基于卷积注意力模块和双通道网络的微表情识别算法
2021-09-18牛瑞华邢斓馨吴仁彪
牛瑞华,杨 俊,邢斓馨,吴仁彪
(天津市智能信号与图像处理重点实验室(中国民航大学),天津 300300)
(*通信作者电子邮箱rbwu@vip.163.com)
0 引言
微表情作为一种有效的非语言线索,在心理治疗、司法审讯、国际反恐及国家安防[1-3]等领域具有其他语言符号无法替代的重要作用。在微表情研究初期,其识别率不足50%[4-5];近年来,微表情分析逐渐成为情感状态判定的重要因素,识别方法也从最初的人工判别向技术手段演变。
Li 等[6]率先提出了一种基线算法,使用三个正交平面的局部二值模式(Local Binary Patterns from Three Orthogonal Planes,LBP-TOP)直方图进行特征提取;Xu 等[7]则引入了光流估计的算法,根据光流的主要方向提取微表情特征;为了更好地描述光流特征信息;Liu 等[8]提出了更加简单有效的基于空间局部纹理的主方向平均光流法(Main Directional Mean Optical-flow,MDMO)[9],但其容易丢失特征空间中固有底层的流行结构,稀疏的MDMO 可以很好地弥补这一缺陷。尽管传统的识别算法在不断优化,但在特征的自动识别上有着难以弥补的劣势,进而难以有效提高分类水平。随着研究的不断深入,深度学习开始应用于微表情识别领域。Peng 等[10]使用了迁移学习的算法,将在ImageNet 上预训练的ResNet10 用于微表情数据集,并进行参数微调;Khor 等[11]进一步提出丰富的长期递归卷积网络(Enriched Long-term Recurrent Convolutional Network,ELRCN),利用卷积神经网络(Convolutional Neural Network,CNN)模块完成微表情序列的特征向量编码,利用长短期记忆(Long Short-Term Memory,LSTM)网络进行微表情分类。文献[12-13]分别提出了顶点帧时间网络(Apex-Time NETwork,ATNET)和基于顶点帧的混合卷积特征网络(Stacked Hybrid Convolution Feature Network,SHCFNet),通过计算顶点帧(apex frame,表示微表情状态幅度最大的图像帧)与序列中某一代表帧的光流特征并利用CNN 完成微表情识别,可节省计算图像序列的网络开销。但使用多张图片的微表情识别需要有记忆功能的特定网络,且会产生一定的冗余信息,若只利用顶点帧进行微表情识别,可以更广泛地选取适合网络以更好地提取微表情特征,也可进一步降低识别过程的复杂性。Zhou 等[14]通过样式聚合和注意力转移(Style Aggregated and Attention Transfer,SAAT)的算法实现顶点帧分类,Pan等[15]提出了层次支持向量机(Hierarchical Support Vector Machine,H-SVM)的顶点帧识别算法,Quang等[16]则直接使用CapsuleNet完成顶点帧的特征提取和识别分类。上述算法相比基线算法可以达到较好的识别效果,但利用神经网络的特点更好地关注微表情的细微特征并获取最有效的特征,才是提高微表情识别效果的有效路径。
文献[17]提出的高度耦合的双通道网络(Dual Path Networks,DPN)算法同时具备细化特征和探索特征的双重优势,在图像分类、场景分类、目标检测等领域展现出极大的优势。文献[18]提出的卷积注意力模块(Convolutional Block Attention Module,CBAM)是一种从通道和空间维度进行双重特征权重标定的注意力模块,它依据多方向的特征增强改善网络识别效果。本文以DPN 为主要框架,融合CBAM,提出一种微表情识别算法——CBAM-DPN。使用该算法得到的模型可以在发现微表情细微特征的同时有效突出重点区域,实现了对微表情顶点帧的识别分类,充分发挥了CBAM 和DPN 的优势。实验结果表明,CBAM-DPN 算法有效提高了微表情的识别性能,未加权F1 值(Unweighted F1-score,UF1)和未加权平均召回率(Unweighted Average Recall,UAR)分别可以达到0.720 3和0.729 3,相对现在的微表情识别算法有较大优势。
1 本文算法
1.1 DPN
DPN结合了ResNet[19-20]细化特征使特征重复使用和DenseNet[21]支持更多新特征细节探索的共同优点,是典型的混合网络。DPN 内部具有高度耦合的双通道链路连接结构,可有效解决深层网络训练时梯度消失的问题,在高计算效率的基础上保证了更少的参数开销。DPN 由多个模块化的Micro-block 堆叠而成,每个Micro-block都采用了1×1,3×3,1×1的Bottleneck层设计,通过ResNet和DenseNet 的Bottleneck层共享形成了一个双路径网络。
DPN 迭代训练的典型特点是Bottleneck 结构最后一个卷积层的输出会根据比例合理地划分为两部分:一部分进入ResNet路径(为提高每个Micro-block的学习能力,使用ResNet的一种变体ResNeXt[22]结构);另一部分进入DenseNet 路径;两个路径输出的特征矩阵进入下一个Micro-block前又会进行合并操作,便于特征提取。如此循环,既很好地探索了新特征又保证了网络的灵活性,同时具备两种路径拓扑结构的优势,Micro-block 网络结构如图1 所示。第k个Micro-block 的特征映射矩阵的推导过程可以用式(1)表示:
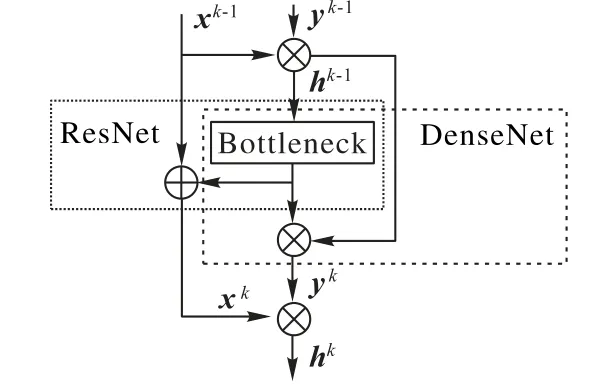
图1 Micro-block的结构Fig.1 Structure of Micro-block
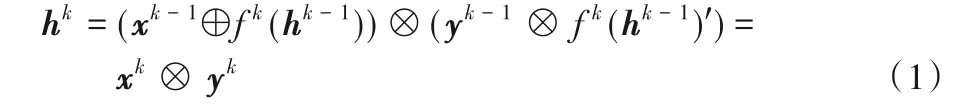
其中:“⊕”表示add 操作;“⊗”表示concat 操作;hk-1为第k-1 层输出的特征映射矩阵;hk为经过concat 操作后得到的新的特征映射矩阵;f k(⋅)和f k(⋅)'为经过Bottleneck 结构后分别进入ResNet 路径和DenseNet 路径的函数;xk-1和yk-1分别表示第k-1层ResNet路径和DenseNet路径的特征映射矩阵。
1.2 CBAM-DPN
1.2.1 CBAM
CBAM[23]是结合了通道和空间这两种不同方向的双重注意力选择模块,可以多方位进行卷积,从而取得更好的效果。其原理是:通过一层新的权重赋值将输入数据中的关键特征标识出来,从而让神经网络学习到输入数据中需要关注的特征区域。CBAM的原理如图2所示。

