基于优化Transformer网络的绿色目标果实高效检测模型
2021-10-12贾伟宽马晓慧赵艳娜JiZe郑元杰
贾伟宽,孟 虎,马晓慧,赵艳娜,Ji Ze,郑元杰※
(1.山东师范大学信息科学与工程学院,济南 250358;2.机械工业设施农业测控技术与装备重点实验室,镇江 212013;3.卡迪夫大学工程学院,卡迪夫 CF24 3AA,英国)
0 引 言
农业生产中,机器视觉已经广泛应用于果蔬产量预测[1-2]、自动采摘[3-4]、病虫害识别[5-6]等领域,目标检测的精度和效率成为制约作业装备性能的关键。当前,对于静态目标果实[7-8]、动态目标果实[9-10]、遮挡或重叠目标果实[11-12]的检测已取得可喜成果。现有的检测模型大都是基于传统的机器学习、新兴的深度网络模型。基于机器学习的检测方法,主要依赖于目标果实特征,如颜色、形状等,与背景差别较大的目标,其检测效果越好,然而遇到绿色目标果实时,果实与背景颜色相近,检测效果相对较差。基于深度学习的检测方法,训练目标网络过度依赖样本数量,在实际果园环境中,有些果园难以获得足够量的样本,无法训练得到精准的检测模型。在复杂的果园环境下,目标果实的姿态千变万化,有些目标果实为绿色,且部分环境数据采集困难造成样本数量不足,这些因素均给目标精准检测带来巨大挑战,吸引着诸多学者的关注。
基于传统机器学习的目标检测方法,在果蔬检测领域积累了大量的研究成果,Li等[13]提出基于均值漂移和稀疏矩阵原理的改进谱聚类算法,均值漂移去除大量背景像素减少计算量,图像特征信息映射到稀疏矩阵,最后实现重叠绿色苹果的识别。黄小玉等[14]针对自然光照条件下绿色目标果实的识别问题,提出DRFI算法的基础上,结合颜色、纹理、形状等特征,实现绿色桃子的识别,该方法先用基于图的分割算法将图像分割成多层,再计算各层的显著图,通过线性组合器得到DRFI显著图。Lv等[15]针对套袋青苹果设计提取果实正常光照区域和突出光照区域相结合的分割方法,利用CLAHE和R-B色差对比增强,分别提取正常光照区域和高亮区域特征,得到完整目标果实区域。Qureshi等[16]利用视觉技术提出 2种芒果树冠图像自动计数方法,基于纹理的密度分割方法和基于形状的水果检测方法,并在夜间图像上测试算法精度和鲁棒性。这些方法在识别精度和效率上均取得较好的效果,为果园目标果实识别提供了重要的理论支撑。然而这些方法大多依赖于果实颜色、纹理、形状特征,在复杂的果园环境下,目标果实特征不够明显,给此类检测方法带来较大挑战。
近几年,随着软硬件技术的发展和深度学习理论的兴起,在目标识别过程中,可实现端到端的检测,大幅提升目标的检测精度以及模型的鲁棒性,广泛应用于目标检测和图像分割领域[17-18]。受此启发,深度学习已逐渐渗入农业生产领域,在此基础上,优化出众多目标检测和图像分割模型应用于目标果实识别[19-20],以辅助实现智慧果园生产的科学管理。Biffi等[21]提出了一种基于ATSS深度学习的苹果果实检测方法,用以处理受遮挡目标果实,该方法只标注物体的中心点,在果园密度大的情况下比边界标注更实用。Li等[22]提出一种适于样本不足的 U-Net绿色苹果分割模型,此方法融合残差块和门限卷积获取目标图像的边界语义信息,利用atrus卷积技术保留更多尺度上下文信息,实现目标果实的分割。