基于TensorFlow.js的英文语音识别研究与实现
2021-09-14李东升苏煜辉陈正铭
李东升 苏煜辉 陈正铭


摘要:TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,而本文将介绍其衍生的js版本即TensorFlow.js框架,并且基于这个框架和浏览器环境加载一个预训练模型来实现语音识别简单孤立的英文单词的功能。通过对预训练模型的使用与优化研究,为进一步使用TensorFlow.js实现更加复杂的商业化功能做了前期探索。
关键词:预训练模型;TensorFlow.js;语音识别
1 概述
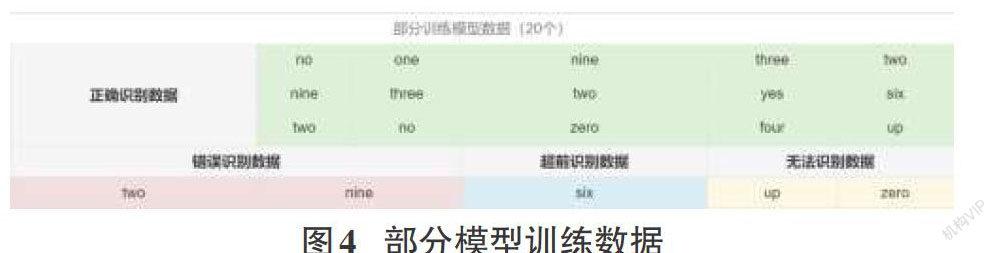
简单的语音识别实际上也是属于分类问题,而声音在计算机中是被当成声谱图,既然是图片类的,那么就可以使用卷积神经网络来构建训练模型[1]。实际上很多成熟的语音识别模型也是基于卷积神经网络构建的,本文也将采用Tfjs-model这个官方模型库里面的speech-commands这个预训练好的语音命令模型,该模型可以获取一秒的音频片段,十分适合用来实现一个简单的语音识别功能。
2 TensorFlow.js框架
2.1 TensorFlow.js特性
需要说明的是TensorFlow.js使用的是Tensor,也称为张量,有别于一般数组,它是向量和矩阵向更高维度的拓展,也可以近似的看成一个多维数组。而神经网络具有多个神经元和层,每一层都需要存储N维的数据[5],这些数据往往需要进行N层的遍历循环计算等,导致其数据结构比较复杂,因此就需要张量这样一个高维的数据结构来存储这些数据。
下文中的模型特指人工神经网络模型,主要由TensorFlow.js框架的sequential方法初始化并根据需求逐步添加输入层、隐藏层和输出层。每个神经网络模型里面都包含一个输入层、最少一个隐藏层、一个输出层,每个层由任意个(至少为1个)神经元构成。每个神经元都会包含若干权重、偏置和一个激活函数。
2.2 TensorFlow.js开发环境搭建
所谓“工欲善其事必先利其器”,第一步首先是如何安装TensorFlow.js。安装的话其实分为在浏览器安装和在node安装,考虑到浏览器的便捷性和容易上手的特性,所以介绍相对比较简单的浏览器安装。
完成上述TensorFlow.js库的安装后就可以在浏览器上运行机器学习模型或者加载预训练模型。
3 预训练模型的使用
3.1 预训练模型
3.2 预训练模型实现
由于是预训练模型,故需要从官方仓库那里下载语音识别模型文件,保存到本地文件夹中,然后就可以在本地开启静态文件服务器(http-server或者nginx皆可,这里启动的地址默认为:http://127.0.0.1:8080)并且能通过静态服务器访问到这个文件,下载这个模型文件后还需要安装对应的依赖,可以在终端命令行运行npm i @tensorflow-models/speech-commands,然后在编写业务逻辑的地方引入即可完成准备工作,接下来将新建一个script.js文件来书写具体的训练逻辑,步骤如下:
语音命令识别器的定义(在线流媒体识别方式):利用导入的模型文件里面自带的create方法建立一个识别器实例,这个识别器可以用来加载我们的预训练模型。该识别器需要传入四个参数(第一个必选,其余为可选的识别参数),这里传入了浏览器傅里叶转换、null为默认识别单词(由于已经给出模型地址故应该给null或者undefined)、预训练模型的地址、预训练模型的源文件信息(地址和信息来源于刚刚安装的语言识别依赖):
3.3模型预测
经过上面的步骤之后就已经完成了加载预训练模型,同时获得了模型的标签,接下来就可以通过监听用户麦克风的输入即特征来进行语音识别了。
监听用户麦克风:这个可以通过H5实现,但是识别器通过了listen方法也可以让开发者监听。需要获得用户输入对应词汇表中每个单词对应的符合程度,并且获取其中符合程度最高的单词,这个单词就是根据用户输入的语音识别得到的,将这个单词打印并显示到页面: