数字图像取证技术研究进展综述
2021-10-11孙建德
郭 欣 孙建德
(1)中国人民大学统计学院,100872,北京; 2)山东师范大学信息科学与工程学院,250358,济南 )
1 引 言
自从发明了成像设备,人们便可记录很多事情发生的瞬间,图像在提供证据和支撑历史纪录等方面得到了越来越广泛的应用,例如:新闻报道、刑事调查、法庭辩护等方面,因此,照片的真实性至关重要.然而,随着图像处理软件、程序方法的快速发展,图像的处理变得越来越简单且多样化,出现了大量的伪造图像.
在图像处理技术尚没高度发达的时候,人们对数字图像的篡改大多是通过图像的复制-移动、剪切-拼接等操作来进行,这些操作也会产生人眼无法识别的篡改图像.近几年来,随着AI(Artifical Intelligence)技术的飞速发展,图像篡改的技术越来越高超,可以由噪声生成不存在的图像,也可以根据自己想要的效果对图像的某个部位进行伪造,出现了越来越多的篡改图像.2017年,“Deepfake”(深度换脸技术)一词风行全球,并取得了非常逼真的效果,给政治界、娱乐圈以及人们的日常生活带来了很大的影响.如图1所示,“Deepfake”把希拉里·克林顿换成了美国总统特朗普的样子,并且可以完美地实现动态视频中的“表情变化”.在图像生成方面,生成的图像质量也越来越高.2018年,Huang H等人[1]提出了IntroVAE模型,能够生成1 024×1 024高分辨率的自然图像;2018年,Deep Mind公司[2]提出了基于ImageNet的BigGANs模型生成高分辨率、逼真的自然图像(如图2所示),可以生成非常清晰的多种类图像.由此可见,图像的篡改技术越来越高明,由起初对图像的小修小改到现在输入噪音生成不存在的图像或视频,给人们研究图像的真实性带来了更大的挑战.

图1 Deepfake 伪造的视频截图

图2 BigCANs生成的图像
为了应对上述问题,数字图像取证技术成为研究的热点问题,是检测图像是否被篡改的主要方法[3-5].数字图像取证技术可以分析数字图像的某些特性,因此可以用于识别、鉴定数字图像是否被篡改,保证数字图像内容的完整性、真实性和原始性[6].研究人员通过提取图像的各类统计特征,或者是相机的一些成像函数特征,将自然图像和篡改图像进行区分,实现篡改图像的检测.这种传统的图像取证技术能够实现的精度比较高,但是产生了高计算成本以及人工操作的成本.随着深度学习方法的发展,研究人员将卷积神经网络(CNN,Convolution Neural Networks)用于图像取证技术,能够提取图像更多的特征,高效地完成伪造检测.
本文致力于数字图像取证技术的研究,将对数字图像取证技术做出介绍,并从传统图像取证技术和基于深度学习的图像取证技术两个方向对近几年来图像被动取证方面的主要进展做出综述,对经典的图像取证方法进行分析研究,概括现在图像取证技术依然存在的挑战,预测未来图像取证技术可能的发展方向.
2 数字图像取证技术的定义
数字图像取证技术(Digital Image Forensics),是通过对图像统计特性的分析来判断图像内容的真实性、完整性和原始性,也就是判断数字图像从被数码相机拍摄以后有没有经过篡改的技术[7].它的出发点是通过提取数字图像周期中留下的固有痕迹进行分析,判断数字图像的操作历史.数字图像取证技术用来检测数字图像的真实性,根据主要的解决思路,可以分为主动取证技术和被动取证技术[8].
主动取证技术是将识别的信息嵌入到数字图像中,然后再提取识别信息,将提取出的信息与原先嵌入的信息进行比较,从而鉴别图像是否真实和完整,如数字水印技术(Digital Watermarking),是事先在图像的空域或者频域中嵌入易碎的水印信息,图像经过传输后再提取水印信息,通过判断水印信息是否完整来判断图像是否被篡改[7].
