基于语音识别的朝鲜语语音检索方法
2021-11-03徐博文金小峰
徐博文, 金小峰
( 延边大学 工学院, 吉林 延吉 133002 )
0 引言
语音检索是指在语音文档中查找与检索语音相关的语音片段及其定位信息的方法[1].目前,语音检索大多采用的是分步策略的方法,即首先通过上游的语音识别技术得到语音的转写结果,然后再经过下游的检索得到最终的结果.2006年, Burget等[2]在语音识别的基础上基于多字查询算法和对三音素进行索引提出了一种语音识别词格网络的检索方法,该方法的检索效果显著优于单音素网络.2011年,李伟[3]提出了一种基于内容的汉语语音检索方法,该方法可有效提高检索效率.金惠琴[4]利用特征级融合和PCA降维的方法设计了一种维吾尔语关键词检索系统,该系统可有效提高维吾尔语的检索速度和重音检测率.Liu等[5]提出了一种利用区分性局部空间-时间描述符对中文语音关键词进行检索的方法,该方法可有效提高语音检索中的抗噪能力.王朝松等[6]提出了一种侧重于关键词的深度神经网络声学建模方法,该方法利用非均匀的最小分类错误准则来调整深度神经网络声学建模中的参数,并利用 AdaBoost 算法来动态调整声学建模中的关键词权重,从而提高了关键词检索的性能.李鹏等[7]提出了一种将不同语音识别系统的词图进行相交融合的关键词检索方法,该方法能综合利用各词图的得分信息来减小冗余,进而可有效提高关键词的检索效率.Chen等[8]提出了一种将语音识别和填充模型相融合的方法,该方法可提高关键词的检出性能.Zhuang等[9]利用LSTM - CTC (long short term memory - connectionist temporal classification)提出了一种基于深度学习的非限制词表关键词的检索方法,该检索方法具有词典无关的优点.Dhananjay等[10]提出了一种基于音素子空间特征增强的关键词检索方法,实验结果表明该方法优于传统DNN后验概率的方法.2021年, Huang等[11]在编码器 - 解码器网络中引入了多头注意机制和软三重损失函数,该方法可有效提高检索性能.本文借鉴上述研究中的分步策略,利用改进的朝鲜语语音识别框架KoSpeech[12]学习来得到朝鲜语声学模型,并在此基础上提出了一种基于语音识别的朝鲜语语音检索方法.
1 改进的朝鲜语声学模型学习框架
2021年, Kim等[12]提出了一种专门针对朝鲜语语音识别的KoSpeech框架,该框架的核心编解码器为LAS (listen, attend and spell)模型[13].LAS模型由1个声学模型编码器和1个基于注意力机制的字符解码器组成,如图1所示.由于LAS模型包含注意机制,因此该模型可以通过学习直接得到语音和文本之间的映射关系.且当训练数据充足时,该模型还可以实现声学模型与语言模型的联合学习.
