河北省治超处罚联网系统的设计与实现
2021-09-13左晓飞高志伟丁晓楠葛红志陈继宝
左晓飞 高志伟 丁晓楠 葛红志 陈继宝

摘要:为了更好地提升治超效果,加强对违规超载运输车辆、驾驶员和企业的管理,设计了治超处罚联网系统,通过采集外部系统的处罚数据和车辆、驾驶员、运输企业等基础数据,并按照相应规则对数据进行清洗、规范化处理和存储,从而满足黑名单的生成。系统实现了治超处罚形势综合分析预测、处罚信息管理、黑名单管理和处罚备案等功能,为治超工作提供助力。
关键词:超限超载;黑名单;数据治理;前后端分离
中图分类号:TP393 文献标志码:A 文章编号:1008-1739(2021)14-53-4
0引言
近年来随着国家对公路货运车辆超限超载整治和处罚力度的加大,各地治超形势稳定好转,道路交通运输行业健康有序发展。但是,由于利益驱使,部分车辆运营单位一味地追求利润,存在侥幸心理,在交管部门下班时间或夜间进行超限超载运输Ⅲ,给公路运输安全带来了不小的隐患。超限超载运输对公路危害极大,严重损害公路的使用年限,同时也是引起交通事故的主要原因之一,对人民群众的生命财产安全带来极大的安全隐患,此外超限超载也严重干扰运输市场的正常运营,不利于我国市场经济的健康有序发展。
为了更好地提升治超效果,加强对违规超载企业、货运车辆和驾驶员管理,将路面及源头查获的违规超载企业、货运车辆和驾驶员处罚信息进行联网,建立黑名单制度,对黑名单中的企业、车辆、驾驶员和源头企业进行处罚,从而减少相关人员和单位重复超限超载的次数。
本文设计的治超处罚联网系统,通过对接已有车辆驾驶员企业基础信息系统和治超执法系统,实现了全省超载超限信息的联网处理,并能够根据黑名单制度自动生成违规超载企业、车辆、驾驶员和源头企业黑名单。
1系统设计
系统的道路运输从业企业、货运车辆和驾驶员等基础数据依托基础信息系统,违规超限超载信息来源于治超执法系统,涉及到外部系统的数据融合治理,是本系统的设计难点和重点。
数据治理是将已有系统进行融合实现数据共享,减少信息孤岛的必要步骤,通过数据治理可以实现数据的标准化,将原先相互隔离的系统变为互联互通的整体,真正实现各种数据的融合和共享,推进数据的资产化和价值化。系统数据治理主要流程包括数据采集、数据清洗与规范化、数据存储。
1.1数据采集
系统需要融合2个不同系统的数据,这2个系统的数据结构、存储方式和数据提供方式均有较大差别,因此根据各自系统的特点设计了2种数据采集方式。
(1)数据库同步方式
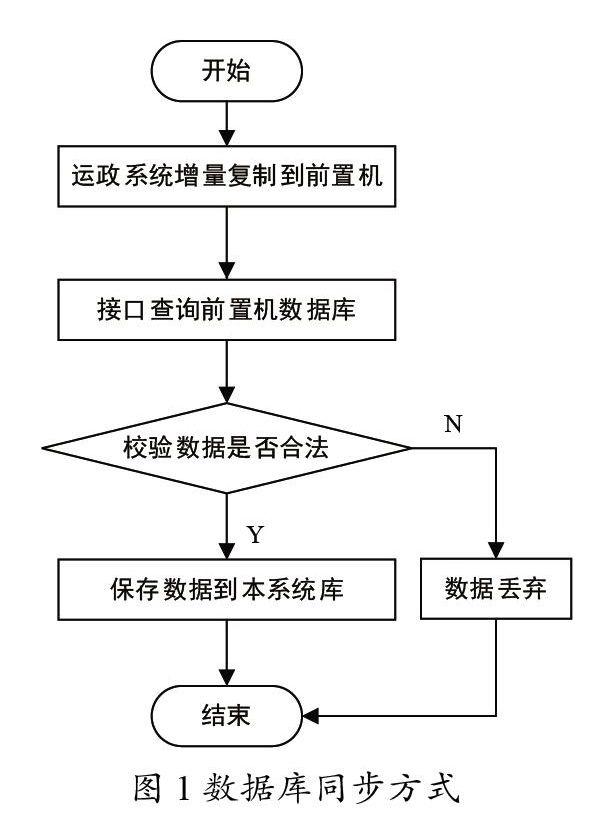
道路运输从业企业、货运车辆和驾驶员等基础数据由于数据量较大,且更新频率不高,故采用数据库同步方式进行2个系统的数据同步,具体实现方式如圖1所示。
①运政系统将前一日的新增和修改的基础数据通过增量复制方式同步到前置初数据库中;②系统接口查询前置机数据库,获取增量复制同步的基础数据;③循环判断数据是否合法;④若数据不合法,则该数据直接丢弃,不予处理;⑤若数据合法,则将该数据保存到本系统数据库;⑥本次数据同步结束。