被动取证技术,又称为盲取证技术,不需要图像的先验信息,也不需要发送端对图像进行操作,仅仅利用接收到的图像来判断其真实性或完整性.被动取证技术认为,尽管人眼无法识别出图像伪造的痕迹,但是图像的基本统计特性和一致性会被篡改操作影响,引起自然图像各种形式的不一致性.因此,可以利用这些不一致性,通过学习分析识别图像的篡改痕迹以及对这些篡改进行定位.
对伪造的数字图像进行被动检测可以看成一个二分类问题,将被检测的图像分为两类:真实图像或伪造图像.盲取证过程(如图3所示)可以由以下几个步骤组成:
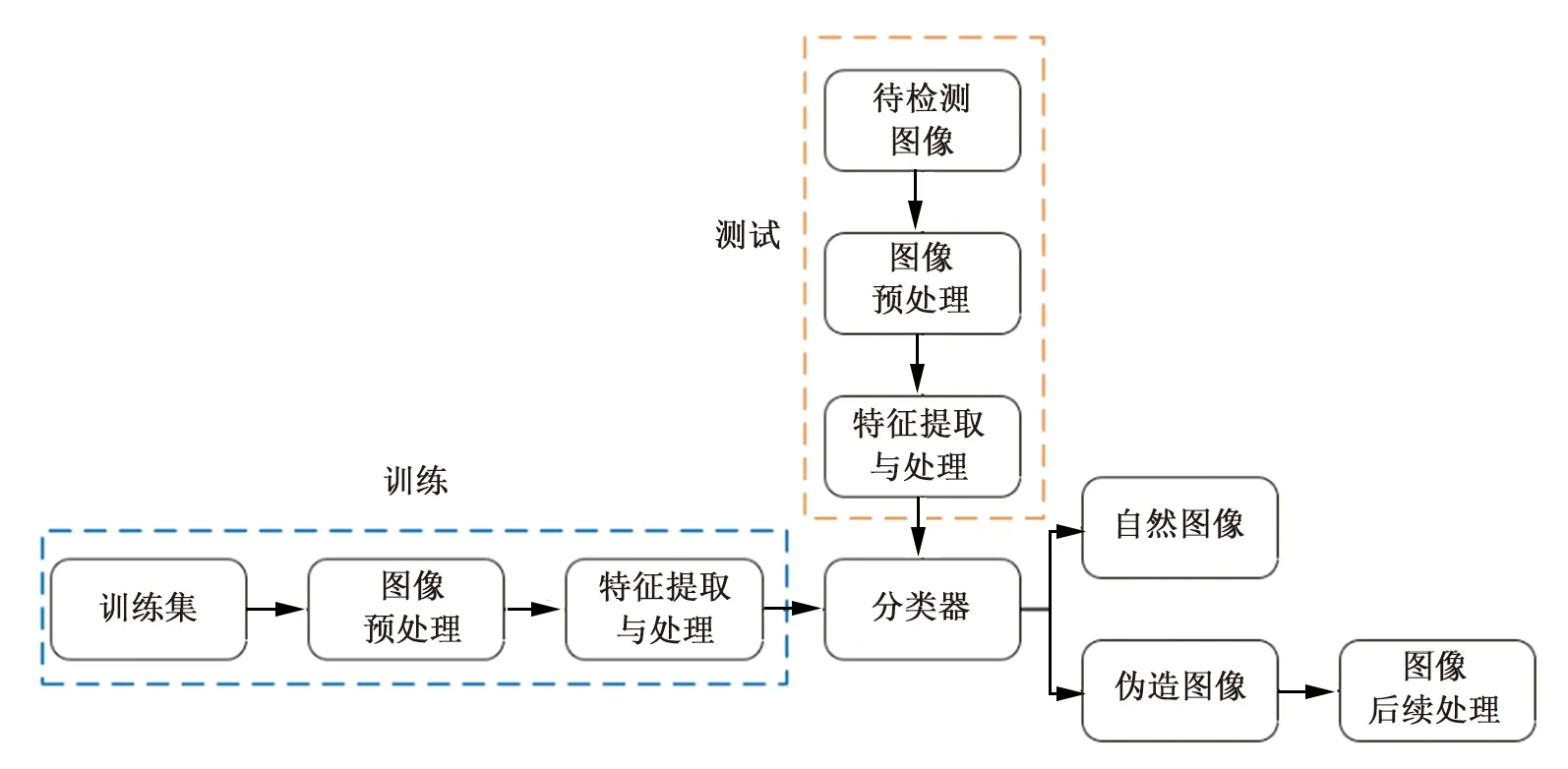
图3 被动取证技术过程图
1) 图像预处理:对图像进行一些预处理操作提高检测的准确率,如,灰度图转换、离散余弦变换等,这一步不是必须的操作.
