基于用户动态兴趣标签的推荐模型研究
2021-11-07周朴雄宫楚凡
周朴雄 宫楚凡
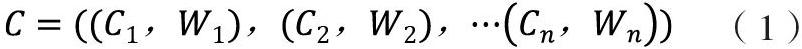


摘 要 随着网络交互性的增强,用户偏好会随主客观条件的变化而转变,因此准确把握用户的动态兴趣是互联网信息平台需要不断探索的问题。本文运用标签描绘用户兴趣,结合兴趣强化和兴趣衰减两方面因素,构建用户动态兴趣模型,以流程图的方式表示推荐模型,并将豆瓣读书的标签资源作为实验对象验证模型的可行性。
关键词 动态兴趣 社会化标签 聚类分析 推荐模型
分类号 G251
DOI 10.16810/j.cnki.1672-514X.2021.09.010
Abstract With the enhancement of network interactivity, user preferences will change with the changes of subjective and objective conditions. Therefore, accurately grasping the dynamic interests of users is a problem that needs to be explored continuously by the Internet information platform. This paper uses tags to describe users interests, combines the two factors of interest enhancement and interest decay to build a user dynamic interest model, and expresses the recommendation model in the form of flow chart. It also takes the label resources of Douban reading as the experimental object to verify the feasibility of the model.
KeywordsDynamic interest. Social tags. Cluster analysis. Recommendation model.
隨着互联网的不断发展,在线生活方式逐渐渗透到大众生活的方方面面,大众开始在网络上进行言论发表、在线购物、浏览器访问等行为。这些网络行为属于用户的特征资源,在很大程度上折射出了用户的兴趣偏好。用户的兴趣处于一个动态变化的过程中,用户的年龄、婚姻状况、所处环境等客观条件以及用户受教育程度、自身性格、个人喜好等主观条件都会对用户兴趣产生影响,这就使得用户在网络上所产生的属于个体表征的信息资源不仅数量庞大而且具有一定的时效性。因此,怎样从数量庞大的这些信息资源中更加精确地识别出用户当下的兴趣,提供满足用户兴趣需求的信息资源是互联网信息平台需要不断探索的问题。
1 用户兴趣推荐研究及其社会化标签应用
用户兴趣会随着主观条件和客观条件的改变而发生转变,学者们将这种转变定义为兴趣迁移,又称用户兴趣漂移。在互联网平台上,用户兴趣的转变通常可以用用户信息行为的转变来体现,即通过分析用户表征的信息(例如用户自定义标签、用户搜索历史等)来识别用户兴趣偏好。同时这些信息与用户兴趣的衰减、 增强也是相互关联的[1]。
1.1 用户兴趣推荐研究
目前国内外的兴趣推荐研究主要基于用户在某一领域的兴趣来推荐相应的资源,且侧重于相应的理论和算法的研究。
在用户兴趣建模方面,有两种通用方法:一种是显示方法,即用户自发性标记感兴趣的内容或者用户自主加入资源的评估反馈活动,强调用户的自发性;另一种是隐式方法,不需要用户自发参与,而是通过分析用户的历史行为来获取用户的喜恶,从而构建用户兴趣模型。Pazzani等将页面的标注信息作为训练样本,进一步分析每个词语的信息增益值,并选择其中的最大值来表示用户兴趣[2]。Adomavicious等利用数据挖掘技术分析用户在互联网平台上的行为信息,得到用户间的关联,最终形成一个网状的用户兴趣模型[3]。王科将两种建模方法相结合,提出显隐式兴趣漂移检测模型,从而精准判断用户当前的兴趣偏好[4]。李志隆等通过构建领域本体来对用户建立兴趣模型,并结合兴趣度和传递调整的方法对兴趣模型进行更新[5]。