(2)接口拉取方式
违规超限超载信息属于变化较快的动态数据,每日均会有新数据产生,是本系统生成黑名单的原始数据来源,直接关系到本系统的运行成效,因此采用接口拉取方式,每日凌晨2点定时从冶超执法子系统获取前一日全省违规超载超限信息,具体实现方式如图2所示。由于接口拉取方式获取数据需要通过网络,如只调用一次接口获取当日所有超限超载信息,则会出现数据传输耗时长、接口等待时间超时的问题,因此设计了循环调用、多次获取的方式。
①本系统开始拉取前一日数据;②从数据库获取开始时间;③调用治超执法子系统接口获取数据;④判断获取的数据条目是否达到100条;⑤若不足100条,则更新开始时间;⑥若达到100条,则开始第2次拉取,并取最后一条数据的时间为开始时间;⑦从步骤②开始循环,直到运行到步骤⑤;⑧本次接口拉取数据结束。
1.2数据清洗与规范化
数据采集后就需要进行数据清洗和规范化处理,之所以要进行这一步,主要是因为外部系统的数据规范同本系统采用的标准有差别,或者是由于外部系统所采用的规范标准比较陈旧已不能满足最新需求,此外对一些明显错误的数据进行了清洗。主要进行如下几方面的清洗和规范化。
(1)重复数据清洗
由于系统在统计企业黑名单时对该企业车辆数据的准确性要求较高,车辆统计比实际多或者比实际少,都会影响企业违规占比的计算结果,对企业是否进入黑名单有直接关系。因此系统在获取到车辆数据后,对车牌重复的车辆进行了去重。
(2)错误数据清洗
对拉取的企业、车辆和驾驶员中的明显错误数值进行更正,确保数据的正确性。对拉取的违规超载超限数据的车牌号进行规范和解析,部分车牌号前面有车牌颜色文字,因此需要将车牌颜色和车牌号属性分别解析并提取。此外也有车牌号是车头牌照加挂车牌照的组合,因此需要将车头牌照和挂车牌照分别解析并提取。
(3)行政区划代码规范
由于运政信息系统所采用的行政区划代码同本系统采用的国家民政部行政区划代码有差别,因此对不一致的行政区划代码的数据进行相应的转换,以便于在本系统内进行使用。
1.3数据存储
系统采集的数据经过清洗和规范化后就需要做持久化,根据数据的更新及访问频率采取不同的存储策略,对于行政区划、车牌颜色、车辆轴数等更新频率较低、查询频率较高的字典类型数据采用内存数据库建立缓存的方式进行存储,从而可以满足数据的查询和处理效率。对于车辆、驾驶员、企业等更新和查询频率均不高,但需要永久保存的数据,则采用关系数据库进行存储,由于车辆、驾驶员数据较多,可达百万级别,在进行模糊查询时检索效率较低,因此对部分查询字段采用全文索引的方式进行检索,经对比查询效率能够满足使用要求。
2系统实现
系统采用前后端分离的技术进行实现,项目前端采用MVVM的模式开发,通过模块化、数据绑定和自动路由的能力来简化开发,后端使用Spring Boot框架进行开发,处理相关业务逻辑,并为前端提供数据服务。传统的前后端耦合开发的方式,会使得代码冗杂,可读性和可重用性下降,前后端分离技术很好地解決了上述问题。