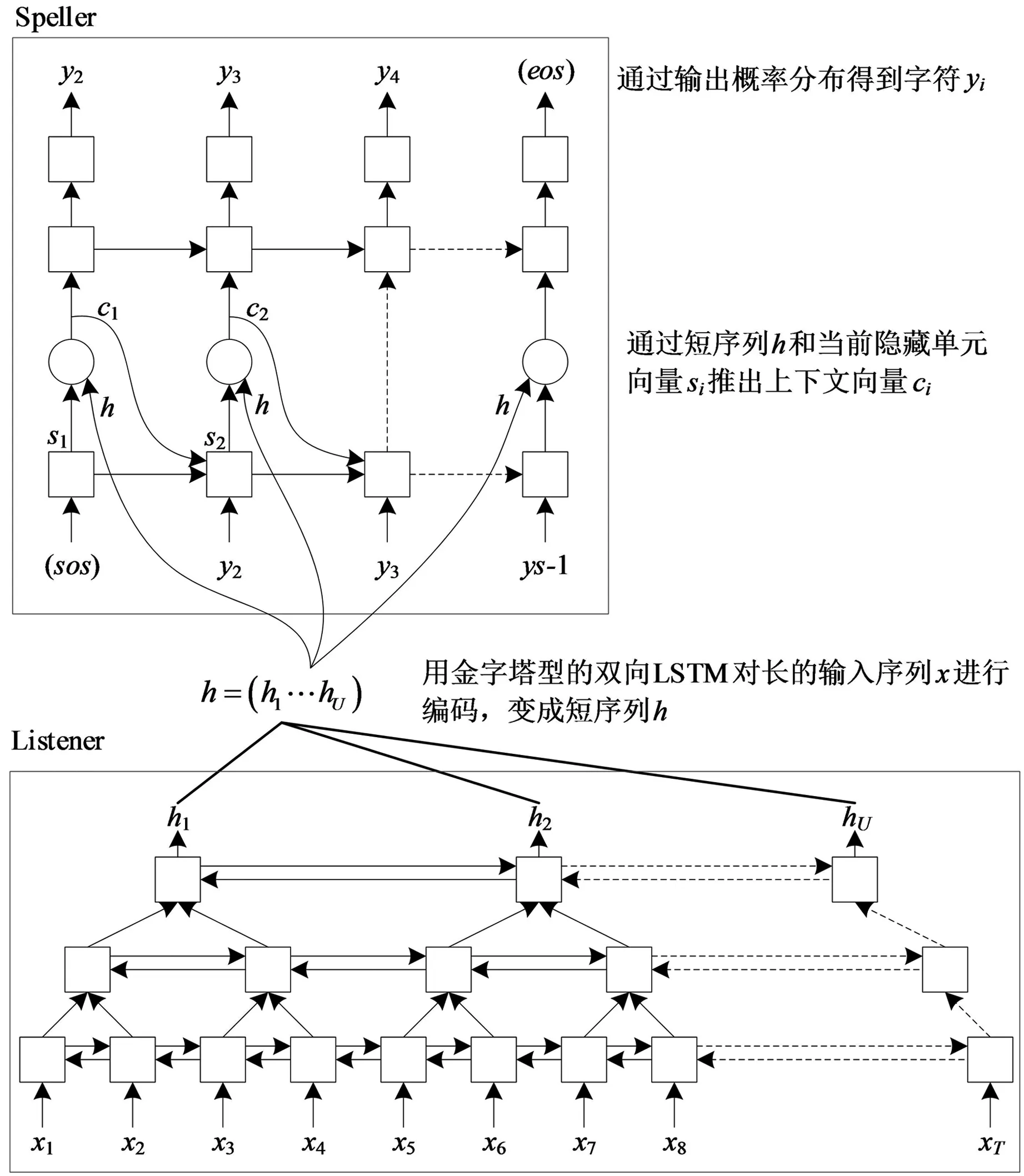
图1 LAS模型的结构
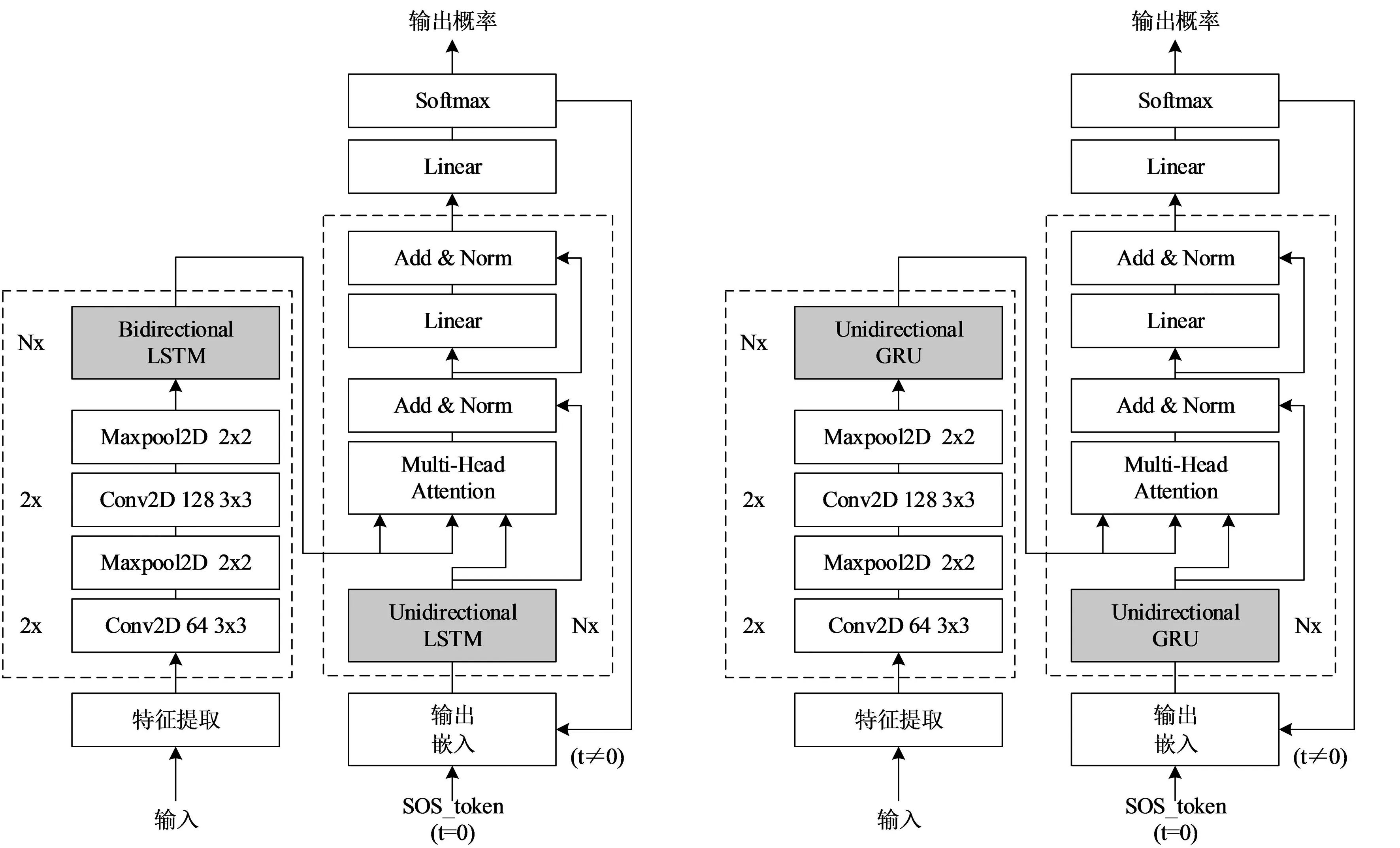
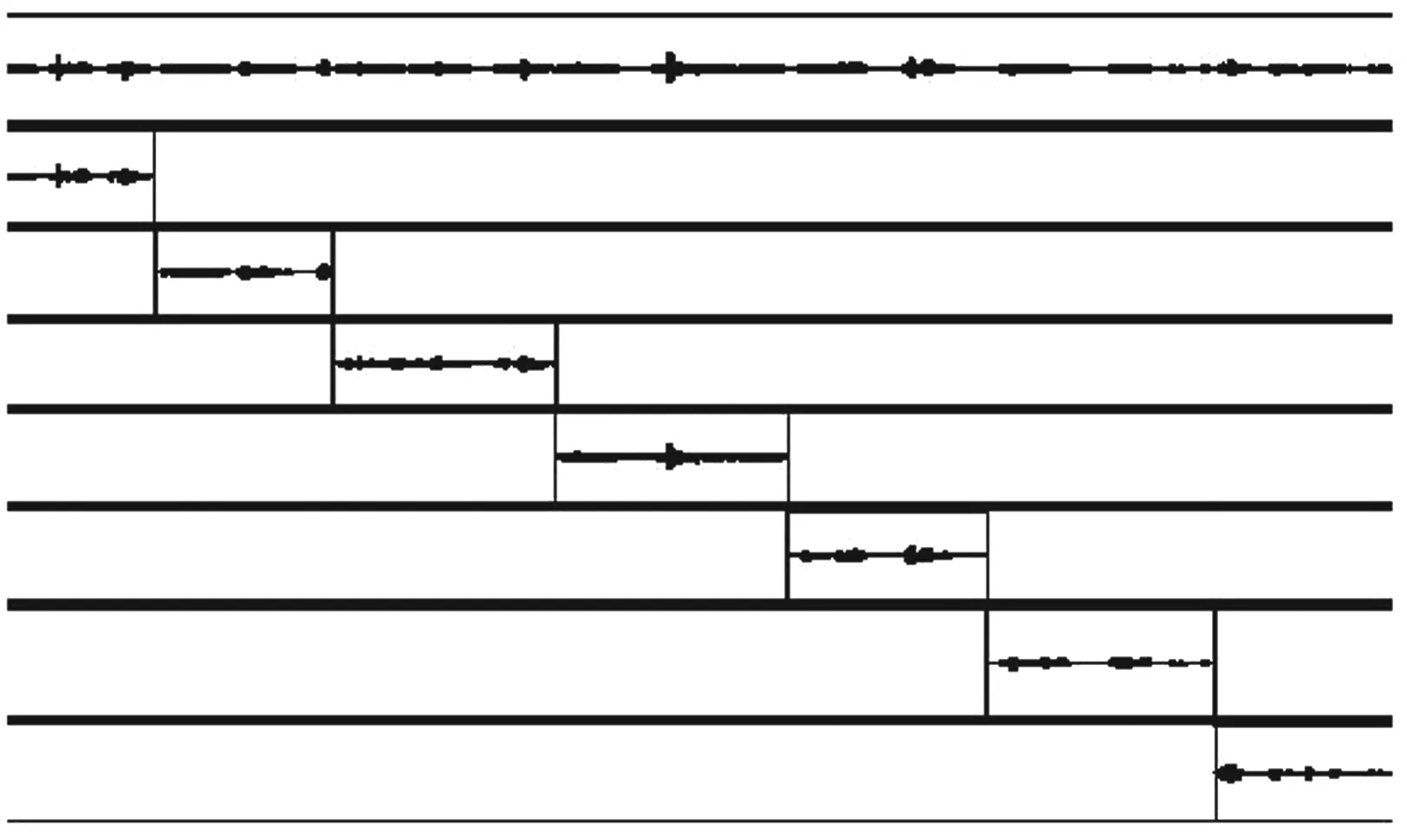
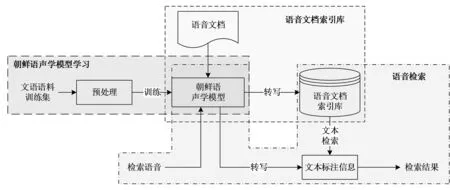
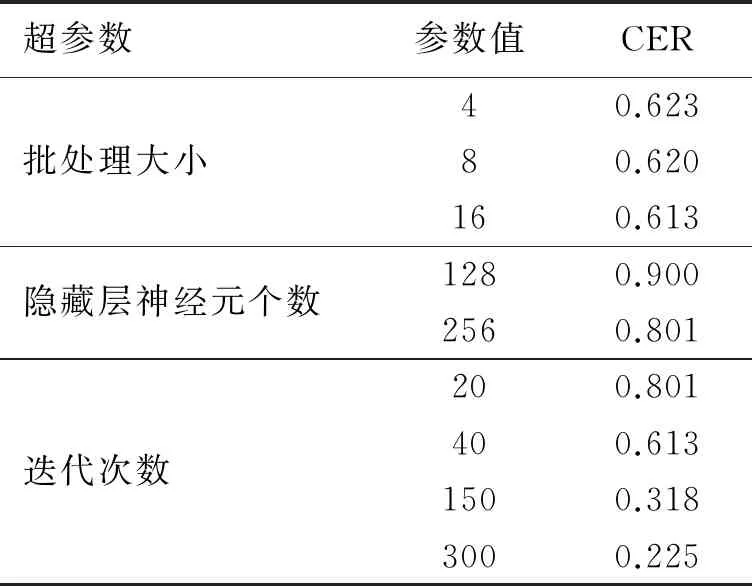
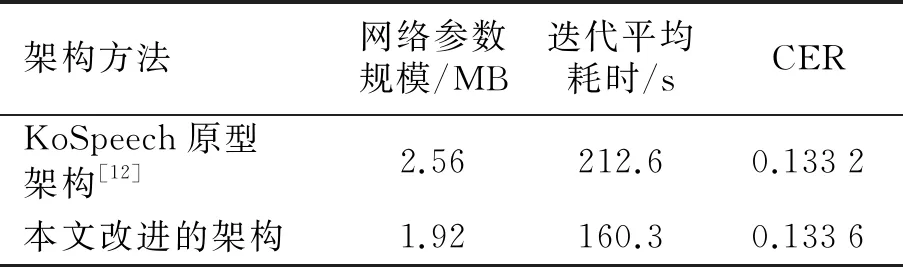
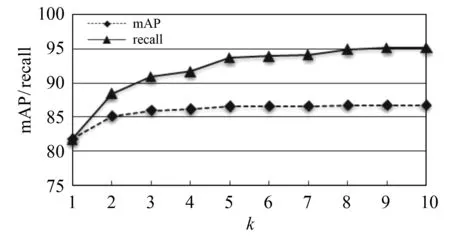
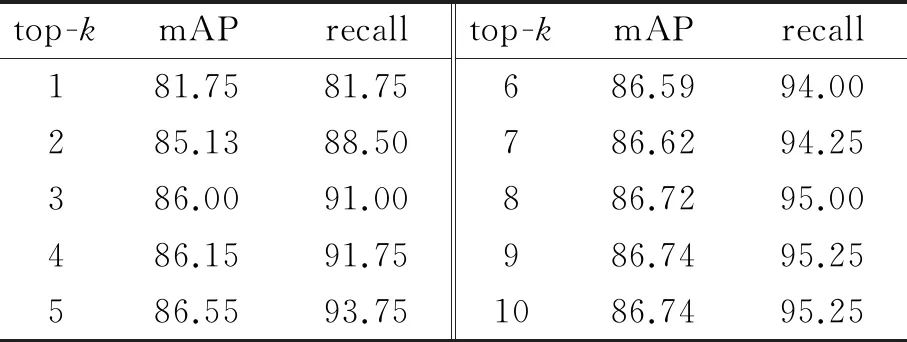
LAS框架有2个核心模块,即Listener模块和AttendAndSpeller模块.其中, Listener模块由多层双向长短时记忆网络(Bi - directional long short - term memory, BLSTM)堆叠而成.声学特征编码序列x=(x1,x2,…,xT)经由Listener模块输出时,其被转换为更为高级的编码形式h(h=(h1,h2,…,hU), 其中U h=Listen(x). (1) AttendAndSpell是一个基于注意力机制的LSTM解码器函数,为Speller的核心操作,它的主要作用是完成声学特征编码x与对应文本字符序列y的映射.设y=(〈sos〉,y1,…,yS,〈eos〉), 则AttendAndSpell可以通过(h,y)计算得到y在输入x时的概率分布P(y|x), 即: P(y|x)=AttendAndSpell(h,y). (2) 由式(2)可知,AttendAndSpell会根据先前产生的所有字符预测下一个输出字符的概率分布,即根据上一时间步的输出字符yi -1、解码器状态向量si -1和上下文向量ci -1来推理当前时间步的向量si.