深度强化学习及在路径规划中的研究进展
2021-10-14张荣霞武长旭孙同超赵增顺
张荣霞,武长旭,孙同超,赵增顺
山东科技大学 电子信息工程学院,山东 青岛 266590
随着机器人技术以及电子信息技术的发展,移动机器人的应用越来越智能化,智能移动机器人的一个重要特征是在复杂动态环境下可以进行良好的路径规划[1]。智能机器人路径规划是指在搜索区域内给出合理的目标函数,并在一定范围内找到目标函数的最优解,使机器人找到一条从起点到目标点的安全无障碍路径[2]。路径规划在许多领域有着广泛的应用,如机器人机械手臂的路径规划[3]、无人机的路径规划[4]等。
传统的路径规划方法,如人工势场法[5]、A*算法[6-7]、蚁群算法[8-9]、遗传算法[10]等,在复杂环境中无法处理复杂高维环境信息,或者容易陷入局部最优。
路径规划方法根据训练方法的不同,可分为监督学习、无监督学习和强化学习[11]、监督学习和无监督学习在进行路径规划时都需要大量的先验知识,否则无法进行良好的路径规划。强化学习(Reinforcement Learning,RL)是一种不需先验知识并且与环境直接进行试错迭代获取反馈信息来优化策略的人工智能算法,并且能够自主学习和在线学习,逐渐成为机器人在未知环境下路径规划的研究热点[12-13]。传统的强化学习方法受到动作空间和样本空间维数的限制,难以适应更接近实际情况的复杂问题情况,而深度学习(Deep Learning,DL)具有较强的感知能力,能够更加适应复杂的问题,但是缺乏一定的决策能力。因此,谷歌大脑将DL 和RL 结合起来,得到深度强化学习(Deep Reinforcement Learning,DRL),取长补短,为移动机器人复杂环境中的运动规划问题提供了新的思路和方向。
深度强化学习具有深度学习强大的感知能力和强化学习智能的决策能力,在面对复杂环境和任务时表现突出,这有助于机器人的自主学习和避障规划。2013年,Google DeepMind 提出深度Q 网络[14](Deep Q-learning Network,DQN),是深度强化学习发展过程中的里程碑,它突破了传统RL方法中基于浅层结构的价值函数逼近和策略搜索的学习机制[15],通过多层深度卷积神经网络,实现了从高维输入空间到Q值空间的端到端映射,以模拟人脑的活动。由于Agent 需要不断与周围环境进行交互,所以深度Q网络(DQN)不可避免地面临着学习大量网络参数的需求,导致学习效率低下。针对这些问题,研究人员对DQN 算法从训练算法、神经网络结构、学习机制、基于AC 框架的DRL 算法等方面进行深入研究并提出了许多改进策略。
本文主要通过研究DQN及其改进算法在移动机器人路径规划中的研究进展,来阐述DRL 算法在路径规划中的演化过程。首先介绍DQN算法的工作原理及不足,然后根据DQN 算法的原理,从训练算法、神经网络结构、学习机制、AC框架多种变形这四类进行深入研究并归纳整理当前的改进策略,介绍移动机器人进行路径规划的其他强化学习算法,旨在为DRL算法在移动机器人路径规划的进一步研究提供依据,最后对DRL 算法在移动机器人路径规划的未来研究与发展进行了展望。
1 DQN算法的工作原理及不足分析
1.1 DQN算法的工作原理
传统的Q-learning 算法在进行路径规划时用Q 表存储数据,但当路径规划的环境过于复杂和数据过多时,Q 表不仅难以存储而且难以搜索,容易出现维数爆炸,为解决这个问题,可以利用函数逼近来代替Q值表对值函数进行计算,但容易出现算法的不稳定。DQN算法结合了深度神经网络和传统强化学习算法Q-learning的优点[16],一定程度上解决了用非线性函数逼近器近似表示值函数时算法的不稳定性问题。DQN算法利用深度神经网络作为函数逼近来代替Q值表,并对值函数进行计算,以神经网络作为状态-动作值函数的载体,用参数为ω的f网络近似代替值函数,公式为:

f(s,a,ω)为函数的近似替代,用神经网络的输出代替Q值,具体如图1[11]所示。s为输入状态,F(s,ai,ω)(i=1,2,3,4)表示状态s下动作ai的Q值。DQN 在与环境互相迭代过程中,状态st与状态st+1具有高度相关性,导致神经网络过拟合而无法收敛。为打破数据相关性,提升神经网络更新效率和算法收敛效果,DQN 算法采用经验库[17](Experience Replay Buffer)将环境探索得到的数据以记忆单元的形式储存起来,然后利用随机样本采样的方法更新和训练神经网络参数。另外DQN算法还引入双网络结构,即同时使用Q估计网络和Q目标网络来进行模型训练,不是直接使用预更新的当前Q 网络,以此来减少目标值与当前值的相关性。估计网络和目标网络的结构完全相同,但是网络参数不同。其中Q网络的输出为Q(s,a,θ),用来估计当前状态动作的值函数;目标网络的输出表示为Q(s,a,θ′)。

图1 DQN代替模型Fig.1 DQN instead model
DQN 网络更新是利用TD 误差进行参数更新。公式如式(2)所示:

