基于数据挖掘的实践及应用
2021-10-30雷湘琦
雷湘琦
摘要:过去数十年中,数据挖掘得到广泛的应用,作用的领域包括人工智能、统计学、数据库等等。于当下的学生来说,数据挖掘是一门经久不衰的学科,而对于从事数据挖掘的工作者来说,更是深刻地体会到了数据挖掘强有力的发展前景。对数据挖掘这个领域应用最多的就是算法,掌握算法的意义就抓住了数据挖掘的核心。如今,虽然数据挖掘技术的应用相当广泛,但是就算法而言其本质并未发生改变。现今运用的都是一些比较经典的算法,如传统的决策树算法等,同时这些算法也是学习数据挖掘算法的根基。文中主要列举相关算法并应用相应的实例加以佐证,指出其中的不足和需要改进的地方。
关键词:数据挖掘;决策树;鸢尾花数据
引言
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。决策树模式呈树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一个类别。学习时利用训练数据,根据损失函数最小化的原则建立决策树模型;预测时,对新的数据,利用决策树模型进行分类。在机器学习中,决策树是一个预测模型,它代表的是对象属性与对象值之间的一种映射关系决策树是一种基本的分类与回归方法,本文应用的是用于分类的决策树。
1 基本原理
决策树学习通常包括三个步骤:特征选择,决策树的生成和决策树的剪枝。
1.1 特征选择
特征选择在于选取对训练数据具有分类能力的特征,这样可以提高决策树学习的效率。通常特征选择的准则是信息增益(或信息增益比、基尼指数等),每次计算每个特征的信息增益,并比较它们的大小,选择信息增益最大(信息增益比最大、基尼指数最小)的特征。
下面重点介绍一下本文特征选择的准则:信息增益。首先定义信息论中广泛使用的一个度量标准——熵(Entropy),它是表示随机变量不确定性的度量。熵越大,随机变量的不确定性就越大。而信息增益(Informational Entropy)表示得知某一特征后使得信息的不确定性减少的程度。简单的说,一个属性的信息增益就是由于使用这个属性分割样例而导致的期望熵降低。信息增益、信息增益比和基尼指數的具体定义如下:信息增益:特征A对训练数据集D的信息增益,定义为集合D的经验熵与特征A给定条件下D的经验条件熵之差,即信息增益比:特征A对训练数据集D的信息增益比定义为其信息增益与训练数据集D关于特征A的值的熵之比,即其中n是特征A取值的个数。
1.2 决策树的生成
从根结点开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点,再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增均很小或没有特征可以选择为止,最后得到一个决策树。决策树需要有停止条件来终止其生长的过程。一般来说最低的条件是:当该节点下面的所有记录都属于同一类,或者当所有的记录属性都具有相同的值时。这两种条件是停止决策树的必要条件,也是最低的条件。在实际运用中一般希望决策树提前停止生长,限定叶节点包含的最低数据量,以防止由于过度生长造成的过拟合问题。
1.3 决策树的剪枝
决策树生成算法递归地产生决策树,直到不能继续下去为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合现象。解决这个问题的办法是考虑决策树的复杂度,对已生成的决策树进行简化,这个过程称为剪枝。
本文将应用鸢尾花数据进行决策树分析。
2 决策树的剪枝
Iris 鸢尾花数据集是一个经典数据集。数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(Iris-setosa,Iris-versicolour,Iris-virginica)中的哪一品种。
2.1 利用Decision Tree分类器对Iris data进行分类
2.1.1 Decision Tree分类过程
如图1-1。
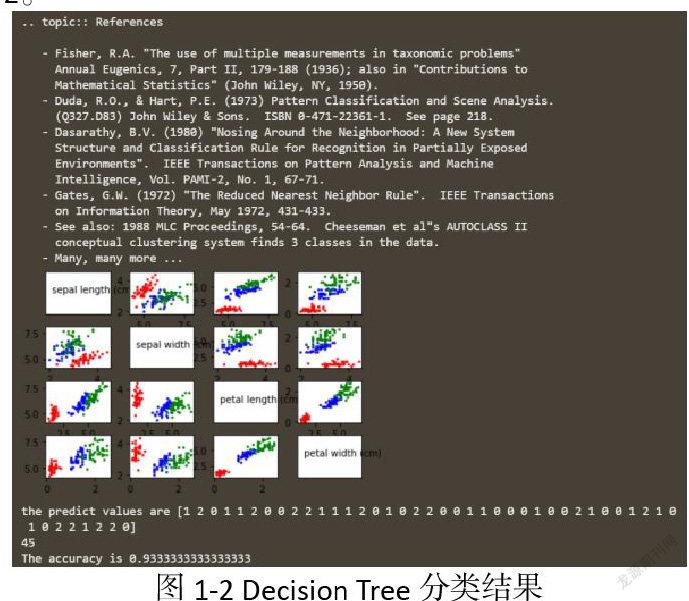
2.1.2 Decision Tree分类结果
如图1-2。
3 结束语
经上述分析,决策树分类算法与统计方法和神经网络分类算法相比较具备以下优点:首先,通过决策树分类算法进行分类,出现的分类规则相对较容易理解,并且在决策树中由于每一个分支都对应不同的分类规则,所以在最终进行分类的过程中,能够说出一个更加便于了解的规则集。其次,在使用决策树分类算法对数据挖掘中的数据进行相应的分类过程中,与其他分类方法相比,速率更快,效率更高。最后,决策树分类算法还具有较高的准确度,从而确保在分类的过程中能够提高工作效率和工作质量。决策树分类算法与其他分类算法相比,虽然具备很多优点,但是也存在一定的缺点,其缺点主要体现在以下几个方面:首先,在进行决策树的构造过程中,由于需要对数据集进行多次的排序和扫描,因此导致在实际工作过程中工作量相对较大,从而可能会使分类算法出现较低能效的问题。
参考文献:
[1]程一芳.数据挖掘中的数据分类算法综述[J].数字通信世界,2021(02):136-137+140.
[2]韩成成,增思涛,林强,曹永春,满正行.基于决策树的流数据分类算法综述[J].西北民族大学学报(自然科学版),2020,41(02):20-30.
[3]姚奇峰,杨连贺.数据挖掘经典分类聚类算法的研究综述[J].现代信息科技,2019,3(24):86-88.