该过程可表示为: si=RNN(si -1,yi -1,ci -1), (3) 其中RNN在LAS网络内是一个两层的LSTM,ci(ci=AttentionContext(si,h))由注意力机制得到.由si和ci可推出当前时间步的输出字符yi的概率分布.设CharacterDistribution为多层感知机的softmax输出,第i个时间步的字符输出概率的计算公式为:P(yi|x,y (4) 由于LSTM性能与GRU性能相近[14],因此本文对KoSpeech框架做如下改进:用图2(b)中的单向门控循环单元(GRU)替换图2(a)中的Bidirectional - LSTM和Unidirectional - LSTM.由于GRU比LSTM少1个门,因此其能够降低运算量,进而提高学习的速度.改进后的KoSpeech框架可通过学习得到的朝鲜语声学模型将语音文档和检索语音的语音信号转写为文本并输出. (a) KoSpeech框架 (b) 改进的KoSpeech框架图2 改进前后的KoSpeech框架 语音检索需要建立语音文档索引库,其主要目的是为了便于集中管理语音文档和提高检索速度.另外,为提高语音文档转写文本的准确性和语音检索的时间定位精度,本文提出了一种语音文档语义分割方法,即将语音文档分割为一系列具有相对语义完整性的子语音文档.语音文档的分割方法是依据人们的说话习惯和文语语料数据集中语音数据的平均时长,将5 s作为每段子语音的初始分割时长,然后再结合语音信号的能量谱和阈值进一步精确定位分割点.