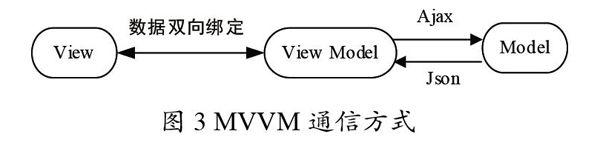
MVVM开发模式由经典的软件架构MVC模式衍生而来,可以用于在前端领域构建基于事件驱动的UI开发平台。MVVM的通信方式如图3所示。
View表示页面,Model表示数据模型,二者没有直接联系,通过ViewModel进行双向交互。MVVM的控制器不会监听浏览器的事件,而是监听一个属性表,由浏览器的事件修改属性,为触发控制器中的方法,增加了一层控制业务的属性,即ViewModel,View与Model通过ViewModel实现双向绑定。View和Model之间的同步工作完全是自动的,ViewModel通过双向数据绑定把View层和Model层连接起,负责把Model的数据同步到View显示出来,并把View的修改同步回Model。MVVM的核心思想就是只关注Model的变化,让框架自动去更新页面DOM,开发人员不需关注数据状态的同步问题,从而实现数据和视图的真正分离。
2.1治超处罚形势综合分析预测
系统能够对冶超处罚数据进行统计和分析,生成治超形势数据、总体信息概览等,并以数字、饼状图、表格、地图及折线图等形式进行展示。不同管理机构的用户可以查看本地的统计分析数据,能够直观了解本地的治超形势,为决策提供依据,运输企业、车辆、驾驶员统计结果如图4所示。
2.2处罚信息管理
可以查看所有车辆超载处罚信息,包括手动录入和自动同步的数据。支持处罚信息的导入和导出以及每条处罚信息对应的处罚决定书的导入和导出,处罚信息管理页面如图5所示。
2.3黑名单管理
可以查看运输企业、车辆和驾驶员的黑名单数据,支持黑名单的查询和导出,同时可以导出每一条违规记录的处罚决定书。可以查看进入黑名单时的违规次数和每次违规的记录,运输企业黑名单可以查看违规占比。系统可以设置黑名单阈值,根据阈佰生成黑名单列表。黑名单管理页面如图6所示。
2.4处罚备案
可以查看运输企业、车辆、驾驶员及源头企业的黑名单,有管辖权限的机构及其上级机构可以对黑名单中的企业、车辆、驾驶员及源头企业进行处罚,处罚时需选择处罚方式,点击礁定即完成处罚操作,此时相应对象将被移除黑名单。此外,车辆发生违规地点的管辖机构可以向管辖对象的机构抄送黑名单处理提醒,起到提醒作用。上级机构可以向下级机构进行抄送,对黑名单的处理工作进行督办。处罚备案页面如图7所示。
2.5基础数据管理
可以对车辆、驾驶员、运输企业和源头企业等基础数据进行管理,能够对上述基础数据进行添加、修改、删除等操作,并可查看数据详情。其中车辆和驾驶员数据量较大,为提升检索速度,数据库表存储时对部分检索字段添加了全文索引,从而极大地提升了模糊查询的效率。基础数据管理页面如图8所示。
3结束语
河北省冶超处罚联网系统通过对超载处罚数据的对接和分析,实现了车辆、驾驶员、运输企业及源头企业超载运输黑名单制度的落实,系统运行半年以来成效显著,为河北省的冶超工作提供了助力。下一步将进一步完善系统对数据的分析能力,构建更优化的模型,提升超载趋势预测的准确度。
