基于问句感知图卷积的教育知识库问答方法
2021-10-12蔺奇卡张玲玲赵天哲
蔺奇卡,张玲玲+,刘 均,赵天哲
1.西安交通大学 计算机科学与技术学院,西安 710049
2.陕西省天地网技术重点实验室,西安 710049
近年来,随着互联网技术的蓬勃发展,各种在线教育平台层出不穷,造成了海量教育资源以及教学数据的不断积累[1]。知识库(或知识图谱)以RDF 三元组的形式存储大量实体及它们之间丰富的语义关系,这为教育领域的海量信息提供了良好的组织方式,因而受到越来越多的关注。具体而言,教育知识库可将分散、无序的教育数据聚合为结构化的,易于检索、修改和保存的知识形式,进而降低用户的使用成本并快速实现认知升级[2]。例如清华大学Yu等人[3]提出了大规模在线课程(massive open online course,MOOC)知识库MOOCCube,其包含概念、课程、教师和学生行为等实体及其交互信息,用以支持多种不同场景的教学研究需求。Xu 和Guo[4]提出适用于K12教育的知识点知识库,其中节点主要包含知识点、学校和教师等,实验表明使用该知识库能有效提升教育资源推荐的准确性。Lin 等人[5]使用大学教师在科研和教学活动中产生的交互数据构建了大学教师知识库,包含教师、研究方向、科研成果和社会兼职等,进而为教师评估提供定性和定量的数据支持。
同时,教育知识库的出现为教育领域的智能问答提供了基础,它能为学习者提供良好的交互体验和精准智能的答疑辅导服务,是在线教育领域亟待解决的关键问题之一[2]。目前,对于教育知识库问答的研究还相对薄弱,不能满足当前教育平台发展的需求[6]。相比于开放领域的知识库问答,教育领域知识库中包含的关系较少。例如基于MOOCCube 的MOOC Q&A[3]中仅包含10 种关系类型,而基于开放知识库Freebase[7]的WebQuestionsSP[8]数据集包含513 种关系。这种差异导致教育领域的问答模型需要有效获取实体针对于问句独特而有价值的表示方式,然而开放域的经典问答方法(例如GRAFT-Net[9]、PullNet[10]、MHGRN[11]和EmbedKGQA[12])在进行实体表示时,很少考虑问句的影响。