任务间共享和特有结构分解的多任务TSK 模糊系统建模
2021-09-11赵壮壮王骏潘祥邓赵红施俊王士同
赵壮壮,王骏,潘祥,邓赵红,施俊,王士同
(1.江南大学 人工智能与计算机学院,江苏 无锡 214122;2.上海大学 通信与信息工程学院,上海 200444)
模糊逻辑和模糊推理被用来描述知识和表达的不确定性。而模糊系统就是由模糊逻辑和模糊推理发展而来的。相比于传统的机器学习模型,模糊系统能够更准确地描述和估计现实中不确定的复杂非线性系统模型[1-4]。近年来,学者们提出了众多的模糊系统建模方法,其中TSK 模糊系统因其能够将非线性系统转化为多个局部线性结构的逼近,而成为最受欢迎的模型之一[5-7]。
TSK 模糊系统由若干条模糊规则构成,每条模糊规则由前件和后件组成。传统的模糊规则构建依靠专家经验。近年来,数据驱动的模糊规则构建方法受到了充分的研究。通常可以划分为两个步骤:一是使用某种划分规则将训练数据分为若干子体来提取规则前件参数,在实际建模中,通常使用聚类来实现;二是学习优化后件参数,从机器学习的角度,可以视为一个线性回归问题[8-11]。
TSK 模糊系统建模是重要的有监督学习的过程,因此需要充分的训练数据。然而,在很多实际应用中,样本数据经常是有限的高维数据,这就不可避免导致了模型的过拟合问题。而多任务学习可以从其他任务中获取相关信息,一定程度弥补训练数据不足的问题,进而提高模型的学习性能[12-17]。在多任务建模中,任务之间往往具有明显的相关性,并存在着共享信息,因此充分利用多个任务间的共享信息进行多任务模糊系统建模,有助于提高每个任务的泛化性能。例如,Jiang等[18]提出了一种利用潜在任务间关系信息的多任务模糊系统,该方法为多个任务学习了一个共享的后件参数来表示任务间的共享信息。然而,这些方法都只着重于任务间后件参数的共享结构,而忽视了如何利用各任务的自身特点。
鉴于此,本文提出了一种新型多任务TSK模糊系统建模方法,在挖掘多任务间共享信息的同时,保留单个任务的特殊性。该方法将多任务的后件参数矩阵分解为共享参数矩阵和特有参数矩阵两个部分:共享参数矩阵表示了任务之间共享的结构信息,而特有参数矩阵保留了每个任务的不同于其他任务的差异信息。本文通过为共享参数矩阵和特有参数矩阵分别引入低秩和稀疏约束来实现这一目标。
1 多任务TSK 模糊模型的基本原理
经典的单任务TSK 模糊系统利用多个局部线性子模型来近似非线性模型。而多任务模糊系统就是多个单任务模糊系统的联合优化。在多任务设置中和D分别表示任务、样本和特征的数量,其t中=1Nt表示任务t的样本数量。对于任意输入向量其表示任务t的一个样本的特征向量,其中是向量xt的第d变量。
因此,任务t的第m个规则可以表示为:

