基于神经网络的汽车侧面造型评价方法
2021-09-19王欢欢初胜男顾经纬
王欢欢,初胜男,顾经纬
(1.天津科技大学机械工程学院,天津 300222;2.天津市轻工与食品工程机械装备集成设计与在线监控重点实验室,天津 300222)
随着汽车技术的不断成熟与完善,汽车已经不再是技术导向型产品,更多的是需求导向型产品,汽车造型成为用户选购时的重要考量点[1-2]。对于汽车这种形态复杂,且非规则几何形状的产品而言,用户往往无法清晰地表达自己的视觉感受,受试者通常会使用较为模糊的表达方式。对于经验不足的设计者,很容易出现主观性的设计误判,难以获得准确的造型意象。反向传播(back propagation,BP)神经网络作为一种非线性运算方法,能够建立用户意象与造型设计参数之间的映射关系,从而把握产品形态设计方向[3-7]。通过研究面部表情有助于客观地评估产品的可用性[8-9],表情识别技术能够连续识别用户在观察汽车造型时的感受,分析造型风格与用户好感度的相关性,帮助设计师了解用户对产品造型的需求,更客观地判断造型优化方向的有效性。因此,本文通过量化意象,并将表情识别技术运用在方案评价阶段,通过识别测试者面部表情的变化和情绪倾向性,获取用户情感需求,以数据形式得出结论,来以指导汽车的侧面造型设计。
1 用户意象与造型特征的关系模型
1.1 选取样本和感性意象词汇
汽车样本图像主要来自于“汽车之家”网站上提供的侧面视图,包括欧洲系、日系、美系和国产品牌4 个大类共80 辆车型,基本涵盖了目前市场上绝大多数的中型车的造型。对图像进行初步处理,利用边缘检测算法[10]得到汽车的侧面线框图,随后对图像进行黑白处理,使其成为二值图像。因车轮属于附加特征,实验只针对主要特征和过渡特征,因此去除了车轮。预处理后将相似的车型剔除,保留了62 辆。这些车型涵盖种类丰富,不同车型之间的造型语言具有一定区分度,以保证神经网络训练的有效性,处理后的图像如图1 所示。

图1 处理后的样本 Fig.1 Processed sample images
对二值图像进行参数化处理,为后续BP 神经网络的造型分类做准备。在平面绘图软件中利用关键控制点,绘制样本车侧面造型的轮廓图和侧面腰线。外轮廓造型有36 个控制点,分别由C1~C36控制;腰线与外轮廓线分开,且为非闭合线,由9个控制点Q1~Q9 控制,样本控制点分布如图2 所示。之后使用网格工具,对样本造型的关键控制点进行定位。以图2 为例,最左端C1 点建立Y轴,以最下端C35 点建立X轴,由此建立坐标系以获取每个控制点的二维坐标,样本的关键控制点坐标值见表1。

图2 样本控制点分布 Fig.2 The distribution of sample control point

表1 关键点坐标值 Table 1 The key point coordinate value of sample
对于语义差分调查问卷而言,62 款车型数量太多,过长的问卷时间可导致测试者疲劳,且看到更多相似的图像后也可能影响或失去评价判断的标准,因此要选择差异性大的车型。问卷调查共选择被试者30 人,男女比例为1∶1。被试者可自由对62 辆汽车侧面造型进行分类,将主观认为相似的车型分到一组。把车型的坐标参数导入SPSS 统计软件进行聚类分析,以确定汽车造型的分类数量,并剔除相似度高的图像样本,最终分为38 类,并在每类中各选择一个车型图像作为进行语义差分调查问卷的样本以及BP 神经网络的训练样本库。
在产品外观设计过程中,设计师主要考虑产品形态、材质、色彩、图案等。本文意象词汇的选择结合了汽车产品本身的特点,从形态、配色、材质、比例、装饰5 个要素出发来表达汽车造型意象。通过相关文献资料、互联网新闻等渠道,收集了32 个与汽车侧面造型相关的意象词汇见表2。选取的意象词汇按照这5 个要素进行分类,并经过对比和分析,去除冗余词汇、意义相近的词汇,以及一些主观性过强而易于对用户的情绪产生过多干扰的词汇。同时,在咨询了汽车设计方面的专家以及对实验对象进行问卷调查后,通过数据处理、聚类分析对意象词汇进行筛选,确立了最终的4 个意象词汇,即“流线”、“稳重”、“大气”和“优雅”。