2) 特征提取与处理:对(处理后)图像进行特征提取,对原始图像和篡改后的图像分别提取特征,提取的特征要对篡改操作非常敏感且能够有效地区分原始图像和伪造图像.如果提取的特征维度较大,可以对特征进行降维处理,这样可以在准确率高的同时达到降低计算成本的目的.
3) 训练分类器:利用处理好的特征,可以对分类器进行训练.
4) 分类与后处理:将要检测的图像,也像训练图像一样执行1)、2)步操作,然后将得到的特征输入到分类器中,判断图像是自然图像还是伪造图像,根据判断结果可以对图像进行一些后续处理,如,篡改定位等操作.
3 基于内在一致性的传统图像取证技术
基于内在一致性的传统数字图像取证技术主要是对图像提取不同的特征,然后用这些特征训练分类模型,实现对被检测图像的分类.常常被考虑到的内在一致性主要包含:光学规律的一致性、传感器规律一致性、图像篡改时的痕迹所做以及统计特征的一致性.
3.1光学规律一致性数字图像取证技术利用光学规律主要体现在利用光照的一致性或图像的色差来完成.对一张图像进行修改后,很难准确地匹配原始图像的光照条件,图4是由电影明星Cher和Brad Pitt的两张个人图像合成的图像[9],Cher拍照时的光源方向是不确定的,而Pitt拍照时的光源方向位于他的左侧,由此可以判断这是一幅伪造图像.因此,光照的不一致性可以成为检测图像是否被篡改的工具.

图4 电影明星Cher和Brad Pitt的合成图像
近年来,有很多检测工作是利用光源的方向进行的.Micah K Johnson等人[9]认为,只要能够估计出一幅图像中不同的人或者物体的光源方向,则可以根据光源一致性来判断该图像是否为伪造图像.因此,他们提出了一种使用单张图像估计光源方向的方法,在P Nillius等人[10]提出的对于光源方向自动预测的模型的基础上,将模型的一些必须假设放宽松,对物体对光线的反射进行分析,并且添加了周围环境因素对于光线的影响,提出了更一般的光源方向预测模型.同时,他们考虑了3-D光源与2-D光源、整体光源与局部光源的情况,取得了不错的实验效果.这个方法可以适用于任何图像确定其光源方向,但是只能在一定模糊度内确定光源的方向.
Micah K Johnson等人[11]在另一个工作中提出,场景中的光源会在眼睛上产生高光,可以借助眼睛中高光的位置判断光源的3-D方向.高光的位置由光源、反射面以及观察者(或相机)的相对位置决定的.当观察者的方向为高光能被看到的方向时,可以从眼睛高光处的表面反射法线和观察者的方向估计出光源的方向.判断出光源的方向后,就可以用来检测图像是否是伪造图像.由于这个方法是从眼睛中高光来判断光源方向的,因此只能用于眼睛分辨率比较高的图像,存在一定的局限性.
