基于注意力机制的多层次编码和解码的图像描述模型
2021-09-18李康康
李康康,张 静
(华东理工大学信息科学与工程学院,上海 200237)
(*通信作者电子邮箱jingzhang@ecust.edu.cn)
0 引言
图像描述任务是图像理解中的重要研究内容,它结合了计算机视觉和自然语言处理两大任务。图像描述需要利用计算机视觉相关的技术准确地识别出图像中的内容,也需要利用自然语言处理中的文本生成的方法生成语法和语义上正确的句子。图像描述任务的关键在于如何充分利用图像特征以及如何有效地解码。
近年来大多数图像描述任务[1-2]都是基于编码器-解码器(Encoder-Decoder)的模型,编码器部分利用VGG(Visual Geometry Group)[3]、ResNet[4]等卷积神经网络(Convolutional Neural Network,CNN)得到图像的特征,然后利用长短期记忆(Long Short-Term Memory,LSTM)网络[5]对特征进行解码从而得到生成的语句。Vinyals 等[1]首先将机器翻译[6]中的编码器-解码器结构引入图像描述任务,他们首先利用预训练的卷积神经网络得到图像特征,并将其输入到LSTM 的第一个时间步骤,然后依次输入上一时间步骤生成的单词,得到描述语句的每个单词。但这种方式仅在第一个时间步骤输入图像特征,使得不是每个时间步骤都关注到图像的重点,而且图像特征信息会随着时间步骤的增加而逐渐减少。注意力机制[7]的使用使得解码器在LSTM 的每个时间步骤都能关注到重要的信息,显著提升了模型的有效性。一些工作[8-10]对编码器部分作出改进,使用 Faster R-CNN(Faster Region-based Convolutional Neural Network)[11]提取对象特征或卷积神经网络的多层次特征;也有一些工作在解码器部分使用了LSTM的变体[9,12],例如双向LSTM(Bidirectional LSTM,Bi-LSTM)[13]、双LSTM 等。然而现有工作缺乏将多层次结构的编码器和解码器有效结合,且现有方法提取特征的方式单一。例如,DSEN(Dense Semantic Embedding Network)[9]使用了两个双向的LSTM 进行特征解析,第一个LSTM 输入为单词,第二个LSTM 输入为图像特征和属性,然而第二个LSTM要对图像特征和属性进行同时解析,这在一定程度上限制了模型的能力,此外该模型的图像特征仅为卷积神经网络最后一个卷积层输出的特征,缺少对特征的再加工与提炼过程。与DSEN[9]类似,Bi-LSTM[13]的改动在于在编码部分对不同卷积层的特征进行级联作为第二个LSTM 的输入,然而本质上该模型仍然没有将不同层次的特征进行层次化解码。DHEDN-3(Deep Hierarchical Encoder-Decoder Network)[14]使用了多个LSTM 进行特征解析,该模型中使用的特征来自卷积神经网络最后两个卷积层的输出,很显然该模型缺少对特征的再次提炼过程,且其第一个LSTM 仅输入单词,缺少使模型在初始时获得图像整体感知的过程。针对上述的问题,本文提出了一种基于注意力机制的多层次编码和解码的图像描述模型MLED(Multi-Layer Encoding and Decoding model),如图1 所示。该模型首先利用Faster R-CNN 提取对象特征,并使用Transformer[15]进行高层次特征提取,Transformer 内部的多头注意力机制能够建立起特征之间隐含的复杂联系从而形成高层次特征,并同时能够将特征映射到不同的子空间。借鉴卷积神经网络中的特征金字塔网络(Feature Pyramid Network,FPN)[16]模型,用高层次的特征依次和低层次特征融合得到新的特征,这将有助于改善低层特征的质量。由于单个LSTM 解析能力有限,本文使用多个LSTM 的结构,将不同层次的特征分别输入到对应层次的LSTM 中层次化解码,最终生成单词。
