一种基于集成学习策略的单细胞转录组数据集成分类算法
2021-09-22刘桂锋于绍楠
刘桂锋, 于绍楠, 崔 璐
(1. 吉林大学中日联谊医院 放射线科, 长春 130033; 2. 吉林大学中日联谊医院 医疗保险管理部, 长春 130033)
单细胞转录组学在细胞发育分化、 肿瘤浸润免疫细胞的功能状态以及慢性疾病诊疗等领域应用广泛. 近年来, 针对单细胞转录组数据的研究已有许多结果[1]. 但在研究人体器官、 组织各主要发育阶段及慢性疾病状态下各类细胞的内在规律、 相互关系和稳态失衡等复杂细胞分化问题时, 以聚类算法为代表的传统细胞类型识别方法存在准确率较低及结果缺乏合理生物医学解释的缺陷. 因此, 探索高效准确的细胞类型识别算法成为该领域亟待解决的问题之一. 为得到更准确的细胞分类结果, 文献[2]提出了一种半监督聚类算法, 其利用少量已标记的基因信息引导细胞样本的聚类, 但由于少量标记基因的监督能力较弱, 因此该细胞分类方法的准确率有待提高; 文献[3]提出了一种半监督降维辅助细胞分类算法, 该方法将少量标记样本与无标记样本混合以训练自动编码器网络, 实现标记信号的放大和传播, 但由于无标记样本作为训练样本时不可避免地存在误差, 当标记样本较多时其分类性能仍然无法与强分类器相比. 基于此, 本文提出一种基于集成学习策略的单细胞RNA-seq数据分类算法, 该方法能利用不同分类算法各自的优点寻找最佳的细胞类型划分.
1 单细胞RNA-seq集成分类模型
给定一个单细胞RNA-seq基因表达矩阵E∈n×m, 其中包含n个基因、m个细胞样本和样本标签集合Y.设集成分类模型中包含L个分类器, 则对于任一细胞样本x, 有
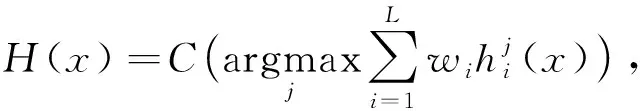
(1)
其中hi(x)表示集成模型中第i个算法为细胞x预测的细胞类型标记,wi表示算法的权重系数,H(x)表示集成模型为细胞x加权投票得到的细胞标记.算法的权重系数wi可根据专家经验设定, 也可通过对数据集进行多次采样训练学习和调整.
2 集成分类模型中的细胞分类算法
本文的集成分类算法选取线性判别分析[4]、k-近邻算法[5]、 分类回归树算法[6]、 朴素Bayes算法[7]以及支持向量机算法[8].线性判别分析方法通过找到不同类型细胞基因特征的线性组合区分细胞类型, 其目标函数[4]为
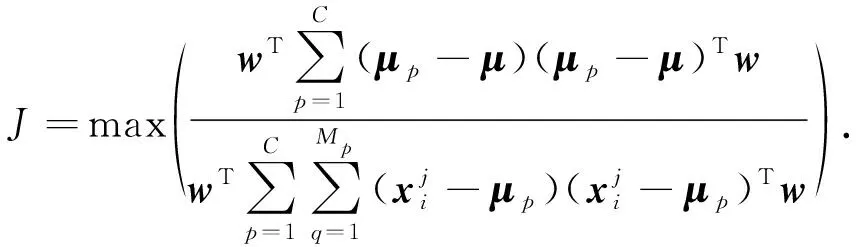
(2)
优化求解得到w后, 将其与细胞xi基因表达向量代入线性函数可求得xi的所属类别.k-近邻算法的分类决策规则为通过细胞i在特征空间中最新的k个细胞类型判断其自身细胞的细胞类型[5]:
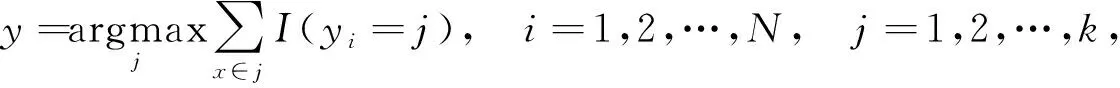
(3)
其中I为指示函数, 当yi=j时I=1, 否则I=0.