上面这两种方法对单一光源为主的图像判断非常有效,但是不适用于包含多个光源或非定向照明的复杂照明环境(如阴天的天空).Micah K Johnson等人[12]提出了在复杂的照明环境中使用光照不一致性检测篡改的方法.基于照明是远距离的、拍摄场景中的表面是凸的、表面的反射率是恒定的以及相机的响应是线性的假设,他们利用Ravi Ramamoorthi等人[13]的工作,将复杂的光照环境进化成一个低维模型(9-D),并且刻画了如何从单个图像估计模型中参数的方法以及如何简化成5-D模型.然而,不同的光照环境有时会产生近似的模型系数,此时,模型无法区分光照差异.
除了利用光源方向,图像的色差也可用于检测伪造图像.横向色差在一阶近似下表示为彩色通道相对于其它通道的膨胀/收缩,在对图像进行篡改时,横向色差经常受到干扰,不能保持一致性.Micah K Johnson等人[14]分析了色差产生的原因,并对色差的产生建立模型,同时考虑了1-D成像系统和2-D成像系统,然后利用最大化颜色通道之间的相互信息算法对色差进行估计,使用估计得到的色差计算其一致性,对伪造图像进行检测.
3.2传感器规律一致性基于传感器特性的数字图像取证技术主要检测相机模式噪声的存在.相机模式噪声是成像传感器中的一个随机特征,而在伪造的图像区域是没有这种模式噪声的,并且对于被抑制的噪声缺少合理的解释,因此,相机的模式噪声可以用来检测伪造图像.
Jan Lukáš等人[15]在假设拍摄图像的相机可用或由该相机拍摄的其它图像可以获得的情况下,提出了基于相机模式噪声的伪造数字图像检测方法.他们主要回顾了模式噪声的特性和近似求解方法,对于给定的相机,通过对由此相机拍摄的多幅图像求平均得到相机的模式噪声参考值.对于给定的检测图像,为了确定其选中区域是否与相机模式噪声兼容,首先计算该区域的噪声残差与相机参考模式的相关性,在相关性超过阈值时,说明该区域是被篡改的.除此之外,他们还介绍了一种伪造区域的自动识别算法,伪造区域被确定为一幅图像中模式噪声最低的区域.通过在一幅图像中滑动一组不同的基本形状,计算每个形状之间噪声的相关性,积累最低的相关值,判断伪造区域.这个方法适用于任何的伪造方法,但是也存在一定的局限性,因为它要求能够有和检测图像同相机拍摄的照片.
Chen Mo等人[16]提出了一个统一的框架,用于从图像中识别源数码相机,并使用光响应非均匀噪声(PRNU,Photo Response Non-uniformity)来显示经过处理的图像.从传感器输出的简化模型出发,利用最大似然原理,估计PRNU,然后通过检测所研究图像的特定区域中的传感器PRNU的存在来实现识别源数码相机以及检测伪造两个取证任务.检测被公式化为假设检验问题,是使用小图像块的测试统计的预测器获得最佳测试统计的统计分布.此方法是在Jan Lukáš等人的工作[15]的基础上提出来的,能够使用更少的数据获得更准确度估计.
3.3图像篡改痕迹或生成痕迹人们对图像进行篡改时,通常会留下各种人眼不可见的内在篡改痕迹,因此,有很多研究工作通过检测这些痕迹对图像进行篡改检测.通常这类篡改检测方法包括对解码、白平衡以及伽马校正的检测.当图像成像时,也会有很多相机产生的痕迹,如果对图像进行篡改,这些痕迹是不存在的或者比较弱,因此也可使用这些痕迹对伪造图像 进行检测.
基于这样一个事实,即通常一个图像的篡改操作会以一种可测量的方式改变相机颜色滤波阵列(CFA,Color Filter Array)的解码工件,缺少CFA工件或检测到较弱的CFA工件可能表明存在全局或局部篡改.Ahmet EmirDirik等人[17]提出了一种基于CFA解码的篡改检测技术,通过对CFA模式数估计和CFA噪声的分析,将计算出来的结果与一个经验阈值进行比较,确定图像是否被篡改.
