基于模糊测试的反射型跨站脚本漏洞检测
2021-09-18倪萍,陈伟
倪 萍,陈 伟
(南京邮电大学计算机学院,南京 210023)
(*通信作者电子邮箱chenwei@njupt.edu.cn)
0 引言
随着因特网技术的日益发展,现代万维网(World Wide Web,WWW)应用程序呈现高度动态、交互性强的特点。Web 用户是网站的浏览者,同时也是网站的创造者。通常,Web应用程序允许捕获、处理、存储以及传输敏感的客户数据(比如个人详细信息、信用卡号等)[1]以供客户使用。因此,Web 应用程序已经成为黑客们的特别关注点,进而带来的就是一系列的Web 安全威胁,如结构化查询语言(Structured Query Language,SQL)注入、跨站脚本(Cross-Site Scripting,XSS)、文件上传、命令执行等[2]。
根据White Hat Security 的统计分析,XSS 攻击约占网络攻击的一半。在2004、2007、2010、2013 以 及2017 年 的OWASP TOP 10[3]中,XSS 分别位居第四、第四、第一、第三、第七名,并且,2019 年的互联网安全威胁报告显示,利用XSS 漏洞引起的钓鱼攻击和表单劫持给企业带来了巨大损失。XSS攻击主要是由于攻击者向Web 应用程序页面中嵌入恶意的脚本代码,在用户浏览相关页面时,这些恶意脚本会在客户端浏览器中执行,从而引发攻击,窃取用户隐私,损害用户利益[4-5]。因此,积极应对并充分保护网站免受此类攻击变得越来越重要。
传统的XSS检测方法一般是通过黑名单备份的方式进行过滤,当网络一旦获取到黑名单中存在的数据就进行拦截,从而避免了一些恶意请求。尽管该过滤器能对Web 用户起到一定的保护作用,但是对于一些经过加密的数据就无法被准确地检测到,检测质量并不高。目前,尽管有许多研究人员通过静态或动态的测试方法来对XSS 漏洞进行检测,但也暴露出了一些问题:静态分析是通过对应用程序的源代码进行分析来发现系统中潜在的漏洞[6],但在很多情况下,研究人员无法轻易获取到程序源码;动态分析[7]虽然相较于静态分析而言,适用性较强,并且无须源码,但是不全面的攻击向量可能会造成较高的误报率,所以需要向漏洞点注入大量的攻击向量来降低误报率,可是这样针对性不强,并且会大大增加检测时间,降低效率。
针对以上问题,本文所做的主要工作如下:
1)传统的网络爬虫技术是通过对给定的统一资源定位符(Uniform Resource Locator,URL)进行迭代爬取,直至达到爬取深度,从而获得页面上的注入点。但是由于当前许多Web网页是通过AJAX 和Javascript 的形式动态产生内容,所以本文通过提取页面中的JavaScript 脚本以及其中的一些事件属性,使用JS 引擎进行编译执行,从而获取到更多的潜在注入点,为更好地挖掘漏洞奠定基础。