在兴趣迁移推荐方面,主要有时间窗口法、遗忘函数法两种方法。于洪等引用心理学领域的艾宾浩斯遗忘曲线将用户兴趣划分为长期兴趣和短期兴趣,提出了基于遗忘曲线的协同过滤推荐算法[6]。张艳芳等将指数遗忘权重与时间窗相结合,在强调了近期兴趣的同时也突出了重复出现的早期数据的重要性[7]。Ding等将时间衰减因子引入到评分公式中,提出了一种基于项目的协同过滤算法[8]。叶锡君等将用户兴趣权重、项目时间等因素结合起来,提出了一种基于用户兴趣和项目周期的推荐算法,并利用融合因子将信息综合起来,从而获得推荐列表[9]。
1.2 社会化标签应用
随着网络交互性的增强,主客观条件的转变会导致用户偏好发生转变,因此准确把握用户的动态兴趣是精准推荐的关键,因此,本文结合社会化标签提出一种面向用户动态兴趣的推荐模型,并进行实证研究。
社会化标签是用来标注信息资源的非线性组织的关键词或术语[10],用户可以根据自身的喜好和语言习惯对虚拟社区如豆瓣、贴吧等中的信息资源进行标注,同时用户也可以使用系统中已有的标签对信息资源进行标注,且所有用户的标注都相互可见。总的来说,用户一方面可以运用标签来管理自己的信息资源,另一方面可以通过查找关键词以获得其他人分享的资源。
随着Web2.0时代的到来,标签云系统应运而生。标签云系统是由用户、信息资源和社会化标签三个部分组成,具有开放多元、动态多变的特点,用户可以通过社会化标签个性化地定义、组合、分享和应用信息资源,因此三个部分可以看作是一个整体[11]。
社会化标签开拓了用户兴趣模型构建的新领域。标签象征着用户对所标记资源的喜恶,代表了用户的偏好。运用标签描绘用户兴趣具有以下几个优势[12]:(1)粒度更细。因为标记标签是用户的自发行为,标签是用户对所标记资源的摘要和说明,所以可以将用户对标签的喜恶视为用户对所标注资源的喜恶。(2)解释性更好。标签具有丰富的语义信息且标签间还可能存在一定的语义关联,因此具有更好的解释性和接受度。(3)话题性更强。标签之间存在一定的关联性可以组成多种兴趣群,用户可以通过标签加入所需的兴趣群或话题社区。
2 用户动态兴趣模型及其指数
本文运用社会化标签来描绘用户兴趣,参考李媛媛[13]的方法将用户的社会化标签看作用户的若干个兴趣量,这些兴趣量共同构成了用户完整的兴趣空间,通过计算用户兴趣量的兴趣权重构建模型。本文将用户动态兴趣模型表示为:
其中向量C为用户存在的所有兴趣量,Ci为第i个兴趣量;Wi为Ci的兴趣权重。兴趣权重代表着用户对某一兴趣量的喜恶程度。同时,通过分析用户的标签行为,计算用户的兴趣强度指数和稳定性指数,进而得出用户的兴趣权重,建立模型。
2.1 用户兴趣强度指数
用户兴趣强度指数可以在一定程度上反映用户对已标注资源的兴趣情况,可以通过计算用户使用标签的频次来确定。即用户使用相同标签标注资源的频次越高,表明用户越偏好运用这一标签来解释和概括信息资源,也就是说用户的兴趣就是这一标签。由于标签系统是一个不断更新的系统,随着用户的不断参与,系统中的标签量不断扩大,而用户兴趣强度指数又与用户使用的标签总量有关。因此,对于用户所用的每个标签,其强度指数可以通過公式(2)来表示。
其中,f(u,tk)表示用户u运用的标签tk的用户兴趣强度指数;freq(u,tk)表示tk被运用的频次;n表示所用标签的总量。由公式(2)可以看出,f(u,tk)越大,代表用户越喜欢运用标签tk,因此标签tk也就越能体现用户的偏好。
2.2 用户兴趣稳定性指数
用户兴趣稳定性指数体现了在时间的影响下用户兴趣的动态变化。本文采用谢梦瑶[11]的计算方法,利用用户的每个兴趣都具有遗忘衰减与记忆强化的过程,并以此来表征时间要素与标签兴趣权重的作用关系,进一步得出稳定性指数。
