基于联体段的印刷维吾尔文预处理∗
2021-11-08邵小青贾钰峰章蓬伟邵敬普
邵小青 贾钰峰 章蓬伟 邵敬普
(1.新疆科技学院 库尔勒 841300)(2.中国石油运输有限公司沙漠运输分公司 库尔勒 841300)
1 引言
在文字图像生成时由于设备或人为等一些因素会给后续的识别带来问题,而图像的预处理就是为了排除这些干扰,提高图像质量,为下一步针对维吾尔文联体段提取特征做好必要的基础准备。
2 维吾尔文的特点
维吾尔文的词是由一个或多个字母组成,笔划简单但字形相差小,而且词汇中存在字母间各种连接变形使得书写形式就不同。印刷维吾尔文的切分是识别技术的一个难点,切分常常碰到粘连,断裂,躁点,伪字母切分等[1]。根据维吾尔文的特点,提出了基于联体段(WordPart)[2]的段切分。此种切分方法能保留住文字的特征信息,极大地简便了图像处理。如图1是维吾尔文结构特点图。
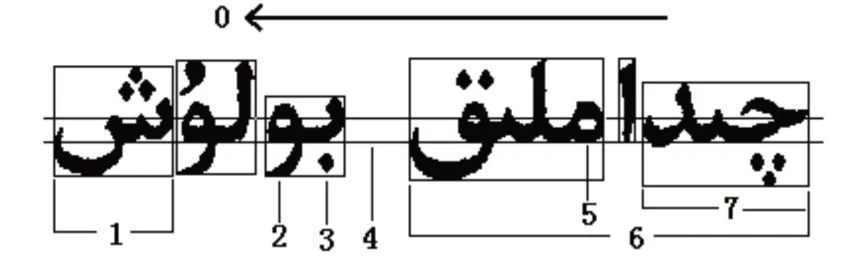
图1 维吾尔文结构特点
3 预处理
3.1 去噪处理
噪点恶化了图像质量,复杂了特征,消除图像噪点的工作称之为图像平滑或滤波,对图像孤立点簇作为杂质区域进行清除,得到只有笔画的洁净样本。在各种去噪方法中比较常用的有梯度锐化、数学形态学中的二值闭运算、均值滤波[3]、中值滤波[4]。但这些方法比较适合256色的灰度图像,而不太适合二值化后的2色的灰度图像,为此我们针对二值化后的2色图像改进了均值滤波:假设滤波模板为3*3,如图2。
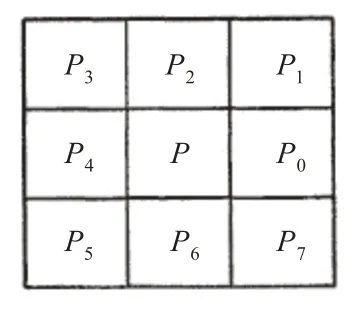
图2 3*3的滤波模板
如果待测图像中某像素点值P为黑点,而周边8邻接点像素点为白点,则该像素点为噪声点。假设将黑点值取为1,白点取值为0。如果待测像素点值P为白点,则同理。新的逻辑表达式可以表示为或0。对消除图像上孤立的点效果很好,结果如图3。

图3 本文的去噪效果对比图
3.2 倾斜校正,基线评估
因人为或者其他因素,扫描图像会出现某种程度的拉伸(或倾斜),它会给下一步每一行文本的判断,以及联体段的切分造成困难。所以倾斜校是特征提取的基础,它的重点和难点是检测出倾斜角,只要算出倾斜角,就可以快速地矫正并评估基线。我们编写了三种方法对图像进行倾斜矫正并以此对比矫正结果的优劣。其中直线拟合法是根据维吾尔文主笔画在基线上的这一特点,进行的一种新的尝试。
3.2.1 投影图法
基于投影图[5]的思想是沿文本书写方向的黑像素点的长度最大的倾斜角进行分析。我们的方法是在一定阈值范围内以1°间隔对文本行进行旋转,并对旋转后的图像进行投影,对投影的长度进行记录,并找出其中最大长度。当前长度与最大长度之间的夹角大于0时代表有倾斜,并计算出倾斜角度,然后根据角度逆向转动矫正整体图像。当然还可以基于投影图波谷的间隙最长进行角度校正。但该算法对一行只有一个词的情况,无法得到满意的结果。
