基于生成对抗网络的医学图像超分辨率重建
2021-10-24陈胜娣
陈胜娣

摘要: 针对医学图像分辨率低导致视觉效果差的问题,提出一种基于生成对抗网络的医学图像超分辨率重建方法。使用生成对抗网络架构,由生成器重建高分辨率图像,再将生成器生成的高分辨率图像送入判别器判断真伪。通过实验验证了该方法的有效性,在视觉效果和数值结果上都有所提高。
关键词: 生成对抗网络; 超分辨率重建; 残差网络; 医学图像
中图分类号:TP391.41 文献标识码:A 文章编号:1006-8228(2021)10-15-05
Super-resolution reconstruction of medical image using
generative adversarial networks
Chen Shengdi
(College of Computer Engineering, Maoming Polytechnic, Maoming, Guangdong 525011, China)
Abstract: Because of the low-resolution medical image has poor visual effects, this paper propose a super-resolution reconstruction method with generative adversarial networks to generate clearer medical image. Using the generation countermeasure networks, the high-resolution images are reconstructed by the generator, and then the images are sent to the discriminator to judge the authenticity. The experimental results show that the proposed method is effective, and both the visual effect and numerical results are improved.
Key words: generative adversarial networks; super-resolution reconstruction; residual network; medical image
0 引言
高分辨率的医学图像可以提供更加清晰的病灶信息,方便医生更加精准判别病变的部位,辅助医生進行医疗诊断。受到现有的医疗成像环境和成像系统的局限性影响,直接获取高分辨率医学图像的设备成本高[1]。图像超分辨率重建技术是从低分辨率图像重建出高分辨率图像的技术[2]。因此,可以借助超分辨率重建技术来提高图像分辨率,改善图像质量。
目前超分辨率重建技术主要有基于插值、基于重建和基于学习三类方法[3]。基于插值的方法一般是通过基函数估计相邻像素点之间的像素值,如:双线性插值、双三次插值。这类方法性能稳定、计算复杂度低,但是难以重建得到图像的高频信息,重建图像存在伪影、模糊等现象,重建效果较差。基于重建的方法一般是利用图像自相似性特点加以约束,重建图像降质过程中丢失的高频信息[4],如:凸集投影法、迭代反投影法,这类方法高度依赖先验知识且重建的图像缺乏细节纹理信息。基于学习的方法是学习低分辨率图像与高分辨率图像之间的映射关系,该类方法克服了前两类方法的局限性,重建图像质量更好[5]。