分类回归树算法采用决策树模型进行分类, 决策树上各节点应用基尼指数选择特征.设细胞属于第q类的概率为pq, 则概率分布的基尼指数定义[6]为
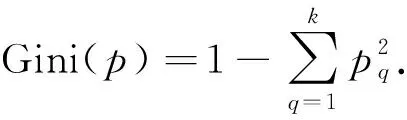
(4)
朴素Bayes算法[7]学习从输入到输出的联合概率分布, 再基于学习到的模型, 输入细胞xi, 求出使后验概率最大的输出yi:
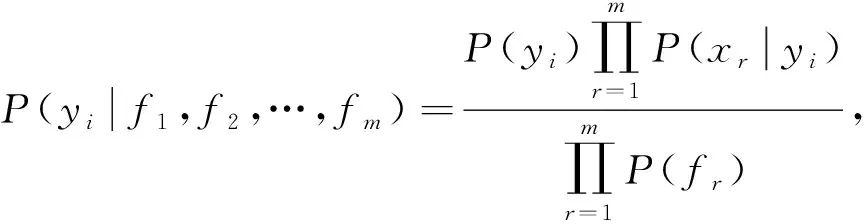
(5)
其中fr为单细胞样本xi在第r个基因上的函数值.
支持向量机算法的分类决策规则为先将细胞表示为核函数映射的高维特征空间中的点, 并寻找尽可能宽的和明显的分类间隔, 对不同细胞类型进行间隔区分; 然后将新的细胞映射到同一空间, 并判断新细胞落在间隔分区的位置预测所属细胞类型yi[8]:

(6)
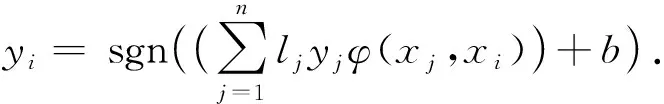
3 实验与分析
为检验集成学习算法的细胞分类能力, 本文首先利用慢性粒细胞白血病(chronic myeloid leukemia, CML)单细胞RNA-seq数据GSE76312[9]进行算法比较和验证, 这些数据来自美国国家生物信息中心(NCBI). 目前, NCBI已收录约51 500条单细胞RNA-seq数据. 本文选择的数据GSE76312等包含5种类型的细胞, 分别是急变期慢性粒细胞白血病细胞(BC-CML)、 慢性期慢性髓性白血病细胞(CP-CML)、 人红白血病细胞系(k562)、 正常造血干细胞(normal)以及前急变期慢性粒细胞白血病细胞(pre-BC)[10]. 选择1 102个不含络氨酸激酶抑制剂的细胞, 这些细胞在5种类别上的分布如图1所示. 由图1可见, 细胞类别分布不均衡, 其中CP-CML约包含500个细胞, 而k562的细胞数则小于50个. 集成学习可利用不同分类算法各自的优点, 减少类别不均衡分布对结果的影响. 本文利用伪发现率和差异倍数选取前234个差异表达基因作为分类特征.
图2为不同分类算法对数据GSE76312的分类准确率比较. 由图2可见, 与线性判别分析、k-近邻算法、 分类回归树算法、 朴素Bayes算法和支持向量机算法相比, 本文提出的集成学习算法准确率最高, 分别比上述各算法高1.8%,10.0%,14.9%,27.0%和1.3%. 实验结果表明, 采用集成学习策略能有效利用不同算法的优点, 提高细胞分类的准确性.