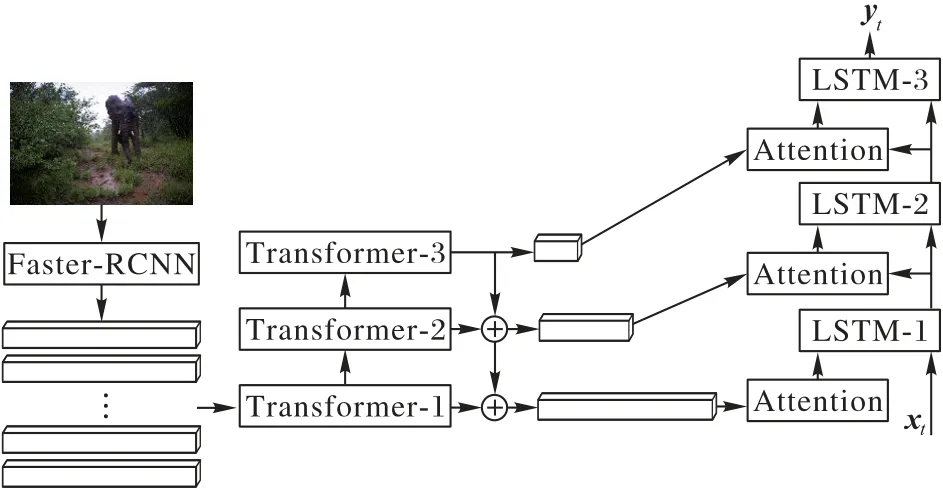
图1 本文模型框架Fig.1 Framework of proposed model
本文的工作主要如下:1)提出了新颖的层次化编码方式,利用Transformer以及残差的思想,得到不同层次的特征;2)将不同层次的特征以特征金字塔的方式进行融合,有效提升了特征的准确性;3)提出了层次化解码的LSTM 结构以及组合方式,对不同层次特征进行有效解码。
1 相关工作
近年来,基于编码器-解码器的框架被广泛地应用于图像描述任务中。本章将主要从注意力机制、编码器结构、解码器结构三方面介绍图像描述相关工作。
Xu 等[7]改进了Vinyals 等[1]的工作,他们利用软注意力机制,在每个时间步骤用LSTM 的隐藏层状态对图像特征加权,将加权后的特征和单词共同输入LSTM 得到结果。由于LSTM的隐藏层状态包含上下文信息,因此这种加权在一定程度上能够选择到当前时间步骤的重要信息。Chen等[8]提出了一种空间和通道的注意力机制,它充分利用CNN 的空间和通道特征,以便在每个时间步骤进行解码。考虑到生成的单词并不总是取决于视觉信息,Lu 等[12]提出了带有视觉哨兵的自适应注意力模型,该模型可以决定何时关注视觉信息和语言模型。
在编码器方面,Zhang 等[17]提出了一种全卷积神经网络(Fully Convolutional Network,FCN),该网络能够生成细粒度网格化的注意力特征图,从而得到更为精细的图像特征。Yao等[18]提出了五种不同的模型来结合图像及其属性以探索图像特征和属性特征的结合方式。Wu等[19]不使用视觉特征,仅使用经过预训练的特定检测器提取图像中的属性,并将其输入LSTM 中以生成描述。Yu等[20]提出了一种给定主题的图像描述模型,主题是从训练的分类器中获得。该模型从主题、描述和图像中学习了一种跨模式的嵌入空间,在生成单词时可从嵌入空间中检索信息。
在解码器方面,Anderson 等[21]提出了一种Bottom-up 模型,该模型包括Faster R-CNN和一个双LSTM结构。他们首先利用Faster R-CNN 提取图像的对象特征,然后将其均值化后的特征和对象特征分别输入到第一个语言LSTM 和第二个注意力LSTM。相较于单LSTM,这种双LSTM 结构有更好的解析能力。Xiao 等[14]建立了一个由三个不同的LSTM 组成的深层次的编解器-解码器框架,最底层的LSTM 用于对单词进行编码,中间的LSTM 和最顶部的LSTM 用于接收来自CNN不同卷积层的特征。Wu等[22]使用GridLSTM 在生成单词时能够有选择地包含视觉特征,其中GridLSTM 由Temporal LSTM 和Depth LSTM 组成,Depth LSTM 能够将视觉信息作为潜在的记忆保留,该解码器能够使得每一步动态地接收视觉信息,且无需添加额外的参数。
受上述工作启发,本文提出了一种基于注意力机制的多层次编码和解码的图像描述模型,通过多层次编码得到不同层次的对象特征,并利用多层次LSTM分别解析。
2 本文模型
本章将首先使用公式介绍图像描述问题,并给出其目标损失函数,然后分别介绍本文所提出模型的编码器和解码器部分。
2.1 问题描述
给定一张图像I和其对应描述单词的序列Y={y1,y2,…,yn},生成序列的分布可由式(1)表示:

任务的目标是最小化式(2)的损失函数:

2.2 模型
本文提出了一种基于注意力机制的多层次编码和解码的图像描述模型MLED,该模型框架如图1 所示,包括编码层的Faster R-CNN、Transformer、金字塔特征融合以及解码层的层次LSTM。
2.2.1 编码器