Wang等[23]提出一种轻量级卷积神经网络 YOLOv4-LITE火龙果检测方法,用此方法替换主干网络 MobileNet-v3提高检测速度,设置上采样特征融合提高小目标检测精度。武星等[24]针对复杂果树背景下苹果检测,提出轻量级YOLOv3模型,采用融合均方误差损失和交叉熵损失的多目标损失函数,在工作站和嵌入式开发板上的检测速度为116.96浮点/秒(f/s)和7.59 f/s,准确率可达90%以上。上述方法在大都是特定情况下完成,检测效果相对较好,然而在复杂环境下检测绿色目标果实,尤其面对样本数量不足的情况时,现有模型的检测性能受到一定的挑战。
针对复杂果园环境下采集到的绿色果实数据,为提高检测绿色目标果实精度与效率,本研究借助Transformer网络,引入重采样法和迁移学习理论,提出基于优化 Transformer网络的绿色目标果实高效检测模型。该方法首先重采样法扩充样本,以解决因样本数量不足导致网络模型的欠学习;其次借助迁移学习加快网络训练的收敛,减少训练时间;最后在匈牙利损失函数的基础上重新构建损失函数,提高网络的训练精度。最后在绿色苹果和柿子数据集上验证该模型的有效性。
1 材料与方法
1.1 数据采集及数据集制作
1.1.1 图像采集
本研究以绿色目标果实精准检测为目标,以绿色苹果图像、绿色柿子图像为研究对象,因绿色目标果实与背景颜色相近致使检测难度加大,极易造成目标果实的漏检或枝叶混检,给检测带来较大挑战。
采集图像地点:苹果采自山东省烟台市福山区龙王山苹果生产基地(山东师范大学农业信息技术实验基地),柿子采集于山东师范大学(长清湖校区)后山和济南南部山区。
采集图像对象:未成熟柿子(绿色),品种包括牛心柿、盖柿和红柿等;绿色苹果,品种为烟嘎1号。
采集图像设备:佳能EOS 80D单反相机,相机采用CMOS图像传感器。图像分辨率为6 000像素×4 000像素,保存为.jpg格式,24位彩色图像。
采集图像环境:采集过程中充分考虑实际果园复杂场景,采集图像包括多时间、多天气、多光照、多角度、多距离图像。多时间包括春季、夏季以及冬季大棚拍摄;多天气环境包括晴天、阴天、雨天;多光照环境包括白天自然光和夜间人工补光环境,其中白天重点在顺光与逆光2个条件下进行拍摄,夜晚环境以LED灯补光拍摄;多角度拍摄包括仰视45度角拍摄,水平拍摄,360度环顾拍摄;多距离拍摄包括远景拍摄、近景拍摄。在上述环境下,拍摄得到果实重叠、枝叶遮挡等多种情况的绿色果实图片。
共采集553张绿色柿子图像和268张绿色苹果图像,图1所示,包括夜间、重叠、逆光、顺光、遮挡,雨后等多种情况。如逆光图像目标果实表面光线较弱,目标果实与背景之间区别不明显;目标果实间相互重叠、枝叶遮挡果实轮廓往往难以区分;果实表现阴影或雨滴干扰等,再由于目标果实与背景颜色十分相近,给目标果实精准检测造成了一定的困难。
1.1.2 重采样法数据扩充
检测模型训练大多基于足够的样本量,然而在实际果园环境中,部分样本采集相对比较困难,由于样本量不足,在训练过程中容易出现过拟合现象,且模型泛化能力较差。为进一步提高检测模型的精度,可先尝试数据集优化,扩充样本数据集。对采集到的 268张绿色苹果图像,采用重采样法[25],解决样本数量不足问题,扩充图片数量,促进训练时模型的收敛与拟合。
