大数据视域下大学生就业创业平台的构建
2021-09-26宿迁学院马红丽咸聪慧蒋子豪丁钱建朱芷娴
宿迁学院 马红丽 咸聪慧 蒋子豪 丁钱建 朱芷娴
大学生就业问题一直饱受社会各界的关注,近几年随着毕业生数量的增加,企业招聘要求的提高,毕业生的处境越来越窘迫,企业招聘也越来越困难。为了改善毕业生就业难和企业招聘难的问题,该平台结合大数据技术和智能推荐算法,旨在为学生和企业提供集精准职位推荐、精准人才推荐、创业指导、就业指导于一体的服务模式。实践表明,平台在校企合作的模式下,提供就业信息,既有利于毕业生快速精确就业,也能够提高企业招聘的人才对口率,同时还能将毕业生的市场需求反作用于学校的招生工作中。
在当今时代的大背景下,由于高等教育大众化、普及化进程的加快,我国大学生的就业问题也呈现出愈演愈烈的趋势,已经成为目前亟待解决的民生问题。一方面,由于毕业生数量的不断增长致使人才市场供应大于需求。另一方面,由于社会经济的高速发展,企业对人才质量和类别的需求也在不断提高和变化,这就在企业和高校毕业生之间产生了需求的鸿沟。因此大数据视域下大学生就业创业平台的构建十分必要,以学校为平台基础,直接为企业和毕业生搭建供求链来实现大学生精准就业具有重要的现实意义。
本文实现目标是构建一个大数据技术和智能推荐算法相结合的人职双向推荐平台,采用“校企合作”的核心内推体系,凭借学校与企业之间的合作关系,给予就业者适当的就业指导及推荐,提高了就业率以及人才对口率。
1 平台分析
1.1 构建目标
在平台的设计过程中考虑到毕业生用户、学校和用人单位三类用户的不同角色之间的需要的功能,利用信息共享,使各类用户在系统中的作用发挥到最大化。
通过对校友信息进行选择提取和智能分析,结合学校具体专业特点,联合企业,即时公开招聘信息,双向智能地帮助学生找到心仪的工作,同时助推高校、毕业生、企业的深度合作。有以下两个主要功能:
建立毕业生用户画像,在规范数据标准,同步各业务系统中的标准数据到中心数据库之后,我们可以通过中心数据库抽取数据进行挖掘分析。基于毕业生的简历信息、专业、兴趣爱好以及行为数据进行分析,构建出符合学生需求的行为模式方法,从而有效的推荐职位给毕业生,促进就业。
建立个性化智能推荐服务平台,系统基于协同过滤推荐算法实现人才和职位之间的双向推荐。人才推荐就是依据企业单位具体的招聘需求,给用人单位推荐可能符合要求的专业人才,促使企业能够快速获取人才资源。职位推荐则是依据毕业生个人求职要求,结合与之相似用户的就业信息,给毕业生推荐可能符合学生就业需求的的职位。
1.2 平台架构描述
本平台通过大数据技术,以校企互助为机制,以推荐就业为核心,以解决毕业生的就业问题为根本,为用人单位提供一站式招聘服务,为应聘者提供一站式就业服务。拓宽学生的就业渠道,提升企业招聘的效率,同时帮助学校了解当前就业趋势。
平台运用分层的思想,在持续、动态的数据基础上,并结合前端开发的需求,设计整体的框架,其主要的内容和每层之间的逻辑关系如图1所示。
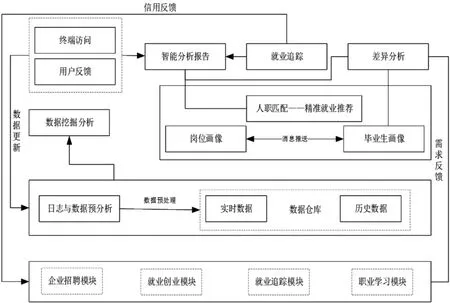
图1 平台整体架构图
该平台是以开源分布式框架为基础的二次开发,具备实时处理大数据和并行式数据处理的能力,具有高并发性和强壮性。平台整体架构分别包含了数据的采集层、挖掘层、分析层和应用层。
数据采集层是整个系统的基础,它不仅是大数据分析的首要前提也是必要的条件之一。只有平台拥有了海量的就业数据信息,才能进行下一步的挖掘,并分析出数据之间某种隐藏的规律。其中采集的数据主要包括往届毕业生就业数据和现阶段用户行为数据如:操作事件、浏览行为、收藏行为、停留时间等操作数据。
数据挖掘层,对采集的就业数灵活地使用K-Means聚类算法、层次聚类、关联规则挖掘等算法,从而发现数据之间隐藏的相关性。
数据分析层,将挖掘到的信息处理后进行知识化信息描述。
数据应用层,主要负责管理和运维数据,系统通过数据仓库中的数据,分别描绘用户画像和职位画像,并通过相似度计算进行人职匹配。只有匹配率达到80%,系统才可以为毕业生用户可能符合其要求的职位,为企业提推荐合适的人才。
2 平台关键技术
2.1 协同过滤推荐算法
在线协同和离线过滤是协同过滤推荐算法的两个部分,其中在线协同是根据在线的数据寻找用户
协同过滤推荐算法包括在线的协同和离线的过滤两部分。在线协同,就是通过在线数据找到符合用户偏好的物品,而离线过滤,则是分离出一些没有价值的数据。预测和推荐是它的主要功能点,算法通过挖掘用户行为的数据来发现用户的喜好,再根据用户喜好对用户进行分组并向用户推荐与其偏好相似的物品。
系统基于前期搜集的毕业生就业信息的数据,建立各类用户的画像模型。系统采用基于用户的协同过滤和基于物品的协同过滤对用户和职位进行双向智能的推荐,基于用户的协同过滤主要分为以下两个步骤:
利用用户求职意向信息,采用欧几里德距离评价公式计算当前用户与其他用户之间的相似度;
通过用户之间的相似度数值,选择与当前用户相似度最高的用户,按照他们的偏好向当前用户推荐其可能会感兴趣的职位。
2.2 Druid架构
Druid架构是一个构建在大数据集之上做实时统计分析的开源数据存储系统,每个Druid流程类型都可以独立配置和扩展,为群集提供最大的灵活性。
Druid集群包含多种节点类型,包括以下5个节点:
(1)实时节点:主要用来实时的摄入数据,并将实时数据生成Segment文件存储到DeepStorage中。
(2)历史节点:负责加载Druid中非实时窗口内且满足加载规则的所有历史数据的Segment。
(3)查询节点:用于分发查询任务和汇集查询结果,并将获得的结果返回给用户。
(4)协调节点:负责管理数据和历史节点的负载均衡,其中包括新数据的加载和过去数据的删除。
(5)索引服务:包含两个组件,Overload组件负责管理和分发索引任务,而MiddleManager则负责执行索引任务。
2.3 画像技术
用户画像技术的根本其实是对现实生活中的用户进行数据建模,它从不同的角度,描述并刻画一个人的形象特点。
平台运用画像技术构建毕业生画像和职位画像,以下是毕业生画像的构建步骤:
数据收集阶段,这一阶段主要对基础数据进行清洗、降噪、标准化处理并存储入库。
行为建模阶段,对数据进行特征提取、确定特征标签权重、选取特征标签,然后建立兴趣标签模型。
画像细化阶段,从标签中提取毕业生的属性,作为毕业生的简单描述,形成一个标签化的人物模型。
3 协同过滤算法的实现
以面向毕业生的求职信息推荐为例,文中将毕业生的求职信息比作用户,将企业单位的岗位比作物品,详细步骤如下:
(1)按照系统设定的特征集(例如:就业意向城市、工资要求、专业方向、停留时间等维度)比对职位画像与毕业生用户画像,计算得到用户评估得分表(本文模拟了5个用户对2个职位的评分),如表1所示。