2)在对模糊测试技术的研究和分析之上,开发和实现了一种基于设计规则和测试用例“变异”的模糊测试算法来生成攻击语法。由于一般的模糊检测方案生成攻击载荷手段单一且容易造成误报率,所以,本文的创新点在于对攻击语法中的每个元素使用权重的方式进行标记,根据评估Web 应用程序的响应来进一步调整攻击语法中的元素权重,由此找到最有潜力的攻击载荷来发掘应用程序中存在的反射型XSS漏洞。
3)通过与其他两个流行的XSS 攻击检测工具进行对比,实验结果表明,本文对模糊测试方法的改进方式是有效的,该方法在漏洞检测率和误报率上呈现一定优势。
1 相关工作
XSS 漏洞作为Web 应用程序中最严重的安全威胁之一[8-9],自1996 年被发现以来便引起了国内外学者的广泛关注,很多研究组织或机构人员已经对其检测工作作了大量的研究并提出相关方法,主要包括三类:静态分析方法、动态分析方法以及动静结合的分析方法[10]。
Zheng 等[11]提出远程执行代码漏洞检测Web 应用程序的路径敏感静态分析,这是一种通过路径和上下文敏感的过程间分析来检测远程控制(Remote Control Equipment,RCE)漏洞的方法。分析的特点是以路径敏感的方式分析Web 应用程序的字符串和非字符串行为。Medeiros 等[12]提出使用静态分析和数据挖掘检测来删除Web应用程序漏洞。
由于静态分析方法依赖于应用程序的源代码,而在检测过程中获取应用程序源码是一件非常困难的事情,并且静态检测方法也无法验证漏洞的真实性,所以存在一定的局限性,于是,更多的人倾向于使用动态或动静结合的方法来检测漏洞。Duchene 等[13]提出了一种用于检测Web 应用程序跨站脚本漏洞的黑盒模糊器。该模糊器通过遗传算法来产生恶意输入,使用攻击语法作为算法参数,攻击语法可以通过限制交叉和变异操作来减少搜索空间并模拟攻击行为,又由于原始字符串匹配的方法可能无法精确地推断出污点位置,因此它使用双重污点推断来获得准确的结果。虽然此方法利用控制流依赖和数据流依赖来引导模糊测试并解决了大多数黑盒检测器无法检测反射型XSS 的问题,但该方法不支持AJAX 程序,应用范围受限。程诚等[14]提出了一种基于模糊测试和遗传算法的XSS漏洞检测方法。该方法主要是通过分析服务端的过滤机制来定义攻击向量的语法补全规则,再使用遗传算法不断分析和优化攻击载荷以生成最优向量;可是该方法中使用的攻击代码需要手动输入,人工操作量大,没有实现自动化。黄文峰等[15]提出了一种使用扩展的巴科斯范式(Extended Backus-Naur Form,EBNF)和二次爬虫策略相结合的方式检测XSS 漏洞,但该方法并未涉及反爬虫及如何对抗Web 应用防火墙(Web Application Firewall,WAF)的措施,而且在实验阶段使用的是自己开发的应用程序,可行性有待考证。