Ledig等人[6]首次将生成对抗网络应用于图像超分辨率重建领域,提出了生成对抗网络超分辨率重建模型SRGAN(Super-Resolution Generative Adversarial Network),使用感知损失和对抗损失联合恢复图像的纹理细节。Wang等人[7]在SRGAN的基础上提出增强的超分辨率生成对抗网络,使用残差密集块代替原始生成器中的残差块且使用相对判别器进一步提高了重建图像的质量。吕之彤[8]也使用同样的方法针对不同类型的医学图像进行超分辨率重建。Muqeet等人[9]构建了混合残差注意力网络使用了空洞卷积保持网络参数不增加的条件下扩大网络感受野,改进了多层次特征融合的方式。高媛等[10]设计深度可分离宽残差网络对部分医学图像进行超分辨率重建。吴磊等[11]使用了多尺度残差网络对部分医学CT图像进行了重建。Qin等人[12]提出了一种多尺度自融合残差网络,从网络广度探索图像特征提高超分辨率重建图像的质量。Liu等人[13]设计了残差蒸馏网络RFDN(Residual Feature Distillation Network)在不引入额外网络参数的条件下利用浅层残差模块对特征通道进行分离蒸馏操作,该网络轻量灵活。
本文基于生成对抗网络框架,将改进的残差结构作为生成器的基础单元,判别器网络借鉴了马尔可夫判别器[14]的思想,将输出图像映射为矩阵而非单一数值,引导生成器生成更高质量的图像。
1 模型结构
保留了SRGAN的高级体系结构设计,低分辨率图像输入生成器网络,先通过残差块提取特征再经过亚像素卷积层进行上采样操作,最后将重建的高分辨率图像输入判别器判断图像的真伪。
1.1 生成器网络
批归一化层BN(Batch Normalization)是沿着通道针对每批次的样本计算均值和方差对特征进行归一化,当输入分布改变时,之前计算的数据分布也可能改变,会导致训练网络的每一层权重不一致[15]。样本归一化层IN(Instance Normalization)是沿着通道计算每一张输入图像的均值和方差进行归一化[16]。Nah等人[17]在图像去模糊中证明了删除BN层可以提高网络性能并降低计算复杂度。相对本文所提的网络,通过实验观察到去除归一化层,网络难以训练,同时由于训练图像间差异较大,因此本文选用IN层作为归一化层,以实现稳定的训练、提高网络表达能力。
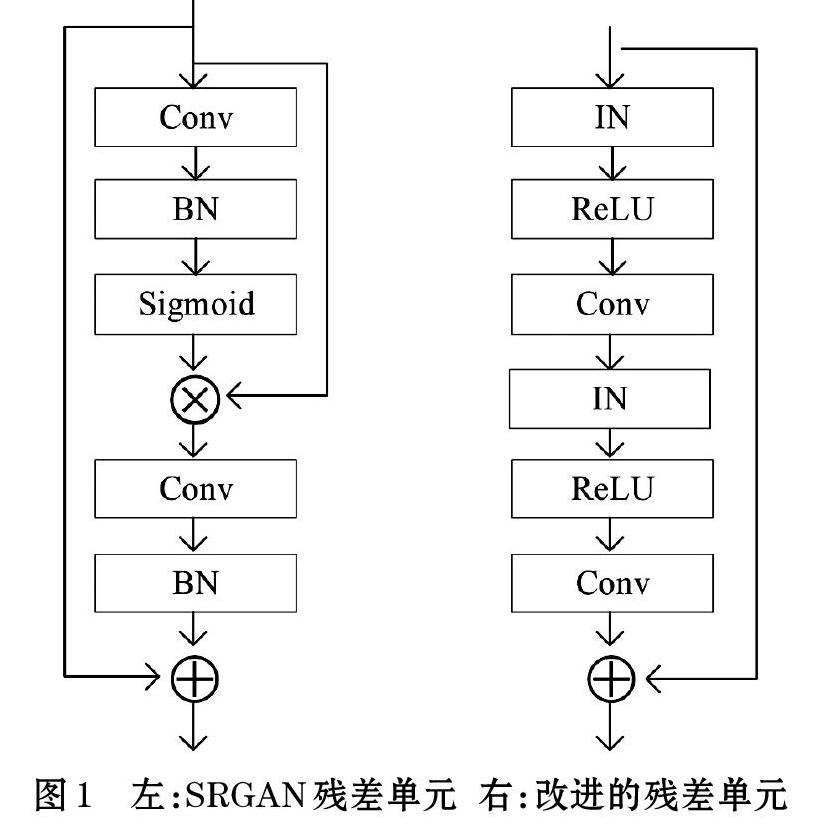
为了进一步提高SRGAN重建图像的质量,本文主要对生成器网络结构做了两个方面的改进:①使用IN层代替BN层;②改进的残差单元代替原始的残差单元,如图1所示。
改进的残差单元结构如图1所示(右图),由IN层、ReLU激活层、3?3卷积层重复组合而成。生成器残差块由16个残差单元串联而成,前面层输出的特征以级联的方式传递给后面的层,将浅层学习到的特征叠加,增强特征的传播。
使用亚像素卷积层对输入的低分辨率特征图进行上采样操作。维度为[H×W×C]的低分辨率特征图期望放大[r]倍,則先通过卷积层将特征维度调整为[H×W×r2C],再利用亚像素卷积层对特征图重排列成[rH×rW×C],最后重建输出[r]倍放大的超分辨率图像。生成器网络结构如图2所示。
图2所示,卷积层的卷积核大小都为3?3、特征通道数都为64、步长都为1。低分辨率图像先经过二个卷积层学习图像的浅层特征,然后将运算得到的特征图输入16个残差单元(Residual Block)提取图像特征,最后在网络的末端使用亚像素卷积进行四倍上采样操作重建出高分辨率图像。