重采样法(bootstrapping)就是利用有限的样本资料经由多次重复抽样,重新建立起足以代表母体样本分布之新样本。假设抽取的样本大小为n,在原样本中有放回的抽样,抽取n次。每抽一次形成一个新的样本,重复操作,形成很多新样本,通过这些样本就可以计算出样本的一个分布。本研究将原始数据多次重复抽样,扩充数据,满足本研究网络在训练时对样本的需求,解决样本数量不足问题。借助重采样法将 268张绿色苹果图像扩充为511张按照7∶3的比例,分为训练集388张图像,测试集123张图像。将553张绿色柿子图像按照7∶3的比例,分为训练集388张图像,测试集165张图像。
1.1.3 数据集制作
本研究采用 LabelMe软件标注绿色球形果实图像制作COCO格式数据集。用LabelMe将绿色目标果实的边缘轮廓使用标注点标注出来,并给出标注标签。标注点将图像分为 2部分,标注点内部为绿色目标果实,其余为背景。所有的标注信息如标注标签、标注点坐标等将会保存到与原图像对应的json文件中。之后将json文件使用LabelMe转换成COCO格式数据集。
1.2 优化Transformer绿色目标检测模型
实际果园所采集的图像,受光照和枝叶影响,目标果实往往会枝叶遮挡、相互重叠、枝叶背景相对复杂,且由于目标果实颜色与背景颜色十分相近,绿色目标果实的高效精准检测是个难题。另外,检测模型受样本数量不足的影响,样本学习不充分,易出现过拟合现象,从而导致目标果实检测精度降低,难以满足在实际作业机械的装配需求。
针对绿色目标果实的高效精准识别问题,本研究提出基于Transformer优化检测模型,如图2所示。首先利用 CNN结构提取图像特征,然后将提取的特征输入到Transformer编码器-解码器,借助前馈神经网络预测目标果实边界框,最后经二值匹配损失处理边界框,实现绿色目标果实检测。在训练过程中,采用二值匹配损失使用唯一的真值框进行分配预测,没有匹配的预测会产生“无目标”(∅)类预测,进一步提高绿色目标果实检测精度。实际果园环境远比预想的情况复杂,尤其是在样本数量不足时,仅使用卷积神经网络,难以有效检测绿色目标果实。本研究引入 Transformer,可一次预测所有目标,在预测目标与真实目标之间进行二值匹配,得出预测结果。
1.2.1 优化模型网络结构
基于Transformer的绿色目标果实优化检测模型的结构由三分部组成:基于CNN的头部网络结构用于图像特征提取,Transformer编码器-解码器用于处理图像特征,前馈网络(FFN)结构用于边框预测。
头部:为更好实现图像特征提取的并行处理,选用CNN作为Transformer网络的头部结构。与其他提取特征方式相比,CNN可与Transformer框架更好的切合,并行处理特征,减少训练时间。从初始图像ximg∈R3×H0×W0的三个颜色通道开始,生成一个低分辨率的激活映射特征f ∈其中使用的特征值为C=2048,H,W=H0/32,W0/32。
Transformer编码器:经 CNN网络得到多维序列特征,然而编码器的期望输入的是一个序列,因此,将激活特征映射f的通道维度从C降低到更小的维度d,建立一个新的维度z0= Rd×H0×W0,并将z0的空间维度压缩成一维,从而产生一个编码器可接受的d×HW的特征映射。编码器由一个多头自注意力模块以及一个前馈神经网络构成,如图3a所示:编码器输入是一个经过压缩后得到的序列,处理时会产生损失,本研究使用固定位置编码来弥补损失,在每个模块当中,添加位置编码,优化编码器结构,解决压缩损失。