Ashwin Swaminathan等人[18]提出了一种基于内在指纹的图像取证技术,内在指纹是指各种图像处理操作,包括内部和外部采集设备,在数字图像上留下的痕迹.他们通过对相机模型及其组成分析,估计出各种相机内处理操作的内在指纹.将相机捕获的图像进一步处理建模为操作滤波器,采用盲反卷积技术获得线性时不变估计,并估计与这些后置相机操作相关的内在指纹.通过对被检测的图像进行分析,与相机施加的指纹出现变化或者不一致,或出现了新的类型的指纹,表明图像经过了篡改.
大多数数码相机使用一个传感器和一个颜色滤波阵列,然后插值缺失的颜色样本,得到一个三通倒的彩色图像.这种插值引入了特定的相关性,当对图像进行篡改时,这些相关性很可能被破坏.Alin C Popescu and Hany Farid[19]量化了CFA插值引入的特定关联,并通过构建算法能够在图像的任何部分自动检测到这些关联,如果一幅图像被检测到缺失这些关联,则是被篡改的图像.
3.4统计特征一致性篡改图像和原始图像的统计特征是存在差异的,基于统计特征的图像取证技术是对两种不同的图像进行特征提取,然后用提取到的特征训练分类器,对测试图像进行检测.
Wang Wei等人[20]提出了一种从图像的色度通道进行边缘信息的提取,建模为一个有限状态的马尔可夫链,从马尔可夫链的平稳分布中提取低维特征向量用于图像篡改检测.首先通过一个掩模与图像的色度分量进行卷积得到此色度分量的边缘图像,然后对此边缘图像进行阈值化,得到阈值化后的边缘图像.由于此图像的像素值为0-T之间的整数,因此可以建模为有限状态的马尔可夫链,随后用一步转移概率矩阵来表征此图像,通过对转移概率矩阵进行操作,得到马尔可夫链的平稳分布,作为特征向量.然后用这些特征向量训练SVM(Support Vector Machines),进行篡改检测.该方法的优点是提取了低维的特征向量,降低了计算复杂度.
Hsu Yufeng和Chang Shihfu提出了一种基于图像中不同区域相机特征一致性检测的自动拼接图像检测方法.首先将测试图像分割成不同的区域,利用平面区域辐照度点(LPIPs)的几何不变量,从每个区域中估计一个相机响应函数(CRF),计算CRF交叉拟合分数和区域强度特征,训练SVM分类器,用来确定两个区域之间的边界划分是否为真实的或者拼接的,进而判断整个图像是否是被篡改的[21].
Hsu Yufeng等人[22]提出了一个基于判别随机场(DRF,Discriminative Random Fields)的统计融合框架来集成适合于篡改检测的多个线索的图像取证方法.进行线索融合检测篡改图像主要有两方面的优势:处理不同类型的篡改图像以及通过不同模块的分工合作提高检测精度.现有的检测方法主要基于检测的输出分为局部真实性检测和空间不一致性检测.本文以双量化(DQ,Double Quantization)作为局部真实性检测的线索,以相机响应函数(CRF,Camera Response Function)作为相邻区域一致性检测的线索,将两个线索的融合看成标注问题,利用DRF进行融合.将图像划分为一个个8×8的块,然后将这些块随机划分为不同的区域,对每一个块计算其DQ得分,对每个区域中的块之间计算CRF一致性得分,对不同区域的块之间计算CRF一致性得分,通过DRF计算其最大后验概率,来估计其相应的标签,判断是否被篡改.