基于此,本文提出基于问句感知图卷积网络(graph convolutional network,GCN)的教育知识库问答方法。针对特定问句,该方法首先将其分解为问句描述信息和查询实体集,并分别进行表示;之后,通过查询实体集构建答案候选子图,并通过双注意力图卷积网络进行处理,注意力的计算分别来自问句描述信息和查询实体集;最后,基于这些表示,进行候选实体打分并预测答案。
本文的主要贡献包括:(1)提出一种基于联合嵌入的教育知识库问答框架,该框架独立地建模问句中的描述信息和查询实体以及候选实体子图,之后融合这些信息并通过前馈神经网络预测得分;(2)针对当前问答方法在候选实体建模时单一、难以捕获特定于问句信息的缺陷,提出问句感知的双注意力图卷积神经网络;(3)在现实的教育知识库问答数据集上的实验结果表明,本文模型的性能优于基准模型。
1 相关工作
目前知识库问答方法主要分为两类:语义解析方法和联合嵌入方法。语义解析方法首先解析自然语言问句,将其转换成逻辑表达式,并通过匹配知识库生成查询语句,最终执行查询得到答案。例如Reddy 等人[13]提出基于语义图的语义解析方法,该方法分析问句,构建由节点(实体、变量或者类型)、边(关系)和操作符构成的语义图,将其视为知识库的子图以实现问句映射,然后通过特定的图匹配方法获取答案。类似地,Yih 等人[14]通过引入查询图提出了基于知识库的问答语义解析框架,其中语义解析被简化为查询图的分阶段搜索生成过程,最终通过查询图的实体链接和卷积神经网络预测答案。整体来说,该类方法虽然取得了一定的效果,且易于理解,但它们通常包含多个模块及多个步骤,在训练时容易造成误差积累,导致性能较差。
基于以上缺陷,一些基于联合嵌入的问答方法被提出,这类方法使用表示学习的思想将问题和候选答案嵌入到统一的向量空间中,之后在该空间中进行距离计算以得到答案。例如Dong 等人[15]提出的MCCNNs(multi-column convolutional neural networks)使用多列图卷积网络处理问句得到其表示向量,同时将候选答案的相关特征(类别、上下文和路径)映射到对应的问句空间中,最后通过向量内积计算距离以预测答案。