很多基于传统的XSS漏洞检测技术在挖掘漏洞注入点方面未考虑网站的反爬机制,亦或者是忽视了那些不支持AJAX的网站,因此导致用户注入点采集不全面,并且,也因为XSS攻击载荷种类单一或检测覆盖面不足等一系列问题,最终导致系统检测性能低,无法全面有效地发现漏洞,所以本文提出一种基于模糊测试的反射型XSS漏洞检测方法。该方法提取了页面中的JavaScript 脚本,通过JS 引擎进行编译执行,挖掘更多潜在的用户注入点,降低了漏报率;同时,还考虑了因攻击向量选取不足或选取过量而导致的检测时间长等问题。本文根据探子向量注入获取输出点类型,根据输出点类型选择相应攻击语法模式构造攻击载荷并变异进行检测,当然,为了更有针对性地利用对网站响应的攻击载荷进行分析并生成更加高效的攻击载荷从而更快地找到存在的漏洞,本文提出了一种基于模糊测试的反射型XSS 漏洞检测技术,通过对攻击语法中的每一个元素进行初始化权重值,再根据服务器响应情况调整权重由此生成更优质的攻击载荷,进而节约了检测时间、提高了检测效率。
2 相关技术
2.1 网络爬虫
2.1.1 定义及其基本原理
网络爬虫[16]是根据一定的规则,自动地爬取互联网信息的一个程序或者一段脚本,被广泛应用于各种搜索引擎以及其他相关网站[17],能够自动获取其能访问到的所有页面内容信息。
网络爬虫从功能上来说一般分为数据采集、处理、存储三个部分。首先从给定的一个或者若干个网站URL 开始,获取初始URL,然后对页面内容进行分析,寻找页面中包含的其他链接地址存入待爬取队列中,根据待爬取队列中的链接依次出队经过解析获取其中的URL 信息,由此循环,直至满足某个条件后停止工作。
2.1.2 抓取策略
在网络爬虫系统中,待爬取URL 队列是特别重要的一个部分,在待爬取URL 队列中URL 以一种什么样的顺序进行存储是一个会直接决定爬取效率的因素,所以,如何选择影响到这些URL 顺序的抓取策略是至关重要的。以下是几种常见的网络爬虫爬取策略:
1)深度优先遍历策略。一般是从起始网页开始,对该页面进行分析,然后选择其中的一个URL 再次进入解析,如此循环抓取,直至到达一个深度阈值,再返回上一层以同样的方法进行爬取。由于一般网站,每深入一层,其网页价值以及PageRank都会有所降低,因此该策略很少被使用。
2)最佳优先遍历策略。就是根据特定的网页分析算法来预测待选URL 中与目标网页类似或相近的URL 进行爬取。因为这种算法只会涉及到网页分析算法认为“有用”的URL,所以在爬取过程中会忽略掉许多相关页面,从而降低了爬取质量。
3)广度优先遍历策略。是指在采集链接的过程中,将当前页面的所有URL 链接都爬取下来,然后再对其子链接进行相同操作的分析获取。该策略实现起来相对简单,并且能够较为全面地获取到网页中的URL 链接,提升了页面爬取质量。