表2 初选意象词 Table 2 Primary imagery
利用意象词汇和38 个样本汽车侧面轮廓造型制作语义差分调查问卷,以获取用户对于不同车辆造型的评价数据。将用户对于造型语言的感知程度分为5 级。以流线为例,5 分为流线程度很高;3 分为一般;1 分为很差。调查一共收到73 份问卷,其中有效问卷62 份。并计算有效问卷中每种车型的意象评价值的均值。
1.2 网络模型的训练与验证
利用3 层、单隐含层的BP 神经网络,在MATLAB 中搭建造型风格与用户意象之间的关系模型。由于BP 神经网络采用的是非线性变换函数Sigmoid 函数,该函数只能识别[0,1]的数据,因此利用mapminmax 函数对样本数据集进行归一化(Normalizing)处理。根据经验公式以及试算,设置隐含层节点为11,并将网络最大迭代次数设置为500,训练目标设置为0.000 06,学习率设置为0.08。基于此训练BP 神经网络用于快速判断汽车侧面造型风格。
为了验证用户意象与汽车造型特征的关系模型的可行性,从剩余的24 个汽车侧面造型中选择5组数据,输入网络模型中进行验证,将神经网络得到的预测值与调查问卷得到的实际值进行比较,结果见表3,结果显示,两者的误差值很小。为了验证该BP 神经网络的有效性,将原本因为车型相似度较高而剔除的10 款车型造型数据输入网络,并对该10 款车型进行感性工学问卷调查,分析比较2组数据的差异性。使用SPSS 软件对2 组数据的平均值进行T 检验,得到显著性水平p=0.186>0.05,说明该BP 神经网络是有效的。