Sun 等人[10]使用联合嵌入的思想将外部文本融入知识库中以实现更全面的问答。通过迭代地扩充问题子图(节点为实体、实体对及文档),并使用卷积网络进行联合嵌入,模型能够有效解决多跳知识库问答问题。Saxena 等人[12]利用知识库嵌入的思想进行实体、关系及问句的嵌入,其中问句可以理解为知识库上的单跳或者多跳关系,进而将它们都嵌入在同一向量空间中,最后使同经典的知识库嵌入方法(如ComplEx[16])进行得分计算。
基于联合嵌入的方法能够有效挖掘问句和知识库的深度特征,进而取得良好的预测性能。但是目前的相关方法在进行实体表示时仅仅利用知识库中的结构信息,并未考虑问句信息的影响,导致建模不充分。基于此,本文提出问句感知的图卷积网络进行实体建模,在图卷积的信息传递时,模型会综合考虑问句描述和相关查询实体的影响。
2 基于问句感知图卷积的问答模型
为了让图卷积网络能够学习到针对问句的特定实体表示,本文引入问句感知的注意力来分别建模问句描述信息和相应查询实体,整体模型架构如图1所示。形式化地,针对待回答的问题q,其蕴含待查询实体集合EH,例如图1 问句所对应的查询实体集合包含[李华]和[张涛]。使用该集合为种子列表,从知识库中获取h阶邻近子图Gq,其节点集合为Eq,h的取值需保证问题q对应的答案集合ET是Eq的子集。为了解决该类教育知识库问答问题,本文采用问题建模、子图建模和答案预测三阶段的计算方式。本章将从以下三方面进行详细介绍:基于Transformer和知识库嵌入的问句建模、基于问句感知图卷积的子图建模和答案预测与损失函数。
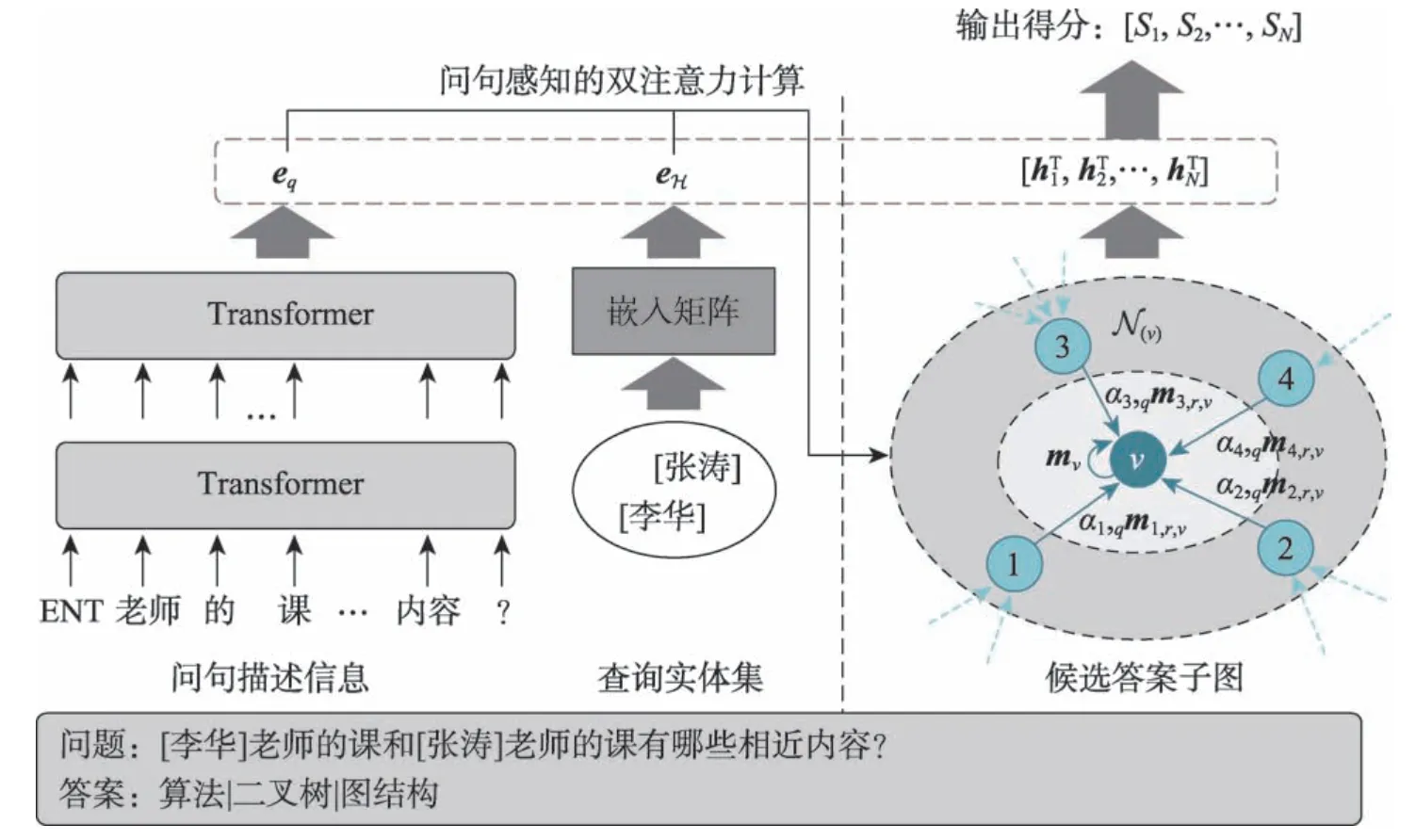
Fig.1 Overall architecture of proposed model图1 模型框架示意图
2.1 基于Transformer 和知识库嵌入的问句建模
本文采用将问句描述与其待查询实体分离的处理方式进行问句建模。具体地,问句描述能够捕获与实体无关的、更本质的意图,而待查询实体能够根据原知识库的结构信息进行建模,两者在预测答案时采用信息融合中“late-fusion”的策略,实现完备的语义补充。针对问句,本文首先将其中的实体转换为特殊符号“ENT”,之后使用中文分词工具“结巴”进行分词处理,得到问句的序列化表示形式q=[w1,w2,…,wn-1,wn],其中n表示句子长度,wi表示第i个词。之后使用带有多头注意力的Transformer[17]进行建模,计算得到问句表示eq:
