基于双迁移度量学习和注意力机制的跨域推荐
2021-10-21普洪飞邵剑飞
普洪飞,邵剑飞
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
随着互联网技术的发展,人们对于网络资源的依赖和需求不断增长,如何为用户推荐其感兴趣的项目,成为重要的研究课题,因此推荐系统被提出并应用[1]。从传统的内容推荐系统和协同过滤域到现在的深度学习推荐系统,尽管其简单有效[2],却存在评分数据稀疏和用户冷启动问题[3]。为了解决推荐系统中的冷启动和稀疏性问题,研究人员提出了跨领域推荐系统[4]。
跨领域推荐的目标是利用其他领域的用户偏好信息和项目特征等各种辅助信息,来提高目标领域的推荐性能,有效缓解目标领域的数据稀疏性和冷启动。例如,喜欢武侠书籍的人,也会比较喜爱武侠片,因此即使在不同的领域也可能有相同 的爱好。
但是,大多数现有方法只关注提高目标域推荐的性能,即利用来自源域的信息来改进目标域的推荐性能。这种方法忽略了源域的信息可以提高目标域、同时目标域也可以提高源域的推荐性能。例如,一旦知道用户想要阅读的书籍类型,就可以推荐相关主题的电影,形成一个循环,以便在两个域中同时提高推荐性能。
以前的研究显示,双迁移学习模型[5]能够高效地提高源域和目标域的推荐性能。基于此,研究人员提出将双迁移学习机制应用于跨域推荐,通过提取每个域中的偏好信息并双向传输不同域之间的用户偏好,来同时提高不同域的推荐性能。
现有的跨域推荐模型通常需要不同域的大量重叠用户作为“枢轴”,以便学习用户偏好的关系,并产生令人满意的推荐性能[6]。这些重叠用户在两个域类别中消耗了商品,如观看电影和读书。然而,收集足够多的重叠用户,在许多应用中实现起来比较困难。例如,可能只有有限数量的用户在亚马逊上购买了书籍和数字音乐。因此,重要的是要克服这个问题,并最大限度地减少跨域推荐中两个域所需的重叠用户数量。
为了解决这个问题,可以采用基于重叠用户构建跨域推荐系统的解决方案。假设两个用户在某个域中具有相似的偏好,那么这两个用户的偏好在其他域中也是相似的。潘等人提出了将度量学习和双学习集合起来,通过度量学习减少两个域的重叠用户,同时提高源域和目标域的推荐性能,潘等人[7]将这种方法命名为双迁移度量学习模型(Dual Metric Learning,DML)。
但是双迁移度量学习模型(DML)是以普通的多层感知机(MLP)为基础推荐系统,不能更好地提取用户和项目之间的非线性交互特征。注意力机制是一种人脑模拟模型,能够通过计算概率分布来突出输入的关键信息对模型输出结果的影响,从而优化模型。注意力机制能够充分地利用句子的全局和局部特征,给重要的特征赋予更高的权重,从而提高特征抽取的准确性。因此,本文提出基于双度量学习(DML)和注意力机制的跨域推荐系统,命名为DML-A模型。实验证明,此方法可以同时提高源域和目标域的推荐性能,而且模型准确性更高。
1 模型介绍
1.1 度量学习
由于用户偏好在不同域中的差异性,每个域中的用户嵌入的分布也应该是不同的。做一个假设:如果两个用户对某个域具有相似的兴趣,那么这两个用户也会对其他域具有相似的兴趣。本文的目标是解决这个假设,利用这些重叠用户作为“枢轴”,以学习不同域中的用户偏好与行为的关系。