具体的分割步骤如下: 输入:语音文档 输出:子语音文档分割信息 初始化:初始分割语音段的时长T(T=5 s),初始分割起止位置(pstart=pend=0). Step 1 读取一个语音文档数据W, 计算静音段的平均能量阈值e、 能量谱E和语音文档的总时长L. Step 2 while(pend≤L): pend←pend+T ifE(pend)≥ethen 向后搜索,直至E(pend+Δt)≤e, pend←pend+Δt 将W[pstart,pend]作为分割片段,转写分割片段,记录该片段的起止时间 pstart←pend Step 3 把W子语音文档分割信息记录到索引库中. Step 4 如果处理完所有语音文档,转Step 5,否则转Step 1. Step 5 输出所有语音文档的分割信息. 图3是语音文档采用上述分割方法处理后的结果,图中第1行是该语音文档的完整波形图,第2行至第7行是分割的子语音文档的波形.由图3可以看出,在保证分割语义完整性的前提下,各子语音文档的时长存在差异. 图3 语音文档切分结果 语音文档索引库包含的主要信息有语音文档名称、子语音文档中的相对完整的起止时间以及子语音文档的转写文本信息.为了验证本文提出的语音文档分割方法的有效性,对277个语音文档进行了分割实验.分割共得到了1 978个子语音文档,其中最长为7.5 s、最短为0.32 s、平均为4.3 s.该分割结果与人工分割结果接近(见表1),由此说明本文提出的语音文档分割方法是有效的. 表1 语音文档分割实验结果 本文提出的朝鲜语语音检索方法采用分步策略:第1步,通过改进的KoSpeech框架学习得到朝鲜语的声学模型,以此实现语音文档和检索语音等语音信号的文本转写输出;第2步,将语音检索任务转化为文本检索任务,即在语音文档索引库的转写文本中匹配和定位检索语音的转写文本.