2.2 模糊测试
2.2.1 概念
模糊测试(Fuzzing test)[17]是最初由威斯康星大学的巴顿米勒在1989 年开发的一种软件测试技术。模糊测试技术通过自动或者半自动地生成无效、意外或随机数据作为计算机程序的输入,然后监视程序是否出现异常,例如崩溃、内置代码断言失败等情况,以发现程序中可能存在的错误。
和传统的漏洞挖掘方法比起来,模糊测试更具优势。由于模糊测试是通过动态实际执行的,而不是静态分析,所以它比基于源代码的白盒测试的适用范围更广、误报率更低;模糊测试原理简单,不存在大量的公式计算和理论推导;其自动化程度高,不同于逆向工程中需要大量的人工参与。模糊测试技术的这些优点让其成为一种备受欢迎的漏洞挖掘技术。
2.2.2 类型
模糊测试可以分成基于生成的模糊器和基于变异的模糊器,区分它们的关键取决于输入是从头生成还是通过修改现有的输入来生成:
1)基于生成的模糊器是从头开始生成输入,它不依赖于种子输入语料库的存在或质量。
2)基于变异的模糊器在模糊过程中是根据现有的种子输入语料库进行的,它通过修改或者突变提供的种子向量来生成输入数据。
2.3 Selenium Webdriver
Selenium[18]是一个由ThoughtWorks 公司开发的,用来自动化测试Web 应用程序的工具。它能够直接运行在浏览器上,像真正的用户一样操作网页。
Webdriver 是一组由W3C 协会制定的用来描述浏览器操作的标准接口。Selenium Webdriver 无法在浏览器上直接运行,必须先运行部署在本地的Webdriver 驱动程序,接着根据驱动程序来启动浏览器,从而控制浏览器去执行测试脚本。
3 基于模糊测试的反射型XSS漏洞检测
本文设计的XSS 漏洞检测系统整体结构分三个部分,分别是网页爬虫模块、模糊测试用例生成模块以及攻击与分析调整模块。网页爬虫模块又包括爬取子模块和网页分析子模块,爬取子模块主要负责爬取网站中指定深度的所有有效链接,然后将其传送到网页分析子模块来对页面中的用户输入点进行提取,并保存到数据库中。模糊测试用例生成模块主要负责通过向爬取到的注入点注入探子向量来获取输出点类型,并且选择对应的攻击语法形式并用带有权重值的元素进行填充,以此构造初始有效载荷并进行变异模糊化得到变异攻击载荷进行测试。攻击与分析调整模块主要是将生成的有效载荷通过注入点发送到被测系统(System Under Test,SUT),并且通过观察服务器返回的响应对元素权重进行调整,由此形成攻击成功率更高的攻击载荷进行检测,从而发现漏洞。系统总体结构如图1所示。
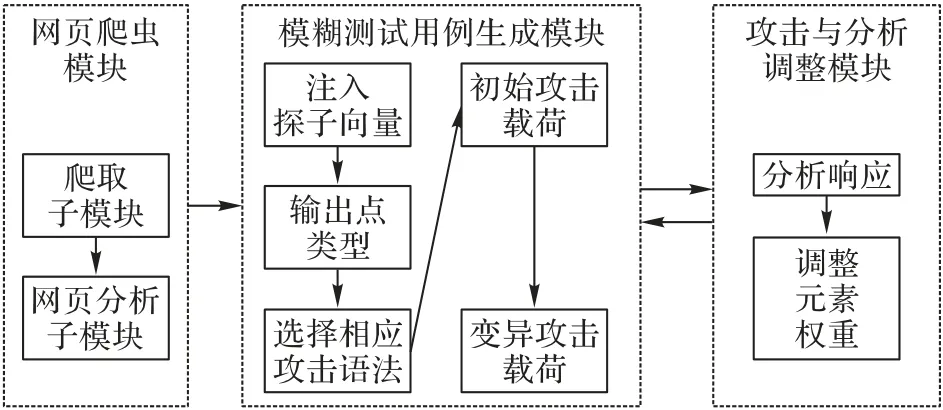
图1 系统总体结构Fig.1 Overall system structure
3.1 网页爬虫模块