DQN 算法流程如图2所示[18],将环境状态s传入到当前值网络,以ε概率随机选择一个动作at,执行动作a得到新的状态st+1和奖励值r,并将(st,at,rt,st+1)存储到经验池D中,然后从经验池D中选取随机采集样本进行训练,最后根据TD损失函数进行target网络参数更新,更新参数的方法为随机梯度下降,每隔N次迭代拷贝参数到目标值网络进行参数更新并训练。

图2 DQN更新流程Fig.2 DQN update process
基于DQN算法的路径规划流程如下所示:
算法1DQN路径规划算法
1.初始化经验池D,初始化Q-target 网络参数和当前网络参数容量为N,初始化折扣因子γ
2.forepisode=1,2,…,d0
3.初始化环境状态,将移动机器人获取的环境特征信息(s,a,r,s′)保存于记忆矩阵D中,并计算网络输出
4.根据概率ε机器人选择一个随机的动作或者根据当前的状态输入到目前的网络中,计算出每个动作的Q值,选择Q值的最优动作
5.得到机器人执行动作at后的奖励rt和下一个网络的输入
6.将得到的数据作为机器人的状态一起存入到记忆矩阵D中(记忆矩阵还保存着前N个时刻的状态),设置合理的奖励函数
7.随机从记忆矩阵D中取出一批样本
8.将按照公式(2)更新过后的Q值作为目标值,计算每一个状态的目标值
9.通过随机快速下降法更新权重,利用TD更新网络参数
10.每C次迭代后更新目标网络θ-=θ
11.end for
12.end for
近年来,将DRL算法应用于移动机器人路径规划的方面的工作已经做了很多,DQN 算法的提出对移动机器人路径规划的发展起着重要作用,2016年,文献[19]最先利用DQN 算法实现了虚拟环境中的机器人路径规划;文献[20]提出一种改进深度强化学习算法(NDQN),加入了差值增长概念,利用改正函数对DQN 算法进行改进并运用到机器人三维路径规划中。图3 为使用基于DRL算法的移动机器人路径规划方法的总体框架[21],该框架由智能体和环境组成,后续很多方法都是从该框架的基础上进行改进,更多详细介绍请见第3章。DQN算法实现了DL 和RL 的结合,对DRL 的发展有重要意义。但DQN 算法在实际应用中存在不足,无法处理连续动作控制任务。
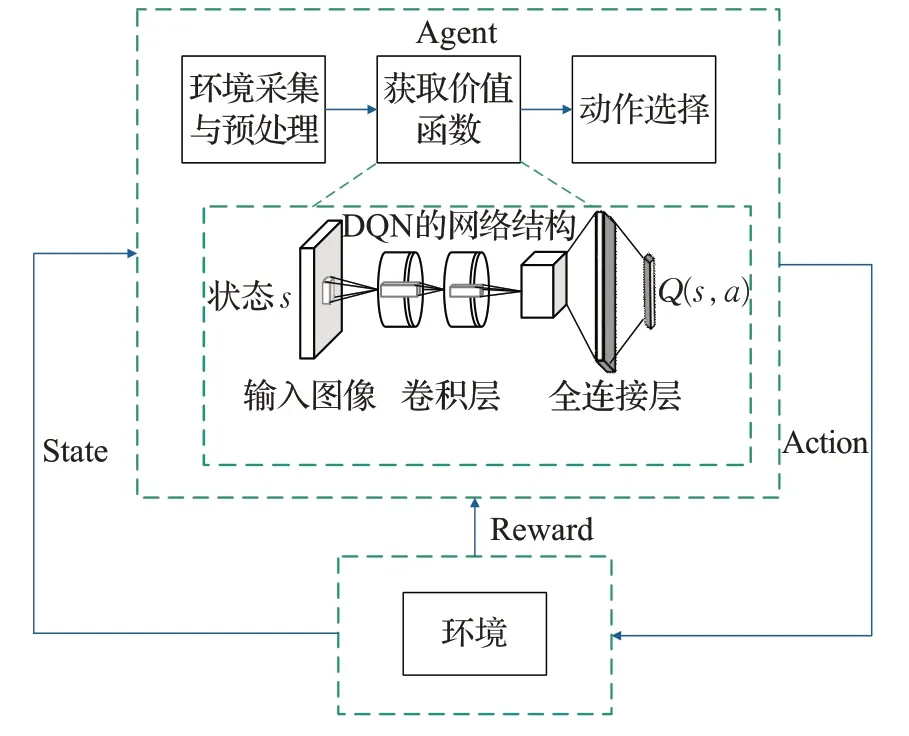
图3 基于DRL的机器人路径规划框架Fig.3 Robot path planning framework based on DRL
1.2 DQN算法的不足分析
DQN 算法在路径规划等领域得到了广泛的应用,但是仍然存在许多问题,比如过估计问题、容易陷入局部最优、学习效率低、不能满足高维动作的输入、算法稳定性差、探索过程中目标丢失、数据探索效率低下等问题,另外DQN算法只能处理短期记忆问题,无法处理长期记忆的问题。分析存在以上问题的原因如下:
(1)过估计问题
机器人运用DQN 算法进行路径规划时,神经网络以状态-动作对作为输入,以Q函数值为输出,实现环境端对端的控制,每一次网络更新时机器人都会对目标Q 网络采取最大化操作,这样容易高估动作值,导致算法将次优行为价值认定为最优行为价值[22],移动机器人容易陷入局部最优。
(2)学习效率低
机器人进行路径规划的时候需要不停地与环境进行交互,这就导致DQN 算法会面临学习大量参数的局面,导致机器人学习效率低下。另外DQN 算法在与环境互相迭代过程中,所采集的运动样本具有较大的关联性,导致神经网络过拟合而无法收敛,降低了神经网络更新效率,影响了算法收敛效果。传统DQN 算法只使用单个机器人进行训练,在进行路径规划时,机器人的数量也会影响机器人的学习效率。
(3)算法稳定性差
DQN算法一般都是使用传统卷积网络处理原始输入,比如机器人上安装的传感器获得的外部环境图像,将处理后的数据分流到两个全连接网络中,分别为动作值和目标值,数值之间具有相关性,导致算法稳定性差,所以必须打破数据相关性,提高算法稳定性。另外,用神经网络的非线性函数逼近器来表示Q值函数容易产生误差。
(4)数据探索效率低下
在路径规划问题中,机器人为了获得最短路径,在运用DQN 算法进行路径规划时,只为获得最大的奖励值,忽略探索过程,陷入死循环,导致机器人探索环境效率低下。所以在机器人在运用DQN算法进行路径规划时,需要设置合理的奖惩函数,提高机器人的性能。
(5)长短期记忆
运用DQN 算法进行路径规划时,需要不断更新经验池,将当前的记忆数据存储到经验池中,将卷积神经网络当前得到的Q函数与之前的数据进行比较;随后将两者的误差通过梯度下降法反向传播回卷积神经网络中,从而实现Q-Network的训练与更新,但是卷积神经网络只能存储短期记忆,这就导致神经网络的更新具有延迟性,降低了机器人路径规划算法的性能。将只能实现短期记忆的卷积神经网络更换成具有长期记忆的神经网络是十分必要的,比如LSTM(Long Short-Term Memory)。
2 DQN算法的改进研究
针对上述问题,Hasselt等人[23]、Wang等人[24]、Foerster等人[25]对DQN 算法进行深入研究,改进算法主要从训练方法、神经网络结构、学习机制、基于AC 框架的RL算法等方面提高算法的优化能力,为后续移动机器人路径规划算法提供理论基础。
