基于半监督学习和三支决策的入侵检测模型
2021-09-18张师鹏李永忠杜祥通
张师鹏,李永忠,杜祥通
(江苏科技大学计算机学院,江苏镇江 212100)
(*通信作者电子邮箱1099682749@qq.com)
0 引言
入侵检测系统是保护信息和通信技术基础设施免受网络攻击的最重要实体之一,是学术界和工业界不可忽视的研究主题[1]。随着人工智能的迅猛发展,越来越多的机器学习模型被应用在入侵检测领域的研究中。
杨宏宇等[2]提出了一种基于改进卷积神经网络(Improved Convolutional Neural Network,ICNN)的入侵检测模型,一定程度上解决了模型的过拟合问题;丁红卫等[3]利用改进的和声搜索方法(Harmony Search,HS)对反向传播(Back Propagation,BP)神经网络的初始值进行优化,提出了一种基于改进的HS 算法优化BP 神经网络的入侵检测模型;Zegeye等[4]提出了一种基于隐马尔可夫模型等多种机器学习方法的多层入侵检测模型,该模型可以解决维度灾难问题;Xiao 等[5]针对误检率高且泛化能力差的问题,提出了基于深度卷积神经网络的入侵检测模型。
上述方法都是基于监督学习的入侵检测模型,监督学习的特点是稳定,效果相对较好,但获取大量的标注信息是一项巨大的工程。然而,当网络遭受攻击时,会产生大量未知攻击的数据,如果单纯地凭借人工进行标注,将会大大降低对于攻击的检测效率。
半监督学习在近些年中也越来越多地被用在了入侵检测的领域中[6-7]。然而已有的基于半监督学习的入侵检测模型大都是基于二支决策的,即对于一个网络行为,应该立即对其作出决策,决定其是正常行为还是异常行为。在一些情况下,尤其是利用基于半监督学习的方法进行分类的过程中,分类器获取到的信息不充足,若盲目对所有网络行为作出决策,可能会出现大量错误;而且在基于半监督学习的分类方法进行分类的过程中,对于伪标记样本的选择没有标准,这些问题可能都会导致分类器无法对所有的网络行为作出一个合理的决策。
针对上述问题,本文提出了基于半监督学习(Semi-Supervised Learning,SSL)[8]和三支决策(Three-Way Decision,3WD)的入侵检测模型——SSL-3WD。基于三支决策理论,在信息不足的情况可以采用延迟决策来保证对于已经作出决策的数据其所含信息是充分的,三支决策的这个特征可以用于满足数据信息冗余性这个假设;利用三支决策理论进行分类得到的结果相较于传统的二支决策得到的标记置信度更高,基于此,三支决策理论可以解决在选择未标记样本时难以选择合适样本这个难题。
表1为本文所使用符号的描述。

表1 符号描述Tab.1 Description of symbols
1 半监督学习