Faster R-CNN[8]主要用于目标识别,本文利用FasterR-CNN得到每张图像N个感兴趣区域(Region of Interest,ROI)特征,并将其转化为N个2048维特征A={a1,a2,…,aN}。
如图2 所示,为了得到复杂的高层次的特征,利用Transformer 隐含式地对特征进行聚合,以此来得到更高层次的特征。
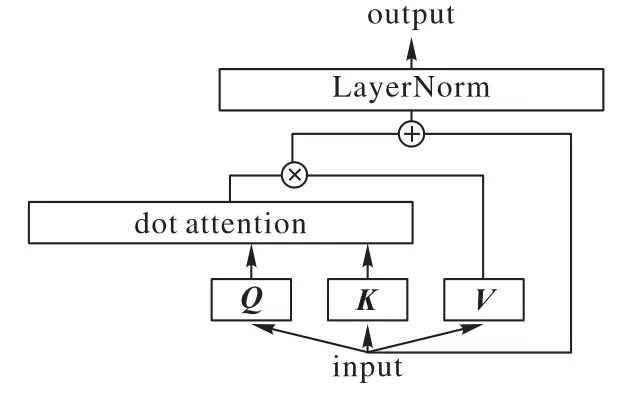
图2 提取高层次特征的模型Fig.2 Model of extracting high-level features
Transformer 中的多头注意力机制能够让模型关注到特征的不同位置,并将来自较低层的特征映射到不同的子空间。同时多个Transformer串联使用,可以获得不同层次的特征,高层次特征的语义性更强,但包含的信息少,低层次的特征包含的信息内容多,语义较弱。该过程可由式(3)~(5)表示:
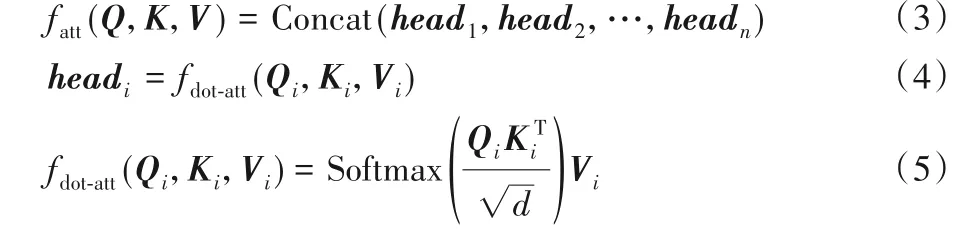
其中:Q、K、V是特征A的三个独立线性映射;fatt是由n=8 个fdot⁃att函数组成的多头注意力函数;d为常数。对于每对(Qi,Ki,Vi),模型都能将输入映射到不同的子空间,多个Transformer 串联又进一步增加了不同子空间的组合,从而进一步增强了模型的表达能力。深度学习网络的问题之一是梯度消失,这会使网络出现饱和现象,因此本文采用残差和归一化的方式,避免在Transformer 层出现梯度消失现象,特征A经过一层Transformer后的输出记为A',其过程如式(6)所示:

其中:LayerNorm为归一化层;Transformer函数为式(3)~(5)所示。本文设置3 个不同的Transformer 层,根据上述公式,可依次得到维度为512的特征A'、维度为256的特征A″、维度为128的特征A‴。与传统的Transformer 只利用最后一层输出不同,本文利用了多层Transformer的输出,并且使用了残差的思想,将Transformer 处理后的特征与输入特征相融合,最后使用LayerNorm对特征进行归一化。使用式(6)的目的一方面在于使得梯度能够直接回传到原始输入本身,使得网络能够更深,有更强的表现能力。另一方面归一化的使用使得结果能够落入非线性函数的线性区,缓解梯度消失问题,以此使得模型更加稳定,加速收敛过程。
在获取到不同维度的高层次的特征后,本文使用金字塔型的多尺度特征融合方式对特征进行有效的融合。这种自上而下的融合方式能够使得高层特征得到加强,低层特征得到补充,如图1所示,该融合方式可由式(7)~(9)表示:
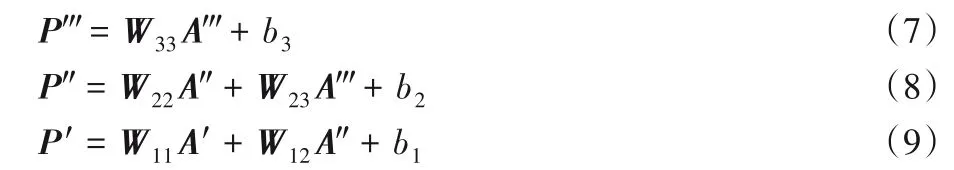
其中:W为参数;b为偏置项。经过融合后P'、P″、P‴的维度均为512。低层特征P'在融合时仅使用A'和A″,而不加入A‴的信息,一方面是防止与A'和A″的维度差异过大,导致升维效果不理想,使得模型表现能力受限;另一方面,A″中包含了A‴部分信息,不添加A‴在一定程度上能够防止重复信息的叠加和信息冗余。
2.2.2 解码器
为了对编码器输出的3 种不同层次的特征进行有效解码,本文使用层次LSTM 的结构处理,该结构包括3 层LSTM。其中低层LSTM 处理低层次特征,高层LSTM 处理高层次特征,这种结构化的层次处理,其目的在于对不同层次的特征进行递进式地解码。此外,使用软注意力机制,在每层特征输入LSTM 之前,根据上下文信息对特征进行加权,关注当前步骤应该关注的重要信息。LSTM 的隐藏层状态包含丰富的上下文信息,利用隐藏层状态和特征得到特征的权重向量,并对特征做加权,以此来获得经过加权的特征。
第一层LSTM 的输入为前一时刻生成的单词的词嵌入向量xt -1和本层对应的编码器特征P',其中使用注意力机制对编码器的特征进行加权处理,该过程如式(10)~(13):