该模块主要负责对指定网站中的用户输入点进行获取并保存。首先,本文使用基于广度优先遍历的网络爬虫策略,通过用户提供的起始URL 作为入口,爬取指定深度的所有有效URL 并将其发送到网页分析子模块,在对URL 页面内容进行解析时,采用定位功能来对所需要的元素信息进行定位,从而获取到页面中存在的用户输入点,将其提交地址与输入内容保存到数据库中,以便之后的注入测试使用。
当然,现在大部分网站需要通过登录用户名和密码才能访问,所以该模块可以提供网站的cookie 信息来获取页面的超文本标记语言(HyperText Markup Language,HTML)内容。在采集页面中的信息时,由于目前的Web 网页中很多内容都是非静态的,需要通过点击事件或滑动页面等操作才能显示出来,针对这些需要动态加载的数据,本文提取了页面中的JavaScript 脚本以及其中的一些事件属性,通过JS 引擎进行编译执行,从而获取到动态URL。
在爬取过程中,获得的部分URL 可能并不是所需要的,比如一些资源文件链接、图片链接、重复URL 等,所以,对爬取到的链接地址进行有效地过滤是必不可少的步骤。主要的过滤行为有以下几种:
1)对无效URL 进行过滤。无效URL 包含非同源URL 和非正常URL 两种情况。首先,同源是指协议名、域名以及端口号都相同的网站。由于每个网站都有可能引入一些站外链接,但XSS检测仅仅是针对本站的URL,因此在爬取过程中只会采集同源URL,就是通过与被检测的起始URL 进行协议、域名、端口号的比较,如果都一致,则判定为站内域名;否则丢弃。其次就是对一些不正常的URL 进行剔除,比如说一些标签的src属性的属性值是空字符串或者伪协议,这一类的内容不应该加入到待爬取队列中。
2)对重复URL 进行过滤。在采集过程中,每个页面可能有重复的URL 会被多次获取到,进而造成重复解析、浪费系统资源的情况,因此本文使用Bloom Filter+Redis 的方法进行去重,降低重复URL的概率。
3)对相似URL 进行过滤。许多URL 可能在协议、域名、端口号以及参数上完全相同,但参数值不同,对于这类URL也没必要进行重复解析,占用资源。
4)去除不可访问URL。通过发送超文本传输协议(HyperText Transfer Protocol,HTTP)请求获取响应状态码,检查状态码是否为200,对于那些不可访问的URL,应予以剔除。
注入点提取模块的主要流程如下:
步骤1 对用户提供的初始URL 和爬取深度H进行判断:若爬取深度是0,则不需要爬取网页内容;否则,就将初始URL加入待爬取队列。
步骤2 对待爬取URL 队列进行遍历,获取该URL 对应的网页源码。
步骤3 定位查找网页源码中的全部URL 并分析其中可能的用户交互点,对其进行过滤操作后添加到待爬取队列中。