Transformer解码器:使用多种注意力机制构建Transformer解码器,对尺寸为d的N个对象嵌入进行转换,如图3b所示。为了提高检测绿色目标果实效率,本研究对N个对象同时进行解码工作,效率高,精度好。编码器特征处理后,生成大小各不相同的输出,经解码器结算,预测结果时可产生远远大于实际对象数量的边界框,避免绿色目标果实漏识。经过解码器学习到的位置编码,与编码器相同,将其添加到解码器的每一个模块中,优化解码器结构。最后经过前馈神经网络独立解码为框坐标和类标签,从而产生N个最终预测。使用编码器-解码器对这些嵌入进行处理,并充分考虑目标对象之间的成对关系,并使用整个图像上下文信息,以此更好的适应样本数量不足的情况,优化输出结果。
前馈神经网络:为了防止网络退化,提高检测效果,前馈神经网络使用一个带有ReLU激活函数、隐藏维数为d的3层感知器和一个线性投影层来计算结果。前馈神经网络预测归一化的中心坐标、边界框的高度和宽度,通过线性层使用softmax函数预测类标签。最终的结果会产生两种结果,一种是有果实的边界框,另一种是没有果实的空值,使用∅代替,这样可以确保将所有的果实进行预测,没有漏识的果实。
综上,绿色目标果实图像经上述 3部分结构连续工作:CNN提取目标果实特征,经位置补码处理后输入到Transformer编码器-解码器中,通过前馈神经网络预测最终结果,产生边界框,最终完成绿色目标果实检测,如图4所示。
1.2.2 损失函数构建
该模型在训练过程中,产生N个预测边界框,如何对这些预测结果进行评分,筛选出最优结果,成为训练的难点之一。本研究尝试构建最优二值匹配损失函数,使用此函数进行二值匹配预测,并优化目标对象的边界框损失。
用y表示真值集,用表示预测集。假设N大于图像中对象个数,则y数量也大于图像中对象个数(当无对象时,用∅填充)。为了找到这两个集合之间的最优二值匹配,使用σ∈代表N个元素的排列,如公式1所示。
其中 Lmatch(yi,yσ(i))是真值yi与预测序列σ(i)之间的二值匹配损失,此优化算法在以匈牙利算法[26]基础上进行的工作
第一步,构建匹配损失函数,在构建匹配损失时,需要同时考虑类预测、相似预测和真值框。真值集的每个元素i可以用yi= (ci,bi)来表示,其中ci表示目标类标签(可能为Ø),bi∈[0,4]4,是一个定义真值框中心坐标及其相对于图像大小的高度和宽度的矢量。对于预测序列σ(i),用概率定义类ci,用定义预测框。定义如下
该匹配过程与目前流行的匹配机制相比,如匹配建议和对真值进行锚框定位的启发式分配规则是大体是相同的。他们之间最主要的区别是需要为其中没有重复的预测集找出一对一的匹配。
第二步是计算损失函数,即前一步中二值匹配时,所有配对的匈牙利损失。对损失的定义类似于普通对象检测器的损失,即类预测的负对数似然值和后面定义的盒损失的线性组合
边界框损失:与其他边界框预测不一致的是,本研究方法经过前馈神经网络处理后,直接预测。对于最常用的ℓ1损失函数来说,即使是在不同的边界框尺度上,其相对误差也十分相似。为了解决这问题,将ℓ1损失函数与 GLOU损失函数 Liou(·,·)在尺度不变的基础上相结合,构建边界框损失函数
其中λiou,λL1∈ℝ是超参数。这两个超参数通过批处理中的对象数量进行规范化。
辅助损失函数:在训练过程中在解码器中使用辅助损耗[27]对优化模型有所帮助,特别是帮助模型输出每个类对象的正确预测。因此,在编码器与解码器每一层中,增加了前馈神经网络和匈牙利损失函数。所有的前馈神经网络共享它们生成的参数,并通过一个额外的共享层来标准化来自不同解码器层的前馈神经网络的输入。