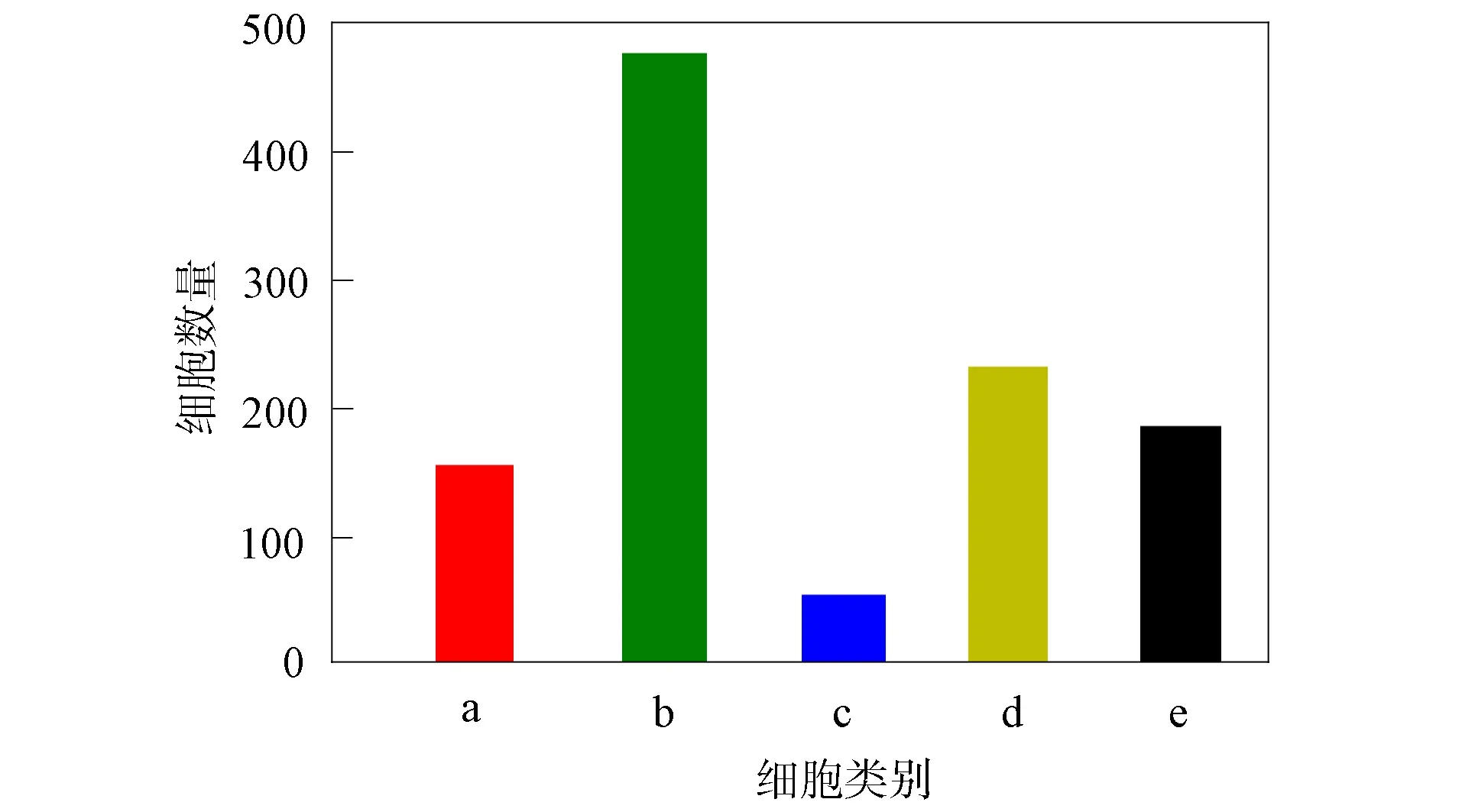
a. BC-CML; b. CP-CML; c. k562;d. normal; e. pre-BC图1 单细胞RNA-seq数据GSE76312的类别分布Fig.1 Category distribution of single cell RNA-seq data GSE76312
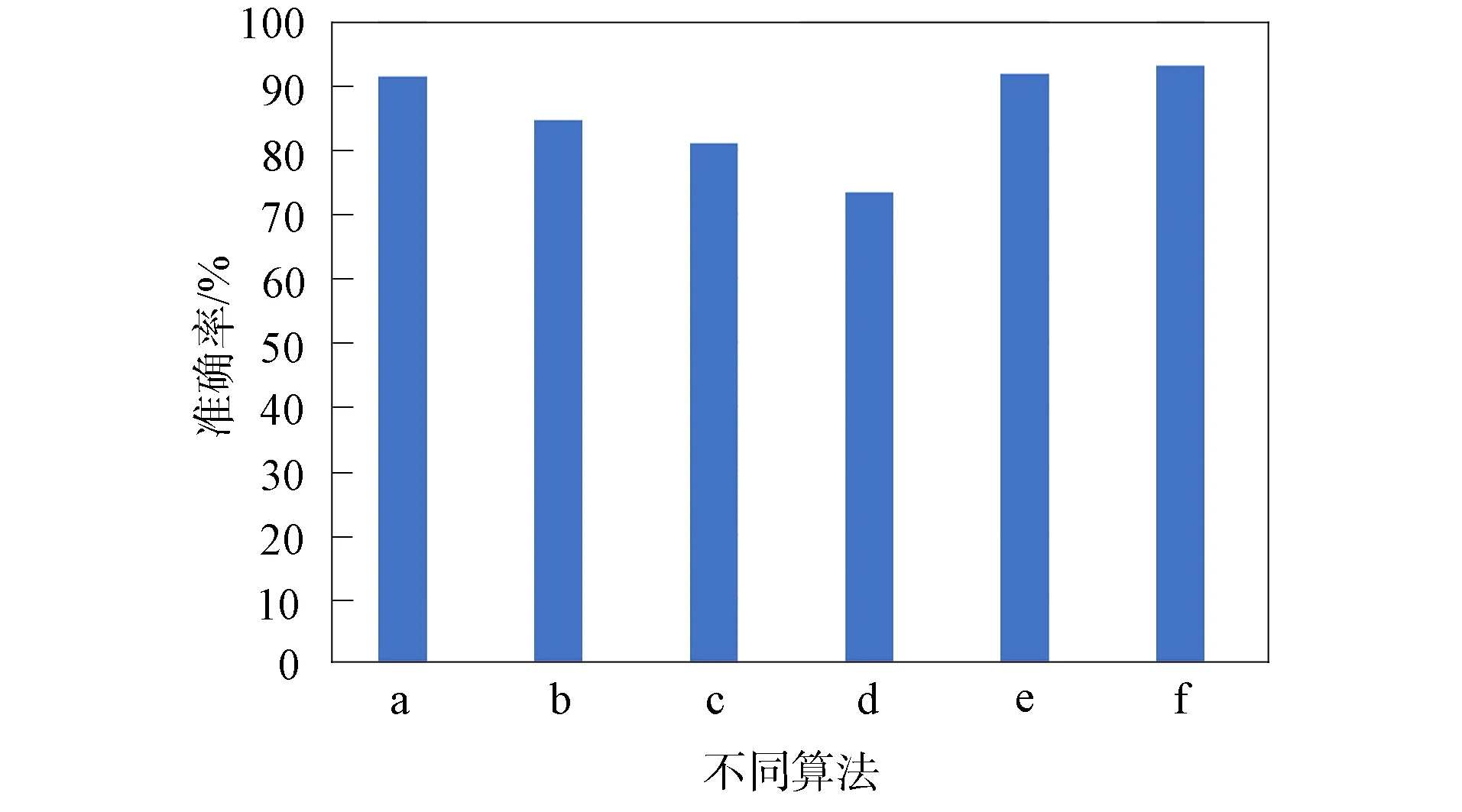
a. 线性判别分析; b. k-近邻算法; c. 分类回归树算法;d. 朴素Bayes算法; e. 支持向量机算法; f. 集成学习算法.图2 不同分类算法对数据GSE76312的分类准确率比较Fig.2 Comparison of classification accuracy of different classification algorithms on data GSE76312
为考察算法的泛化能力, 本文将不同算法应用到三阴性乳腺癌(triple-negative breast cancer, TNBC)单细胞测序数据GSE118390上, 该数据共包含6种类型的细胞, 分别是基细胞、 巨噬细胞、 上皮细胞、 内皮细胞、 T淋巴细胞和B淋巴细胞[11]. 选择1 112个细胞, 这些细胞在6种类别上的分布如图3所示. 由图3可见, 细胞类别分布不均衡, 这种不均衡分布会降低分类算法的性能. 其中上皮细胞包含868个细胞, 而B淋巴细胞数则小于50个. 集成学习能利用不同分类算法各自的优点, 减轻不均衡分布的影响. 本文利用伪发现率和差异倍数选取前56个差异表达基因作为分类特征.
图4为不同分类算法对数据GSE118390的分类准确率比较: 由图4可见, 与线性判别分析、k-近邻算法、 分类回归树算法、 朴素Bayes算法和支持向量机算法相比, 本文提出的集成学习算法准确率最高, 分别比上述各算法高11.2%,1.9%,0.9%,36.3%和10.7%. 实验结果表明, 集成细胞分类算法在三阴性乳腺癌单细胞测序数据上也取得了较好的分类效果.