步骤4 若当前深度的待爬取URL 队列遍历结束,则将当前爬取深度加1。
步骤5 如果待爬取URL 队列为空或者是检测深度达到用户提供的爬取深度,那么爬虫结束;否则返回步骤2。
具体流程如图2所示。
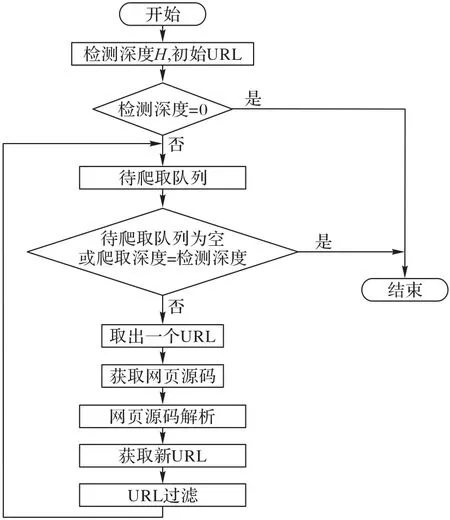
图2 爬虫提取模块流程Fig.2 Flowchart of crawler extraction module
在对页面进行解析时,一般包含两种操作行为:提取新的URL 以及获取当前页面注入点。在HTML5中,URL 通常存在于href、src、action 等可以指定网站链接的属性中。同样,一般情况下,页面的注入点则存在于form 表单的input 标签、textarea 标签或者是iframe 包含的表单中。当然,对于之前所说的潜在注入点,即那些可能导致页面DOM 结构发生变化或者说是出现更多注入点的用户交互点标签,诸如鼠标悬浮、点击事件等,此时,就需要对当前页面重新解析并提取所谓的潜在注入点和URL。本文使用python 的第三方库BeautifulSoup对页面HTML 进行URL 和注入点搜索,并存于指定队列中。主要流程如图3所示。
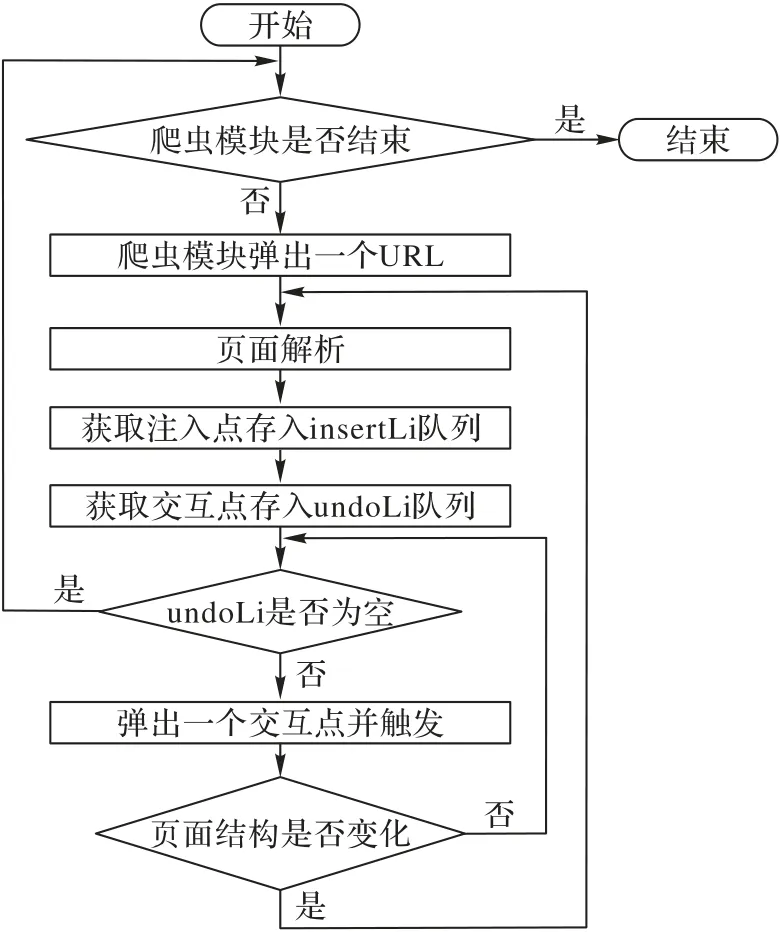
图3 注入点提取模块流程Fig.3 Flowchart of injection point extraction module
3.2 模糊测试用例生成模块
检测XSS 漏洞的主要步骤就是对攻击向量的合理选取,直接关系到检测系统的性能问题:若攻击向量选取不足或者是不适当,则会导致最终的检测结果误报漏报情况严重;但如果攻击向量选取过量又会造成检测效率的下降。所以,为了有效、有质地检测出XSS漏洞,本文开发了一个通过调整权重值方式来构造最有潜力攻击载荷的模糊测试生成器,该生成器通过接收元素作为基础数据,元素指的是JavaScript 和HTML的关键字和基本字符,使用配置文件的形式进行定义。
从理论可知,引发XSS 漏洞产生的根本原因是浏览器或者服务器端没有对用户输入的内容进行严谨或充分的过滤,所以,在检测该漏洞时要设计足够且丰富的测试向量来绕过过滤器,从而找到网站漏洞。因此,本文的攻击载荷生成模块包括初始攻击载荷生成和变异攻击载荷生成。初始攻击载荷生成模块的设计主要是为了构建种类丰富的初始XSS攻击载荷库,由于攻击载荷的选取会对漏洞的检出率产生直接影响,所以使用尽量少的攻击载荷来检测更多的漏洞是系统的关键,因此在构建初始攻击载荷库时结合了目前经过检验后比较有效的攻击向量,且尽量多地分析输出点类型,以保证初始XSS 攻击载荷库丰富而精确,为漏洞检测提供基础数据;同样,为了更多地绕过过滤机制,还对初始攻击载荷进行模糊化,形成变异攻击载荷,提高载荷精度。主要过程如图4 所示。