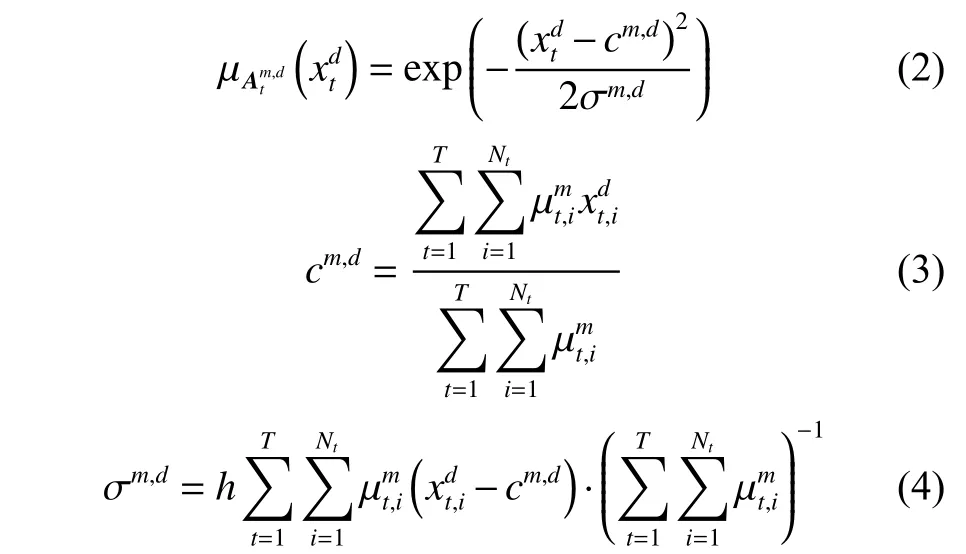

为方便计算,本文为多任务TSK 模糊模型进一步定义W=(w1,w2,···,wT)∈R(D+1)M×T,表示多任务模糊模型的后件参数联合矩阵。所以,基本多任务模糊系统的目标函数可以表示为
2 任务间共享和特有结构分解的多任务TSK 模糊系统建模新方法
本节在基本多任务模糊系统的基础上,进一步提出新型多任务模糊系统建模方法。考虑到多任务之间是相互关联的,因此可以认为多个任务的模型参数包含着潜在的共享信息;另一方面,各任务的模型参数中都包含了自身不同于其他任务的特有信息。如图1 所示,本文将各后件参数联合矩阵W分解为共享参数矩阵V和特有参数矩阵E,即:
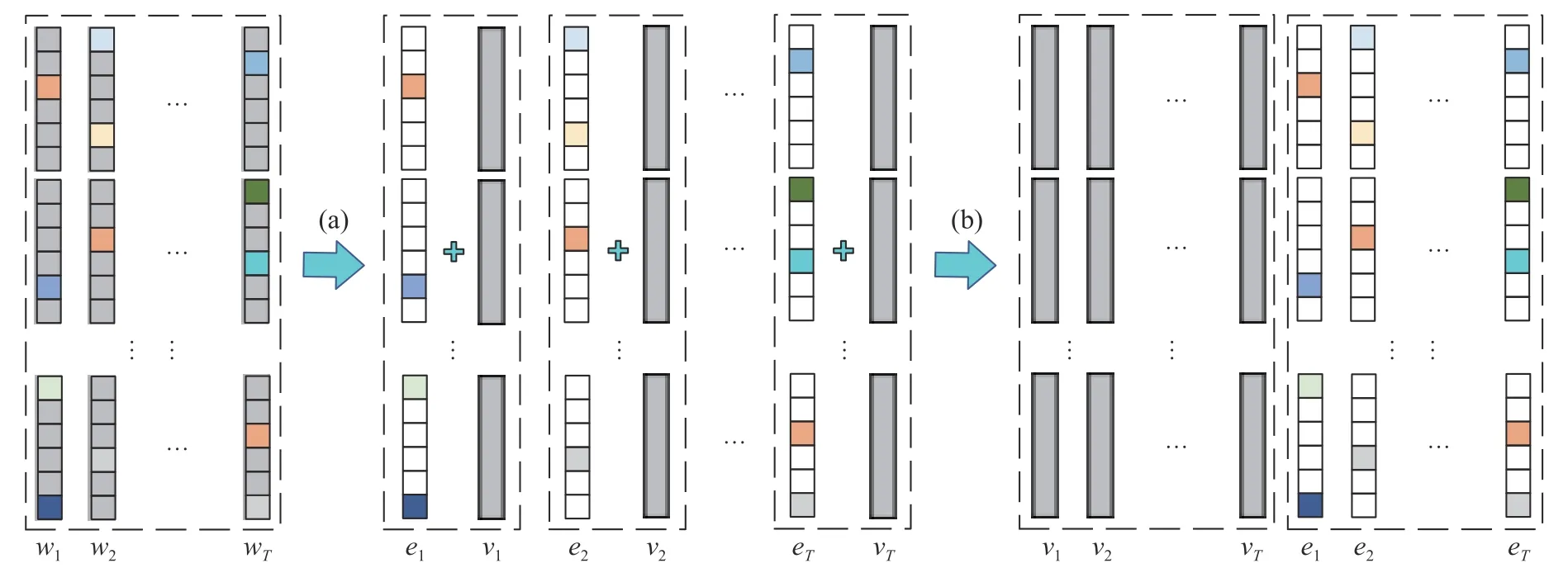
图1 后件参数矩阵 W=(w1,w2,···,wT) 可以拆分为低秩部分 V=(v1,v2,···,vT) 和稀疏部分E=(e1,e2,···,eT)Fig.1 The consequent parameter matrix W=(w1,w2,···,wT) can be decomposed into the low-rank component V=(v1,v2,···,vT)and the sparse componentE=(e1,e2,···,eT)