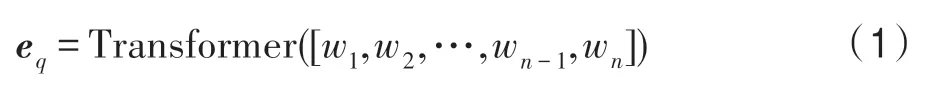
为了有效获取待查询实体在原知识库中的结构信息,模型使用知识库嵌入技术进行初始化向量表示,得到实体表示矩阵E(其中Ei表示实体i的嵌入向量)。本文默认采用DistMult[18]方法进行嵌入,嵌入方法对模型结果的影响见3.4.3 小节。基于此,查询实体集合EH的表示eH可以通过实体嵌入向量均值的方式析出:

2.2 基于问句感知图卷积的子图建模
图卷积神经网络[19]由于其强大的图结构建模能力而逐渐引起广泛关注,它一般遵循迭代消息传递的模式来捕获节点邻域的结构化信息,其第k+1 层的表示通常基于第k层的表示进行图卷积操作(消息传递机制)得到:
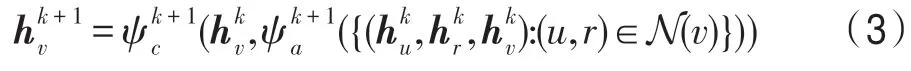
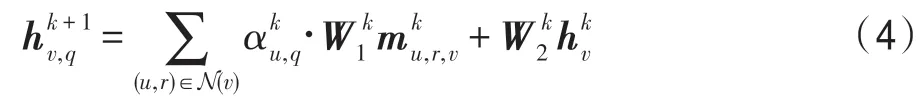

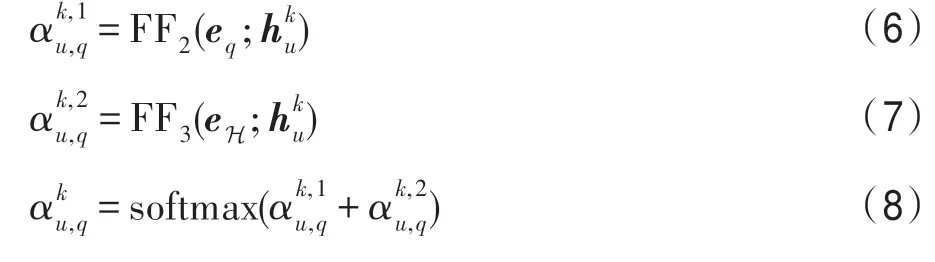
FF 表示前馈神经网络层,符号“;”表示向量之间的拼接操作。通过式(6)和(7)的计算,图卷积在信息传递时会综合考虑问句描述信息和相应的查询实体,因此与问句相关的信息会被增强而无关的信息会被削弱,进而模型能够更好地建模实体表示并预测答案。在图卷积网络的最后一层,记录子图Gq中的节点表示用于最终答案预测。
2.3 答案预测与损失函数
基于前文中对问句和查询子图的建模,本文将问句表示、查询实体表示和候选节点的表示进行拼接,并使用前馈神经网络与sigmoid 函数计算得分:
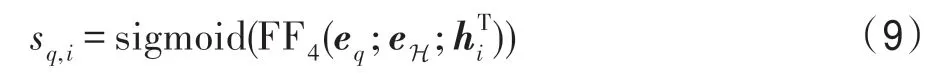
在答案预测时,根据以上计算选择子图中得分最高的实体作为答案。模型最后通过二分类交叉熵定义模型的整体损失函数:
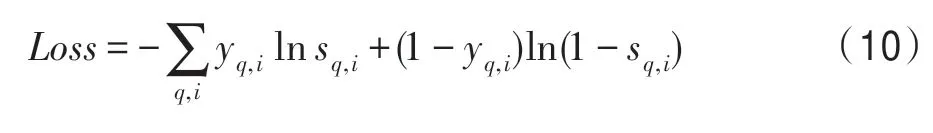