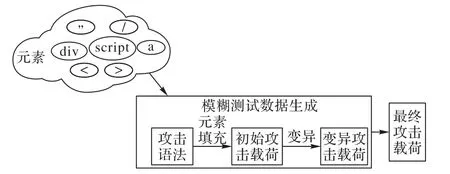
图4 攻击载荷生成模块过程Fig.4 Process of attack payload generation module
3.2.1 初始攻击载荷生成
OWASP XSS Cheat Sheet[19]是由国外著名的安全工程师Rsnake 提出的一份XSS 攻击脚本列表,可以用来对Web 应用程序中的XSS漏洞进行检测。本文将它当作适当攻击模式的参考来源,并且在对一些常见用户输出点类型分析之后,定义了自己的攻击载荷语法形式。当然,为了将语法定义转换成实际的攻击载荷,有必要对元素进行分组归类,分别将HTML标签和HTML 事件定义符号为“TAG_HTML”和“EVENT”;同时,也确定了能够被浏览器解释为空白的字符,例如“ ”“ ”等;并且,其他的一些闭合元素也被定义,这些字符或符号都被保存在配置文件中。表1 展示了部分攻击载荷语法的基本元素符号及其对应的元素。
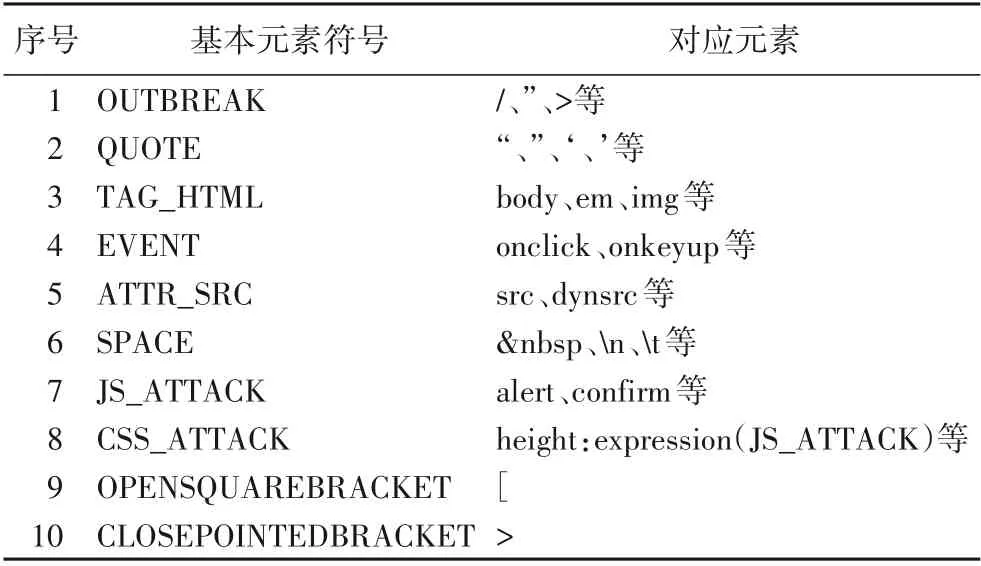
表1 基本元素符号及其对应元素Tab.1 Basic element symbols and their corresponding elements
由于在测试过程中会对每一个注入点注入大量的生成载荷,从而导致客户端与服务器的交互次数不断增加,进而降低检测效率,所以,本文在进行检测之前先使用探子请求向量进行探测,即在测试之前,构造合法向量注入输入点,然后根据响应页面的输出点类型对攻击语法模式进行选择,输出点类型一般分为如下几类:
1)HTML 普通标签之间。HTML 普通标签一般包括div、p、span、li 等,在这类标签之间则会选用诸如以下序列组成的攻击语法:
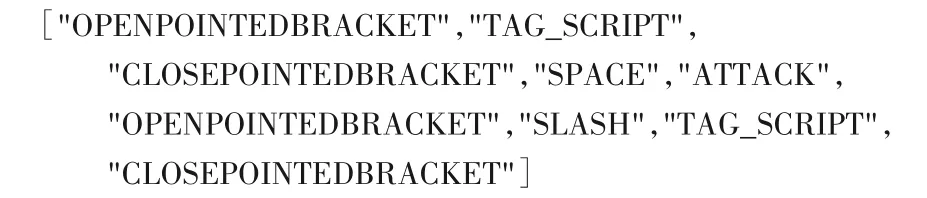
2)在HTML 标签属性值之内。此类输出点一般存在于如img的src属性、a标签的href属性。这种情况通常会先用闭合模块将前面的属性闭合,再进行正常攻击。此时可以选择诸如以下序列生成的攻击语法模板:
3)在HTML 特殊标签之间。此类标签一般是指iframe、title、noscript 之类的标签,因为在这类标签中,js 脚本无法执行,所以需要先将此类标签闭合再进行攻击,这里可以选择和第2)类一样的攻击模板,只不过在这样的攻击模板中,“OUTBREAK”不能是单纯的符号闭合,而是根据实际情况产生的标签闭合。
4)在Javascript 伪协议中。用户输出有时可能会作为js的一部分,此时可以选择诸如以下序列组成的攻击语法:
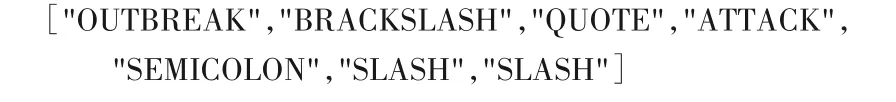
5)在层叠样式表(Cascading Style Sheets,CSS)样式中。CSS作为定义HTML的样式,主要通过