共享参数矩阵V包含了任务之间的共享参数信息,这种共享信息是指同一个特征在不同的任务中发挥相似的作用。具体表现在,如果某个特征在任务i中被赋予了一个较高的权重值,那么它在相关任务j中也将被赋予较高的权重,反之亦然,即对应于任务i和任务j的共享参数vi和vj是相似的。因此,共享参数矩阵V具有低秩性,本文通过引入核范数来实现对共享参数矩阵V的低秩约束特有参数矩阵E表示各项任务不同于其他任务的特有信息,这种特有信息体现在某一特征在不同任务中发挥不同的作用,即特有参数矩阵E是行稀疏的,本文通过引入正则化项实现行稀疏。
所以,通过对后件参数联合矩阵的分解,再分别施加低秩和行稀疏约束,在多任务建模中兼顾多任务之间共享信息和特有信息的作用,提出了任务间共享和特有结构划分的多任务TSK 模糊系统的目标函数,表示如下:

式中:α和β 是正则化参数,用于调节共享参数和特有参数在模型训练中发挥的作用,参数越大,惩罚力度越大。
3 目标函数优化
本文使用增广拉格朗日乘子法[19-20]求解式(10)提出的最优化问题,其增广拉格朗日目标函数为
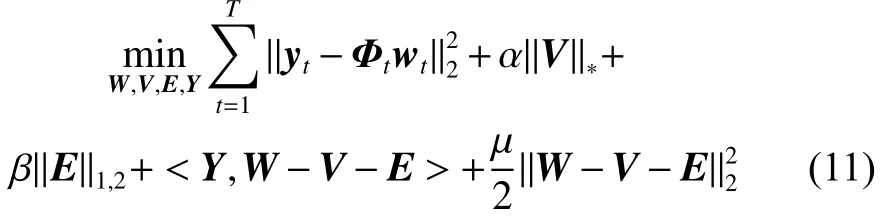
式中:Y∈R(D+1)×T是拉格朗日乘子矩阵,〈·,·〉 表示两个矩阵的内积运算。为便于计算,使用LADMAP 方法[21]将目标函数重新表示为
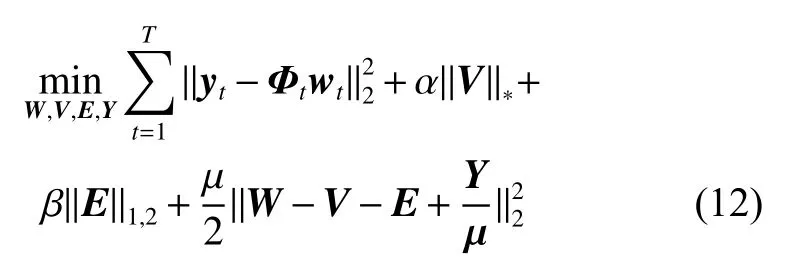
这是一个包含W、V、E、Y4 个优化变量的最优化问题,所以本文交替使用其他变量的固定值迭代优化每个变量,原问题被转化为下面若干个子问题:
1) 固定V、E、Y,式(12)化为如下目标函数:

对wt求导,并令其等于 0,整理之后,可以通过式(14)获得wt的解:
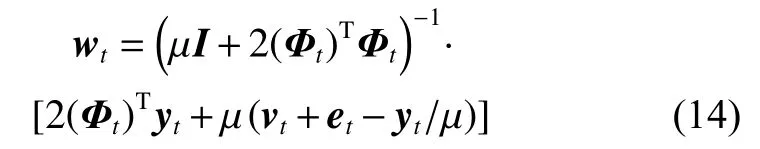
因此,可以进一步得到W的解:

2) 固定W、E、Y,式(12)转化为目标函数:
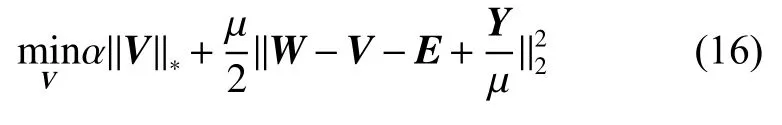
使用奇异值阈值算子[22]求解式(16)的低秩问题,V的最优解可以写成如下形式:

3) 固定W、V、Y,式(11)变成如下目标函数:

式(18)等同于求解如下问题:
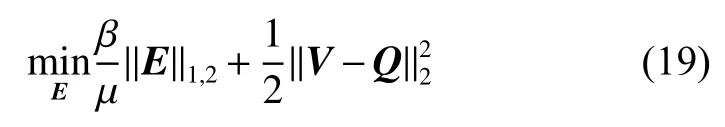
其中Q=W−V+Y/µ,可以使用文献[23] 中的方法求解式(19)的最优化问题,得到E的最优解。
4) 更新拉格朗日乘子矩阵Y和正则化参数 µ:
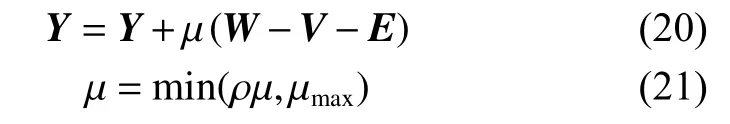
式中:ρ 是一个大于1 的正数。
最终,本文提出多任务TSK 模糊系统建模方法具体描述如下:
算法MTTSKFS-CS
输入多任务数据集X1,X2,···,XT和对应的标签y1,y2,···,yT;模糊规则数量M;正则化参数 α,β,µ ;可调节参数h;正整数 ρ>1,µmax=103;
输出多任务的模糊前件和多任务后件参数联合矩阵。
训练过程
1) 生成模糊字典:首先对全部任务的样本使用FCM 聚类,获得M个聚类中心。然后计算每个样本的模糊隶属度,生成每个任务的模糊字典。
2) 联合学习多任务的后件参数:求解式(12),得到W、V、E最优解:
①初始化:设定W是一个随机矩阵,V=W,E=W−V。拉格朗日乘子矩阵
②当式(12)不收敛