3 实验结果和分析
3.1 实验数据集
实验数据集使用清华大学构建的大规模在线教育知识库MOOCCube[3],并使用其中的MOOC Q&A数据集进行教育知识库的问答实验。该知识库包含706 门真实在线课程、700 个概念和4 723 个用户等7类实体,以及概念-领域、课程-视频和概念先后修顺序等10 类关系,总共构成52 195 个三元组。知识库详细统计信息如表1 所示。MOOC Q&A 中包含两类问题:单跳(one-hop)和多跳(multi-hop)。单跳问题只涉及知识库中的一个头实体和一个关系,而多跳问题可能包含多个实体,且要回答这类问题需要对知识库中的多个事实进行推理。单跳和多跳问题的数量分别为5 504、13 637,在进行实验时,它们都按照80%、10%和10%的比例进行训练集、验证集和测试集的划分。
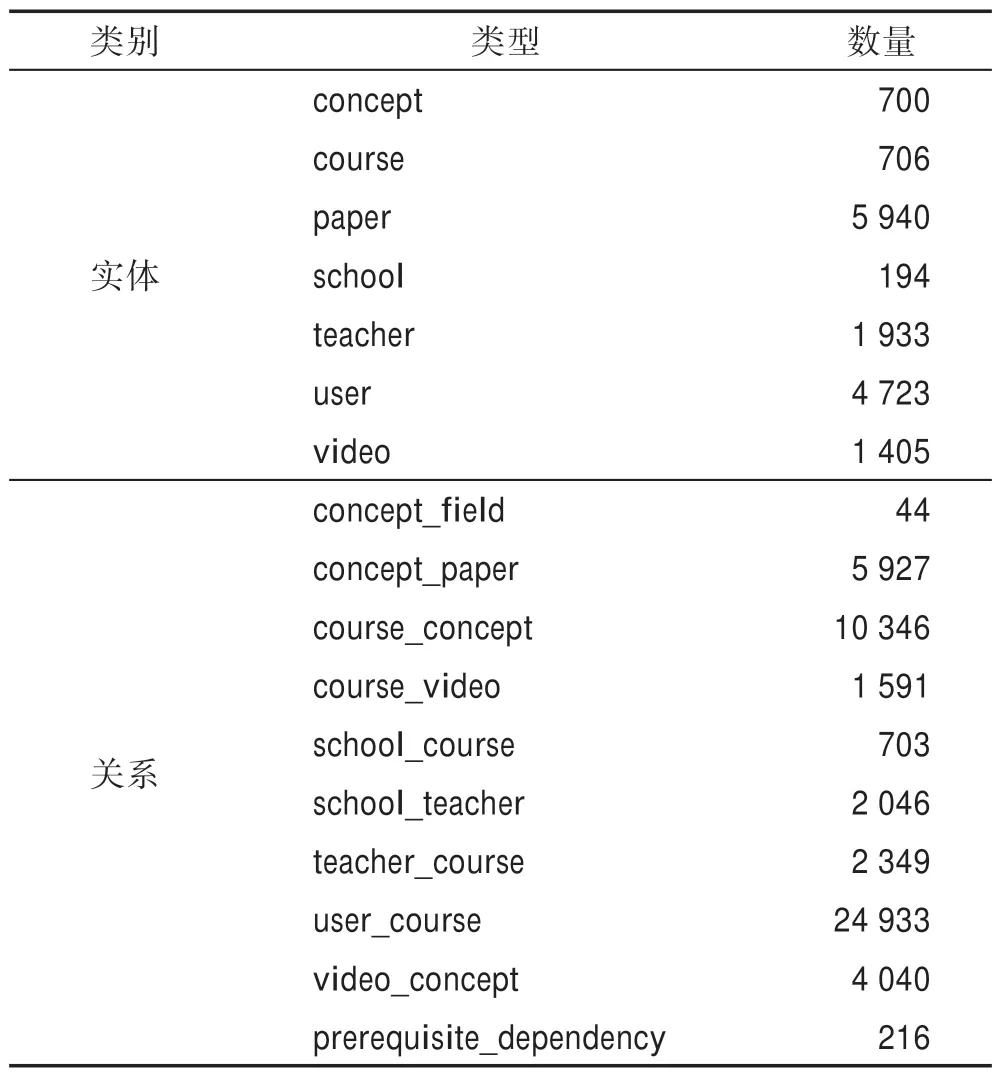
Table 1 Statistics of entities and relations in knowledge base of MOOC Q&A表1 MOOC Q&A 知识库中实体和关系的统计
3.2 实验参数设置
在进行实验时,本文使用“结巴”分词工具进行问句的分词处理,并使用DistMult方法进行知识库中实体的嵌入,默认嵌入维度为200。针对单跳和多跳问题,邻近子图Gq抽取时阶数h分别设置为1 和2,类似地,图卷积网络的层数也相应设置为1 和2。词语嵌入维度、Transformer 隐藏层维度和图卷积网络的维度都被默认设置为200,且每个前馈网络层都采用ReLU 函数激活,并增加丢弃率为0.1 的Dropout 层以增强模型的泛化性能。在进行训练时,本文使用学习率为0.002 的Adam 算法[20]进行优化,并将最大迭代次数设置为30。
3.3 对比模型与评价指标
为了验证本文模型的有效性,实验对比了当前最优模型EmbedKGQA[12]。该模型将问句视为知识库中关系的单跳或多跳推理过程,进而将知识库问答问题类比为链接预测任务,并通过链接预测的得分函数计算候选实体的得分。实验中分别使用TransE[21]、DistMult[18]、ComplEx[16]和RotatE[22]作为得分函数进行答案预测。