1.2 判别器网络
判别器网络设计为九层的全卷积神经网络,选用卷积核大小为3?3,步幅为1、2交替的卷积层组成。网络结构如图3所示。
借鉴PatchGAN的思想,将输入为96?96的图像映射为6?6的矩阵M,M的每个元素(i,j)都对应输入图像中某个特定的图像块(patch)的判定,最后的判别结果为M的均值,通过关注重建图像的高频信息来引导局部图像特征提取,有利于促进生成器生成更加逼真的图像,提高重建质量。判别器网络的详细参数如表1所示。其中c表示卷积核,f表示滤波器,s表示步长。
1.3 损失函数
使用内容损失和对抗损失联合训练生成器网络,整体损失函数[LG]如下:
[LG=μLCont+LGen] ⑴
其中[LCont]为内容损失函数;[μ]为加权系数,经过多次实验观察到取值为400时网络性能相对最优;[LGen]为对抗损失函数。
[L1]损失(Mean Absolute Error)用于表示预测值与真实值之差的绝对值之和。[L2]损失(Mean Square Error)定义为预测值与真实值之差的平方和。已有研究表明,在使用同样优化算法的前提下,[L1]损失比[L2]损失更能脱离局部极值点所在凸域的束缚,但也存在在全局最小值附近震荡的可能;[L2]损失相比[L1]损失更容易陷入局部极值点[18]。[L1]损失对任意大小的异常值均使用固定的惩罚,受到离群点的影响较小,因此,选择[L1]损失作为内容损失函数,公式如下:
[LCont=Ex~Pdata(x)Gx-y1] ⑵
其中[E]表示数学期望,[x~Pdata(x)]表示输入数据[x]来源于低分辨率训练数据集,[y]表示数据来自原始高分辨率数据集(Ground-truth),[G(x)]表示低分辨率图像经过生成器生成的重建高分辨率图像。
一般地,生成对抗网络的对抗损失函数定义如下。
[LGen=Ey~Pdata(y)log(D(y))+Ex~Pdata(x)log(1-D(G(x)))] ⑶
其中[G]表示生成器,[D]表示判别器。
受到文献[19]的启发,使用均方误差作为对抗损失函数,网络训练更稳定。因此生成器的优化目标为最小化[Ex~Pdata(x)(DGx-1)2],判别器的优化目标为最小化[Ey~Pdata(y)Dy-12+Ex~Pdata(x)D(G(x))2]。
2 实验
在CPU为Intel core i5-8400@2.80GHZ,GPU为NVIDIA GeForce GTX1060,16GB内存的主机上进行。使用Ubuntu20.04操作系统,PyTorch1.7深度学习框架。
2.1 实验数据集
实验所用数据集来自癌症影像档案TCIA(The Cancer Imaging Archive)网站公开医学影像资料TCGA-COAD数据集。该数据集包含胃腺癌、结肠腺癌等癌症系列医学图像,部分图像的示意图如图4所示。
参考文献[10]数据处理方法,将医学影像转为PNG格式的图像用于实验,尺寸为96?96,数据集共包含有5241幅图像。将图像分为三个部分,其中训练集为4444幅,验证集为397幅,测试集为400幅。使用双三次插值算法进行4倍下采样处理获取尺寸为24?24的低分辨率图像作为生成器网络的输入数据。
2.2 参数设置