Kaur等人[23]提出了一种无源混合方法检测复制-移动和拼接进行的图像伪造.该方法基于离散分数余弦变换(DFCT,Discrete Fractional Cosine Transform)和局部二值模式(LBP,Local Binary Patterns)实现.其中,离散分数余弦变换的分数参数可以提高检测的精度,局部二值模式可以有效地突出伪影.同时,利用支持向量机(SVM)对图像进行分类,分为真实图像、复制移动图像和拼接图像.接下来,对复制移动图像和拼接图像进行定位,定位图像中的篡改区域.
Shah等人[24]致力于图像复制-移动伪造检测,提出一种有效的检测方法.该方法首先将离散小波变换应用于输入图像,所得到的最低频率近似子带被分割成具有固定大小的重叠小块,滑动因子为一个像素.然后计算每个固定大小块的二维离散余弦变换,然后通过Zigzag扫描存储为单行向量,用于伪造检测.混合变换和快速K-means聚类技术的使用有助于提高处理速度,减少整体伪造检测时间.
4 基于深度学习的图像取证技术
随着深度学习的兴起,图像取证方向的研究人员也将目光转移到深度学习的方法上[25-28].基于深度学习的图像取证技术与上文中描述的传统的图像取证技术不同,类似于其它基于深度学习算法的任务,将图像的特征提取的分类结合在一起,构造一个统一的网络,实现了end-to-end的图像取证技术.同时,也有研究者将深度网络与信息论相结合完成图像取证工作[29-30].基于深度学习的图像取证领域的研究工作主要涉及到了三个方面:一是简单的迁移;二是对网络输入进行修改;三是对网络结构进行修改.
4.1简单的迁移由于图像取证问题可以看成是分类问题,因此可以将已经在计算机视觉领域经常用于分类的卷积神经网络(CNN)结构直接应用于图像取证领域,这可以看成是对卷积神经网络在图像取证问题上的简单迁移.相机源取证是可以解决图像取证的一个关键思路,判断出图像是否符合某种相机拍摄的特点,就可以确定图像是哪款相机拍摄的,进而判断其是否被伪造.在传统的方法中,已经有根据不同相机在管道中留下的特征轨迹对图像的相机源进行取证.Luca Baroffio等人[31]首次提出将卷积神经网络用于判断图像相机源问题,与传统的相机源取证方法不同,该方法直接从每个相机拍摄的大量图片中学习每个相机的特征,利用学习到的特征对测试图像进行分类.他们提出的网络结构使用了三个卷积层和两个全连接层,包含了滤波、池化和非线性激活等一系列简单的操作,对于27种相机模型的识别准确率均大于94%.
4.2对网络输入进行修改虽然图像取证问题可以看成是分类问题,但是它和分类问题是有区别的.由于造假技术越来越高超,真伪图像之间的差异越来越小,多数情况下是人眼无法识别的,如图5所示,BBC新闻上报道的伊朗导弹图片中显示了四枚,但实际上只有三枚导弹是真的,其中一枚是通过其它导弹复制移动过去的,这是人眼无法识别的[32].而对于计算机视觉领域的分类问题,类别之间的差异还是比较明显的,多数情况下是人眼可以识别的.因此,研究人员将计算机视觉领域中用于分类任务的深度学习模型迁移到图像取证领域时,通常在模型之前对网络的输入进行处理,以达到放大类间差异的效果.