DML模型利用双迁移学习机制同时提升两个域的推荐性能。源域的用户向量经过度量学习后,作为目标域推荐系统的输入。相同地,使用目标域中经过度量学习输出,作为源域的输入。通过这种方式,可以迭代提高两个域的推荐性能。通过迭代地重复学习过程,每次都会获得更好的度量映射和推荐系统,直到学习过程满足收敛标准。因此,度量学习[8]可以更好地捕获用户偏好,从而提供更好的推荐性能。
将A域和B域的用户向量表示为WUA、WUB,将两个域的重叠用户表示为ouA=ouB,重叠用户向量表示为WouA、WouB。模型的目标是在相同的重叠用户下,找到最佳映射矩阵X,来最小化映射矩阵乘A域用户重叠向量XWouA和B域目标用户重叠向量之间的距离:
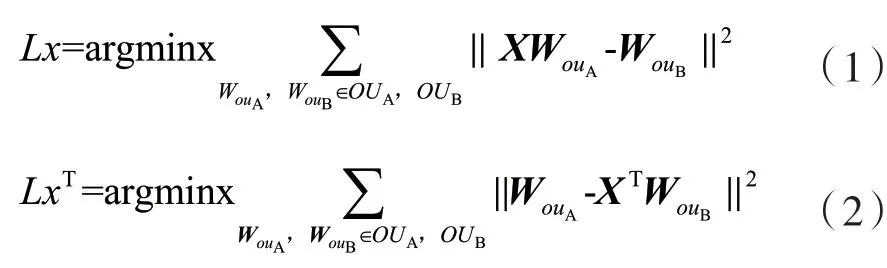
将映射矩阵X限制为正交映射(即XTX=I),其用于强制保持每个域用户偏好的结构不变性。优化式(1)和式(2)以学习正交度量映射矩阵X。
1.2 双迁移学习
迁移学习[9]将已训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务存在相关性,因此通过迁移学习可以将已经学到的模型参数通过某种方式来分享给新模型,从而加快并优化模型的学习效率。用于跨域推荐的现有迁移学习方法包括协作DualplSA[10]、联合子空间非负矩阵分解JDA[11]。
此外,为了同时提升两个学习任务的性能,研究人员提出了双迁移学习机制[12],同时学习边缘和条件分布。最近,研究人员通过双迁移学习机制实现了对机器翻译的良好表现[13],这证明双迁移学习在研究中具有重要的研究意义。
本文利用前阶段中学到的度量映射矩阵X来模拟跨域用户偏好,对源域和目标域(A域,B域)进行用户评级,如下所示:

式中:WUA、WUB、WiA、WiB分别表示为A域和B域的用户特征向量和项目特征向量,RSA、RSB分别表示为A域和B域的推荐系统,rA*和rB*分别表示为A域和B域的评分输出。双迁移学习需要跨两个域进行传输循环,并且学习过程通过循环迭代。
1.3 DML-A模型
在度量学习中所做的潜在假设是:如果两个用户对一个域具有相似的兴趣,那么这两个用户对其他域也会具有相似的兴趣。本文的目标就是验证这个假设,所以本文需要在相同的用户重叠中找到最佳映射矩阵X,用X来模拟重叠用户的跨域偏好,其中度量映射X是通过式(1)和式(2)不停地迭代直到收敛而来。
整个DML-A模型分为三个部分,如图1所示,分别为推荐系统A、推荐系统B、潜在正交度量 矩阵。
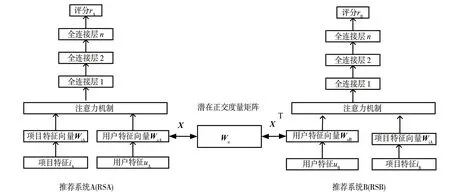
图1 DML-A模型

(14)更新参数RSA和RSB
(15)End for
(16)直到收敛结束
整个算法分为三个部分,首先输入项目和用户特征,然后转换成用户和项目特征向量,让它们经过推荐系统(RSA和RSB),得到预测评分,然后通过反向传播预测评分和真实评分之间的损失值,然后更新RSA和RSB的参数,一直不停地循环来更新模型参数,直到收敛为止。输入A域和B域的重叠用户向量和映射矩阵X,通过后向传播映射X和用户重叠向量XWouA和WouB之间的损失值,然后更新映射矩阵X,一直循环更新映射矩阵X,直到收敛为止。第三部分最为重要,在第二部分得到了映射矩阵X来模拟重叠用户的跨域偏好,如公式所示将XWuA,WiA作为RSA的输入,XTWuB,WiB作为RSB的输入,输出预测评分r*A和r*B,后向传播预测评分和真实传播的损失值,更新参数,一直循环到收敛。
