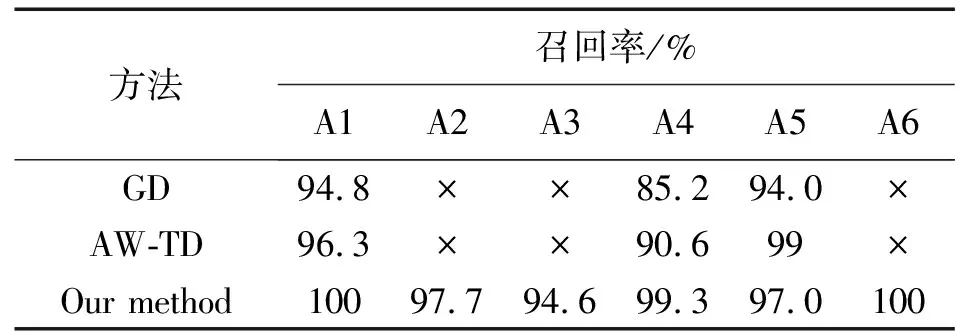
表7 提出的方法与其他方法召回率的对比
4 结 论
论文针对复杂动作的分割识别,将用于语音信号识别的频域特征梅尔倒谱系数应用到惯性传感器时间序列信号识别系统中。同时,在梅尔倒谱系数基础上计算一,二阶delta系数,显著改善最后分类器识别效果。可以分割并识别复杂动作序列中的连续动作,并将每个动作窗口片段进行类别的标定,在多种分类器下识别结果比较令人满意。本模型在 UCI 公开的HARuS 数据集上进行研究实验,实验结果表明,可以很好地分割识别出6类基本连续动作,并且整体准确率达到 98%以上。与在同一个数据集上并做相同的研究相比,整体准确率比 GD 方法和AW-TD方法高。
虽然可以很好地分割识别出6类基本连续动作,但是本研究还有可探讨的深层问题。例如,本文没有对6类动作之间的过渡段动作进行研究,同时,模型鲁棒性方面存在不足之处。未来可以尝试在其他数据集上来优化实验,需要考虑过渡动作在现实生活中的实际意义和模型稳定性。