半监督学习(SSL)[8]的目标是利用大量未标记的数据来提高小数据集上监督学习的性能。基于分歧的半监督学习[9]是目前主流的四种半监督学习范型的一种,关于基于分歧的半监督学习的研究开始于对协同训练的研究[10]。假设数据集D=L∪U,其中L={(x1,y1),(x2,y2),…,(xm,ym)}是带标签的数据集,X={x1,x2,…,xm}是数据集L中的原始的属性集,而Y={y1,y2,…,ym}为标签;U=为无标签的数据集。
定义1假设X1、X2分别表示两种不同视角V1和V2的特征,即X1=V1(X),X2=V2(X),且在理想情况下当给定标签Y,协同训练需要满足p(X1,X2|Y)=p(X1|Y)p(X2|Y)。假设Y=g(X)为需要学习的真实的映射函数,f1和f2分别为两个视角的分类器,则

在协同训练的过程中,利用通过不同视角的特征训练得到的模型f1和f2在无标签的数据集上进行预测,各选取预测置信度比较高的样本加入训练集中,重新训练两个不同视角的模型,并不断地重复这个过程。
当f1=f2以及V1=V2时,协同训练方法便退化成为自训练方法。虽然目前相关研究都证明协同训练方法充分利用了分类器之间的分歧,相对来说有更好的性能,然而在本文的实验中发现,当与三支决策进行结合时,自训练方法才是最合适的方法。相对协同训练,自训练方法更加简单高效,而且不用考虑视图的条件独立性这个假设,通常情况下,这个假设并不能得到满足,甚至连弱依赖性也不能满足[8]。
2 三支决策
三支决策(3WD)理论来自粗糙集理论[11]。目前,人们普遍认为,粗糙集理论只是构造三支决策的许多可能方法之一[12]。
定义2假设S是一个有限非空实体集,C是有限条件集,三支决策通过一个映射f将有限非空实体集S划分为3 个两两互不相交的域:POS、NEG和BND,即

其中:POS∪NEG∪BND=S,POS∩NEG∩BND=∅。
POS、NEG、BND可用于生成三支决策的规则。具体而言:POS区域生成接受决策规则,即正域;NEG区域生成拒绝规则,即负域;而BND区域生成延迟决策规则,即边界域。如何确定对象是否包含在特定区域中将取决于它满足C中条件的程度。正域中的样本满足接受条件,负域由满足或低于拒绝级别的对象组成,边界域由满足度高于拒绝级别但低于接受级别的对象组成。在基于三支决策理论的整个决策过程中(最后一步除外),有必要确定是否对当前对象作出最终决定,即对象是否属于正域(POS)或负域(NEG),或当前对象应分类为边界域(BND)。对于边界域中的数据,在获取其他信息之后,将重新评估边界域。如果样本可以分为正域或负域,则作出最终决定。对于某些样本,最终决定需要再次推迟[13]。决策过程将继续进行,直到将所有对象划分为正域或负域为止。
对于一个样本,存在三种可能的决策,即:接受(POS)、拒绝(NEG)和延迟决策(BND),并且存在样本属于某个域或不属于该域两种可能的状态。根据这三个可能的决策和两个可能的状态,相关成本λ如表2所示。

表2 三支决策的决策损失函数Tab.2 Decision losst function of three-way decision
假设样本x属于集合的概率为P(C|x),将C定义为正域,而P(CC|x)则为样本x不属于域C的概率,即x属于负域CC的概率。则:
1)如果P(C|x)>α,则x∈POS;
2)如果P(C|x)<β,则x∈NEG;
3)如果β≤P(C|x)≤α,则x∈BND。
假设0 ≤λPP≤λBP<λNP,0 ≤λNN≤λBN<λPN,根据文献[14-15]的推演证明,可以得到如下两个相关阈值的计算公式:
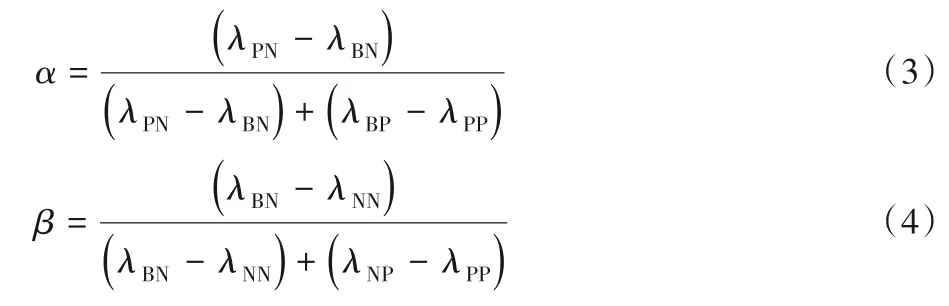
其中,0 ≤β≤α≤1。可以得到如下三条应用到入侵检测领域的规则:
1)如果P(C|x)>α,则该网络行为被归为正类,即该网络行为是入侵行为;
2)如果P(C|x)<β,则该网络行为被归为负类,即该网络行为是正常行为;
3)如果β≤P(C|x)≤α,则表示当前信息下,无法对该行为采取任何决策,则该行为需要被划分到边界域以等待进一步的处理。
三支决策为入侵检测提供了一种有用的机制。考虑这一种情况,在大多数情况下入侵检测是正确的,但偶尔会拦截某些正常行为或释放某些入侵行为。重复发生此类错误将导致严重后果。作出错误分类决定的原因可能有多种,例如分类器的不合理设计和误导的网络行为等,一个重要的原因是用于决策的信息不完整且不充足。为了解决此类问题,可以采取三支决策,通过使用延迟选项,可以避免某些错误的分类。
3 本文模型SSL-3WD
3.1 入侵检测模型设计
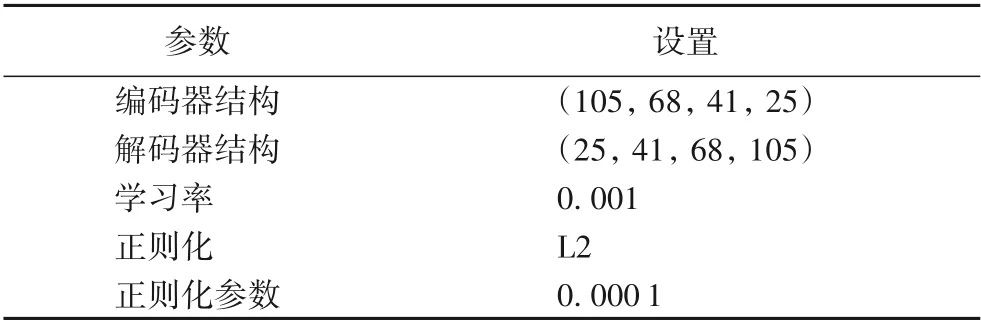
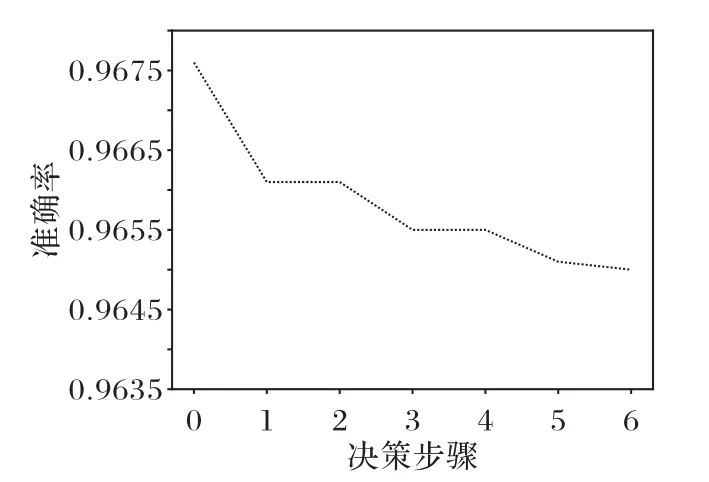
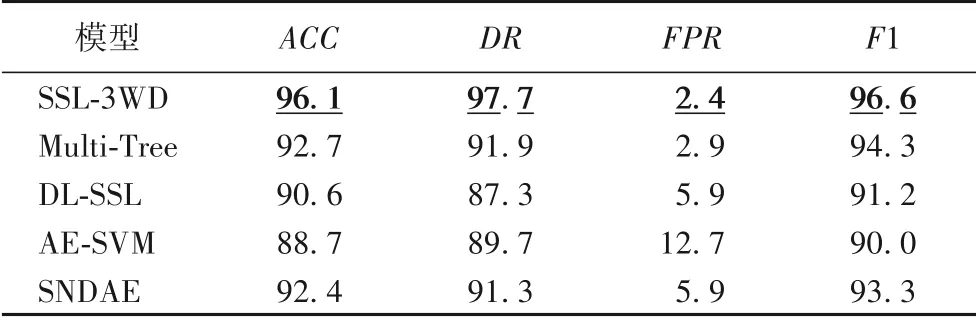
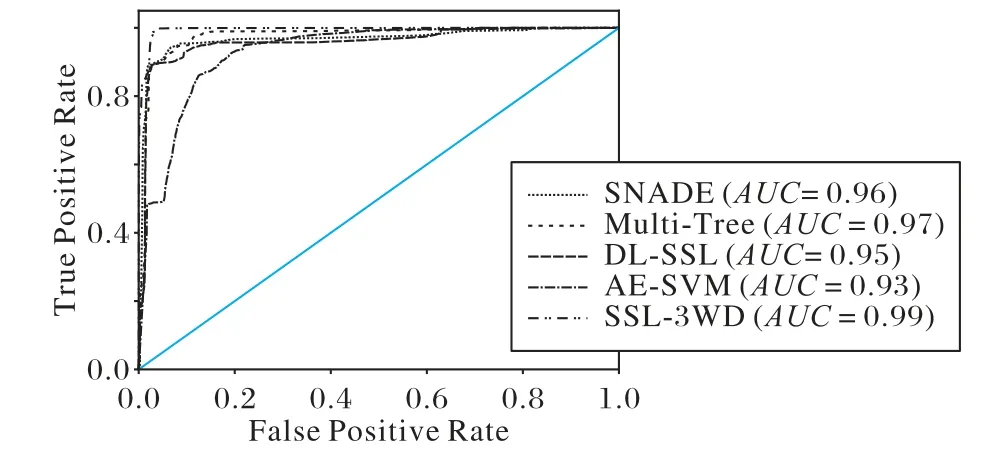
根据上文所阐述的半监督学习相关定理,假设数据集D1所含信息可以支撑分类器对k个无标签的数据作出分类,通常情况下k 在半监督学习中,需要从未标记样本中挑选出一定比率的样本进行标记,并把这些带有“伪标记”的样本加入分类器的训练集中,从而组成新的训练集。然而在没有标签的前提下,如何挑选样本是一个难题。目前有关半监督学习的研究中,并没有在这一方面作出过多的阐述。本文提出利用三支决策理论来挑选由分类器给出“伪标记”的样本。如上文所述,利用三支决策理论得到的正域和负域,可以认为当前有标签的数据集所包含的信息是足以支撑分类器对这些样本作出标记的,即从某种程度上可以信任对这些数据的标记,因此,可以选择正域以及负域中的样本与原有的训练集组成新的训练集,并利用得到的新的训练集继续对模型进行训练,而此时,无标签的样本集为负域中的样本组成的样本集。上述训练过程将一直持续下去,直至满足停止条件,通常情况下,停止条件可以人为指定,可以指定训练次数达到一定程度时训练停止,也可以指定当负域中不存在样本时停止训练。 本文提出的基于半监督学习和三支决策的入侵检测模型(SSL-3WD)的算法流程如算法1所示。 特征提取方式用于获取原始数据集的低维表示。