对于时间点上的标签权重,本文采用TF(词频)方法进行计算,即计算用户u运用标签tk的频次占某一时间点上(通常为一天)用户使用的所有标签频次的比重,从而得到标签tk在某一时间点T上的权重WT(u,tk),计算公式如(3)所示。
其中,标签tk在某一时间点T上的权重用 WT(u,tk)来表示,tf(u,tk)表示 tk 在T上出现的频次,n表示为T上的标签总量。
如果标签tk在一定时间内没有被用户反复使用,随着时间的持续延长用户对标签tk的兴趣权重Wtk将会下降,标签权重的遗忘衰减,可以使用指数遗忘函数来计算,Wtk遗忘函数如(4)所示。
用户对已用标签的再次使用是该标签的记忆强化,根据兴趣衰减规律,每个遗忘阶段的初始兴趣度由上一阶段标签tk兴趣度衰减后的余量和再次使用同一标签tk进行标注所带来的兴趣的增量相加而成,如公式(5)所示。
用户运用标签进行标注的行为既存在遗忘衰减的环节也存在强化学习的环节,综合考量用户兴趣的衰退和增强,利用公式(6)动态地计算不同标签的权重,从而构建用户兴趣稳定性指数。
2.3 用户兴趣权重计算
上述两个指数分别从不同角度来表征用户兴趣,兴趣强度指数在标签数量上反映出用户的兴趣偏好,稳定性指数从兴趣衰减和兴趣强化方面反映出用户兴趣的动态变化,因此结合这两个指数就可以得到用户标签兴趣权值,计算如公式(7)所示。
3 用户兴趣推荐模型及陈述
本文结合用户动态兴趣与社会化标签进行研究,在计算每个兴趣量权重的基础上,按照权重值的大小对标签进行排序,选择权重值大的标签作为强兴趣标签,对强兴趣标签进行聚类分析进一步筛选出最能代表用户兴趣的推荐标签,推荐模型如图1所示。推荐模型分为数据准备、数据分析两大模块,其中数据分析包括用户动态兴趣模型构建和聚类分析两部分。
3.1 数据准备
数据准备包括对数据筛选和数据预处理。由于本文选用标签刻画用户兴趣,所以数据准备在本文中就是标签的筛选和标签的预处理。在数据筛选方面,首先选取足量的用户标签;其次标签可以来源于具有标注系统的某一网站或某一社交平台。用户标签的获取方式分为显性获取和隐性获取两种,本文采用显性获取方式来获取标签,即获取用户自定义标签、用户间接引用其他用户的标签、用户注册信息等。
在标签预处理方面,一是选择名词作为标签,剔除数字、特殊符号等不能充分表征用户兴趣的无用标签;二是提取标签特征。本文采用中文分词工具 ICTCLAS 切分语句类标签,以提取标签语句中的关键名词;针对英文标签,选取词根作为标签词,并将其统一翻译为中文标签词语。三是规范标签语义。由于标签含有丰富的语义使得标签间存在各种关联,如等同、整部、逻辑关系等,因此本文中的标签语义规范就是加强对标签间的属性、关系的挖掘,实现标签的优化重组,例如同义词合并处理等。
3.2 数据分析
本文对用户兴趣标签采用聚类分析。聚类是将数据集分为多个相似对象组成的多个组或簇的过程,使得同一组中对象间的相似度最大化,不同组中对象间的相似度最小化。聚类组代表某个紧密相连的组合,组内对象在兴趣上具有一定的相关性;类的大小体现了聚类组的聚集程度[10]。由此进一步可从得到的聚类组中筛选出最能代表用户兴趣的推荐标签。
推荐标签的选择规则是:若某一聚类组中有且只有一个标签,则该标签为该聚类组的推荐标签;若某一聚类组中有两个或两个以上标签,则选择该聚类组中标签兴趣权重最大的一个标签作为该聚类组的推荐标签。
4 数据采集与处理
为了确保研究的可靠性,本研究选择豆瓣读书平台上注册年限为10年以上(含10年)的长期活跃用户作为实证研究的对象,基于此随机挑选了 10 名符合条件的近期活跃用户,并记录了各用户的基本信息如用户名、注册时间、在读书籍数、想读书籍数、读过书籍数等,如表1所示。考虑到所选的10名用户中,用户Rinna芮娜的数据值处于中间位置,所以本文将以用户Rinna芮娜作为研究对象。
选择用户Rinna芮娜(下文简称芮娜)在2019年9月-11月感兴趣的书目作为实验样本,采集用户感兴趣书目的常用热门标签作为刻画用户兴趣的实验数据,同时使用汉语词法分析系统ICTCLAS对标签数据进行分词处理,并将所得数据进行清洗和整理,得到用户的标准标签集作为实验集,如表2所示。