表3 神经网络预测值误差 Table 3 Neural network predictive error
1.3 汽车造型风格
本文的最终目的是研究同一车型在迭代优化中的造型风格是否符合用户市场的需求,并研究何种风格的设计趋势更易获得市场的喜爱。因此选取了3 种具有代表性的车型,这3 种车型迭代次数较长,分别以车型A,B 和C 命名,每种车型各12种迭代款式,编号1~12。并将3 种车型每一代的侧面造型特征输入到用户意象与汽车造型特征的关系模型,得到模型反馈的结果,即车的意象分值曲线如图3 所示。
图3 的结果显示,随着不断迭代,B 车模型反馈的分值最高的意象为优雅,稳重的分值处于第二位,流线意象在2.5 分附近波动,大气的意象概率一直保持较低的概率,在近几代的车型中大气意象有小幅上升。通过对比原图可知,这种情况的出现是由于近几代车型尺寸有所增大及局部比例变化,因此把B 车型作为优雅和稳重意象的代表。同理,A 车型作为流线和优雅的代表;C 车型作为大气和稳重意象的代表。
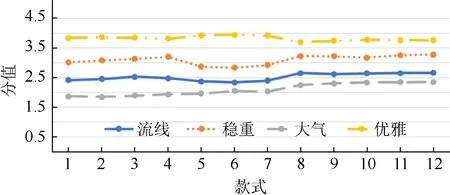
图3 B 车意象分值曲线 Fig.3 Model B image value curve
2 汽车造型评价系统
2.1 表情识别模型的训练与验证
本文表情识别的网络结构选择了VGG 结构[11-14],VGG 结构的泛化能力非常好,在不同的图像数据集上都有良好的表现。其采用了AlexNet[15]的思想,网络架构是卷积层-池化层-全连接层的结构。本文中表情识别实验的重点是需要能够准确判断受试者情绪的正负向倾向,对于7 种情感的少量分类,VGG 结构下的VGG13 网络模型更加轻巧、层数适中,不易出现冗余,且降低了整个模型的训练效率。
表情识别模型[16]的初步训练阶段选取了Fer2013,JAFFE 和CK+3 个公开的数据库,并按照9∶1 的比例分为训练集和测试集,最终训练集包含32 782 张图像,测试集包含3 643 张图像。在训练网络模型过程中,通过不断测试将学习率设置为0.000 1,批大小(Batch-size)设置为32,丢失概率(Dropout)设置为0.7。为了方便数据和标签的统一读取,将3 种数据库的图像都处理为CK+图像的形式,并分为高兴(Happy)、愤怒(Angry)、厌恶(Disgust)、悲伤(Sad)、恐惧(Fear)、惊讶(Surprise)和平静(Neutral)7 类。实验采用在每个epoch 后评估测试集的准确率,当准确率提高时,存储模型当前的权重。在多个epoch 后,得到对测试集识别准确率最高的结果,首次训练后模型对各数据库识别准确率如图4 所示。横轴分别代表模型对JAFFE 原数据集、JAFFE 数据集中人的面部区域(说明能从图像中提取有效的面部信息,不会因为图像中人脸的面积大小影响测试的结果,证明模型的鲁棒性)、Fer2013 数据集及CK+数据集的识别率。
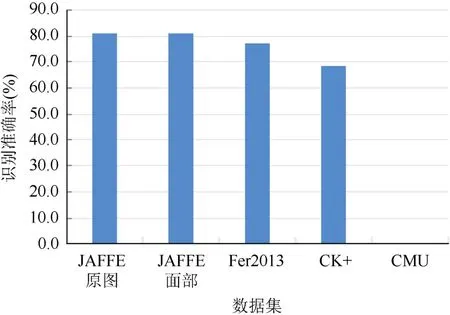
图4 首次训练后的识别准确率 Fig.4 The recognition accuracy of the first training
为了检验该模型对于非数据库中图像的识别准确率,采用了由卡内基梅隆大学采集的The CMU Multi-PIE Face 数据库(CMU),将CMU 数据库中6 152 张标记的图像输入模型,并用图像增强的方法来提高模型的准确率和鲁棒性,最终训练后模型对各数据集的准确率如图5 所示。
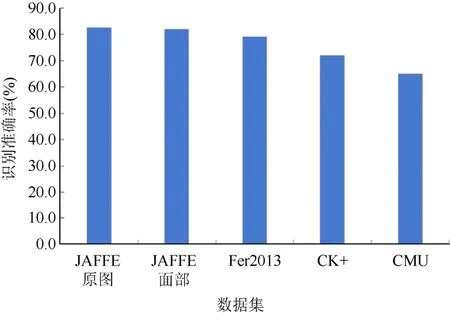
图5 模型改进后的识别准确率 Fig.5 The recognition accuracy after model improvement
与此同时,查看CMU 数据库识别各表情分类的准确率如图6 所示,发现并不是所有表情的识别率都高。对于高兴、惊讶和平静这3 种表情识别准确率较高,而其余的表情识别率较低。由于之后的实验只需要研究用户情绪的正负向倾向,愤怒、厌恶、恐惧和悲伤都属于偏负向的情绪,虽然这4 种表情之间识别率存在不均衡的问题,但不会对实验准确性造成过大的影响。经过训练和改进,该神经网络综合准确率可达76%以上,能够有效地区分测试图像中人脸情绪的正负向倾向,满足了之后实验和评价体系建立的要求。

图6 CMU 数据库各表情识别正确率 Fig.6 The recognition accuracy of each expression in CMU
2.2 实验
2.2.1 实验过程
36 名受试者参加表情识别实验,图像采集所采用的设备为工业相机,配套的软件为官方提供的“MV Viewer”。在正式实验之前,通过预实验剔除因环境、眼镜反光等因素造成的表情识别准确率不佳的受试者。首先使用被标记的表情诱导图像识别受试者表情并将这些表情的原始图像输入到预实验程序中,运行后自动显示识别结果,识别后在图像上标定情绪标签如图7 所示,若识别表情的准确率达到80%以上,则受试者通过预实验。实验最终剔除了7 名受试者,29 名(男18 名,女11 名)参与了实验。

