基于大数据平台的中压配电网精准损耗分析
2021-10-14黄园芳谭涛郑世明徐达艺王晓明王星华
黄园芳,谭涛,郑世明,徐达艺,王晓明,王星华
(1.广东电网有限责任公司湛江供电局,广东 湛江 524005;2.广东工业大学 自动化学院,广东 广州 510006)
线损计算是精细化线损分析的前提,也是针对性改善配电网的依据。目前,线损计算方法主要有2类:①基于物理模型的线损计算方法,如均方根电流法和等值电阻法等[1-2],由于存在预设条件、忽略拓扑差异等原因,计算精度较低;②基于智能算法的线损计算方法[3-6],虽然在线损率的拟合上可以达到较高精度,但不满足精细化分析的要求,无法为降损提供全面依据。
前推回代法基于配电网物理模型,通过直接计算潮流可精确获取每一设备的损耗,满足精细化损耗分析的要求[7-8],特别适用于配电网电力大数据平台建成后的电网。
由于设备故障和信号干扰造成大数据平台存在一定程度的数据缺失,阻碍了配电网数据分析和计算。目前,数据填充的常用方法有均值填充和众数填充,由于忽略了负荷数据的变化,填充精度较差[9]。为此,许多学者提出基于数据分析的填充方法:①基于时间序列的分析法[10-12],简单易用;但仅考虑数据随时间的变化,数据缺失严重时,填充精度较低。②基于预测技术的数据填充[13-14],利用大量历史数据建立预测模型对缺失数据曲线进行拟合填充;但受历史数据完整性、规律性及随机事件影响大。③基于聚类的数据填充[15-17],依赖数据间的相似性,通过寻找相似负荷曲线进行填充,因无需考虑随机事件的影响,得到广泛的重视;但聚类簇数主要依赖人工经验设定,聚类中心的形成易陷入局部最优等缺陷,使得填充数据的准确性受到影响,且大量连续缺失数据时,该方法也难以确定所缺数据的归类。
因此,本文提出一种基于随机发生的分布式延迟粒子群优化(randomly occurring distributed delayed particle swarm optimization, RODDPSO)的模糊C均值(fuzzy C mean, FCM)聚类算法,将FCM的内部迭代替换为聚类中心优化避免陷入局部最优,从而获得更精确的历史数据聚类中心。而对于大量连续缺失数据的初始归类,则需要依赖馈线首端和其余变压器的负荷差值形成的初始预填充数据进行聚类,再利用聚类填充形成更为准确的补充数据。
1 基于大数据平台的损耗分析方法
前推回代法的计算过程包括2个步骤:①回代计算支路电流,根据负荷节点的有功和无功功率及电压初值计算各条支路的电流;②前推计算节点电压,依据平衡节点电压保持不变的原则按照电压降公式计算得到各个节点的电压。在此基础上,即可进行精细化的配电网损耗分析。
根据上述算法需求,需获取馈线中每台变压器的有功功率、无功功率、馈线拓扑及参数。配电业务系统集成的多源数据融合大数据平台能够为方法应用提供数据支撑[18],但需填充由于各种原因造成的实时数据缺失[19]。基于大数据平台的损耗计算框架如图1所示。