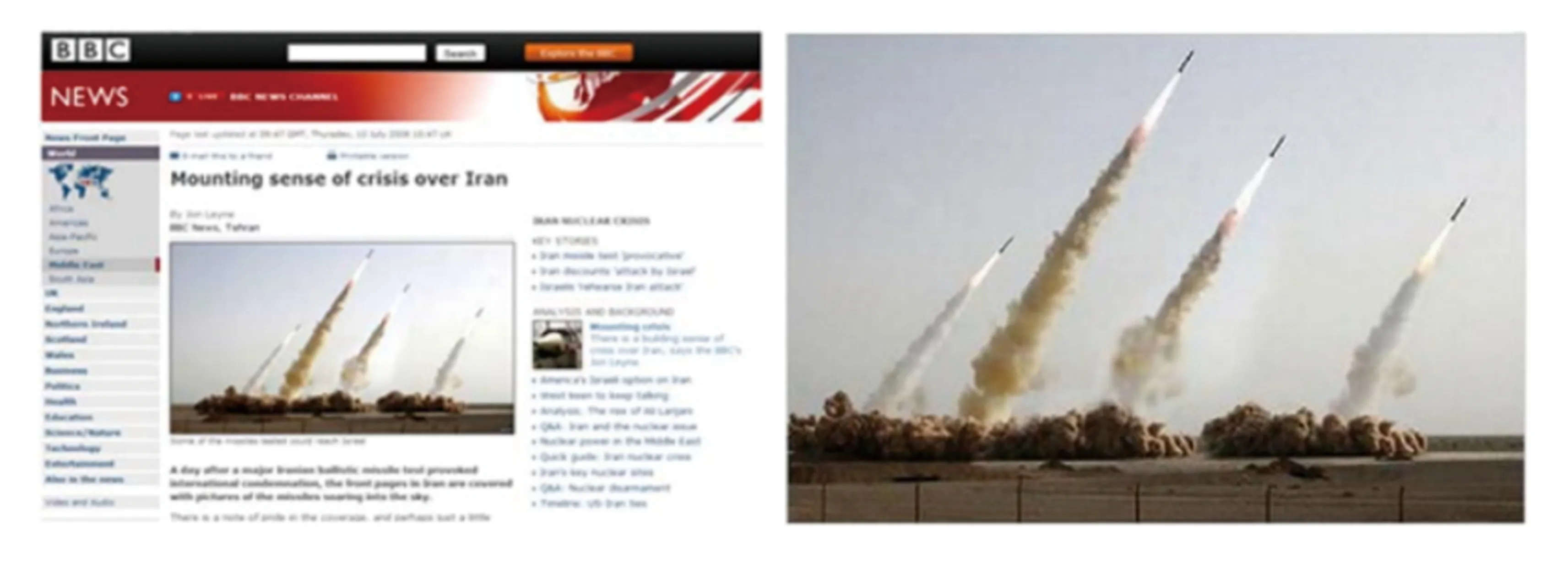
图5 伊朗导弹伪造图片
Chen Jiansheng和Kang Xiangui等人[37]提出的基于卷积神经网络的中值滤波取证模型,与传统的CNN模型不同,这个CNN框架的第一层为滤波层,将图像作为输入,然后输出其中值滤波残差(MFR,Median Fitering Residuals),通过这步预处理操作,图像内容被去掉,同时图像噪声信号也被放大.然后,通过卷积层和池化层学习图像噪声的特征表示,最后对图像进行分类.实验结果显示,该文章中的取证模型取得了显著的性能改进,特别是在复制粘贴伪造检测方面.通过对比实验,添加了滤波层的模型,检测结果优于未添加滤波层的模型7.22%.
Paolo Rota等人[34]认为,为了能够直接从数据中学习到原始图像和篡改图像的特征,需要一组一致的标记图像,而很多篡改图像只是图像中的小部分被篡改,图像的其它内容会对其特征提取产生影响.因此,他们提出了一种基于补丁(Patch)的卷积神经网络模型去检测篡改图像,对于篡改的图像,从篡改区域的边界提取Patch,对于真实图像,从图像中随机抽选Patch,使用提出的Patch学习特征训练网络.这种方法不仅使学习到的特征更加精确,而且还能达到扩充数据集的效果.
Luca Bondi等人[35]基于不同相机模型在图像上留下不同的特征痕迹,利用图像补丁的方法训练CNN模型,进行篡改检测.如果图像是原始图像,则所有像素都应该被检测为一个设备的痕迹,如果图像是伪造的,则可以检测到多个设备的痕迹.通过CNN模型学习特征后,利用迭代聚类技术对这些特征进行分析,检测图像是否伪造.
