基于K-means算法的企业信用无监督分类研究
2021-09-14施天虎韦诗玥
施天虎 韦诗玥


摘要:企业信用分类的应用,能够为商业银行降低信贷业务的风险,随着市场竞争的不断加剧,机器学習和大数据的应用,越来越多的计量方法不断革新,并广泛运用到信用分析领域。本文设计了一个基于K-means算法的企业信用无监督分类方法,通过对企业信息进行大数据分析,提取企业信用相关的内容,再使用K-means算法对企业数据进行聚类,对目标企业根据其聚类所在簇来评估信用等级,以此对企业的信用进行分类。
关键词:企业信用;信贷风险;K-means算法;分类;特征选择
Abstract: The application of corporate credit classification can reduce the risk of credit business for commercial banks. With the continuous intensification of market competition, the application of machine learning and big data, more and more measurement methods continue to innovate and are widely used in the field of credit analysis. This paper designs an unsupervised classification system for corporate credit based on the K-means algorithm. Through big data analysis of corporate information, the content related to corporate credit is extracted, and then the K-means algorithm is used to cluster the companies, and the target companies are based on their The clusters where the clusters are located are used to evaluate the credit rating and thus classify the credit of the enterprise.
Key words: Corporate credit; Credit Risk; K-means algorithm; classification; Feature selection
1引言
金融行业积累了大量的企业脱敏数据信息,企业的有效划分及标识在企业信用评估、企业风险监测中具有重要作用并受到各大平台的重点关注[1]。金融场景中企业作为信贷主体的数据覆盖互联网、政府、线上应用等来源的方方面面,数据量大,来源广泛、涉及企业的维度丰富[2]。企业信用分类的应用,为商业银行降低企业信贷业务风险,创新风险管理理念,探索出一条行之有效的解决办法[3]。随着大数据、人工智能的发展和市场竞争日益加剧,大量基于机器学习的信用评估分类方法提出并广泛应用于企业信用分析[4]。本文将企业脱敏数据信息进行特征选择,提取信用分类相关的内容,再使用K-means算法对数据进行聚类,按聚类簇划分信用等级。
2 关键技术
2.1 K-means算法
2.2 特征选择
特征选择是重要的数据预处理方法,在数据中选出重要特征可以降低数据维度、去除多余的变量,提高算法的精度和效率。
本文使用皮尔森相关系数[6]对数据进行特征选择,皮尔森相关系数能够获取特征和变量之间的线性相关系,其计算公式如下:
3 基于K-means算法的企业信用无监督分类
3.1 提取相关特征
计算数据所有特征与信用分类的皮尔森相关系数,根据结果判断该特征是否与信用分类相关。设企业的信用类别为C={x1,x2,...,xn},特征项为T={t1,t2,...,tn},相关阈值为x,当该特征项与信用类别的皮尔森相关系数大于阈值x即满足下式时选用该特征。
3.2 使用K-means算法聚类
在选取到相关特征后,使用K-means算法对企业数据进行聚类。K-means算法聚类效果的好坏很大程度上取决于初始聚类中心的选择,若选取的K个中心点中有离群点或者各中心点相互距离较近,则常导致聚类的效果不佳。针对这个问题,本文使用基于最大距离和密度相结合的初始中心选取方法。其过程如下:
Step1:设置密度阈值q,随机选择一个样本密度小于q的点作为第一个初始中心点K1。
Step2:在所有满足样本密度的点中,选择离K1最远的点作为第二个初始中心点K2。
Step3:同上方法寻找第三个点,以此类推,直至获得K个初始中心点。
用此方法可以使聚类初始中心间的距离较大,且避免存在离群点。
在将数据进行聚类后得到K个簇,以簇内企业数据占比最多的信用类别来表示该簇的类别,对目标企业计算其到各簇中心的距离,距离最近簇所表示的信用类别即表示对该企业预测的信用类别。
4 实验与分析
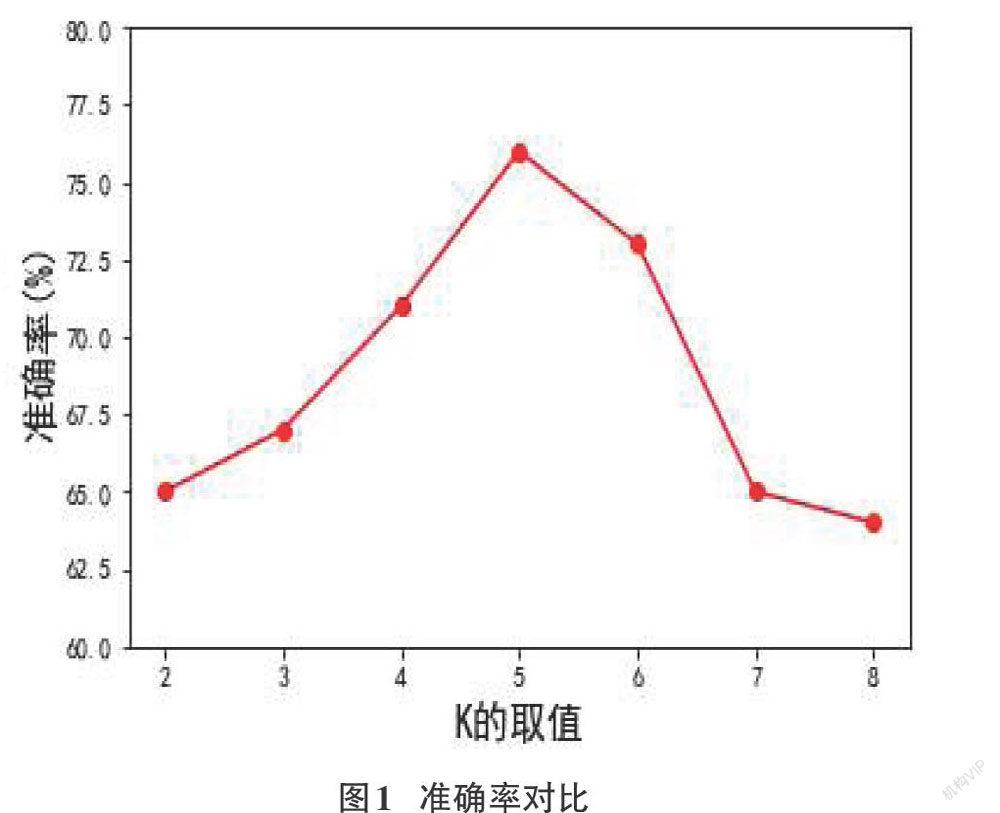
本文采用浪潮公司发布的企业脱敏数据进行仿真实验,从数据集中取1万条数据,数据集共36个特征。实验结果如下图所示:
从图1可以看出,在K取值为5时,本文算法拥有最佳准确率,表示分类效果最好。
5结束语
本文设计了一个基于K-means算法的企业信用无监督分类方法,首先提取企业信息中与信用分类相关的特征,再将企业数据使用改进中心点选取的K-means算法进行聚类,通过判断目标企业所在簇判断其信用类别,为企业信用评估提供参考。
参考文献:
[1] Simon Rogers,MarkGirolami.机器学习基础教程[M].郭茂祖,译.北京:机械工业出版社,2014.
[2] 李恩,刘立新.小微企业信用评价指标体系研究综述[J].征信,2013,31(1):67-70.
[3] 张杏枝.基于机器学习的信用评分模型研究[D].重庆:西南大学,2019.
[4] 张萌.基于层次分析法的商务领域企业信用评价模型的构建[J].中国商论,2019(14):232-233.
[5] 黄晓辉,王成,熊李艳,等.一种集成簇内和簇间距离的加权k-means聚类方法[J].计算机学报,2019,42(12):2836-2848.
[6] 马克勤,杨延娇,秦红武,等.结合最大最小距离和加权密度的K-means聚类算法[J].计算机工程与应用,2020,56(16):50-54.
【通联编辑:梁书】