2.1 改进训练方法
(1)分布式深度Q网络
在训练过程中,传统DQN 算法只使用单个机器进行训练,这就会导致较长的训练时间,学习效率低。针对此类问题,Nair 等人[26]提出了分布式深度Q 网络算法,可以多个机器同时进行训练,用分布式重放存储器和分布式神经网络并行工作和学习,与单个机器训练相比,有效地提供了增大容量的分布式经验回放内存,不仅可以生成更多的训练数据,分布式参与者还可以更加有效地探索空间,因为每个这样的参与者都可以存储其自己的过去经验记录,根据一定差异性策略进行操作,使机器人的训练时间大大减少,提高了学习效率。分布式深度Q网络算法主要由四部分组成,分别为并行参与者、平行学习者、参数服务器、经验回放存储机制,算法框架图如图4所示[26]。
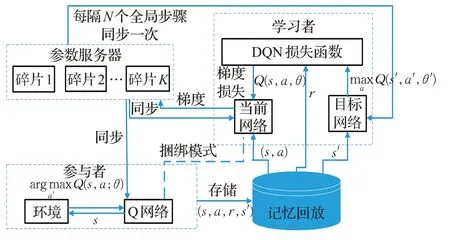
图4 分布式DQN算法框架Fig.4 Distributed DQN algorithm framework
参与者用于产生新行为;从储存的经验中训练出平行学习者;参数服务器用以表示价值函数或者行为策略的分布式神经网络;经验回放存储制用以储存分布式经验存储。分布式DQN算法能够利用大量的计算资源来扩大DQN 算法的规模,但是也对计算机本身的计算能力和内存有了更高的要求。
(2)平均DQN算法
DQN算法的不稳定性和可变性可能会对机器人路径规划的效率产生影响,针对这个问题,Anschel等人[27]提出平均DQN(Averaged-DQN,ADQN)算法。ADQN算法是传统DQN算法新的扩展,ADQN算法与DQN算法的主要差异是目标值的不同选择,ADQN算法通过使用之前学习的Q值进行平均估计,产生当前的行动价值估计来减少目标近似误差的方差,可以使得学习进度更加稳定,价值估计也更加保守,实现更稳定的训练过程。ADQN算法能够对学习曲线产生方差减少效应,该算法解决了由Q学习和函数逼近相结合而产生的问题,表明了平均DQN 算法在理论上比DQN 算法在降低方差方面更有效。文献[28]表明ADQN 算法在玩具问题和街机学习环境中的几个Atari 2600游戏中表现良好,但同时也使得训练时间变长,资源消耗增加。
2.2 改进神经网络结构
DQN 算法是通过神经网络来估计Q 函数,网络结构决定了网络的学习效率和表达能力[29],神经网络结构的选择对DQN算法的性能的高低非常重要。
(1)Double DQN算法
DQN算法每一次更新时都会对目标Q网络采取最大化操作,这样会导致Q值受到了严重的高估,即网络输出的Q值高于真实的Q值。为有效解决过估计问题,Hasselt等人[23]提出深度双Q网络(Double DQN,DDQN)算法,对DQN 的优化目标进行优化改进。DDQN 算法将目标中的最大运算分解为动作选择和动作评估来减少高估问题,通过随机分配每个经验来更新两个值函数中的一个来学习两个值函数,这样就有了两组权重,对于每次更新,一组权重用于确定贪婪策略,另一组用于确定其值,有效解决了DQN算法中存在的过估计问题,使得智能体能够选择相对较优的动作。实验表明DDQN算法在价值准确性和策略质量方面都优于DQN,不仅产生更准确的价值估计,而且产生更好的策略,使机器人的学习更加稳定。
但DDQN算法在选择相对较优的动作时,是利用当前估计网络参数,而不是已经更新的先验知识库,所以解决价值高估问题的同时,也会带来价值低估问题。董永峰等人[30]提出动态目标双深Q网络(DTDDQN)算法,将DDQN算法与平均DQN算法相结合,取长补短,对网络参数进行培训,使网络输出的Q值更接近实际Q值,解决了路径规划中的估计值误差大的问题。
(2)基于决斗架构的DQN算法
决斗网络是一种新的无模型强化学习神经网络结构,Wang等人[24]提出基于决斗架构的DQN(Dueling DQN)算法,从神经网络结构方面对DQN 算法进行改进。基于决斗网络的DQN算法采用卷积神经网络处理原始输入,将处理过的原始输入分流到两个全连接网络中,分别为状态值和优势函数。这种分流的优点是在动作之间推广学习,而不对底层的强化学习算法进行任何改变,结构如图5所示[24]。
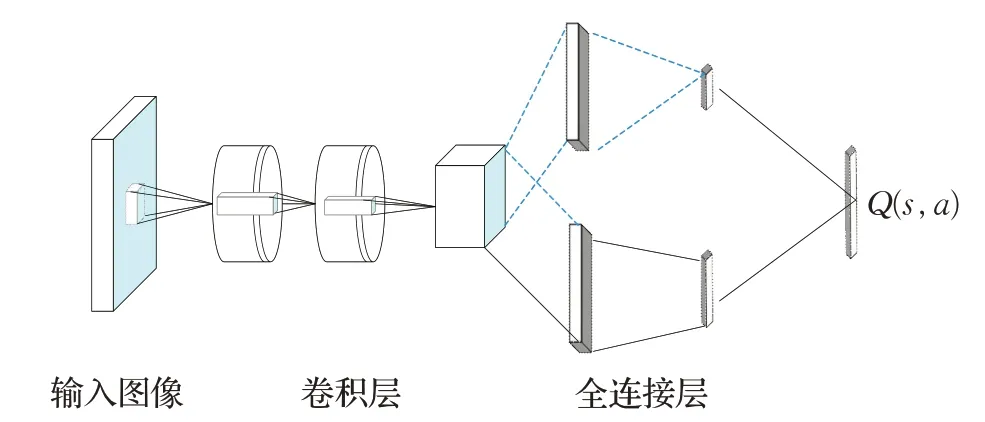
图5 决斗架构的DQN网络结构Fig.5 Dueling DQN network structure
基于决斗架构的DQN算法的优势部分在于它能够有效地学习状态值函数。当决斗架构中的Q值每次更新时,价值流也会更新,这与传统DQN算法结构中的更新方式形成鲜明对比,在DQN结构中,只更新一个动作的值,所有其他动作的值保持不变。在基于决斗架构的DQN 算法中,更频繁的价值流更新将更多的资源分配给价值函数,从而允许更好地逼近状态值,这对于基于时间差异的方法来说是非常必要的和准确的[31]。实验表明,当动作数较大时,决斗结构比单流Q 网络的优势更大,可以获得更高的平均奖励,以及更快的早期训练速度,提高算法的稳定性。