1.2.3 迁移学习优化收敛
从头开始训练一个神经网络通常来说代价非常大,训练网络并使网络收敛需要足够大的数据集,以及需要足够长的训练时间等。基于以上原因,在实际应用时,需要消耗较大的空间与较多的时间。即使有足够多的数据集,达到收敛所花费的时间也较长,不利于农业机器人实时作业,因此使用预先训练的权值代替随机初始化的权值就有十分重要的意义。利用迁移学习中的继续训练过程,微调网络之中的权值可以减少训练所花费的时间,节约时间与空间成本。
Long等人[28]的研究结果表明,特征的可转移性随着预训练任务与目标任务的差异减少而增大,证明即使是从与目标任务差异很大的任务进行特征迁移,也是比初始化训练参数要好。在实际应用迁移学习技术时,需要考虑预训练模型是否满足目标框架约束以及怎样进行微调等细节。因此,首先使用不相似任务的模型作为预训练模型,分别训练绿色柿子与绿色苹果模型,使用绿色苹果为数据集训练得到的模型为模型a,使用绿色柿子为数据集训练得到的模型为模型b,然后使用模型a作为训练绿色柿子模型的预训练模型,预训练模型 b作为训练绿色苹果模型的预训练模型,在不影响模型精度的前提下,交叉进行迁移学习,对比迁移训练前后训练时间。
2 试验设计
2.1 试验流程
本实验算法处理平台为个人计算机,处理器为 Intel i5-7400,8 GB内存。显卡为NVIDIA GTX 1080 Ti。软件环境为 Linux系统,编程语言为 Python,构建解码器与编码器各6层,在服务器上搭建PyTorch深度学习框架,实现绿色果实目标检测的训练和测试。
本研究的绿色果实检测模型训练过程具体步骤如下:
1)在果园环境下使用佳能EOS 80D单反相机采集丰富的绿色果实图像。
2)重采样法(bootstrapping)扩充样本。
3)使用LabelMe软件对图像进行标注,标注时,将每个目标果实标注为一个独立的连通域,制作成 COCO格式数据集。
4)将数据集输入卷积神经网络提取特征。
5)构建Transformer网络框架,训练模型。
6)进行迁移学习,加快模型收敛,减少训练时间。
7)输入测试样本,使用评估指标评价获得的绿色果实检测模型的检测结果,根据评估结构调整模型的参数。
8)重复训练改进模型,直至获得最优网络模型。
2.2 评估指标
为评估本模型对绿色目标果实检测的效果,本研究采用召回率(%)、精确度(%)以及训练时间3项指标对模型进行评估,召回率、精确度的取值范围均为[0,1]。
式中TP是真实的正样本数量,FP是虚假的正样本数量,FN是虚假的负样本数量。
3 结果与分析
3.1 迁移学习效果
试验时,充分考虑实际应用环境,模拟复杂果园环境下数据难以采集的情景,首先使用不相似任务模型迁移学习,将训练完成得到的模型作为新的预训练模型,再次迁移学习,对比训练时间。使用不相似任务的模型迁移学习后,训练绿色柿子图像使用 6小时28分钟55秒,训练绿色苹果图像使用6小时23分钟41秒,使用相似的模型迁移学习后,训练绿色柿子使用5小时37分钟07秒,训练绿色苹果图像使用5小时28分钟43秒,训练效率提高 13%以上。通过对比时间可以看到,使用相似类别模型进行迁移学习,实际训练模型所需要的时间更少,且速度更快。充分说明了特征的可转移性随着预训练任务与目标任务的差异减少而增大,增加了检测速度与效率。