由标准标签集可知,用户芮娜在2019年9月-11月期间已使用77种标签进行标注(共计217个)。根据公式(2)计算其标签强度指数,得到标签强度指数散点图。再利用公式(6)动态地计算不同标签的权重,从而构建用户兴趣稳定性指数,得到标签稳定性指数散点图,其中在计算标签的遗忘衰减时,取遗忘因子为hlu=10。由于标签的兴趣强度指数和稳定性指数同等重要,因此取调和因子为0.5,再根据公式(7)计算不同标签的兴趣权值,如表3所示。
5 标签相似度计算及聚类分析结果
根据计算出的标签兴趣权重,选择兴趣权重较大的前15个标签作为强兴趣标签,并采用《知网》语义词典计算强兴趣标签的相似度,结果见表4。
本文使用UCINET6软件对用户的强兴趣标签进行聚类分析,并将上述相似度结果导入UCINET 6中,可获得7个组,并将得到的7个组分别标记为组1—组7,结果如图2所示。
根据上述推荐标签的选择规则得到最能刻画用户兴趣的推荐标签组,即美国、全球化、伦理学、文学、犯罪、小说、道德等7个推荐标签组。之后,平台可将使用推荐标签组中的标签进行标注的书籍优先推荐给用户,其中满足7个推荐标签的书籍最先推荐,满足6个的次之,以此类推,满足1个推荐标签的书籍最后推荐。
可见,此种应用社会化标签进行聚类分析的模型,准确地把握了用户兴趣的动态多变性,实现了较为精准的推荐。但本文尚存在两方面的不足,一是标签相似度计算的精度不足,二是由于人力物力的限制,本文的实证研究仍有不足。因此未来的工作需要着力解决以上两个不足,实现更为精准的推荐。
参考文献:
范玉全,陈跃新.基于本体的用户兴趣模型的更新方法[J].计算机光盘软件与应用,2013,16(7):22-23,35.
PAZZANI M, BILLSUS D. Learning and revising user profiles: the identification of interesting web sites [J]. Machine Learning, 1997, 23(3): 313-331.
ADOMAVICIOUS, TUZHILIN. Learning about user from observation [J], Information sciences,2008, 178(17): 3356-3373.
王科. 基于兴趣漂移协同过滤算法的推荐系统研究与实现[D].咸阳:西北农林科技大学,2017.
李志隆,王道平,关忠兴.基于领域本体的用户兴趣模型构建方法研究[J].情报科学,2015,33(11):69-73.
于洪,李转运.基于遗忘曲线的协同过滤推荐算法[J].南京大学学报(自然科学版),2010,46(5):520-527.
张艳梅,王璐.适应用户兴趣变化的社会化标签推荐算法研究[J].计算机工程,2014,40(11):318-321.
DING Y,LI X. Time weight collaborative filtering[C].Proceedings of the 14thACM international conference on Information and knowledge management.ACM,2005:485-492.
叶锡君,袁培森,郭小清,等.基于用户兴趣和项目周期的协同过滤推荐算法[J].南京理工大学学报,2018,42(4):392-400.
胡昌平,胡吉明,邓胜利.基于Web2.0的用户群体交互分析及其服务拓展研究[J].中国图书馆学报,2009,35(5):99-106.
谢梦瑶. 社会化标注中用户动态兴趣主题挖掘[D].杭州:浙江理工大学,2017.
扈维,张尧学,周悦芝.基于社会化标注的用户兴趣挖掘[J].清华大学学报(自然科学版),2014,54(4):502-507.
李媛媛. 結合本体与社会化标签的用户动态兴趣建模研究[D].武汉:武汉大学,2019.
周朴雄 华南理工大学电子商务系硕士生导师。 广东广州,510000。
宫楚凡 华南理工大学大学电子商务系硕士生。 广东广州,510000。
(收稿日期:2020-07-14 编校:刘 明,谢艳秋)