图1 损耗计算框架
首先,从大数据平台提取负荷与拓扑等数据;然后,根据历史数据聚类形成最优的聚类中心,并计算对应的隶属度;接着,根据日负荷曲线的隶属度和聚类中心进行缺失数据填充;最后,利用前推回代法求解馈线损耗。
2 基于RODDPSO的FCM聚类的填充算法
2.1 RODDPSO算法
为了改善PSO算法容易陷入局部最优这一缺陷,改进算法大多在粒子速度、位置修正增加随机性和可变权重,如量子粒子群算法(quantum particle swarm optimization, QPSO)[20]在传统PSO基础上取消了粒子的移动方向属性,增加了粒子随机性,文献[21]则提出具有线性减小的惯性权重,即
(1)
式中:ω为粒子群算法的惯性权重,随迭代次数增加而变小;ωmax和ωmin分别为惯性权重最大、最小值;t为当前迭代次数;tmax为最大迭代次数。
在此基础上,本文进一步提出RODDPSO算法,将随机出现的分布式时延引入速度更新模型,速度更新公式中分布式延迟项的强度因子(以下简称“强度因子”)需根据演化状态来确定,其中演化状态分为收敛状态、开发状态、探索状态、跳出状态[22],4个演化状态可通过等分策略进行划分,即:
(2)
(3)
(4)
式(2)—(4)中:ξ(t)为第t次迭代的演化状态;Ef(t)为第t次迭代的进化因子;di为第i个粒子到其他粒子之间的平均距离;dg为全局最佳粒子到其他粒子之间的平均距离;dmax和dmin分别为种群中di的最大值和最小值;S为种群数量;D为粒子维度;xik为第i个粒子的第k维数据。
4种演化状态分别对应4种不同的强度因子ml(ξ)和mg(ξ),其更新策略见表1。
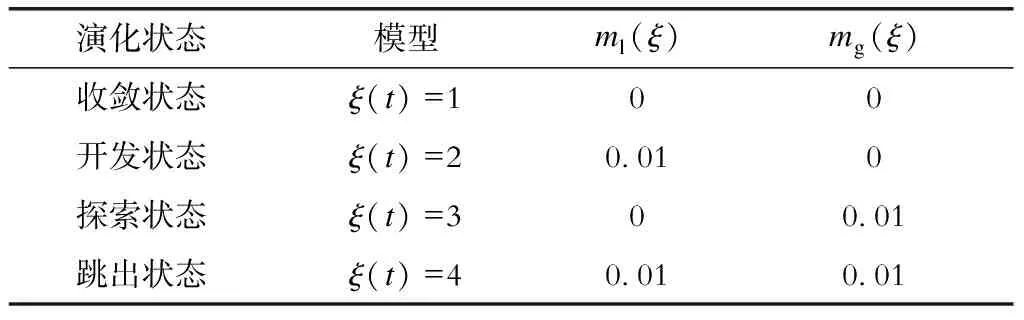
表1 强度因子更新策略
根据上述的更新策略即可得到速度和位置更新[23]:
vi(t+1)=ωvi(t)+c1r1(pbest(i)(t)-xi(t))+
c2r2(gbest(t)-xi(k))+
(5)
xi(t+1)=xi(t)+vi(t+1),
(6)
(7)
(8)
式(5)—(8)中:vi和xi分别为第i个粒子的速度和位置;c1和c2分别为个体加速因子和社会加速因子,c1s和c2s分别为c1和c2的初始值,c1f和c2f分别为c1和c2的终值,由实际经验确定,取c1s=2.5、c1f=0.5、c2s=0.5和c2f=2.5;c3和c4分别为分布式延迟项的个体加速因子和社会加速因子,取c3=c1、c4=c2;pbest(i)为第i个粒子当前最优位置;gbest为所有粒子当前最优位置;M为分布式延迟项的数目;α(τ)为0和1中的随机数,以体现算法中的随机发生;ri(i=1,2,3,4)为均匀分布在[0,1]中的随机数,以增加搜索的随机性。此外,当延迟迭代次数τ小于当前迭代次数t时,速度更新公式根据式(5)执行,否则执行式(9)。
vi(t+1)=ωvi(t)+c1r1(pbest(i)(t)-xi(t))+
c2r2(gbest(t)-xi(k))+
(9)
2.2 基于RODDPSO的FCM负荷曲线聚类算法
本文采用FCM进行负荷曲线的聚类。FCM的聚类中心为p=(a1,a2, …,aD)的D维向量,RODDPSO中每个粒子含K个聚类中心,其格式为K×1×D的三维数组,通过迭代寻找FCM的聚类中心使目标函数最小,其目标函数为
(10)
式中:U为大小为N×K的隶属度矩阵,计算方法见文献[24],N为样本数量;V为大小为K×D的聚类中心矩阵;uij为样本xi属于第j类聚类中心的隶属度;pj为第j类聚类中心;‖xi-pj‖为样本xi到第j类聚类中心的欧式距离;m为模糊参数,通常设置为2。
聚类中心数K作为人为输入参数,在一定程度上会影响聚类效果。为了达到“类间分离度高,类内紧凑性好”的效果,需要借助Xie-Beni(XB)指标确定最佳聚类数K[25]:
(11)
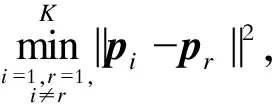
基于RODDPSO和XB指标的聚类算法过程如下:
a)基于XB指标利用原始FCM找出最优聚类簇数K。
b)初始化RODDPSO的参数,其中,聚类中心为随机的K条负荷曲线。
c)根据聚类中心和隶属度计算出所有粒子的目标函数,并更新pbest和gbest。
d)确认演化状态,并根据演化状态更新速度和位置方程。
e)重复步骤c)—d),直至达到最大迭代次数。
2.3 缺失数据填充
隶属度的准确性关系着填充值的精确性,而数据缺失程度高时不能忽略缺失值对隶属度计算结果的影响,因此本文针对数据全部缺失的极端情况,采用负荷预填充的方法。当根据馈线首端的负荷数据与馈线中其他变压器的负荷数据的差值进行预填充时,由于不能保证数据能同时采集与上传,预填充值与实际值之间会存在误差,但预填充值在一定程度上提高了隶属度的准确性。
在进行RODDPSO后可得到最优的聚类中心和由聚类中心计算得到的隶属度,由于负荷曲线对每个聚类中心都存在隶属度,因此应综合考虑多个聚类中心与隶属度对缺失数据的影响,则缺失数据可由式(12)计算得到。
(12)
式中:xij为第i个缺失数据样本中第j维的数据;uik为样本xi属于第k类聚类中心的隶属度;pkj为第k类聚类中心中第j维的数据。
图2为RODDPSO加FCM填充算法的流程图。