基于决斗架构的DQN算法通过两个决斗数据流来估计Q值,但是它只专注于Q函数内的决斗,影响了算法的性能,而且决斗网络只适用于那些基于Q值的算法,使得算法有局限性。为了解决这些问题,Qiu等人[32]提出用一个创新的状态表示决斗网络来提高强化学习算法的性能,将状态表示决斗网络与决斗DQN相结合,形成了一种新的算法——SR 决斗DQN(State Representation Dueling DQN)算法,结果表明,与决斗DQN相比,SR决斗DQN算法更有利于解决高维环境下的任务,提高了决斗DQN 算法在CartPole 环境下的训练速度和性能。
(3)深度循环Q网络算法
长短期记忆网络(LSTM)是循环神经网络的升级版,具有长期记忆的特点,最早由Hochreiter 等人[33]在1997 年提出。传统的DQN 算法进行路径规划时,机器人在与环境进行交互传递信息的过程中,神经网络只能传递当前的信息,而忽视了后面的影响,而且数据之间是有联系的。为了解决这个问题,Hausknecht 等人[34]提出了一种基于LSTM 的DQN 算法,深度循环Q 网络算法(Deep Recurrent Q-Network,DRQN),将递归LSTM替换第一个后卷积全连接层来增加深度Q 网络(DQN)的递归性的效果,并对DQN滤波进行改进,降低对较远信息的权重,增加关系强的信息权重。在Atari2600 游戏平台验证了其性能,在相同的历史长度下,LSTM 是在DQN的输入层中储存历史记忆的一种可行的替代方案,可以更好地适应评估时间。
单层LSTM记忆历史信息能力有限,在一些连续性不强的环境中进行路径规划时,机器人不能取得满意的结果。2017年,翟建伟[35]在DRQN算法的基础上加入自注意力机制,提出一种具有视觉注意机制的深层循环Q网络(Deep Recurrent Q-Network with Visual Attention Mechanism,VAM-DRQN),能够聚焦图像中的关键信息,使得机器人获得的环境图像更加清楚。2019年,刘全等人[36]提出一种带探索噪音的深度循环Q 网络模型(EN-DRQN),引入改进的简单循环单元,解决了单层LSTM记忆力能力有限的问题,既保留了状态序列之间的相关性,又可以在序列之间有效的探索出新状态,同时在历史信息的指引下做出有效决策,进一步加快了网络的运算。实验证明EN-DRQN 加快了机器人的训练速度,减少了训练时间。
2.3 改进学习机制
(1)基于优先经验回放的DQN算法
机器人连续运动时所采集的样本本身之间存在较强的相关性,将导致机器人价值网络更新梯度消失,机器人无法继续学习,容易陷入局部最优,使得算法稳定性差。为打破数据相关性,提高算法稳定性,Schaul等人[37]提出了基于优先经验回放的DQN(Prioritized Replay DQN)算法,使用基于优先级的经验回放机制替代等概率的抽样方式,解决了经验回放中的采样问题。该算法使机器人能够在更多数量级的数据中有效地学习,并且将行动与学习结合。行动者根据共享的神经网络选择行动,与之前的环境实例进行交互,并在共享的经验重放存储器中积累所得经验,学习者回放经验样本并更新神经网络[38],提高有价值样本的利用率。但经验回放就意味着每个真实交互中的环境信息将使用更多的内存和计算,机器人需要很多探索行为才能得到积极的反馈,这就使得基于优先经验回放的DQN算法进行路径规划时需要耗费大量的时间和资源,导致算法很难收敛。
(2)示范DQN算法
DQN 算法进行路径规划时需要大量的训练数据,严重地限制了深度学习在许多真实世界任务的适用性,学习过程中的表现非常差。Hester 等人[39]提出示范DQN(Deep Q-learning from Demonstrations,DQFD)算法,该算法利用少量演示数据,可以访问来自系统先前控制的数据,即使是从相对少量的演示数据中,也能大大加快学习过程。DQFD 算法利用少量的演示数据对机器人进行预培训,使其能够从学习开始就很好地完成任务,然后从自己生成的数据中继续改进,而且优先重放机制能够在学习时自动评估演示数据的必要比例,将时间差异更新与演示者行为的监督分类相结合来工作,减少了和环境交互次数,提高了学习效率。DQFD算法使逆向学习应用于许多现实问题成为可能,但不能对示范者的行为进行准确的分类,示范和代理数据之间存在差异,无法应用于连续动作域。
(3)策略与网络深度Q学习算法
DQN算法能通过模仿人类学习技能的过程从经验中学习,当机器人学习过去的经验时,全面多样的经验有助于提高算法的性能。基于不同学习阶段对经验深度和广度的不同需求,LV 等人[40]提出了一种快速学习策略,策略与网络深度Q学习算法(Policy and Network Deep Q-Network,PN-DQN),该算法计算Q值采用密集网络架构,在学习的初始阶段创建经验值评估网络,增加深度经验的比例,从而更快地理解环境,改变了技能学习过程中经验的概率分布,使得模型可以在学习的不同阶段获得更多所需的经验,从而提高学习效率。在路径规划应用中,只需要输入地图图像,不需要对地图进行建模,旨在提高路径规划的速度和精度。仿真实验表明,PN-DQN 算法在学习速度、路径规划成功率和路径精度方面都优于传统的DQN 算法,但该算法只适用于离散状态空间,对于连续动作控制的效果并不好。