图7 预实验识别结果 Fig.7 Pre-experimental identification result
在正式实验中,每秒采集图像20 帧,将图像保存为表情识别模型可读取的图像格式。并通过幻灯片的形式将A,B 和C 3 款车的侧面造型按汽车发布的时间顺序展示给受试者,每幅图像在屏幕上停留10 s,同一款车型的12 张图像放映结束后,休息1 min,再展示下一组;采集受试者面部图像的同时同步录制屏幕上的幻灯片内容。并将摄像头录制到的连续图像与受试者观看幻灯片的录像时间轴同步,保证采集到的受试者表情与看到的图像内容在时间上的一致性。
2.2.2 数据处理
受试者的表情数据用搭建的 VGG13 CNN 表情识别模型进行处理,最后输出代表7 种表情的预测结果。
由于只需要分析受试者对于所看到造型的喜好程度,愤怒和恐惧过于极端,在实际观察一个没有强烈主观色彩的中性图像时,出现这3 种情绪的可能性极低,因此作为误差将其剔除。对于剩下的5 种表情,将厌恶和悲伤作为负向情绪;将高兴作为正向情绪;将平静认为无情绪波动。对于惊讶这种表情,比较难以直接界定这个表情的正负向情绪,采取该表情出现时其前一张与后一张图像的表情来界定。这里分2 种情况,若前后2 张图像的表情识别情绪一致,均为正向、负向或无情绪波动,则认为中间这张惊讶的表情与前后的表情一致;若前后2 张图像的表情识别情绪不一致,则认为惊讶为用户的情绪正在发生转变,为了平滑情绪波动曲线,将这一时间点的情绪判定为无情绪波动。分析整理各个受试者的正负向情绪后,以1 s 为一个单位,每个单位20 个表情数据,将3 种情绪归一化处理,然后绘制随时间变化的用户群情绪变化曲线图(B 车为例)如图8 所示。

图8 B 车用户群情绪变化曲线 Fig.8 Model B Users’ emotional change curve
2.3 实验结果分析及验证
对意象分值和情绪倾向性相关性的分析,在双侧检验,置信度为0.01 上使用SPPS 对双变量进行了Pearson 相关系数分析。结果显示,4 个意象词之间呈现不同程度的负相关性,“流线”与正向情绪具有显著性差异,2 变量呈较强正相关(0.767),“稳重”和“优雅”与情绪之间呈较低相关性,则说明这2个造型意象与用户好感度关联性较低。结合相关性分析,从图8 与图3 中可以看到,最初用户对该车表现以平静为主,情绪倾向性较低,随着车型的迭代,用户的好感度逐渐上升。在之前对B 车的造型风格进行预测时,从第五到第七代,这3 款车型正好处在一次大的换代阶段,整车造型变得十分圆润,因此稳重的意象显著下跌,与此同时优雅的意象有所增加。然而在情绪变化曲线中,造型意象的显著改变并未对用户的评价造成显著的影响,因此初步认为这2 个造型意象与用户好感度关联性较低。同理,分析A 和C 的意象分值曲线和情绪变化曲线(图9~10)。随着A 车型的迭代,流线分值大幅上升,超过了20%,其余的意象得分变化不大。与之对应的情绪变化曲线显示,正向情绪也取得了大幅上升,负向情绪大幅下降;C 车型的4 种意象,分值均有不同程度的提高。从第七代车型开始,流线的得分开始大幅增加。对应的情绪变化曲线可以看出,在第七代车型,负向情绪就有了大幅下降,从第八代车型开始,用户对于C 车型基本已经没有负向情绪。