3.2 绿色目标检测效果
试验采集的图像充分考虑到果园的真实复杂场景,包括不同光照、不同角度影响,如顺光、逆光、相互重叠、枝叶遮挡、夜间等混合干扰下的图像,本研究所构建的Transformer的绿色目标果实优化检测模型,柿子和苹果的检测效果图如图5、图6所示,检测评估结果列于表1。
苹果图像有较多远景图像,果实比较密集,数目较多,柿子图像采集环境明显比苹果图像采集环境复杂,所以柿子图像的召回率与准确率相比之下略高。重叠、逆光、夜间和遮挡条件对果实检测造成了一定影响,检测效果稍微略差。顺光和雨后下的果实检测效果相对较好,不存在遮挡和重叠情况的独立果实检测效果最好。综上,该方法的泛化能力和鲁棒性较好。
3.3 重采样法对比
为了进一步分析算法性能,将本研究方法与具有代表性的 Mask r-cnn[29]、Mask scoring r-cnn[30]、Faster r-cnn[31]和Retinanet[32]方法进行对比,试验结果列于表1。
试验采集绿色柿子图像553张,由表1可知,检测绿色柿子准确率为93.27%,试验精度较好,使用原始绿色苹果图像训练网络,准确率为90.70%,精度较差,故将绿色苹果图像使用重采样法扩充样本,有效解决因样本不足致使网络拟合较差问题,使用重采样后,检测绿色苹果准确率为91.35%,召回率为88.38%。Mask r-cnn、Mask scoring r-cnn以及 Faster r-cnn分别为 90.03%,89.52%和89.11%,较未使用重采样法前,精度有所提升。Retinanet方法面对样本数量不足时检测精度为87.82%,使用重采样法后精度为88.59%。
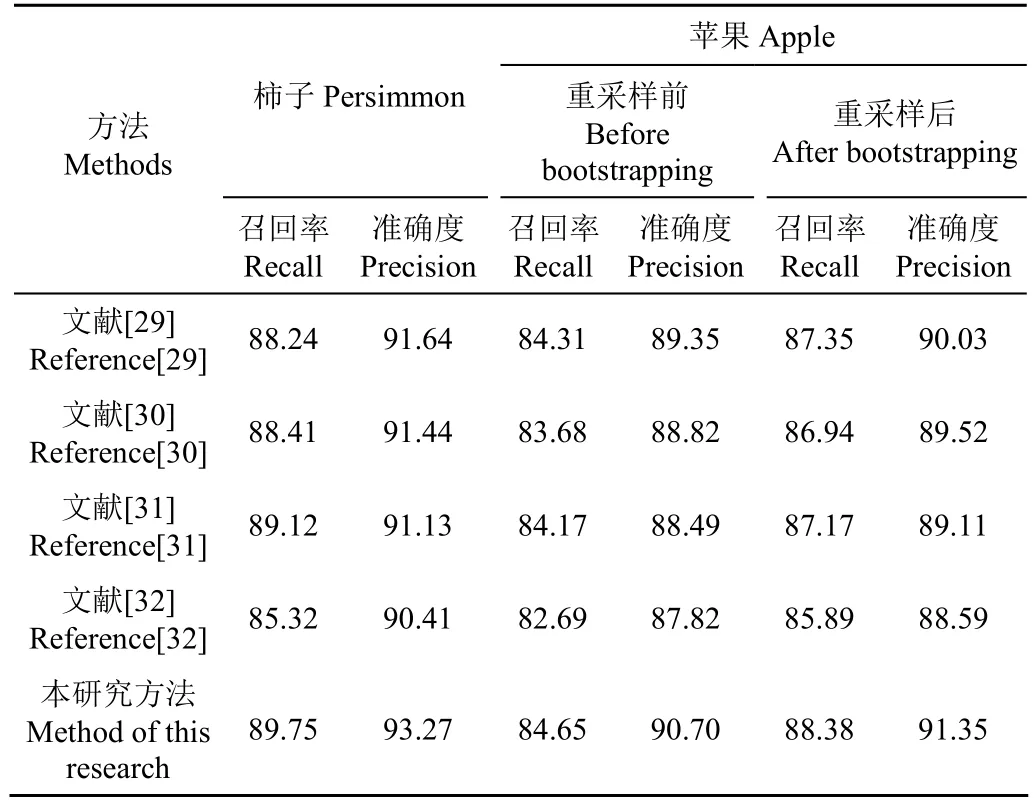
表1 5种方法性能比较召回率和准确度Tabel 1 Performance comparison of five methods by recall rate and precision rate %
经过上述分析,通过目标检测精度来看,使用重采样法后,精度有所提升,可更好的满足果园智能测产和自动化采摘要求,提高模型泛化能力。
3.4 算法对比
由表1可知,尽管存在误识和漏识现象,但与其他方法相比,本研究方法检测性能最好,可较为准确地检测出图像中绿色目标果实。本研究检测绿色柿子准确率分别为93.27%,召回率为89.75%。其中Mask r-cnn、Mask scoring r-cnn以及Faster r-cnn都采用r-cnn结构,其遵循序列处理特征原则,在处理并行问题上,效果表现不佳,而本研究方法使用Transformer框架处理图片,可并行处理特征,优化最终结果。Retinanet方法检测效果比Faster r-cnn略差。
经过上述分析,通过目标检测精度来看,本研究方法取得了不错的效果,基本可以达到实时性的要求,具有很强的泛化能力和鲁棒性。
4 结 论
1)通过重采样处理,可有效扩充样本数量,提高检测模型学习能力,有效解决因样本数量不足引起的网络模型欠学习。
2)模型训练引入迁移学习,有效提高模型的训练效率和加速网络收敛,从实验结果看,训练效率提升 13%以上。
3)新模型可有效实现复杂果园环境下多姿态、多光照、多场景的目标识别,新模型的泛化能力和鲁棒性较好。试验结果表明,检测绿色柿子与绿色苹果时,精度分别为93.27%和91.35%。