2.4 基于Actor-Critic框架的DRL算法
基于强化学习的运动规划是一种基于数据的非监督式机器学习方法,将感知、规划集成于一体,通过策略学习实现端到端的运动规划[41],基于强化学习的DQN算法对移动机器人路径规划的发展具有深远意义。除了从训练方法、神经网络结构、学习机制等方面研究DQN算法,通过其他角度对DQN算法的研究也取得了一些进展。
根据机器人路径规划是否存在价值函数的指导,分为基于值函数算法和策略梯度算法两种运动规划算法[42]。以价值函数为基础的强化学习方法常被应用于机器人离散动作空间的运动规划,但对连续动作的处理能力不足,无法解决随机策略问题;基于策略的强化学习算法直接通过给定的策略评价函数在策略空间内搜索得到最优控制策略[43],能够处理连续动作问题,但学习效率较低,缺乏随机探索能力。将值函数算法和策略梯度算法结合得到新的一种结构:行动者-评论家(Actor-Critic,AC),融合了值函数算法和策略梯度算法的优点,在进行训练时,Actor和Critic的交替更新参数,优化了算法的性能。
(1)DDPG
无模型、脱离策略的行动者-评论家算法,使用深度函数逼近器,可以在高维、连续的行动空间中学习策略,Lillicrap 等人[44]将行动者-评论家方法与DQN 算法相结合,得到一种无模型的深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG),用来自重放缓冲器的样本对网络进行离线训练,以最小化样本之间的相关性,同时通过双网络结构和优先经验回放机制,解决了Actor-Critic难收敛的问题,提高了算法的效率。但DDPG进行路径规划时存在训练时间过长、训练数据需求大、训练初期的学习策略不稳定等问题,而且由于环境的复杂性和随机性,DDPG往往受到低效的探索和不稳定的训练的影响。
众多研究者对DDPG 算法进行了改进,Hou 等人[45]提出基于知识驱动的DDPG算法,在策略搜索阶段应用混合探索策略来驱动有效的探索,使机器人能够从经验中高效、稳定地学习多孔装配技能。Zheng 等人[46]提出自适应双自举DDPG算法,该算法将DDPG扩展到自举演员-评论家体系结构,通过多个Actor捕捉更多潜在的行动和多个Critic协作评估更合理的Q值,提高了机器人探索效率和算法性能。武曲等人[47]将LSTM 算法与DDPG 算法相结合,以环境图像作为输入,通过预先训练的自动编码器进行图像降维,方便准确提取环境特征信息,利用LSTM 处理数据时的预测特性,实现了有预测的机器人动态路径规划。
(2)TRPO
在DDPG策略梯度的优化过程中,得到合适的步长对移动机器人路径规划学习效率和训练效率至关重要。为确定合适的步长,Schulman等人[48]提出了一种基于信赖域策略优化的强化学习算法(Trust Region Policy Optimization,TRPO)。实验表明,最小化某个替代损失函数可以保证策略在非平凡步长下的改进,使策略始终朝着好的方向持续更新,但计算过程复杂、对策略与环境的交互依赖大、容易出现较大误差的问题。
Jha等人[49]提出了一种拟牛顿信赖域策略优化(QNTRPO)方法,将计算步长作为搜索方向计算的一部分,而且步长能够根据目标的精度而变化,使得该算法的学习速度比TRPO 要快。Zhang 等人[50]对TRPO 算法进行了从不同目标中学习信息能力的扩展,解决了奖赏稀少、算法误差大的问题,进一步优化了算法的性能。Shani等人[51-52]对TPRO算法进行改进,使得改进后的TPRO有更强的学习能力。
(3)PPO
针对TRPO算法计算过程繁杂,过于依赖策略和环境的交互,从而导致机动机器人运动规划路径与最优路径产生偏差的问题,Schulman等人[53]在TRPO算法基础上提出了近端策略优化算法(Proximal Policy Optimization,PPO)。它通过与环境的交互作用来采样数据,使用随机梯度代替标准策略梯度优化目标函数交替,使得机器人路径规划算法具有较好的数据效率和鲁棒性。PPO 和TRPO 算法最大的区别是PPO 支持多个时段的小批量更新,实施起来更简单、更通用,并且具有更好的样本复杂性。
PPO 算法可以在各种具有挑战性的任务中实现最先进的性能,但是,PPO 算法不能严格限制似然比和强制执行定义明确的命令与约束,这就导致PPO算法的性能不稳定。为了解决这个问题,Wang 等人[54]提出了一种增强型PPO 算法,真实PPO 算法(Truly PPO,TPPO)采用新的函数来支持回滚行为,限制新旧策略的差异,优化目标函数,改善最终策略性能,通过将策略限制在信任域内,TPPO 算法在样本效率和性能上都有了很大的提高。
(4)A3C