4.3对网络结构进行修改通过4.2节的分析,可以看出取证问题与分类问题存在一定的差异,很多研究人员也意识到了这些差异,有关学者尝试对深度学习中的模型进行修改,结合图像取证的实际问题提出相应的网络模型.
Belhassen Bayar等人[36]提出了一种使用深度学习模型检测篡改图像的方法,使用一种新的卷积神经网络结构,直接从大量的训练数据中自动学习不同操作的不同特性.与以往的学习图像内容特征的卷积网络不同,在新的模型中,他们开发了一种新的卷积层,用来抑制图像内容对检测的影响,并且能够自适应地学习篡改操作的特性,而不需要预先选择特征或其它的预处理.通过对图像内容的抑制,对于图像的篡改检测准确率能达到99.10%.
Peng Zhou等人[37]提出了一种双流的Faster Region-CNN网络,可以学习更丰富的特征,实现端到端的训练.两个特征流之一是RGB流,其目的是从RGB图像输入中提取特征,以发现篡改痕迹,如强度对比差异、非自然篡改边界等;另一个特征流是噪声流,利用隐写分析模型中提出的SRM滤波层提取原始图像和篡改图像的噪声特征.然后,通过一个双线性池化层融合这两种特征,进一步合并这两种特征的空间共现.两种特征融合在一起进行篡改检测,提高了准确率,不仅能够检测篡改痕迹,还能够区分各种篡改技术.
DariusAfchar等人[38]提出了一种自动有效检测视频中人脸伪造的方法,主要是针对目前伪造视频的两种新技术:Deppfake和Face2Face.他们提出了两种不同的MesoNet模型,网络结构主要由卷积层、最大池化层以及全连接层组成,能够很好地学习图像的细观特性,在Deppfake数据集上能够达到98%的检测准确率,在Face2Face数据集上能够达到95%准确率.
Liu等人[39]的研究不同于以往经典的检测篡改解决方案,提出一种新型端到端生成对抗网络(CD-GAN)解决图像的复制-移动伪造检测问题.该模型不需要具体的提取特征,只需要真实图像的样本和伪造图像的样本输入网络进行训练.与传统的基于卷积神经网络的伪造检测方法对比,该网络的检测精度大大提高.
Elaskily等人[40]提出了一种检测图像是否有复制-移动篡改的深度网络模型(CMFD).该模型的主要结构为卷积神经网络(CNN)和卷积长短时记忆网络(CovLSTM).该方法通过卷积(Convolutions, CNVs)层、ConvLSTM层和pooling层提取图像特征,然后进行特征匹配,检测复制移动伪造.
5 展 望
由于深度学习的快速发展以及良好效果的取得,图像伪造效果也越来越好,人们也慢慢地把目光转移到对视频进行篡改.因此,在对图像取证提高准确率的同时,对视频的取证也是一个有待解决的问题.传统的图像取证技术虽然能够取得不错的效果,但是需要人工操作的地方比较多,而深度学习的取证方法能够实现端到端的效果,并且是自动提取特征,不需要过多的人工干预,在数据集充足的情况下,也能取得很好的效果.基于深度学习的取证技术也是未来的主流研究方向,将传统方法和深度方法进行结合能否取得更好的效果,也是一个值得讨论的问题.
6 结 语
本文主要介绍了数字图像取证技术,并对传统的数字图像取证技术和基于深度学习方法的取证技术分类概述.在传统的数字图像取证方面,本文重点概述了基于光照统一性、传感器规律统一性、图像篡改痕迹或成像痕迹以及统计特征四个方面的经典方法;在深度学习用于图像取证方面,本文重点从简单的模型迁移、对网络输入层的修改以及对网络结构的修改三个方面进行介绍.由于篡改技术越来越高超,对视频的篡改检测也是取证领域面临的一大挑战.深度学习在计算机视觉领域取得了重大进展和良好的效果,基于深度学习的图像取证方法将是主要的研究方向.