综上所述, 针对单细胞RNA-seq数据上的细胞分类问题, 本文提出了一种基于集成学习策略的单细胞RNA-seq数据集成分类算法. 首先将单细胞RNA-seq数据的细胞类型识别模型转换为集成学习模型; 然后基于支持向量机、 朴素Bayes算法、 分类回归树算法、k-近邻算法和线性判别分析算法构建了集成细胞分类模型, 对单细胞RNA-seq数据集中的细胞进行精确划分. 分别在慢性粒细胞白血病单细胞测序数据和三阴性乳腺癌细胞测序数据上的实验结果表明, 本文的集成分类算法能取得更高的分类准确率和较好的泛化能力.
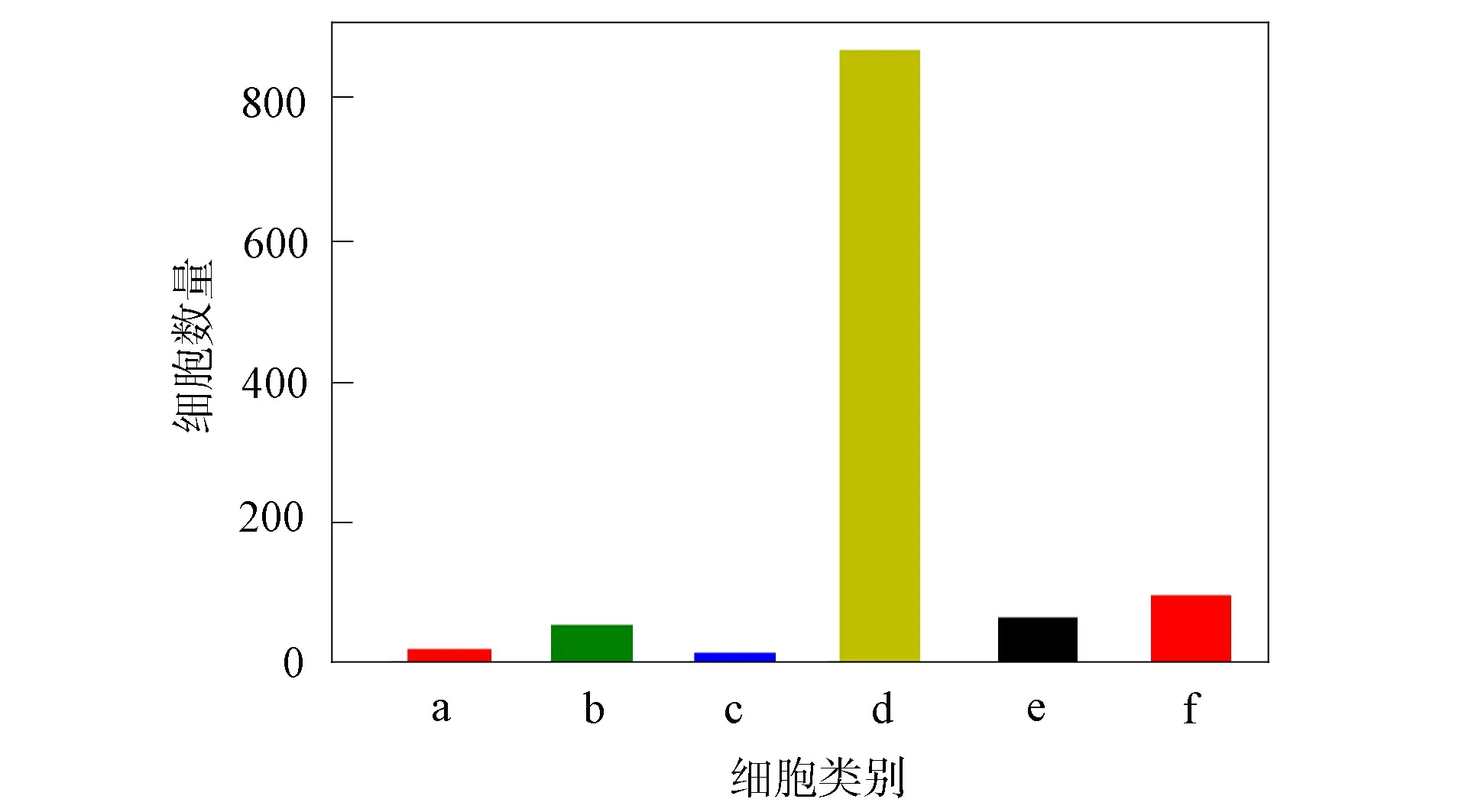