Mnih 等人[55]基于异步强化学习(Asynchronous Reinforcement Learning,ARL)的思想,提出一种概念简单、轻量级的深度强化学习框架——异步优势的演员评论家算法(Asynchronous Advantage Actor-Critic,A3C)。基于A3C的移动机器人路径规划算法主要是将异步梯度下降算法和DQN 算法以及多种强化学习算法相结合,让不同的机器人在相同的环境进行不同步的交互学习,训练时间和数据效率随着并行参与者学习者的数量而变化,当使用更多的平行参与者学习者时,并行应用在线更新的多个参与者学习者对参数进行的总体改变在时间上的相关性可能较小。因此,A3C算法不再依赖经验回放来稳定学习,能够使用基于策略的强化学习方法,使得训练时间更短,效率更高。
在实际问题中,当并行参与训练的机器人过多时,就会导致训练数据过大,应用成本增加,而且存在收敛于局部最优策略和样本探索效率低下等问题。Kartal等人[56]将终端预测(Terminal Prediction,TP)任务集成到A3C 中,并进行了最小程度的细化,通过让机器人预测其终端状态的距离来学习控制策略。实验表明,A3C-TP算法在大多数测试领域的性能都优于标准的A3C算法,在针对不同对手的策略方面学习效率和收敛性都有显著提高。Labao 等人[57]提出了一种基于异步梯度共享(Gradient Sharing,GS)机制的A3C 算法(A3C-GS),用于改进A3C算法探索数据的效率。该算法具有在短期内自动使策略多样化以供探索的特性,从而减少了对熵损失项的需求,而且在需要探索的高维环境中表现良好。
(5)SAC
一般基于强化学习的移动机器人路径规划算法样本学习效率都比较差,是因为基于梯度策略的算法学习有效策略所需的梯度步骤和每个步骤的样本数量随着任务的复杂性而增加。针对这个问题,Haarnoja 等人[58]提出了一种基于最大熵的离线学习强化学习方法:软行动者-批评者(Soft Actor-Critic,SAC)算法。SAC 算法将非策略更新与稳定的随机Actor-Critic公式相结合,在最大化熵的同时,最大化预期回报,即在尽可能随机行动的同时成功完成任务。实验证明,SAC算法提高了样本的学习效率和算法稳定性,很容易扩展到非常复杂的高维任务[59],更加适应于真实环境。
Fu 等人[60]提出了一种基于最大熵框架的SAC 算法,并成功应用到车载互联网中的实时流媒体服务控制中。Cheng等人[61]将无人机的决策问题建模为马尔可夫决策过程(MDP),构建强化学习框架,并将SAC算法与仿真环境相连接,训练模型使得无人机学习任务的决策,生成基于SAC算法的自主决策能力,使无人机在与环境交互的过程中不断总结经验,做出最佳的战略选择。Tang 等人[62]提出了一种层次化的SAC 算法来解决多物流机器人分配任务问题,通过引入子目标在不同的时间尺度上对模型进行了训练,其中顶层学习了策略,底层学习了实现子目标的策略,与原本SAC算法相比,该方法能够使多物流AGV 机器人协同工作,在稀疏环境下的奖励提高了约2.61倍。
3 DQN算法在路径规划方面的改进总结
DQN 算法在移动机器人路径规划中得到广泛应用,为了进一步提升DQN算法的学习效率,许多学者提出了许多富有成效的改进措施,将上述的主要内容进行总结,如表1所示。

表1 DQN算法的改进总结Table 1 Summary of improvements in DQN algorithms
单一的DQN 改进算法的都能实现显著的性能改进,因为它们的改进都是为了解决单一的问题,把DQN改进算法相互融合,取长补短,它们很大程度上可以更好地提高算法性能。Xie等人[63]提出了一种基于决斗结构的深度双Q 网络避障算法(Dueling Double Deep-Q Network,D3QN)。D3QN 算法可以有效地学习如何在模拟器中避开障碍物,实验表明,D3QN 与传统的DQN算法相比,能够实现双倍的学习速度,而且可以将在虚拟环境中训练的模型直接应用到复杂未知的路径规划环境中。基于优先经验的DDQN和决斗DDQN都使用双Q 学习,决斗DDQN 也可以与优先经验重放相结合。Hessel等人[64]提出了Rainbow的概念,将DQN算法的六个扩展集成到单个集成代理中,将Rainbow的表现与A3C、DQN、DDQN、优先DDQN、决斗DDQN、分布式DQN和噪音DQN的相应曲线进行比较,Rainbow的性能明显优于任何基线,数据效率和最终性能都表现良好。