由于原始数据中包含大量冗余信息,这些信息对于分类效果产生了不好的影响,因此需要对原数据进行特征提取。相较于主成分分析方法(Principal Component Analysis,PCA)等传统的线性特征提取方式,自编码器[16]是一种非线性的特征提取方式,其提取到的特征更能抽象表示出原始数据的信息,故本文采用自编码器这种非线性的特征提取方式。 分类器模型f用于获取样本属于正域的概率,因此,对于f的选择以选择软分类模型为宜,本文选用逻辑回归作为分类器模型。逻辑回归是一种软分类模型,可以输出每个样本属于某个类的概率。根据模逻辑回归求出每一个数据属于正类的概率p,并根据三支决策的理论,通过预先设置的两个阈值α以及β将该数据归为正域或者负域:若某个样本属于正域的概率p>α,则将该样本划归为正域;若某个样本属于正域的概率p<β,则将该样本划归为负域;若α 对于划分到正域以及负域的样本,则需要将其作为被选中的数据加入原有的训练集组成新的有标签的训练数据集,而边界域中的数据则作为无标签的数据等待被重新划分。重复上述步骤,直至不存在无标签的数据。 从算法1 的流程可看出:本文算法在一个循环中完成,循环的结束条件为分类器对所有的无标记样本作出一个合理的决策,由于在迭代过程中设置了一个强制程序终结的步骤,如第12)步,因此算法不会陷入无限的循环中。假设算法的迭代次数为T,而循环内部主要的时间消耗集中在特征提取,如第2)步,以及对分类器模型的训练,并利用模型进行分类,如第3)~4)步,第5)步中的for 循环并不是主要的时间消耗,在整个外部循环中进行的次数也只为测试集的个数,即时间复杂度为O(M)。特征提取方式G(自编码器)以及f分类器(多层感知机)都是深度学习模型,而随着分布式计算的发展,通常并不计算深度学习模型的时间复杂度,因此并不能确定给出整个算法的时间复杂度,假设这两部分的时间复杂度为O(N),则本文算法的时间复杂度可以表示为O(T•N+M),本文的数据不是大量的图像数据,只是网络行为数据,对于采用了分布式计算的深度学习模型来说,时间消耗在可接受范围内。 在决策的过程中,三支决策划分三个域的关键在于决策阈值对的设置。通常情况下,对于损失函数,应该根据所分析问题以及实际情况的不同,根据专家经验以及先验知识进行设定。不同的问题对应不同的损失函数,不同的损失函数对应不同的划分结果。本文将三支决策理论应用于入侵检测的领域,用于确定一个网络行为属于正常行为还是异常行为,则损失函数的选取就要植根于入侵检测的领域中。根据经验可得,将一个正常的网络行为误认为异常行为所产生的代价要远低于将一个异常行为误认为正常行为所产生的代价,故可根据经验设置各损失函数如表3所示。 表3 据经验设置的三支决策损失函数值Tab.3 Setting of loss functions of three-way decision based on experience 本文实验所采用的数据集有两个,分别是NSL-KDD 数据集以及UNSW-NB15数据集。NSL-KDD数据集由41个特征属性和1 个类属性组成。