从图4中看出文本图像被倾斜校正后就可以看出波峰间距是文本行的高度,波谷的间距是行间距(利用空白间隙是我们进行文本行切分的依据),波峰是基线的位置。基线,维吾尔文字书写时虚拟的一条直线,在倾斜校正或者是在特征提取中都起到很重要的作用。

图4 左图为右图的水平投影
3.2.2 Hough变换法
霍夫变换(Hough)[6]是一个非常重要的检测间断点边界形状的方法。它通过将图像坐标空间变换到参数空间,来实现直线与曲线的拟合。这里它把二值图像变换到Hough参数空间,在参数空间用极值点检测完成目标的检测。Hough变换是利用图像全局特性而将边缘像素连接起来组成边界区域封闭的一种办法[7]。Hough变换对于纯文本的抗干扰能力强,可以减少计算量,对曲线间断的影响也较小。只需要在参数空间里进行简单的累加统计即可。Hough变换有大量的资料信息可以查阅,这里不再赘述。
3.2.3 直线拟合法
我们知道,如果有一些离散点(X(i),Y(i)),就可以拟合出一条直线y=ax+b,使所有点到这条直线的距离平方和最小,那么这条直线就成为离散点的目标拟合直线[8~10],如图5所示。
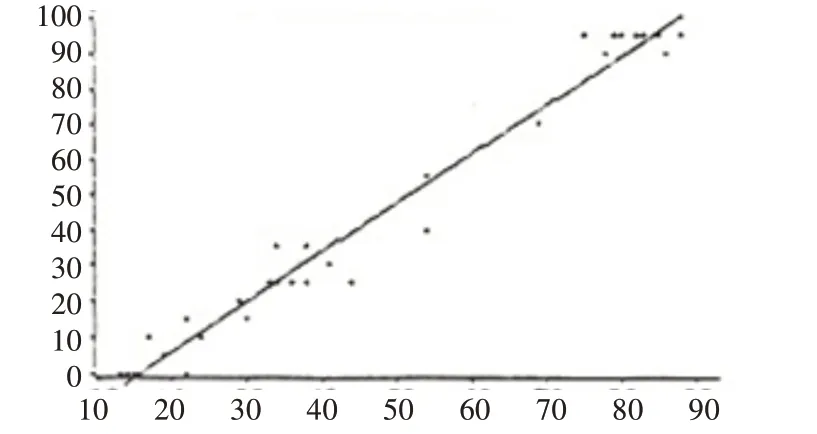
图5 直线拟合
由于图像文件能够看成一个整体的版块,所以我们每隔一定距离从下往上判断,直到碰触到黑色像素点为止(即:从下往上数第一个前景点),然后把此点作为采样点,得到一系列坐标值(X(i),Y(i))。然后使用直线拟合算法算出该直线的系数a,b,得到拟合直线:y=ax+b,此直线就是图像文本的方向直线,在由此直线可以得出倾斜角:α=arctanb,然后再进行倾斜校正。如果我们每一行都用此方法进行直线拟合,则拟合的直线就是当前行的基线下界。这是一种新的方法,是本文的创新。
3.2.4 小结
通过投影图法,Hough变换法,直线拟合法,我们发现效果都合格,但其中的投影法还可以运用到基线的评估上,而我们特征提取需要判定基线。所以本文后续所使用的倾斜校正和基线评估方法就是基于投影图法的。
3.3 联体段切分
最基本的建立模型[11~13]的单位有比划、字母、单词。维吾尔文是拼写词,词汇量达几百万之巨,随着社会的发展新词也在逐步增加,建立词汇模型不切实际。建立笔画模型更是不切实际。我们选择了基于联体段的切分和文字识别模型,识别的模型就是基于此的。我们继续利用垂直投影的方法在文本行的基础上进行联体段的切分(同理水平投影切分的原理和垂直切分的一样,水平切分是为了划分文本行)。
图6中矩形框框出来的长方体就是根据水平和垂直投影切分出来的联体段,也是进行建模的基础单位。记录下矩形框的左上角的坐标位置以及长度和宽度,就可以对矩形框(联体段)进行图像处理了。