图2 CBAM的原理图Fig.2 Principle diagram of CBAM
CBAM 将原神经网络卷积层的输出矩阵F∈RC×H×W作为该模块的输入矩阵。该模块在通道维度上对输入矩阵同时进行最大池化和平均池化操作,并对得到的2 个不同的信道描述符进行压缩合并操作,合并后的描述符经过单个卷积核的隐藏层生成通道权值矩阵F′∈RC×H×W,如式(2)所示。而空间注意力模块作为通道注意力模块的扩充部分,是在空间维度上使用最大池化和平均池化并将信息压缩为一个信道描述符,经过空间压缩操作的计算得到空间权值矩阵F″,如式(3)所示。上述操作可建模像素点之间的重要程度以有效突出信息区域。


其中:Ms(F)∈RC×H×W和Ms(F′)∈RC×H×W分别表示三维的通道压缩权值矩阵和空间压缩权值矩阵;“⊙”表示矩阵元素的乘操作。
1.2.2 CBAM-DPN的单个结构
CBAM-DPN 的结构优化是将CBAM 融合到每个Bottleneck 层之后,形成一个新的Mirco-block 结构。CBAMDPN 结构可以在获得Bottleneck 层的共享权重后,根据通道、空间的不同重要程度去增强有用特征并抑制无用特征,从而增强网络的特征表达能力,实现对卷积层输出的特征矩阵中信息区域的有效突出。CBAM-DPN中单个结构块的计算单元结构如图3所示。

图3 单个结构块的计算单元结构Fig.3 Calculation unit structure of single structure block
图3 中:hk-1为第k-1 层输出的特征映射矩阵,即经过上一个Mirco-block的卷积变换后得到的非线性特征映射。hk-1经过Bottleneck层和CBAM的过程可以具体化为如下公式:

输入CBAM-DPN 单个结构的特征矩阵经过Bottleneck 层式(4)~(6)所总结的过程进行权重赋值,得到新的特征映射矩阵。为进一步突出特征矩阵内的有效区域,进入CBAM,在模块内依次经过通道和空间维度,两个维度中的平均池化和最大池化层可以完成特征降维并实现特征的有效突出,通道维度中的多层感知机(Multi-Layer Perceptron,MLP)可以根据需要改变输出特征矩阵的维度。通过空间和通道的双维度特征提取得到新的特征映射矩阵Uk,从而实现信息区域的有效突出。
1.3 CBAM-DPN算法设计
CBAM-DPN 微表情识别算法的主要步骤如图4 所示。对微表情数据集进行图像预处理,获取到微表情序列的顶点帧,将其转化为图像矩阵并作为InputBlock 模块的输入数据。Input Block 模块会对输入数据进行批归一化操作以加快所训练模型的收敛速度,并粗略筛选有效特征矩阵。然后,特征矩阵进入双通道Block,每个双通道Block 都会存在一个Transition 层[24]。Transition 层的结构只存在于每个Block 的第一个Micro-block 之前,既可以承接上一个Block 的特征信息,又可以减少网络参数,降低数据冗余量。