本文提出的语音检索方法的处理流程见图4. 图4 朝鲜语语音检索的处理流程 本文采用的文本检索方法是基于编辑距离(levenshtein distance)的文本相似度度量方法,即对检索语音转写文本与索引库转写文本的匹配度进行打分,并以top -k评价检索的准确率.计算两个字符串a和b的编辑距离的公式为: leva,b(i,j)= 其中, leva,b(i,j)表示的是a中前i个字符与b中前j个字符之间的距离.当min(i,j)=0时,意味着i和j中有一个为0, leva,b(i,j)=max(i,j), 即编辑距离为i和j中的最大值.当min(i,j)≠0时,编辑距离为删除操作(leva,b(i-1,j)+1)、插入操作(leva,b(i,j-1)+1)和替换操作(leva,b(i-1,j-1)+1(ai≠bj)下的最小值.1(ai≠bj)是指示函数,当ai=bj时取0, 当ai≠bj时取1. 若将本文检索语音的转写文本字符串设定为a, 将索引库中的每个子语音文档所对应的转写文本字符串设定为b, 则a和b的匹配度得分可由式(5)计算获得.得分越高表示两者越相似.按照得分值大小降序排序即可生成候选的检索结果. (5) 实验数据采用公开数据集AI - hub中的朝鲜语文语语料,每个样本由一个语义完整的语音文件和一个对应的人工标注文本文件组成,所有的语音数据时长为1 000 h.由于受计算机硬件资源的限制,本文滤除了文本字符数超过100的样本,并在滤除后的文本中随机选出1.1万条文语语料用于声学模型训练,其中训练集8 000条、验证集2 000条、测试集1 000条.样本的音频格式为PCM, 采样频率为16 000 Hz, 音频特征为80维fbank, 帧长度为20 ms, 帧移为10 ms, 窗口使用汉明窗. 