2 实验介绍
2.1 实验数据
本文采取了Amazon数据集进行评估,该数据集主要包含用户对网站商品的评价信息及商品元数据,由从亚马逊平台收集的用户购买行为和评级信息组成。本文选择具有足够多重叠用户的两个域来进行实验,分别选择名为Movie and TV的数据集和Book数据集,作为源域和目标域数据。简单描述这两个数据集如下:每行数据由用户id、项目id及用户对项目的评分组成,由多行数据构成一个数 据集。
2.2 评价指标
均方根误差RMSE(Root Mean Squared Error,RMSE)通过计算预测评分与真实评分之间的误差来衡量推荐结果的准确性。RMSE为:
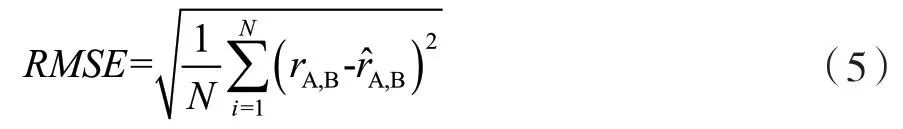
式中:N表示测试数据的数量,rA,B表示为真实的评分,r^A,B表示经过DML-A模型的评分预测值。RMSE的值越小,表示推荐准确性越高。
2.3 数据集和实验结果分析
将目标域数据随机分为训练集和测试集,其中80%的数据用于训练,20%用于测试。实验采用Pytorch作为实验框架,实验配置为:Intel Core i5-10200H处理器、8 GB内存、NVIDIA GTX 1050 TI显卡。学习率设置为0.01,Dropout设置为0.5,批次设置为1 024,训练批次为32,优化函数为Adam,特征嵌入维度为16,全连接层设置为8。
为了验证模型的推荐准确度,对本文所提出的DML-A模型和没有添加注意力机制的DML模型进行对比,分别在两个实验数据Movie and TV的数据集和Book数据集进行实验。实验结果如图2和图3所示。
如图2和图3所示,采用的训练批次为32批次。在Book数据集中,DML模型和改进的DML-A模型在前10个批次,RMSE的值不断下降,在10批次之后趋向于平衡。在Book数据集中可以清晰地看到,经过本文改进的注意力机制DML-A模型的RMSE值一直都比DML模型小,证明本文的模型推荐性能更优。在Movie数据集中,在15个批次之前,DML和DML-A模型RMSE的值不断下降,在15批次之后趋向于平衡。可以清晰地看到,经过本文改进的注意力机制DML-A模型的RMSE值一直都比DML模型小,同样证明本文的模型推荐性能更优。综上所述,改进后的DML-A模型可以同时提高Movie域和Book域的推荐性能。
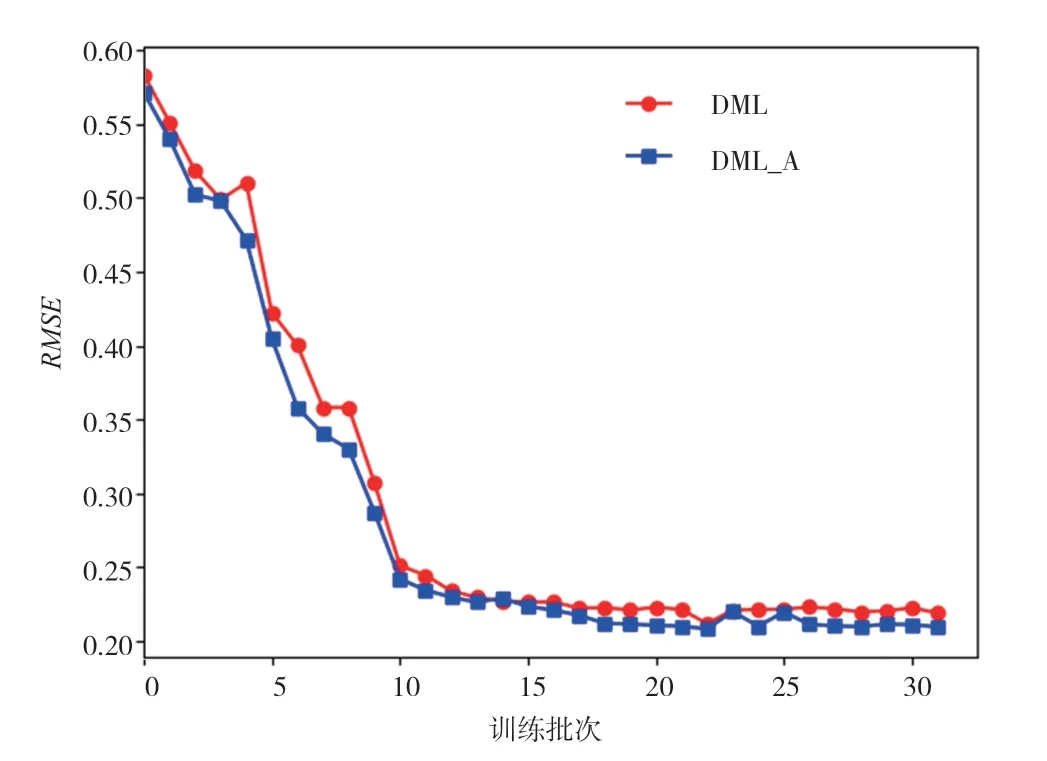
图2 Book数据集的RMSE值
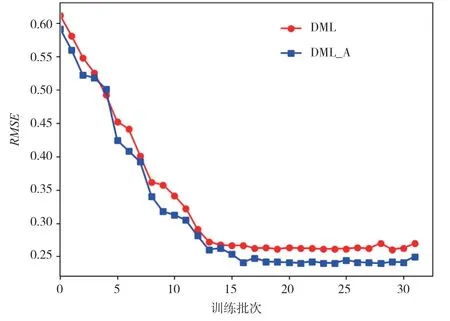
图3 Movie数据集的RMSE值
3 结 语
本文提出了一种基于注意力机制和双度量学习的跨领域推荐模型DML-A,将注意力机制应用和双迁移度量学习结合,通过减少源域和目标域之间的重叠用户,利用源域和目标域的信息来实现双方性能的提升。在未来的研究中将会对注意力机制进行改进,同时将增加数据集和评价指标来丰 富实验。