CBAM-DPN 共存在4 个Block 结构,每个Block 中Micro-block 的数量直接决定了整个CBAM-DPN 的深度,可以根据数据集大小,完成对每个Block 中Micro-block 个数的划分,实现更好的模型训练效果。特征矩阵经过双通道Block后会提取到丰富的特征信息,通过自适应平均池化层进行下采样,实现特征矩阵降维,减少计算量。在全连接层前加入Dropout 层,可以进一步降低特征冗余,加快运算速度,一定程度上解决过拟合问题的出现。最后,通过全连接层将特征矩阵展成一列并连接在一起,根据每个数值的权重占比进行微表情状态概率的评估,根据概率大小完成微表情状态的分类。
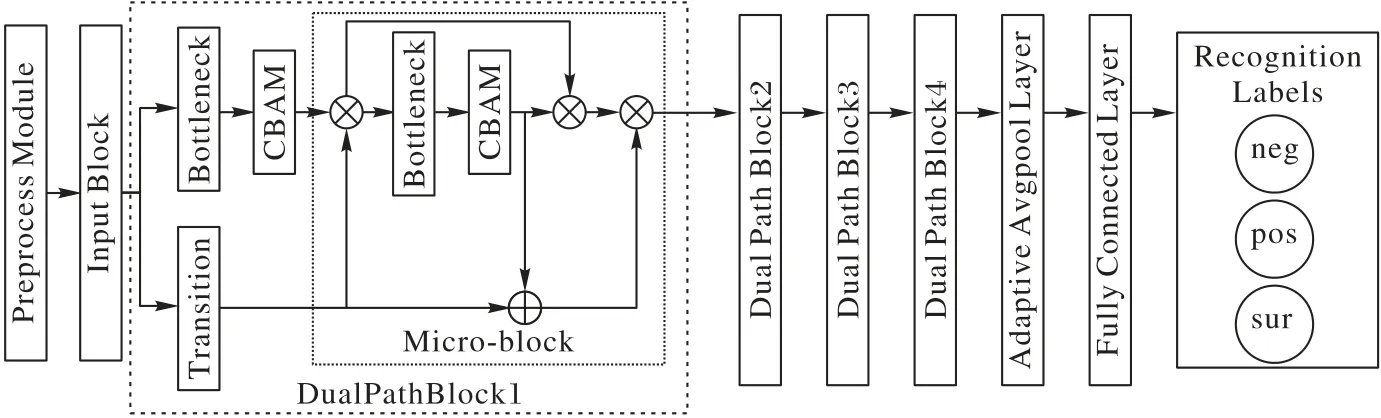
图4 基于CBAM-DPN的微表情识别算法Fig.4 Micro-expression recognition algorithm based on CBAM-DPN
2 实验与结果分析
2.1 微表情数据集预处理
2.1.1 数据融合
根据国际微表情识别大赛(facial Micro-Expression Grand Challenge,MEGC)建模标准,对SMIC(Spontaneous MICroexpression database)[6]、CASMEⅡ(Chinese Academy of Sciences Micro-Expression databaseⅡ )[25]和 SAMM(Spontaneous Activity and Micro-Movements)[26]三个数据集进行数据融合。
SMIC 数据集记录了16 名受试者的164 个微表情片段。每个微表情片段的帧率和分辨率均为100 frame/s和640×480,微表情状态分别为“积极”“消极”和“惊讶”。
CASMEⅡ数据集由26 名平均年龄在22.03 岁的受试者提供,共255 个微表情片段。每个微表情片段的帧率和分辨率均为200 frame/s 和640×480,共7 种微表情状态:“高兴”“惊讶”“悲伤”“厌恶”“恐惧”“压抑”和“其他”。
SAMM 数据集由32 名多种族、平均年龄33.24 岁的受试者提供,共159 个微表情片段。每个微表情片段的帧率和分辨率均为200 frame/s 和2 040×1 088,共8 种微表情状态,分别是:“高兴”“惊讶”“悲伤”“愤怒”“恐惧”“厌恶”“轻蔑”和“其他”。
由于三个数据集的微表情状态划分不完全相同,为避免数据融合导致问题复杂化,根据SMIC 标签重新分类,具体为“高兴”重新 标注为“积极”;“厌恶”“压抑”“愤怒”“轻蔑”“悲伤”和“恐惧”重新标注为“消极”;“惊讶”类别保持不变;“其他”微表情状态不作为实验样本。
融合数据集共包含68 名受试者的442 个微表情顶点帧,具体内容见表1。为了得到更好的微表情识别模型,将训练数据集扩充为融合后数据集中顶点帧的相邻四帧。顶点帧数据集中“惊讶”“积极”和“消极”的比例大约为1∶1.3∶3,为降低微表情状态数量不均衡对训练效果的影响,采用重采样技术[16]均衡训练数据集输入神经网络时不同微表情状态的比例。