在改进的KoSpeech架构的超参数调优实验中,分别对批处理大小、迭代次数和隐层单元数进行了调优,评价指标采用字符错误率(character error rate, CER).CER越低表示语音识别方法的性能越好.具体调优实验过程如下: 1)批处理大小参数调优.预设隐层单元数为256, 分别取批处理大小4、 8、 16.当迭代次数为40、 批处理大小为16时CER收敛(稳定在0.613), 因此最佳批处理大小为16. 2)隐层单元数参数调优.批处理大小取16, 隐层单元数分别取128和256.当迭代次数为20次、隐层单元数为256时CER收敛(稳定在0.801), 因此最佳隐层单元数为256. 3)迭代次数参数调优.批处理大小和隐层单元数分别取16和256.当迭代次数为300次时CER收敛(稳定在0.225), 因此最佳迭代次数为300. 超参数调优实验的具体结果见表2.由以上结果可知,当批处理大小、隐层单元数以及迭代次数分别取16、 256、 300时模型的性能最优. 表2 超参数调优实验结果 为了验证改进的KoSpeech架构的性能,本文将改进的KoSpeech架构与文献[12]中的KoSpeech原型架构进行对比实验,结果见表3.由表3可以看出,改进的KoSpeech架构的CER指标与KoSpeech原型架构基本接近,表明二者的语音转写性能相近.另外,改进的KoSpeech架构的网络参数规模和迭代平均耗时显著低于KoSpeech原型架构,表明改进的KoSpeech架构的学习速度优于KoSpeech原型架构. 表3 改进前后的KoSpeech架构的性能 检索实验采用另外准备的451条检索语音,评价指标使用基于top -k的召回率(recall)和均值平均精度(mean average precision,mAP).