KDD 数据集包括训练集和测试集两种,总共包含38种攻击,其中训练集包含22种攻击,而测试集中包含训练集中的20种攻击,除此之外还包含17种不在训练集中的攻击类型。因此可以使用测试集测试入侵检测方法在未知攻击上的表现。38种攻击类型可以分为4种主要的攻击类型:拒绝服务攻击(Denial of Service,DoS)、远程攻击(Remote-to-Login,R2L)、本地用户非法提升权限的攻击(User-to-Root,U2R)以及网络刺探(Probe)。UNSW-NB15 数据集包含许多现代网络的新攻击,可以将其分为1 个正常类和9个攻击类[17]。在本文的实验中,数据分布如表4所示。 表4 不同数据集的数据分布Tab.4 Data distribution of different datasets 数据不能直接用于训练,原始数据包含类别特征,而类别特征大多都是用字符串进行表示的,因此需要进行数值化处理。 以字符串类型表示的类数据需要进行数值化处理,数值化处理最简单的方法是序号编码,以属性protocol_type 为例,它的属性值为(TCP,UDP,ICMP),则可以表示为(1,2,3)。然而利用序号编码处理过的数据有了大小关系,例如按照上文处理会得到ICMP>UDP>TCP 的处理结果,这种大小关系并不是该属性的性质,所以采用独热编码进行编码。 原始数据所处的量纲不同,自编码器在训练过程中要使用梯度下降法,若每列属性的取值范围相差过大,会影响算法的性能,还有可能带来意想不到的错误,因此要进行归一化处理。 线性函数归一化是一种常见的归一化方法,也被称为Min-Max 归一化,通过这种归一化方法可以将数据归一到[0,1]区间内,归一化的计算如式(5)所示: 其中:x是第i个属性列的一个值;mini是第i个属性列的最小值;maxi是第i个属性列的最大值。 选择准确率ACC(ACCuracy)、误报率FPR(False Positive Rate)、检出率DR(Detection Rate)与F1值作为评判指标。 评价指标的计算公式如下。 其中:TP(True Positives)和TN(True Negatives)分别表示攻击记录和正常记录已正确分类;FP(False Positives)代表被误认为是攻击的正常记录;FN(False Negatives)代表错误分类为正常记录的攻击记录。 对于三支决策的损失函数的设置已经给出,表5 给出了SSL-3WD模型在工作的工程中所使用的自编码器参数。 表5 自编码器的参数设置Tab.5 Setting of parameters of autoencoder 对比模型包括:文献[18]提出的一种基于深度堆叠自编码器(Stack Nonsymmetric Deep Autoencoder,SNDAE)的入侵检测模型;文献[19]提出的一种基于深度学习(Deep Learning)和半监督学习的入侵检测模型DL-SSL;文献[20]提出的一种基于自编码器(Autoencoder,AE)和支持向量机(Support Vector Machine,SVM)的入侵检测模型AE-SVM;文献[21]通过调整训练数据的比例并设置多个决策树提出的一种自适应的集成学习入侵检测模型Multi-Tree。 