表1 用于实验的微表情融合数据集Tab.1 Micro-expression fusion datasets used for experiments
2.1.2 图像预处理
模型训练所用的图像应包含尽量少的无关信息,但SAMM 数据集提供的图像包含较多的无关背景信息,这些信息的存在会影响神经网络对特征信息的提取。本文使用多任务卷积神经网络(Multi-Task CNN,MTCNN)[27]对SAMM 数据集中的图像进行裁剪,得到几乎不包含背景信息的图像。裁剪前后的对比如图5所示。

图5 图像裁剪前后的对比Fig.5 Comparison of images before and after clipping
三个数据集中,只有CASMEⅡ和SAMM 数据集注明了顶点帧位置,SMIC 数据集的标签只注明了起始帧和结束帧,并未对顶点帧位置进行说明。本文对微表情数据集中标记了顶点帧位置的序列进行统计,发现顶点帧并不在序列中某一固定位置;故通过科学的计算方法,寻找顶点帧的位置也是必要工作。
通过python 中的开源模块face-recognition[28]识别人脸,获取到人脸的68 个面部特征点;根据获取到的特征点以半个唇宽度为标度尺,将面部肌肉活动最频繁的10 个区域进行定义,分别是:唇左半部分、唇右半部分、下巴、左侧鼻翼、右侧鼻翼、左眼左侧、右眼右侧、左眉右侧、右眉左侧以及两眉之间。图6是68个特征标记点和定义的十个区域的具体位置。

图6 68个特征点及定义区域的具体位置Fig.6 Location of 68 characteristic points and defined areas
为确定微表情序列中的顶点帧位置,将图6 中定义的10个区域作为计算微表情特征变化的区域;依次计算10 个区域中当前帧与开始帧像素差的绝对值及当前帧与结束帧像素差的绝对值并求和;为降低图像中环境噪声对计算结果的影响,同时计算当前帧与相邻帧像素差的绝对值,让两值做比,进行归一化处理。然后,将10 个区域归一化后的值求平均,并找出均值中的最大值Fmax。

其中:xi、oni、offi分别为定义的十个区域中当前帧、开始帧和结束帧中的某一个区域。为保证式(8)有意义,同时对分子分母进行加1 的操作。式(9)是对定义的十个面部区域求和并均值化。均值Fi的大小可以直接反映当前表情状态与中性表情状态的差异量。顶点帧应为整个序列中差异量最大的帧Fmax,关于均值Fi的值在整个序列中的变化如图7 所示(其中虚线表示顶点帧位置)。

图7 一个微表情序列中不同帧像素均值的变化过程Fig.7 Change process of pixel mean of different frames in a micro-expression sequence
2.2 实验环境及参数设置
实验使用的计算机硬件配置:处理器为Intel Xeon E5-2630,CPU频率为2.20GHz,GPU加速显卡为Tesla P100-PCIE,显存为16 GB,操作系统为Ubuntu 16.04.3,深度学习开发平台为Pytorch 1.1.0框架。
实验中设置如下参数:优化器引入自适应的Adam 方法;学习率设为0.001,并通过指数衰减调整学习率,学习率的衰减设为0.9;训练时批处理数量为32,epoch 为100,训练测试过程中使用的损失函数为Margin Loss函数。
2.3 实验评价标准
本文采用LOSOCV(Leave One Subject Out Cross Validation)作为微表情融合数据集的评估方法,具体操作是每次从68 名受试者的微表情样本中依次选择1 名作为测试集,其余为训练集,直至所有受试者的样本都做过测试集,将所有的测试结果合并作为最终的实验结果。这种评价方法适用于小样本的微表情数据集,既保证了三个数据集在评价时的独立性,又很好地考虑到了种族、性别、微表情幅度大小等的区别。基于三个数据集中的微表情状态数量具有明显的不均衡性,为保证实验的评估结果更有参考意义,采用未加权F1 值和未加权平均召回率两个指标来评估DPN 和CBAMDPN模型的识别性能。
未加权F1 值(UF1),也称作宏平均F1 值。UF1 可以同等强调稀有类,在多分类问题中是个很好的选择。UF1 可以用式(10)计算:

其中:TPc、FPc、FNc分别为类别c中真正、假正和假负的数量,即实际类别为c预测也为c的数量、实际类别不是c预测为c的数量和实际类别是c预测不是c的数量。对C个类别的比值求平均得到UF1。
未加权平均召回率(UAR),也称“平衡准确率”,是一种较标准准确率(或加权平均召回)更合理的评价标准。UAR可以用式(11)计算:

其中:Nc为样本c的数量;TPc为样本c中预测正确的数量。对C个类别的比值求平均得到UAR。
UF1 和UAR都可以公平对待少数特定类,公平地评估模型在所有类上的表现。
2.4 实验结果分析
2.4.1 算法复杂度
衡量模型的算法复杂度主要从空间复杂度和时间复杂度上考虑。空间复杂度即模型参数量,直接决定了参数的数量,受维度影响,模型的参数越多,训练模型所需的数据量就越大,若实际数据集不太大,参数过多则容易导致模型训练过拟合。时间复杂度即模型的运算次数,一次运算可以定义为一次加乘运算,用浮点运算次数作为衡量标准,其大小直接决定了模型的训练时间,如果复杂度过高,会导致模型训练和预测耗费大量时间,既无法快速地验证和改善模型,又无法做到快速预测。
表2列出了DPN和CBAM-DPN在不同网络层数上模型的算法复杂度的对比情况。输入数据相同的条件下,同一算法会因网络层数的增加导致算法复杂度的增加;针对相同网络层数,算法改进前后模型复杂度的变化非常小。因此,将CBAM 嵌入DPN 的优化算法,使模型整体的参数数量和计算量的增长基本可以忽略不计,是一种十分节约开销的优化算法。

表2 不同层数模型的算法复杂度对比Tab.2 Algorithm complexity comparison of different layer models
2.4.2 损失值
训练集损失值的大小可以直观衡量模型训练效果的好坏,损失值越小,模型训练的收敛度越高,鲁棒性就会越好,测试结果也会更接近真实值。图8 为20、26 和38 层的DPN 和CBAM-DPN 训练模型的损失值随epoch 次数变化的对比。三张图中的损失值都会随epoch 次数的增加而逐渐减小,最后趋于平稳。网络层数改变损失值也会发生相应变化,当层数为26和38时,两个模型平稳后的损失值基本不会因层数改变而发生较大变化,证明该深度下的模型基本收敛;此时,DPN模型平稳后的损失值在0.05左右,而CBAM-DPN 模型可以保持在0.04 左右。分别对比三种层数下模型改进前后的损失值,发现同一层数上CBAM-DPN 模型的损失值都会比DPN 模型的损失值下降速度更快,且趋于平稳后的值更低。可以说明CBAM-DPN 模型较DPN 模型可以达到更好模型训练效果。

图8 模型优化前后的训练损失值对比Fig.8 Comparison of loss in training before and after model optimization
2.4.3 特征区域可视化
在训练模型的过程中,训练效果的好坏可以通过损失值及测试准确度等结果展示出来,但模型对特征的提取能力难以通过训练过程直接反映出来。基于Grad-CAM(Gradientweighted Class Activation Map)的算法[29]构建特征区域可视化,该算法可以实现模型所关注区域的可视化,充分体现模型的特征提取能力。输入图像在前向传播至模型的最后一层卷积后获得特征映射矩阵,对特征映射矩阵求平均梯度值得到权重矩阵,权重矩阵中每一维的数值代表判定图像类别的重要程度。权重矩阵与特征映射矩阵线性相乘,再通过ReLU函数过滤,可以得到模型关注区域的热力图。将热力图放大到与输入图像尺寸相同,然后进行加权相加就得到识别分类模型所需要关注区域的可视化图像。
DPN 和CBAM-DPN 模型所关注和强调的特征区域如图9所示。输入图像经过同样层数DPN 和CBAM-DPN 模型进行特征提取。图9(a)中的DPN 模型只关注到了动作幅度较大的眼周及唇部等位置,而图9(b)的CBAM-DPN 模型关注到的区域涉及了几乎所有产生微表情动作的区域,说明CBAMDPN 模型比DPN 模型关注的特征区域更广,CBAM 具有更强的发现细微特征的能力。图9 中颜色的深浅代表了关注区域所占权重的大小即被模型所强调关注的程度,图9(a)中关注区域整体的颜色较浅,即DPN 模型关注区域整体所占权重并不高,特征提取的能力不强;而相同区域下图9(b)的CBAMDPN 模型关注区域的颜色更深,可以说明在动作幅度较大的区域内,CBAM-DPN 模型比DPN 模型的权重值更大,CBAM 可以有效突出特征区域。

图9 DPN和CBAM-DPN模型关注的特征区域Fig.9 Feature areas that DPN and CBAM-DPN models focus on
2.4.4 识别效果
在神经网络的模型构建过程中,训练过程可以训练模型对微表情的识别能力,测试过程则可以验证所训练模型的鲁棒性和泛化能力。图10 分别列出三种不同层数的DPN 和CBAM-DPN 模型在融合数据集上UF1 和UAR的测试结果。从实验结果可以看出改进后的CBAM-DPN 模型在层数相同的情况下,测试效果均优于DPN 模型。可以说明优化后CBAM-DPN 模型具有更强微小特征的信息提取能力,可以实现更优于DPN模型的识别效果。
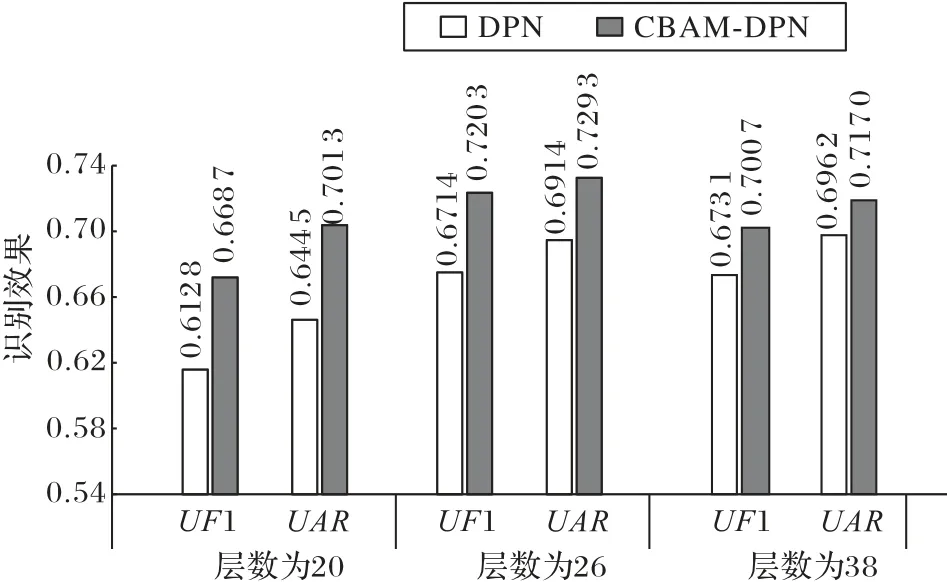
图10 优化前后模型不同深度的识别效果对比Fig.10 Comparison of recognition effect of different depth models before and after optimization
选择识别效果最好,网络深度为26 层的DPN 及CBAMDPN模型与其他几种基于顶点帧进行微表情识别的模型进行对比,识别效果对比如表3 所示。表3 中对比的模型均使用UF1 和UAR的评价标准、LOSOCV 的验证算法,实验均在SMIC、CASMEⅡ、SAMM 以及三种数据集的融合数据集上进行。CBAM-DPN 模型整体的UF1 和UAR识别效果可以达到0.720 3 和0.729 3,是几种算法中效果最好的。在这之前,几种基于顶点帧的微表情识别模型中效果最好的是CapsuleNet,其模型的参数量为13.400×106,所需算力是7.585 GFLOPs,而CBAM-DPN 模型的参数量为5.114×106,算力是943.600 MFLOPs,在大量降低计算复杂度的基础上提高了识别效果。

表3 不同模型的识别效果对比Tab.3 Comparison of recognition effect of different models
图11 是根据CBAM-DPN 模型对融合数据集中三种微表情状态的识别结果绘制的混淆矩阵图(“neg”“pos”和“sur”分别代表“消极”“积极”和“惊讶”)。整个融合数据集中三种微表情状态的比例非常不均衡,其中“消极”样本的数量超过了样本总量的50%,训练中采用的重采样技术使接受训练的样本数量基本保持1∶1∶1 的比例。根据最后的测试结果可以看到“消极”“积极”和“惊讶”样本召回率(recall)分别是0.77,0.67 和0.75,这充分说明了在训练CBAM-DPN 的模型时,采用重采样技术对抗数据不平衡的有效性。CapsuleNet 的平均召回率只有0.65,而CBAM-DPN 模型对三种微表情状态的平均召回率可以达到0.73。

图11 CBAM-DPN模型在融合数据集上的测试结果的混淆矩阵Fig.11 Confusion matrix of CBAM-DPN model test results on fusion dataset
根据统一的评价指标综合比较不同算法的模型识别效果,可以发现CBAM-DPN 的效果最好。在模型识别效果较优的前提下进一步比较模型总体参数的大小,CBAM-DPN 的模型参数也远小于CapsuleNet。综上,可以充分说明使用优化后的CBAM-DPN算法进行微表情识别的有效性。
2.4.5 更多微表情状态实验及结果分析
上述实验及结果分析均针对三种微表情状态展开,虽然在相同的微表情分类条件下,与前者实验成果相比,优化后模型的识别效果具有一定程度的提高;但真实场景下微表情状态的划分更为精细,仅划分为积极、消极和惊讶三大类,难以满足实际应用需求。
为了更全面地验证所提出模型的泛化性,使用CASMEⅡ数据集分别对DPN 和CBAM-DPN 模型进行更多类别微表情状态的识别训练并进行测试。实验方案中除数据集发生变化及未采用重采样技术,实验环境、参数设置及评价标准等均与三类微表情状态识别的实验保持一致。CASMEⅡ数据集的七类微表情状态中,“悲伤”和“恐惧”的样本数量分别为4 和2,为避免微表情状态数量过少影响模型的训练、测试效果,将这两类状态去除,对另外五类共244 个有效样本进行训练和测试。另外五类样本的具体数量如表4所示。

表4 CASMEⅡ数据集中用于实验的各微表情状态的数量Tab.4 Number of different micro-expression states used in experiments in CASMEⅡdataset
2.4.4 节中,三类微表情识别的实验已经验证网络层数相同时,CBAM-DPN 模型的测试结果均优于DPN 模型,且当模型层数为26时,模型会基本收敛。故针对CASMEⅡ数据集的实验,只设计了一组层数为26 的对比实验,训练过程中DPN 和CBAM-DPN 模型的损失值趋于平稳时,均可以保持在0.05 左右,说明模型训练基本完成。关于模型具体的识别效果如表5所示。

表5 DPN和CBAM-DPN模型在CASMEⅡ数据集上的识别效果对比Tab.5 Comparison of recognition effect of DPN and CBAM-DPN models on CASMEⅡdataset
由表5 中的实验结果可以看出,虽然因为识别类别的增加以及数据集的大量减少,会在一定程度上影响模型的识别效果,但对比同一网络层数下DPN 和CBAM-DPN 模型的识别效果可以发现,CBAM-DPN 模型的识别效果是优于DPN 模型的。
进一步衡量两个模型对同一数据集的识别能力,将两种模型对每一类微表情的召回率分别绘制混淆矩阵,如图12 所示(“rep”“hap”“sur”“dig”和“oth”分别代表“压抑”“高兴”“惊讶”“厌恶”和“其他”)。混淆矩阵中每一类的召回率会随着样本数量的增加变高,其中样本数量最多的“其他”类别,召回率可以达到0.70 及以上,可以说明两种模型均具有识别更多微表情类别的能力。对比DPN 和CBAM-DPN 模型对每一类微表情的召回率,大部分类别CBAM-DPN 模型的召回率优于DPN 模型的召回率;CBAM-DPN 和DPN 模型的平均召回率分别为0.486和0.468,说明优化后的模型具有更好的识别微表情状态的能力。

图12 CASMEⅡ数据集上测试结果的混淆矩阵Fig.12 Confusion matrices of test results on CASMEⅡdataset
综合比较更多分类状态下的微表情识别效果,可以充分说明CBAM-DPN 模型及DPN 模型均具有识别更多微表情状态的能力;优化后的CBAM-DPN 模型比DPN 模型具有更好的微表情识别能力和更强的泛化性,可以更广泛地应用于微表情识别领域。
3 结语
本文以双通道网络(DPN)为主要框架,融合卷积注意力模块(CBAM),提出了一种基于CBAM-DPN 的算法,并基于该优化算法实现了对微表情序列顶点帧状态的识别。通过综合比较模型的参数、浮点运算次数和实验结果,可以表明基于CBAM-DPN算法对融合数据集进行微表情识别效果优于DPN算法及典型的微表情识别算法,是对DPN 算法的有效改进。本文实验采用融合了3 个数据集的融合数据集,这种方式既增加了样本数量,又增加了样本的多样性和样本环境的复杂性,更贴近真实的微表情产生场景。此外,本文方案采用的重采样技术,大大降低了样本类型不均衡对识别效果的影响;同时,在少量的样本数据下,采用LOSOCV 评估方法,充分保证了评估对象的独立性。为进一步验证模型应用到实际场景中的能力,实验对比更多微表情状态下DPN 与CBAM-DPN 模型的微表情识别效果,说明了两种模型均具有识别更多微表情状态的能力且CBAM-DPN 模型具有更好的识别能力和泛化性。因此,本文所提供的算法具有较强的实用性。为进一步提高CBAM-DPN 的识别效果,后期拟先通过ImageNet 等数据量充足的数据集对CBAM-DPN 进行预训练,再通过迁移学习的算法将预训练后的模型用于微表情识别。