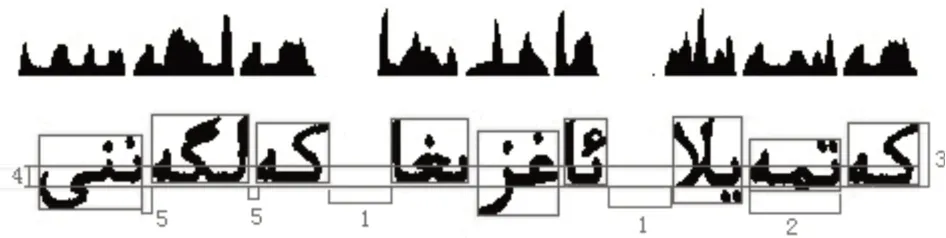
图6 联体段切分结果
3.4 细化
为了使特征形式显现,需要对文本图像进行细化。使笔划宽度变为只有一个比特(bit)的细曲线。为了不破坏文字特征我们的细化要保证如下要求:1)笔画不能造成断裂,必须是连续的。2)要将笔画的整体细化为一个比特(bit)的单线。3)骨架拓扑结构和整体字形没有被改变。
常用的细化算法有Pavlidis,Hilditch,Rosen⁃feld,基于索引表的细化算法,数学形态学细化算法等。本文经过测试最终选用了Rosenfeld算法,此算法的处理结果满足细化骨架的三个基本要素,经过验证效果良好[14~15](图7)。
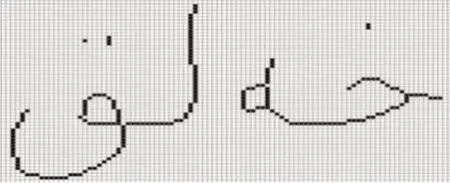
图7 Rosenfeld细化算法下的像素点模型
3.5 训练用比对方法的建立
至此我们做好了特征提取,识别训练的准备。但是训练部分必须要知道对应的维文Unicode码字符串,它起到了标识和认识的目的。这就需要我们进行一一匹配(比对方法建立)。为此开发了一个由程序自动划分并加人工校正的匹配程序。匹配程序难免受躁点和切分的影响,人为校正使每一个维吾尔文图像文本的联体段与其Unicode码进行了完美的匹配,如图8。最后把Unicode码加入了特征库,作为训练比对的参照。

图8 图像文本联体段与其Unicode码的对齐
这里有个难点,对于图像文件的联体段如何进行划分第3.3节已经解决。那么,对于文本文件的联体段如何自动进行划分呢?其实,维吾尔文的联体段结束标识均是由字母的尾写形式组成的。经过多方求证,在维吾尔文文章中联体段结束标识除了是维语尾写字母外还包括英文、数字、特殊字符等[16]。结合图像文本的切分这些就都是我们判断结束的标志了。经过搜集整理,得出维文联体段结束字母共有十三个,其中十一个用十六进制的Uni⁃code码定义为

另外还有两个用十六进制的Unicode码定义为
static WCHAR WordPartEndS[2]={0x0649,0x06d0},这两个字母也是维文联体段的结束字母,当这两个字母后面跟着上面十一个字母中任一个字母时,上面的字母为此联体段的结束字母。
4 结语
本文根据维吾尔文文字的特点,以联体段为基本建模单位,通过VC++完全实现了印刷维吾尔文图像识别技术中的预处理部分。预处理完成的工作有去噪、倾斜校正、基线判定、联体段切分、细化等。为了能够更好地去噪使用了改进的滤波方法。在倾斜校正,基线评估中提出了直线拟合的校正方法,用投影法完成基线判定。为方便后续特征的提取选取了合适的细化算法,同时建立了比对方法程序。在此基础上对联体段提取相应的特征用于后续的识别。