本文选取预测准确率(accuracy,ACC)和平均倒数排名(mean reciprocal rank,MRR)作为性能评价指标。准确率ACC 衡量预测得分最高的实体是否出现在实际答案列表中,MRR 表示答案集中的实体在预测列表中平均倒数排名,它们的计算方式如下:
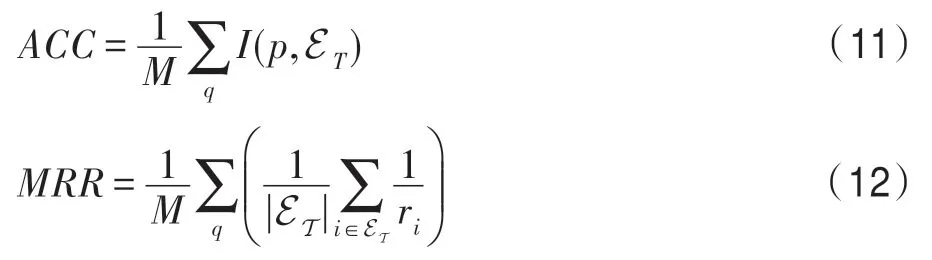
其中,M表示问句数量;ET为问题q的实际答案集合;p为模型预测得分最高的实体;函数I表示元素是否在集合中,其值域为{0,1};ri表示实体i在预测答案列表中的排名。
3.4 实验结果与分析
3.4.1 实验结果对比
本文模型与EmbedKGQA 方法在MOOC Q&A数据集上的性能对比如表2 所示。整体上,可以看出提出的模型在单跳和多跳问答的指标上都取得了优秀的性能。除了多跳的MRR 略小于(0.009)得分函数为ComplEx 的EmbedKGQA,其他指标都优于对比模型,其中相比使用TransE 的提升最大,4 个指标分别提升了0.129、0.120、0.241 和0.210。类似地,对比使用ComplEx 的最优EmbedKGQA,单跳的ACC、MRR 和多跳的ACC 也分别取得了0.011、0.008 和0.004 的提升。这显示出本文模型的有效性。
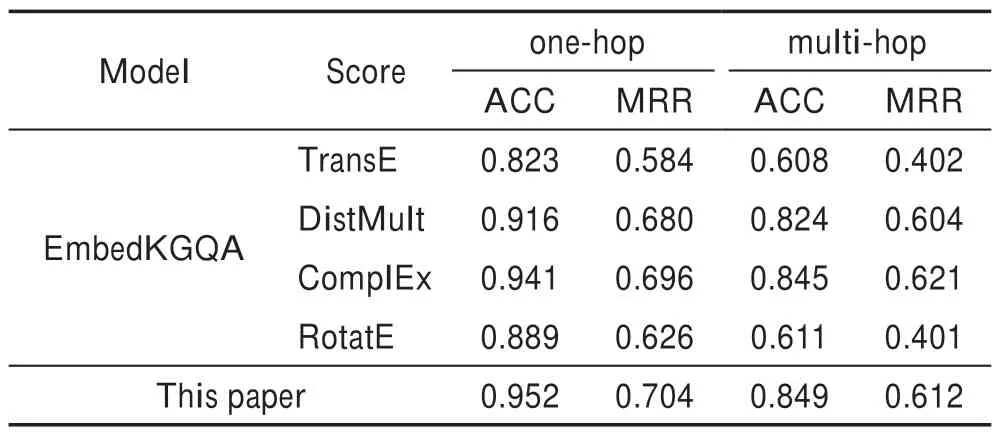
Table 2 Comparison of experimental performance表2 实验性能对比
3.4.2 消融实验
为了验证本文提出的问句感知的双注意力机制对于答案预测的真实作用,本文开展了注意力消融实验。实验结果如表3 所示,表中“注意力1”和“注意力2”分别指式(6)、(7)计算的关于问句描述信息和相应查询实体的注意力。由表3 可知,消融某个或全部注意力得分都会降低实验性能,说明每个注意力对于实验性能的提升都具有积极作用。同时注意力2 的影响略高于注意力1,这从侧面说明在进行图卷积的候选答案建模时,模型会更注重考虑其与查询实体之间的关联。