a. 基细胞; b. 巨噬细胞; c. 上皮细胞;d. 内皮细胞; e. T淋巴细胞; f. B淋巴细胞.图3 单细胞RNA-seq数据GSE118390的类别分布Fig.3 Category distribution of single cell RNA-seq data GSE118390
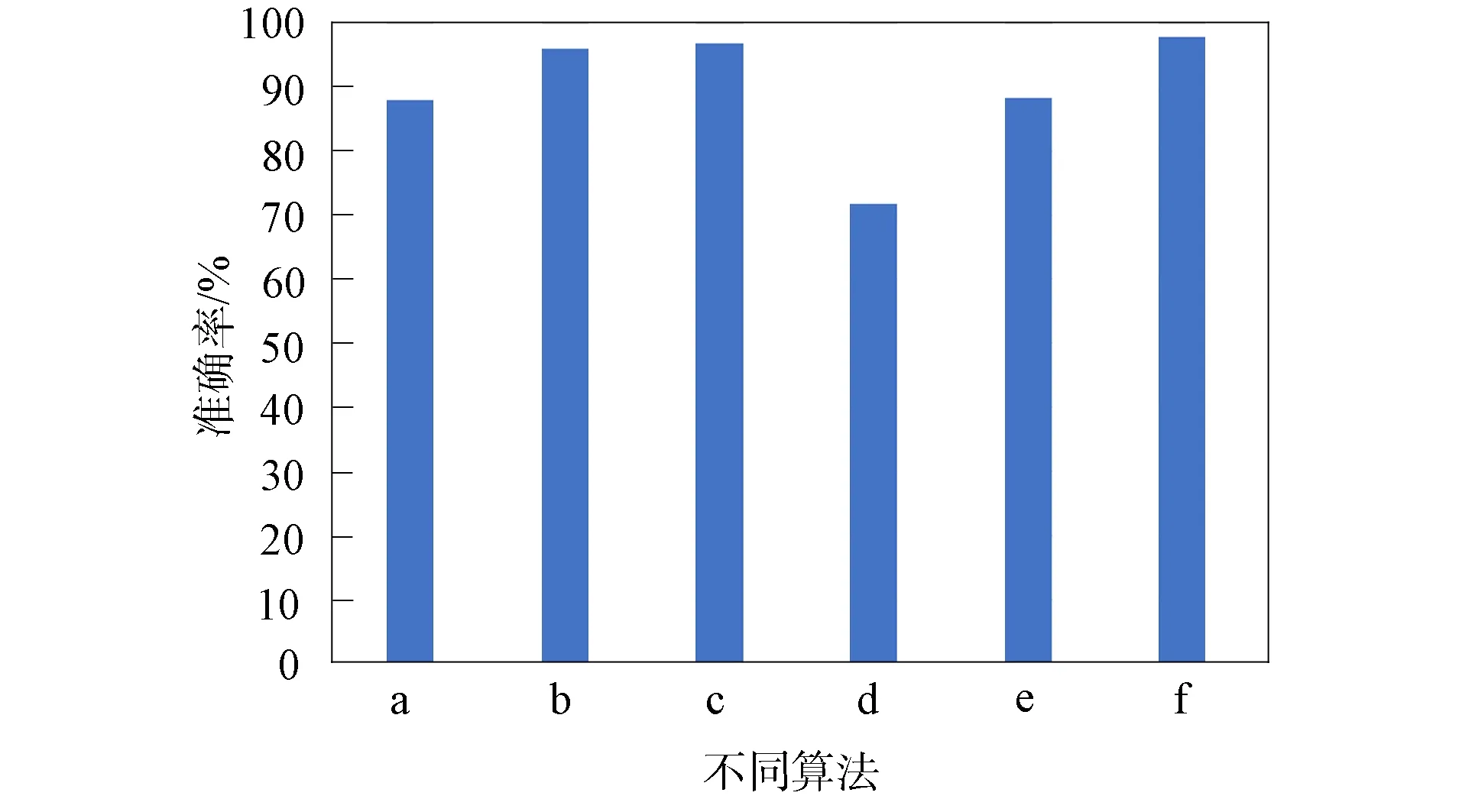
a. 线性判别分析; b. k-近邻算法; c. 分类回归树算法;d. 朴素Bayes算法; e. 支持向量机算法; f. 集成学习算法.图4 不同分类算法对数据GSE118390的分类准确率比较Fig.4 Comparison of classification accuracy of different classification algorithms on data GSE118390