除了对DQN 算法进行以上改进外,还从其他角度对DQN 算法及模型架构进行了研究。Kulkarni 等人[65]提出一种分层DQN算法(hierarchical-DQN,h-DQN),将控制任务分成若干层次,从多层策略中学习,每一层都负责在不同的时间和行为抽象层面进行控制,提高了学习效率。徐志雄等人[66]将Sarsa与DQN 算法相融合,提出了基于动态融合目标的深度强化学习算法(Dynamic Target Deep Q-Network,DTDQN),有效地减少了值函数过估计,提高学习性能和训练稳定性。张俊杰等人[67]提出了状态值再利用的决斗深度Q 学习网络(Reuse of State Value-Dueling Deep Q-learning Network,RSVDueling DQN),将机器人训练样本时得到的奖励值标准化后与Dueling-DQN算法中的Q网络值进行结合,加强状态-动作对的内在联系,使得机器人能够得到更加准确的奖励值,不仅使算法的稳定性大大提高,更加加快了算法的收敛速度。Avrachenkov等人[68]、Hui 等人[69]也对DQN 算法从不同的角度进行改进,并取得了良好的效果。
4 DRL算法在其他方面的实际应用
4.1 计算机博弈
深度强化学习(Deep Reinforcement Learning,DRL)综合利用了强化学习的心理和神经机制以及深层神经网络强大的特征表示能力,在人工智能的发展中发挥着重要作用[70]。计算机博弈是人工智能领域最具挑战性的研究方向之一,已经研究出了很多重要的理论和方法,并应用到实际问题中。2016 年,DeepMind 团队根据深度学习和策略搜索的方法研制出了围棋博弈系统AlphaGo,并以4∶1的战绩打败了围棋冠军李世石[71],之后AlphaGo 的升级版Master 在与世界顶尖围棋大师柯洁的对战中以3∶0 的成绩取得了胜利。2017 年,Deep-Mind 团队在此基础上研制出完全基于DRL 的系统AlphaGo Zero,完全不需要人类的经验数据,在短时间内并且自己训练自己的情况下以100∶0 的成绩打败了AlphaGo[72]。计算机博弈分为完备信息博弈和非完备信息博弈,破解完备信息博弈游戏相对来说比较容易,但非完备信息博弈更加复杂,破解更加困难,具有更大的挑战性。对于人工智能的研究者来说,对非完备信息博弈游戏的研究仍是一个充满挑战性的方向。
4.2 视频游戏
由于DRL 的训练需要大量的采样和试错训练,而游戏环境能够提供充足的样本,并且避免了试错的成本[73],所以DRL适用于视频游戏领域。游戏环境具有多样性,但DQN算法较早应用于Atari 2600的算法,在跨越49 场比赛的专业人类游戏测试仪的水平上进行,计算机能够在超过一半的比赛中实现超过75%的人类分数的成绩[74]。之后,Nair[26]、Hasselt[23]、Wang[24]、Schaul 等人[37]对DQN算法进行改进,分别在Atari 2600游戏中取得了成绩,并得到不同程度的提升,Atari 2600 的游戏数据集已经达到了人类级的控制精度。2020 年,Badia等人[75]提出Agent57 算法,在Atari 2600 游戏中取得了良好的成绩,超越了人类的平均水平。除了Atari平台,人们也基于其他游戏平台对DRL进行了研究。Kempka等人[76]、Vinyals 等人[77]通过研究DRL 算法,提出了将ViZDoom 和StarCraftII 为DRL 的测试平台,ViZDoom基于监督学习的方法,StarCraftII 基于实时策略(RTS)的方法,大大提高了算法的训练速度,显著地提高了智能体在游戏中的表现性能。RTS游戏被视为AI研究的大挑战,MOBA(Multi-player Online Battle Arena)是一种RTS游戏。腾讯的AI Lab利用DRL研究MOBA中的王者荣耀(Honor of Kings)游戏,其中重点研究1V1 模式[78],经过训练后,在2 100 场的1v1 竞赛中的获胜率为99.81%。目前,视频游戏是DRL 算法最好的训练方法之一,人们对视频游戏的研究对未来人工智能的发展具有重要意义。
4.3 导航
导航是指移动机器人在复杂环境下在一个地方运动到一个指定的目的地,在运动过程中要避开障碍物、找到最优路径。近年来,利用DRL在迷宫导航、室内导航、视觉导航等方面的研究取得了一定进展。在迷宫导航方面,Jaderberg等人[79]提出采用无监督的辅助任务的强化学习,在没有外在奖励的情况下也能继续迷宫导航,使得迷宫学习的平均速度提高10 倍。在室内环境中,Zhu等人[80]利用迁移强化学习方法,以深度图像作为神经网络输入提取环境特征,训练后的移动机器人经过参数微调可以被直接应用到现实环境中的导航控制。基于视觉的导航对机器人的应用至关重要,Kulhanek等人[81]提出一种基于视觉的端到端的DRL导航策略,设计了视觉辅助任务、定制的奖励方案和新的强大模拟器,能够在真实的机器人上直接部署训练好的策略。在30次导航实验中,机器人在超过86.7%的情况下到达目标的0.3 m 邻域,该方法直接适用于移动操作这样的任务。导航技术的发展对于机器人路径规划技术的发展是非常重要的,导航技术的应用也越来越广泛。
4.4 多机器人协作
多机器人协作是指机器人之间通过相互合作完成任务,从而得到联合的奖励值,通过并行计算提升算法的效率或者可以通过博弈互相学习对手的策略。单个机器人在一个复杂的环境中进行路径规划发挥的作用总是有限的,多机器人与单机器人相比,通常能够完成更加复杂的任务[82]。基于DRL 的多机器人协作问题是机器学习领域的一个重要的研究热点和应用方向,因此研究多机器人路径规划具有极高的价值和意义[16]。