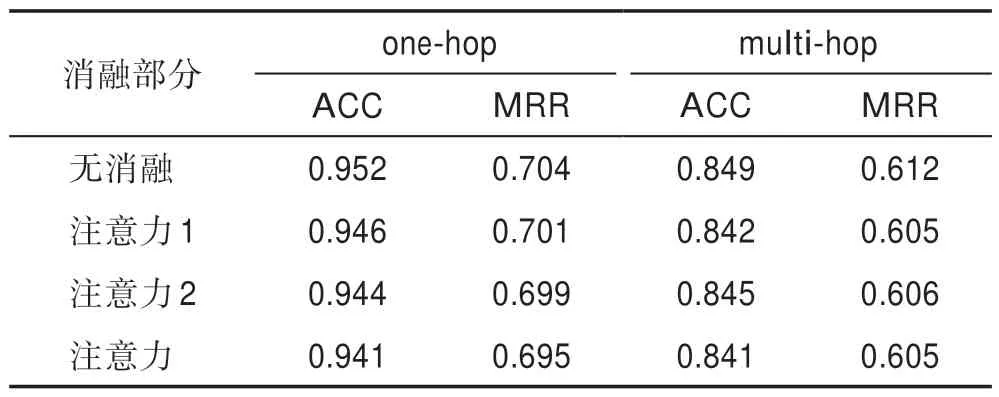
Table 3 Results of ablation experiments表3 消融实验结果
3.4.3 特征初始化的影响
为了探究知识库中实体的初始嵌入矩阵对于问答性能的影响,本文使用不同的初始化嵌入方法进行实验。图2 展示了使用TransE、DistMult、ComplEx和RotatE 时模型的性能对比。由此可知,初始化嵌入方法对模型整体的影响较小,模型在每种嵌入方法上都能取得良好的性能。
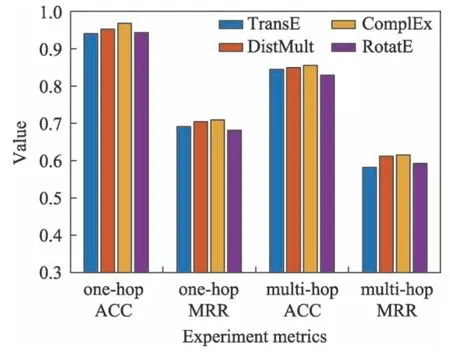
Fig.2 Impact of initialization embedding method on Q&A performance图2 初始化嵌入方法对问答性能的影响
3.4.4 特征维度的影响
为了探究嵌入维度对实验性能的影响,本文在区间[100,500]上以100 为步长进行了分组实验。在实验时,词语嵌入维度、Transformer 隐藏层维度和图卷积网络的维度都被统一设置,实验结果如图3 所示。可以看出,当嵌入维度小于200 时,嵌入维度的增加会略微提升模型性能;当维度大于200 时,其对于模型的影响较小,模型的性能趋于稳定。
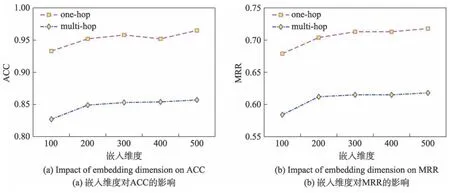
Fig.3 Impact of embedding dimension on performance图3 嵌入维度对性能的影响
4 结束语
由于开放领域的知识库与教育领域存在差异,且相关方法都相对独立地进行候选实体建模,缺乏与问句的交互,基于此本文提出了基于问句感知图卷积网络,分别使用问句中的相关描述信息和查询实体集计算图卷积信息传递时的注意力得分,进而能够学习到特定于问句的实体表示。实验结果表明了该方法的有效性,且消融实验证明了提出的两个注意力对于预测性能都具有积极作用。
本文在进行问句建模时,使用了简单的Transformer 进行处理,且并未考虑候选答案实体对其表示的影响。在以后的工作中,将考虑使用大规模预训练语言模型进行更高效的问句建模,并考虑多种信息(如查询实体和候选答案实体)之间的有效融合方式。