图2 聚类填充流程
3 实例分析
本文以广东省某地级市的某台区2020年7月的有功功率作为算例数据,并将7月31日的台区有功功率、无功功率作为精细化损耗计算的验证数据。
3.1 算法精准度分析
传统损耗计算方法计算精度低、精细化程度不足导致应用性不强,而基于大数据平台的前推回代法却能适应目前线损管理要求。本节在数据无缺失情况下,将传统损耗计算方法中常见的等值电阻法与前推回代算法进行对比,以验证前推回代法准确性,其计算结果见表2。
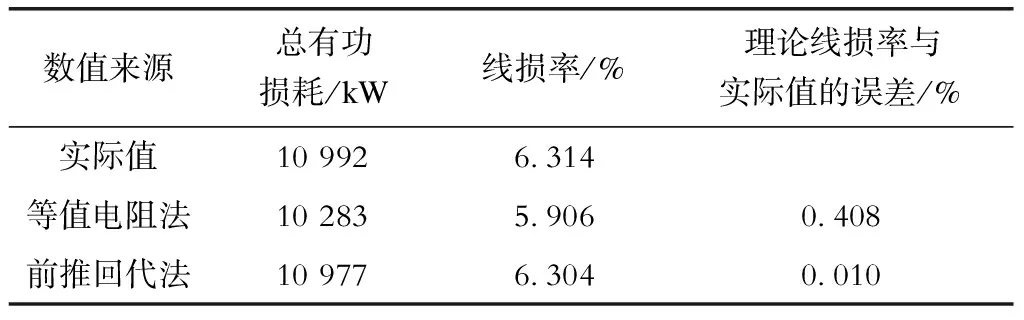
表2 理论线损率
从表2中可以看出前推回代法得到的线损率比等值电阻法更接近实际线损率。此外,前推回代法能够提供更详细的设备损耗信息,因此更适合用来进行精确损耗分析。
3.2 聚类填充仿真与验证
考虑到部分缺失和全部缺失2种情况,现将部分缺失设置在日负荷曲线的前段,缺失率为12.5%,即连续缺失3 h的负荷数据。
设置粒子种群数量s=20,通过聚类有效性指标(XB指标)得到聚类中心数K=2,最大迭代次数tmax=1 000,允许的最大速度vmax=0.5,最大最小惯性权重分别为ωmax=0.9、ωmin=0.4,分布式延迟上限M=200。以某一台变压器的有功负荷曲线为例,采用RODDPSO的FCM算法对这台变压器2种情况下的有功负荷曲线进行模糊聚类,基于最佳聚类数的聚类结果如图3所示。