计算mAP时,首先利用式(6)计算不同k值对应的平均精度值(average precision,AP),然后再利用式(7)求出mAP值. (6) (7) 其中Q表示查询结果的个数,AP(q)表示第q个查询精度,N表示检索数据库的语音个数, rel(k)表示检索的语音是否和查询语音相关(1为相关, 0为不相关). 表4为k取不同值(k=1,2,3,…,10)时的实验结果, mAP和recall随k值的变化见图5.从表4和图5可以看出:随着k值的增加,召回率显著提高,并且在k=9时召回率达到最大值(95.25%); mAP在k≥2时呈现小幅上升随后趋于稳定,且在k=9时达到最大值(86.74%).mAP虽然总体上低于召回率,但是较高的召回率对于语音检索任务而言比mAP更具实用意义. 图5 mAP和recall随k值的变化 表4 本文方法的检索实验结果 % 研究表明,本文以构建朝鲜语声学模型为目标而改进的KoSpeech框架可以降低基于语音识别的语音检索方法对数据集规模和语言模型的依赖,进而可以减少模型参数规模,提高训练速度.本文提出的语音文档的分割方法能够有效地分割出具有相对完整语义的子语音文档,有助于提高语音文档转写文本的准确性和语音检索的时间定位精度.当k=9时,本文方法语音检索的召回率和均值平均精度分别达到了95.25%和86.74%,该结果表明本文提出的语音检索方法是有效的,可应用在朝鲜语的语音检索中.在今后的研究中,我们将尝试构建音素级的朝鲜语声学模型,以此进一步提高语音转写的准确率.
2 语音文档的分割方法

3 朝鲜语语音检索方法
4 结果与分析
4.1 网络超参数调优实验
4.2 改进的KoSpeech框架的性能验证
4.3 朝鲜语语音检索实验
5 结论