生成器网络和判别器网络都使用Adam优化器且参数设置为[β1=0.9],[β2=0.999]。批大小(batch-size)设置为8,epoch为1200。初始学习率设置为[5×10-4],并伴随训练的过程进行微调,一段时间训练后观察损失函数,当损失函数趋于平稳时,降低学习率继续训练,如此循环直至学习率降至原来的1/1000时,模型基本收敛。
2.3 客观评价标准
在PyTorch中导入skimage.metrics模块的peak_signal_noise_ratio和structural_similarity函数计算峰值信噪比PSNR和结构相似性SSIM作为重建高分辨率图像的客观评价标准。
2.4 实验结果与分析
将本文方法与Bicubic、SRGAN、RFDN算法进行了比较。图5、图6、图7分别展示了SRGAN算法、RFDN算法和本文方法在四倍放大时训练迭代次数和PSNR值的收敛曲线。
图5所示是SRGAN在验证集中的四倍放大重建训练收敛曲线,在10000epoch之后,网络基本趋于稳定,共训练20000个epoch。
图6是RFDN算法对输入低分辨率图像直接进行4倍重建时在验证集上的收敛曲线,初始学习率为[5×10-4],每迭代200epoch学习率减半,且在1000epoch之后损失函数由L1损失改为L2损失,学习率调整为[10-5]微调网络。
图7为本文算法在验证集四倍重建的训练曲线,初始学习率为[5×10-4]在 1100epoch之后学习率下降10倍,继续训练20epoch之后学习率再次下降100倍继续训练直至稳定,共训练了1200个epoch。
⑴ 客观指標测试
对本文构建的网络进行实验测试,并将测试结果与Bicubic、SRGAN、RFDN算法在四倍重建下进行比较,结果如表2所示。相比SRGAN、RFDN,本文算法的平均PSNR值大约提升了0.8359dB、2.9311dB;在SSIM值方面也分别提高了0.0163、0.0082。实验验证了本文算法的有效性。
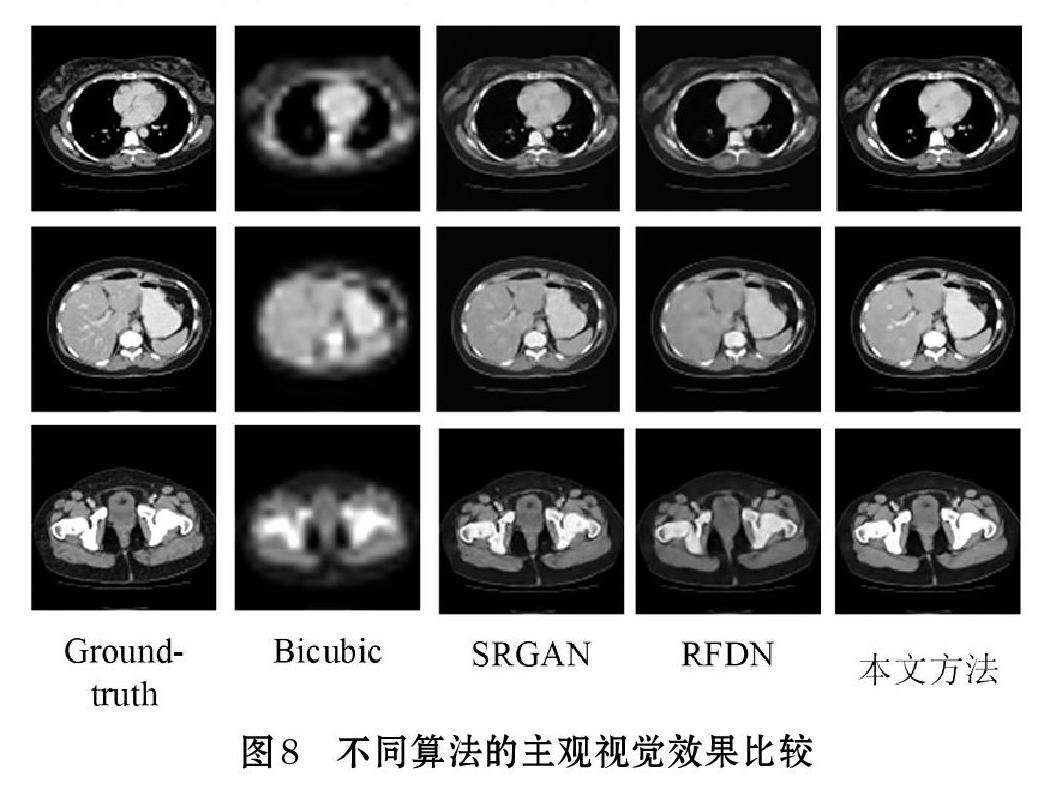
⑵ 主观视觉效果测试
将不同算法在四倍放大下的重建图像进行对比,结果如图8所示。Bicubic重建的图像比较模糊;本文方法与SRGAN、RFDN相比,主观效果更贴近真实的图像,纹理更加清晰,细节也更加丰富。
3 结束语
本文基于生成对抗网络构建了医学图像超分辨率重建的网络模型。利用改进的残差网络单元级联构建生成器,借鉴PatchGAN网络的思想设计判别器,以对抗的方式不断优化网络,重建高质量的高分辨率图像。实验结果表明,该模型重建的医学图像平均PSNR和平均SSIM比Bicubic、SRGAN、RFDN算法都有所提高。但是在速度方面,本文方法不及RFDN算法优秀。因此,未来可以在提升网络运算速度方面进行深入研究。
参考文献(References):
[1] Gao Y, Li H, Dong J, et al. A deep convolutional network for medical image super-resolution[C]//2017Chinese Automation Congress (CAC). 2017. IEEE,2017:5310-5315
[2] Haris M, Shakhnarovich G, Ukita N.Deep Back-Projection
Networks for Single Image Super-resolution[J/OL].arXiv,2020.https://arxiv.org/pdf/1904.05677v2.pdf.