目前解决多机器人的路径规划问题取得了一定进展,梁宸[83]提出一种基于改进的DDPG多机器人DRL算法。该算法将DDPG算法中的AC网络加入了带注意力神经元的双向循环神经网络,用于多机器人之间的通讯,改进后的算法不仅提高了算法的收敛速度,任务的完成度也有显著提升。Foerster等人[84]提出了一种多机器人行为-批评方法,采取分散的政策,即每个主体只根据其局部行动观察历史来选择自己的行动,同时提高所有智能体共同的奖励值,显著提高了机器人路径规划的平均性能。Mao等人[85]提出了一种基于深度多主体强化学习的算法:学习-交流的ACC(Actor-Coordinator-Critic)网络,解决多机器人之间的“学习-交流”问题。ACC网络有两种模式:一种是在Coordinator 的帮助下学习Actor 之间的通信协议,并保持Critic 的独立性;另一种是在Coordinator 的帮助下学习Critic 之间的通信协议,并保持Actor 的独立性,由于Actor 是独立的,在训练完成后,机器人之间即使没有交流也可以相互配合。Sunehag等人[86]、Iqbal等人[87]也对多机器人之间的协作进行了研究,并取得了一定成果,促进了多机器人协作的发展。
DRL训练通常需要大量样本进行训练,多机器人协作可以使得多个机器人并发产生大量样本,增加了样本数量,提高了学习速率,但多机器人环境下的学习任务仍然面临着诸多挑战,因为人类社会中很多问题都可以抽象为复杂的多机器人协作问题,所以还需要进一步探索研究该领域[88]。
5 结论
本文主要通过研究DQN 算法的原理、改进算法以及实际应用等,体现了DRL的演化过程。如今,虽然基于改进DQN 算法的深度强化学习模型已经较为完善,在机械臂、电动汽车实时调度策略[89]、室内外路径规划、无人机等方面得到了广泛应用,但对DQN 算法的研究主要集中在虚拟环境中,算法的实际应用现仍处于发展阶段。DRL算法的自主学习应用需要大量的学习样本,但在实际环境中获取大量样本是不实际的,样本收集成本高,但少量样本使得机器人学习到的经验准确性不足。探索过程中目标的丢失也是路径规划研究中的一个重要问题,计算机本身的计算能力也限制了移动机器人路径规划算法性能。另外,DRL算法在进行路径规划时,需要时刻与环境进行交互,机器人依靠传感器和图像信息完成复杂环境中的避障任务,所以从传感器获取信息的准确性,对算法的性能有重要影响。DQN 及其改进算法都是首先在模拟环境中进行的,模拟环境的成功应用才可以推广到现实环境中,但是模拟与现实环境总是存在差距的。据此,未来对DQN 算法的研究可以从以下方面展开:
(1)建立精准环境预测模型。建立准确的环境模型,Agent就可以减少与真实环境的交互,通过学到的环境模型预测未来状态[90],这不仅有助于提供一个潜在的无限数据源,还可以缓解真实机器人的安全问题。然而面对复杂多变的环境,在有限样本的情况下,建立精准的环境模型是十分困难的。
(2)避免在探索过程中失去目标。在路径规划问题中,机器人可能过于专注于探索路径以避开障碍物而忽略学习目标。奖励函数是移动机器人的训练的支撑,设计合理有效的奖励函数,对过度专注于探索路径的机器人进行惩罚是至关重要的。另外可以进行模仿学习,使智能体模仿人类思考,与给定观察环境进行交互,使其最终获得最大的累积奖励。
(3)提高勘探数据的有效性。利用递归神经网络模块在机器人的学习过程中加入记忆单元。机器人的输出动作可以由多个状态控制,可以解决信息丢失导致的低效探索问题。但在实际问题中,环境往往都是复杂且未知的,机器人探索得到的数据庞大且复杂,无法快速筛选得到有效的样本,导致算法学习效率差。
(4)提高计算机的计算能力。计算机的计算能力对于算法性能,就像大脑的思考能力对于人类生命,无论多么优秀的算法,都需要以计算机为载体进行实验仿真,然后运用到实际环境中,所以提高计算机本身的计算能力,对于算法性能的提升至关重要。
(5)增强处理传感器信息技术的发展。DRL算法可以完成各种传感器信息的融合,做出合理决策,但是不同类型的传感器具有不同的信息冗余性,处理不同渠道的传感器信息[91],获取准确的环境信息是亟待解决的问题,一些传统的规划方法可以作为辅助决策,来提高算法决策的可靠性。
(6)缩小模拟环境与真实环境的差距。虚拟模型被转换到真实环境中会降低策略的性能[92],提高模拟环境的真实性能更好地为现实世界做准备,但缩小虚拟和现实的差距需要更广泛的理论和经验,以便更好地理解DRL算法在学习过程中的效果。
就目前发展现状而言,基于DRL 路径规划算法大多还处于实验室阶段,与应用到现实世界中的运动规划算法还具有较大的差距。未来对DRL算法的应用研究不能仅仅局限于算法本身的改进,可以多学科合作,将人机交互知识领域的经验融于DRL算法,提高Agent应对环境的不确定性和突发性情况的能力;将DRL 算法与自动控制理论相联系,两者相互借鉴,让Agent 向着更加智能化的方向发展。