对于一个入侵检测模型来说,检测出入侵行为才是最主要的,因此在实验的过程中,把所有的入侵行为的标记设为1,正常样本的标记设为0。 SSL-3WD 模型通过多步决策对所有的网络行为进行分类,每一步都得到一个对当前的正域以及负域(已经作出确定决策的样本)的分类结果,如图1 所示为得到的各步的准确率。 图1 各决策步骤的准确率变化Fig.1 Accuracy change of each decision step 从图1 中可以看到,随着决策步骤的增加,准确率在下降。假设第i次得到的准确率为a,第i+1 次得到的准确率为b,则一般情况下b要小于a。因为,根据三支决策理论,一个样本越难以被决策,则对其作出错误决策的可能性就越大,而随着决策步骤的增加,对于边界域中的决策很难达到上一次决策所得到的准确率,因此准确率呈现出一个下降的趋势,但是作出正确决策的样本的数量是不断增加的。 表6为各个模型在NSL-KDD测试集上的性能表现。本实验在选择数据集时,令训练集与测试集中的样本数量基本保持一致,即对于分类器模型来说,所获取的信息是不充足的。通过这种数据选择的方式更能体现出SSL-3WD 模型的优秀表现。 表6 在NSL-KDD测试集上的实验结果 单位:%Tab.6 Experimental results on NSL-KDD test set unt:% 从表6 可以看出,本文模型SSL-3WD 的所有指标都是最优,准确率达到了96.1%,检出率达到了97.7%,误报率低至2.4%,F1值达到了96.6%。检出率相较于对比模型中表现最好的Multi-Tree提升了5.8个百分点。 从实验结果可以看出,SSL-3WD 模型不仅要优于对比模型中的几种监督学习模型,而且要优于同样使用了半监督学习的DL-SSL 模型。SSL-3WD 模型基于三支决策理论完成伪标记样本的选择,这种选择方式要优于DL-SSL的随机选择。 图2为根据几种模型ROC的实验结果得到的受试者特征图(Receiver Operating Characteristic,ROC)曲线图,ROC 曲线也可以综合反映出一个模型的表现。每条曲线围成所围成的面积被称为AUC(Area Under Curve),AUC越大代表一个模型的综合性能越好。从图2 可以看出,本文模型SSL-3WD 的AUC达到了0.99,是几种对比模型中最高的。 图2 在NSL-KDD数据集上进行测试得到的ROC曲线图Fig.2 ROC curve obtained by test on NSL-KDD test set 为了验证实验数据的规模对于SSL-3WD 模型的影响,在本文原本使用的训练集上作了调整,分别使用训练集的20%、40%、60%、80%、100%作为训练数据,分别记为训练集1、2、3、4、5,实验数据分布如表7所示。 