[3] 段友祥,张含笑,孙歧峰等.基于拉普拉斯金字塔生成对抗网络的图像超分辨率重建算法[J/OL].计算机应用,2020.https://kns.cnki.net/kcms/detail/51.1307.TP.20201021.0852.002.html.
[4] ZIWEI L,CHENGDONG W,DONGYUE C,et al. Overview on image super resolution reconstruction [C]// CCDC 2014:Proceedings of the 26th Chinese Control and Decision Conference.Washington,DC:IEEE Computer Society,2014:2009-2014
[5] 黄陶冶,赵建伟,周正华.双层可变形卷积网络的超分辨率图像重建[J].计算机应用,2019.39(S2):68-74
[6] Ledig C, Theis L, F Huszar, et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network[J].2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2017:105-114
[7] WANG X,YU K,WU S,et al. ESRGAN:enhanced super resolution generative adversarial networks[C]//ECCV 2018:Proceedings of the 15th European Conference on Computer Vision. Berlin:Springer,2018:63-79
[8] 吕之彤. 基于深度学习的医学图像超分辨率重建[D].山东师范大学硕士学位论文,2020.
[9] Muqeet A, Iqbal M T B, Bae S. HRAN: Hybrid Residual Attention Network for Single Image Super-Resolution[J].IEEE Access,2019.7: 137020-137029
[10] 高媛,王晓晨,秦品乐等.基于深度可分离卷积和宽残差网络的医学影像超分辨率重建[J].计算机应用,2019.39(9):2731-2737
[11] 吴磊,吕国强,赵晨等.基于多尺度残差网络的CT图像超分辨率重建[J].液晶与显示,2019.34(10):1006-1012
[12] Qin J, Huang Y, Wen W. Multi-scale feature fusion residual network for single image super-resolution[J].Neurocomputing,2020.379:334-342
[13] Liu J, Tang J, Wu G. Residual Feature Distillation Network for Lightweight Image Super-Resolution[C]. ECCV, 2020, https://arxiv.org/pdf/2009.11551.pdf.
[14] LAN Z,LIN M,LI X,et al. Beyond Gaussian pyramid:Multi- skip feature stacking for action recognition[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Washington,2015:204-212
[15] Ioffe S, Szegedy C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift[J].arXiv,2015.https://arxiv.org/pdf/1502.03167.pdf.
[16] D Ulyanov, Vedaldi A, Lempitsky V. Instance Normaliza-tion: The Missing Ingredient for Fast Stylization[J/OL]. arXiv, 2017.https://arxiv.org/pdf/1607.08022v3.pdf.
[17] NAH S, KIM T H, LEE K M. Deep multi-scaleconvolutional neural network for dynamic scene deblurring[C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,2017:257-265
[18] 黃荔.基于深度学习的3D磁共振图像超分辨率重建算法研究[D].电子科技大学硕士学位论文,2020.
[19] Zhu J Y, Park T, Isola P, et al. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks[C] //Proceedings of the IEEE International Conference on Computer Vision,2017:1125-1134