图9 A 车的意象分值曲线和情绪变化曲线 ((a)意象分值曲线;(b)情绪变化曲线) Fig.9 Model A image value curve and emotional change curve ((a) Image value curve;(b) Emotional change curve)
通过对3 款车型的风格演变进行分析和评价,得出了用户目前更倾向于流线和大气造型的结论,增加“流线”意象的分值能显著提高用户好感度。由于本文中的A,B 和C 3 款车型年代跨度长、造型变化多,用户好感度的提升可能是多种造型意象综合的结果。所以本文选取D 车型的3 款车,验证是否单一流线意象的提升能够对用户好感度起到正相关作用。
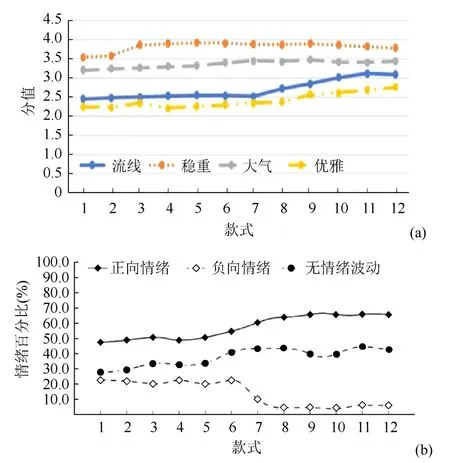
图10 C 车的意象分值曲线和情绪变化曲线((a)意象分值曲线;(b)情绪变化曲线) Fig.10 Model C image value curve and emotional change curve ((a) Image value curve;(b) Emotional change curve)
选择的验证车型D 的迭代次数较少,每代造型风格都有明显地改变。最新一代的D-3 侧面造型拥有更流畅的造型比例,整车主要提升了流线的意象,比较适合对流线感这项单一变量进行实验,因此选取这款车型来验证评价系统结论的有效性。首先对D 车侧面外轮廓造型参数化,随后将3 辆车的参数值输入到预测模型中,得出意象分值曲线。由预测曲线可以看出,D 车的造型意象提升较为单一,主要的提升在“流线”这一造型意象中。同时,结合用户的表情识别数据,验证了流线造型意象与用户好感度具有显著相关性的结论,即单一的流线意象提升也能够提升用户好感度。新一代D-3 对比前两代车型,该车在流线意象得分中有一定的提高,与之对应的,用户对于新款车型的评价也较上两代车型更好,由此验证了之前的分析判断。由此得出,在汽车造型设计优化中,提升流线型意象,更符合未来一段时间用户对于汽车造型语言的需求趋势。
此外,通过量化意象得到具体的侧面造型,进一步帮助设计师在众多的“流线型”设计方案中选择最接近用户好感度的车型。首先对比D 车型3 款车的关键点坐标,分析得到C6~C17 的关键点在汽车迭代过程中变化较大、具有显著相关性。其次以C10,C12 和C14 折点为分界点,在Excel 中根据散点图的走势,选择拟合结果的R 平方值最接近于1 的拟合函数(R 平方值越接近1,拟合效果越好),由此得到C6~C10,C10~C12,C12~C14 和C14~C17的函数表达式。最后利用MATLAB 软件计算3 款车对应曲线的曲率,推断出流线型汽车大致的曲率范围见表4。
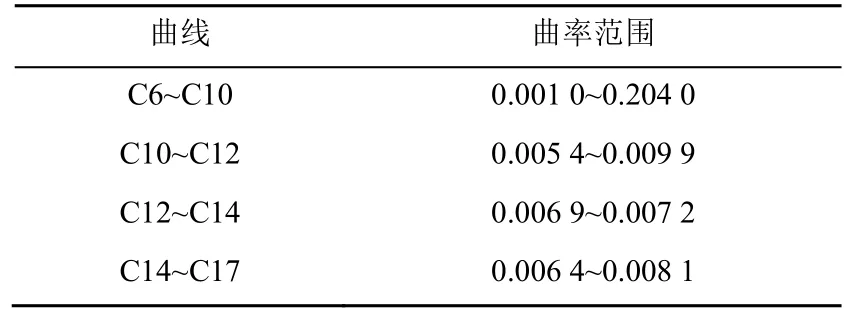
表4 “流线型”汽车曲率范围 Table 4 The curvature range of“Streamlined”
3 结束语
本文是通过神经网络的学习能力,搭建用户意象与造型风格的关系模型,使计算机获得识别车辆造型风格的能力,取代传统的调查问卷,提高风格评价的效率。其次,使用表情识别技术来量化地分析产品造型意象和用户好感度之间的关系,对造型风格趋势进行分析和评价,由此获得满足用户情感需求的设计方案。并利用Excel 和MATLAB 软件快速计算的能力,得到流线型汽车最佳的曲率范围。此方法的优势在于:
(1) 快速识别汽车造型风格。为了研究造型风格变化趋势,需要用户观察同一款车型的不同年代的改款,这些车型之间变化较小。将汽车图像二值化后,用户也难以区分车款之间的细微差异,容易造成用户判断力的缺失。通过用户意象与造型风格神经网络关系模型的建立,获得对输入车型风格的判断能力,能够对有的造型风格进行快速识别,而不需要每一次都重复调查问卷并人工分析。
(2) 识别用户潜意识情绪。应用表情识别技术可以发现设计师容易忽略的被试者的细微情绪变化,可以分析设计中某些细节对被试者产生的心理作用。帮助设计师更客观、更理性地了解用户的真实感受,分析用户行为,从而设计出更符合用户心理预期的设计。
(3) 以数据形式得到具体意象的侧面造型。通过量化意象,以数据形式得出具体结论,来指导汽车研发流程中的侧面造型设计,做到以用户为导向判断造型优化方向的优劣,帮助设计师在造型优化时有迹可循。