图3 负荷曲线聚类结果
图3中,横坐标表示1 d中每隔15 min的采样点序号,纵坐标表示该时刻的瞬时有功功率。图3中分别展示了2类负荷曲线的上下限及其所属聚类中心。通过聚类结果可知,该台区所有负荷曲线分成了2类,2类负荷曲线变化趋势虽然相近,但是第二类负荷曲线的峰谷差明显高于第一类,而且波动性更强,另外混合用电性质使得负荷曲线总体呈现向下凹的形状。
为了验证改进后的FCM算法的效果,将本文所提RODDPSO-FCM算法与文献[13]中的BP神经网络(BP neural network,BPNN)、传统的FCM算法和文献[17]中聚类均值(cluster mean,CM)填充算法进行对比,分别对2种缺失情况的数据进行填充,其绝对误差曲线如图4和图5所示,根据标准差(standard deviation,SD)、均方根误差(root mean square error , RMSE)和平均绝对误差(mean absolute error, MAE)得到的误差指标见表3和表4。

图4 有功功率误差曲线(部分缺失)

图5 有功功率误差曲线(全部缺失)

表3 部分缺失下的误差评价指标

表4 全部缺失下的误差评价指标
连续部分缺失数据位于负荷曲线首端的12个数据点,其数据具有波动下降的特征;数据全部缺失时,原负荷曲线仍为凹形曲线,相似的曲线形状也提高了填充的精度。综合图4、图5中的误差曲线和表3、表4的误差指标可知,本文算法所得到的误差SD最小说明填充值更加平滑,RMSE和MAE最小说明填充精度更高。而且通过对比传统的FCM算法,可知经过RODDPSO优化后的聚类中心更能体现数据的总体特征。BP神经网络的填充精度最低,主要原因是:选取的馈线属于D类供电分区的农村地区,其负荷变化没有明显的规律可循,负荷变化也易受到环境因素的影响,而且需要大量的历史数据来建立神经网络,如遇到历史数据缺失则很难完成神经网络的建立。
对缺失数据进行填充后,分别对填充后的负荷数据进行线损计算,其计算结果见表5。

表5 3种情况下的理论线损率
从表5中可以看出,3种情况下得到的理论线损相差较小,故从线损考核标准层面看,本文算法得到的线损率可靠性高。
4 结束语
本文通过与大数据平台的结合,实现数据的自动获取,考虑到实际情况下的数据缺失问题,采用RODDPSO的FCM聚类算法,克服了FCM算法可能陷入局部最优的缺陷,同时提高了PSO算法的全局寻优能力。最后利用算例验证了前推回代法计算的精准度和聚类填充的有效性。综上所述,基于RODDPSO的FCM聚类在缺失数据下的中压馈线精准线损计算方法,与大数据平台紧密结合,着重解决了数据缺失条件下的线损计算精度不高等问题,具有良好的工程实用性。