其中:W为参数;b为偏置项;t表示解码器第t个时间步骤;i表示当前图像N个特征中的第i个;是LSTM 的细胞状态,在t时刻第一层LSTM 的输出为。第一层LSTM 的输入包括单词和编码器特征,其中编码器特征经过软注意力机制加权,重要信息得到加强。第一层LSTM 的输出的隐藏层状态包含了上下文特征,能为第二层LSTM提供语义信息。
第二层LSTM 的输入为第一层LSTM 输出的隐藏层状态和本层对应的编码器特征P″,同样使用软注意力机制对编码器的特征进行处理,该过程如式(14)~(17):
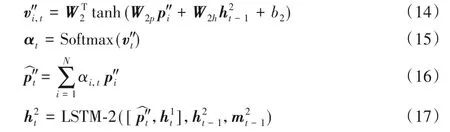
第三层LSTM 的输入为第二层LSTM 输出的隐藏层状态和本层对应的编码器特征P‴,该过程同前两层LSTM 相同,最终第三层LSTM输出为式(18)所示:
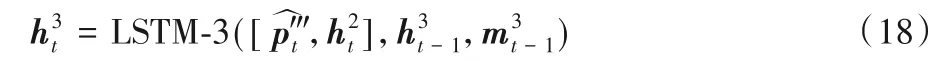
在第t时间步骤,生成单词的概率分布函数由多层感知机fMLP和Softmax 函数组成,得到的最大值即为生成单词在词典中的索引,具体如式(19)所示:

3 实验与结果分析
3.1 实验数据及配置
本文主要使用2014 年发布的MSCOCO(Microsoft COCO:Common Objects in Context)[23]大型数据集进行模型验证。MSCOCO 包括12 387 张图像,每张图像有5 句描述。本文使用BLEU(BiLingual Evaluation Understudy)[24]、METEOR(Metric for Evaluation of Translation with Explicit ORdering)[25]、ROUGE-L(Recall-Oriented Understudy for Gisting Evaluation with Longest common subsequence)[26]、CIDEr(Consensus-based Image Description Evaluation)[27]四种指标验证模型的有效性。
实验平台为Ubuntu16.04,使用Pytorch 深度学习框架,GPU 为显存为8 GB 的Geforce RTX 2080,CUDA 版本为10.0,CPU为英特尔E5-2630,内存为32 GB。
编码器采用的Faster R-CNN使用ResNet101为基础框架,输出的对象特征维度为2 048,限制每幅图像最大对象数量上限为50。对于每条描述,限制其最长单词序列长度为20。选取在数据集中至少出现过5 次的单词组成词典并忽略大小写,得到的单词词典大小为10 201,词典使用“BOS”作为单词序列的起始输入标志,“END”作为生成单词序列的结束标志,“PAD”作为补位标志,“UNKNOW”作为不在词典中的单词标志。
训练阶段,本文使用Adam[28]优化器,损失函数为交叉熵,首先使用小的学习率1× 10-6进行热身学习10 000次,然后使用1× 4-4的学习率训练模型20 轮。为了防止在反向传播阶段出现梯度消失或梯度爆炸,本文在编码器部分使用了残差及归一化的方式,如式(6)所示,在解码器部分设置了梯度截断,其范围为[-0.1,0.1]。在测试阶段,使用beam search 策略每次选择3个得分最高的候选。
3.2 实验分析
将本文提出的基于注意力机制的多层次编码和解码的图像描述模型MLED与当前主流模型进行对比,实验结果如表1所示。实验对比了NIC(Neural Image Caption)[1]、SA(Soft Attention)[7]、DSEN(Dense Semantic Embedding Network)[9]、Adaptive(Adaptive attention)[12]、Bi-LSTM[13]、DHEDN-3[14]、FCN[17]、Recal(lRecall what you see)[22]、基于注意力特征自适应矫正(Attention Feature Adaptive Recalibration,AFAR)模型[29]、HAF(Hierarchical Attention-based Fusion)模型[30]。