表7 不同比例的训练集的数据分布Tab.7 Data distribution of train data with different proportions 由于U2R 攻击类型的数据极少,因此在选择数据时会选择所有攻击类型为U2R 的数据。利用以上训练集对模型进行训练,并在测试集上进行测试,可以得到如表8 所示的测试结果。 表8 在比例不同的训练集训练的测试结果 单位:%Tab.8 Test results with training datasets with different proportions unit:% 从表8 中可以看出,SSL-3WD 模型随着数据的增多,性能在逐渐地变好,检出率在不断地增加,误报率在不断地减小,且模型变好的趋势比较明显。也在一定程度上说明了模型的鲁棒性较好。 和在NSL-KDD 数据集上的实验一样,在实验的过程中依旧将异常数据的标签置为1,正常行为的标签置为0,可以得到如表9所示的实验结果。 表9 在UNSW-NB15测试集上的实验结果 单位:%Tab.9 Experimental results on UNSW-NB15 test set unit:% 在UNSW-NB15 的表现相较于在NSL-KDD 数据集上的性能表现,各个模型都有一定的下降,但是下降幅度都非常小。从表9 中数据可以看出,SSL-3WD 模型的性能表现还是最优的,其检出率达到了96.3%,与比较方法中表现最好的基于深度堆叠非对称自编码器(SNDAE)的入侵检测模型比较,分别提升了3.5 个百分点和6.2 个百分点;此外,误报率低至3.2%,F1值达到了95.6%。 图3 为几种模型的ROC 曲线图。从图3 可以看出,SSL-3WD 的AUC为0.98,是几种模型中最高的,也佐证了SSL-3WD模型是几种模型中较优的。 图3 在UNSW-NB15数据集上进行测试得到的R0C曲线图Fig.3 ROC curve obtained by test on UNSW-NB15 dataset 本文提出了一种基于半监督学习和三支决策的入侵检测方法SSL-3WD。通过三支决策理论来改善半监督学习在信息的冗余性以及“伪标记”样本的选择这两个情形上的不足。仿真实验结果表明,基于半监督学习和三支决策的入侵检测方法要好于对比方法。 当使用三支决策理论挑选“伪标记”样本的过程中,不可避免地会选择一些标记错误的样本,如何尽可能地去除这些被错误标记的样本是接下来的研究应该注意的一个方向。3.2 入侵检测模型的算法流程

3.3 三支决策阈值的设置

4 实验结果和分析
4.1 实验数据


4.2 评价指标
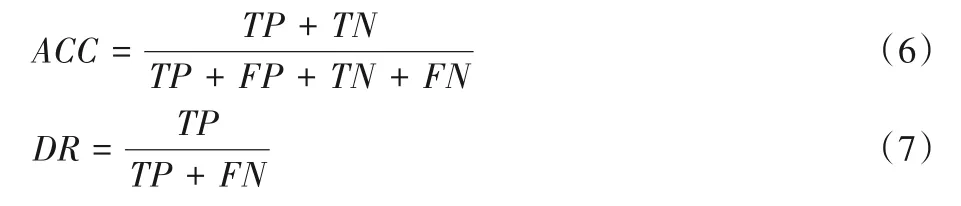

4.3 参数设置
4.4 对比模型
4.5 在NSL-KDD数据集的实验结果


4.6 在UNSW-NB15的实验结果


5 结语