表1 用户评估得分表
(2)根据表格的数据作出散列点图,在图中,Y轴表示对职位1的评分,X轴表示对职位2的评分,通过用户的分布情况可以发现,A、C、D三个用户距离接近,而用户E和用户B则形成了另一个群体,具体如图2所示。

图2 用户评估散列图
(3)欧式距离n维空间的一般性公式为:

欧几里得计算两个用户间相似度的公式为:
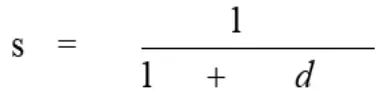
s的取值范围为(0,1],其值越小,用户相似度越小;其值越大,用户相似度也越大。
根据欧几里德公式计算各用户在职位信息评价上的欧式距离和相似度,计算结果如表2所示。

表2 用户之间的欧式距离
协同过滤算法与画像技术的结合,系统实现了毕业生和企业之间的双向推荐功能最大程度满足了企业与毕业生的需求,取得了较好的效果,如图3所示。
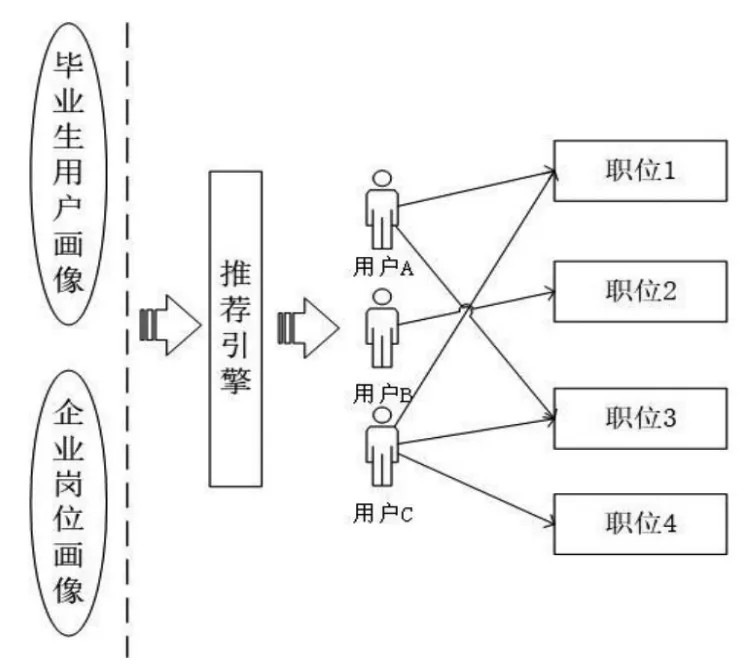
图3 就业智能推荐结果示意图
基于欧式距离推荐Python编写的部分代码如下:


本文介绍了基于大数据技术和智能推荐算法的大学生就业创业平台具体设计,旨在解决学生就业能力和企业招聘要求不匹配、就业信息不对称、专业与职位匹配度低等问题。平台利用往届毕业生的海量就业数据和校企合作的企业招聘数据,在大数据平台下对其进行清洗、挖掘、分析和存储。构建用户、职位的画像,使用协同过滤推荐算法实现个性化的双向精准推荐就业,进一步提高了毕业生的就业率和企业的雇佣效率。平台的构建有不仅有利于企业和毕业生个人,它同时也为学校的学科建设、课程安排等方面提供了积极的参考意义。