由表1 可知,本文提出的算法在指标BLEU-1(BLEU with 1-gram)、BLEU-2(BLEU with 2-grams)、BLEU-3(BLEU with 3-grams)、BLEU-4(BLEU with 4-grams)、METEOR、ROUGE-L和CIDEr上得分分别为75.9%、59.7%、46.1%、35.6%、27.3%、56.2%、112.5%,结果优于其他模型,相较于DSEN 和Adaptive 模型,指标平均提升约2 个百分点,相对Recall 模型和HAF 模型分别提升约3 个百分点和1 个百分点。以DSEN为例,该模型利用了多层次特征和双LSTM,本文模型相较于DSEN,利用Transformer 提取了高层次特征,并对特征做了进一步融合,最后利用层次LSTM 对特征层次化解析,因此结果优于DSEN。相较于其他利用注意力机制的模型Attention、FCN 以及Adaptive,本文提出的模型在Transformer 中使用的多头注意力机制以及对每个LSTM 的输入使用软注意力机制,都进一步对特征进行了重要信息提取,因此获得了优异的结果。此外,这种金字塔型的特征以及融合方式在一定程度上体现了全局特征、局部特征以及对象特征,符合人类对图像的整体认知的顺序。

表1 不同图像描述算法模型指标对比 单位:%Tab.1 Comparison of different image captioning algorithm models on indicators unit:%
表2为对比实验结果,包括单Transformer 和单LSTM 的结构模型SLED(Single-Layer Encoder and Decoder)、无特征融合模型MLED-NF(No Fusion)实验结果。
由表2 可知,相较于MLED,SLED 指标均低于MLED,单编码单解码的结构一定程度上限制了对特征的提取和解析能力,验证了MLED 模型多层次编码和解码的有效性。MLEDNF 无特征融合过程,而MLED 的自上而下的融合过程有一定程度的特征加强作用,最顶层的特征最接近单词输出,反向传播后的梯度能多次影响下层特征,使得模型能达到更优的解。

表2 消融实验结果Tab.2 Ablation experimental results
图3 为随机挑选的样例,包括图片、标注的5 句描述以及模型生成的对应描述。可以看出,本文所提出的MLED 模型能够很好地捕捉图像内容和细节,例如图3中样例1的“large”和“lush”、样例2的“metal fence”以及样例3的“covered slope”,这些生成的语句能够涵盖图像的内容和细节,并且模型生成的描述基本符合语法和语义。

图3 生成描述样例Fig.3 Examples of generated description
4 结语
本文设计了一种基于注意力机制的多层次编码和解码的图像描述模型,通过Faster R-CNN 得到对象特征,然后使用Transformer 进行高层次特征的提取并使用金字塔型的融合方式对特征进行融合,最后使用层次LSTM 对不同层次的特征分别解析。该模型在不同层次充分利用了对象特征,并且使用金字塔型的融合方式对特征进行了有效融合。模型对不同层次特征的层次化解码促进了网络的解码能力。实验结果和分析表明,本文提出的模型在各项指标均有优异的表现,所生成的描述也符合语法和语义,并且优于其他模型。未来将结合卷积神经网络的不同层次特征、对象的不同层次特征、特征融合方式以及Transformer 方式的层次化解码等方面进一步研究。