3) 输出多任务的模糊前件和多任务后件参数联合矩阵。
4 结果与分析
4.1 实验设置
为了验证本文提出的多任务建模方法的有效性,在多个真实数据集上进行泛化性能实验。实验中用到的数据集包含2 种类型:一种是相同输入不同输出的SIDO 数据集,将数据集的每一个输出作为一个回归任务构成一个多任务数据集,数据集的多个任务共享同一个输入数据,但每个任务拥有不同的输入空间到输出空间的映射函数;另一种是不同输入不同输出的DIDO 数据集,同样将每一个输出作为一个回归任务,每个任务拥有不同的输入数据和不同的输入空间到输出空间的映射函数。
本节选择的Slump、Parkinsons Telemonitoring、Winequality、House 数据集来自UCI Machine Learning Repository 数据集网站。Slump 数据集用来模拟混凝土的坍落度,涉及到坍落度、流动性和抗压强度3 个输出,是一个SIDO 数据集。Parkinsons Telemonitoring 数据集由来自42 名早期帕金森氏症患者的生物医学声音测量组成,用来测量motor 和total UPDRS scores,也是一个SIDO 数据集。Winequality 数据集是一个利用基于理化测试数据来划分葡萄酒质量等级的数据集,包括红葡萄酒和白葡萄酒两个子集,本节分别将每个子集视为一个任务,这是一个DIDO 数据集。House 数据集被用于波士顿房价预测,在本节根据特征变量“RAD”的值将数据集划分为(Task 1:RAD<5;Task 2:5<=RAD <7.5;Task 3:RAD>=7.5)3 个子集,作为一个DIDO 数据集。Multivalued (MV) Data Modeling 数据集可以从KEEL Datasets Repository 获得,是一个具有特征间依赖关系的人工数据集,本节中根据第8 个特征变量可以将数据集划分为两个任务,作为DIDO 数据集。表1 中列出来了上述所选用的数据集的特征维数、样本数量等具体细节。
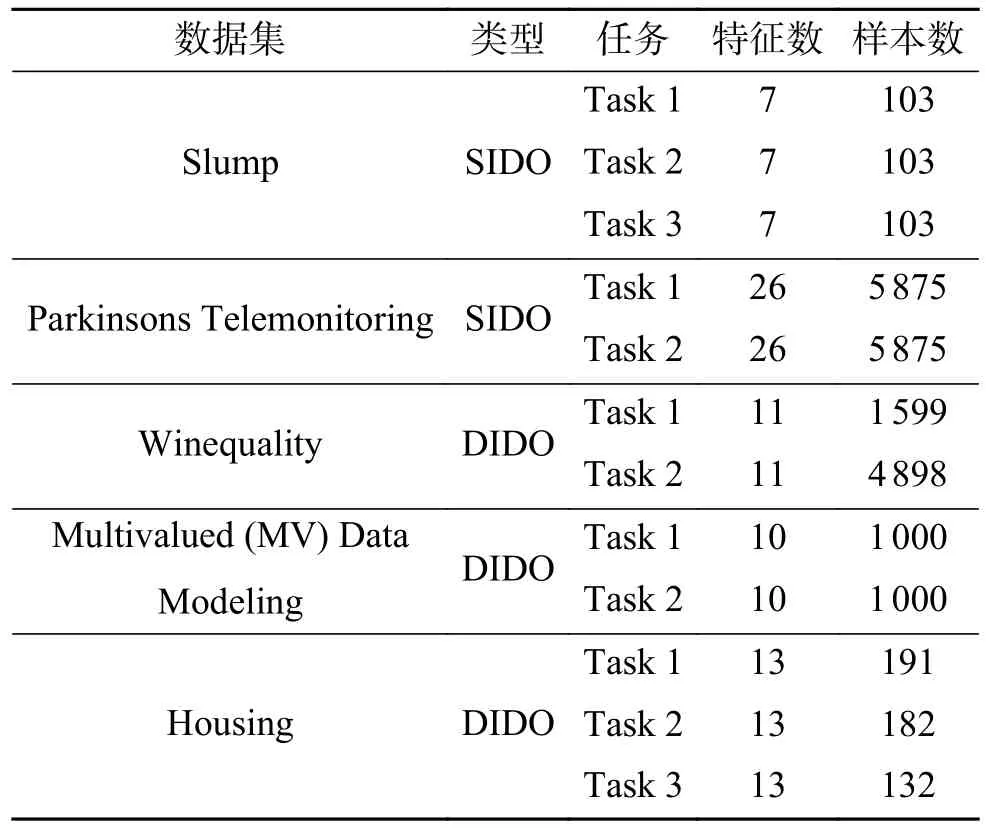
表1 多任务数据集的详细信息Table 1 Details of the multitask datasets
我们在实验中比较了几种经典的回归算法,包括多任务和单任务回归算法。算法中涉及到的参数的设置通过5 折交叉验证来进行寻优,这些算法的详细介绍以及参数的寻优范围如表2 所示。
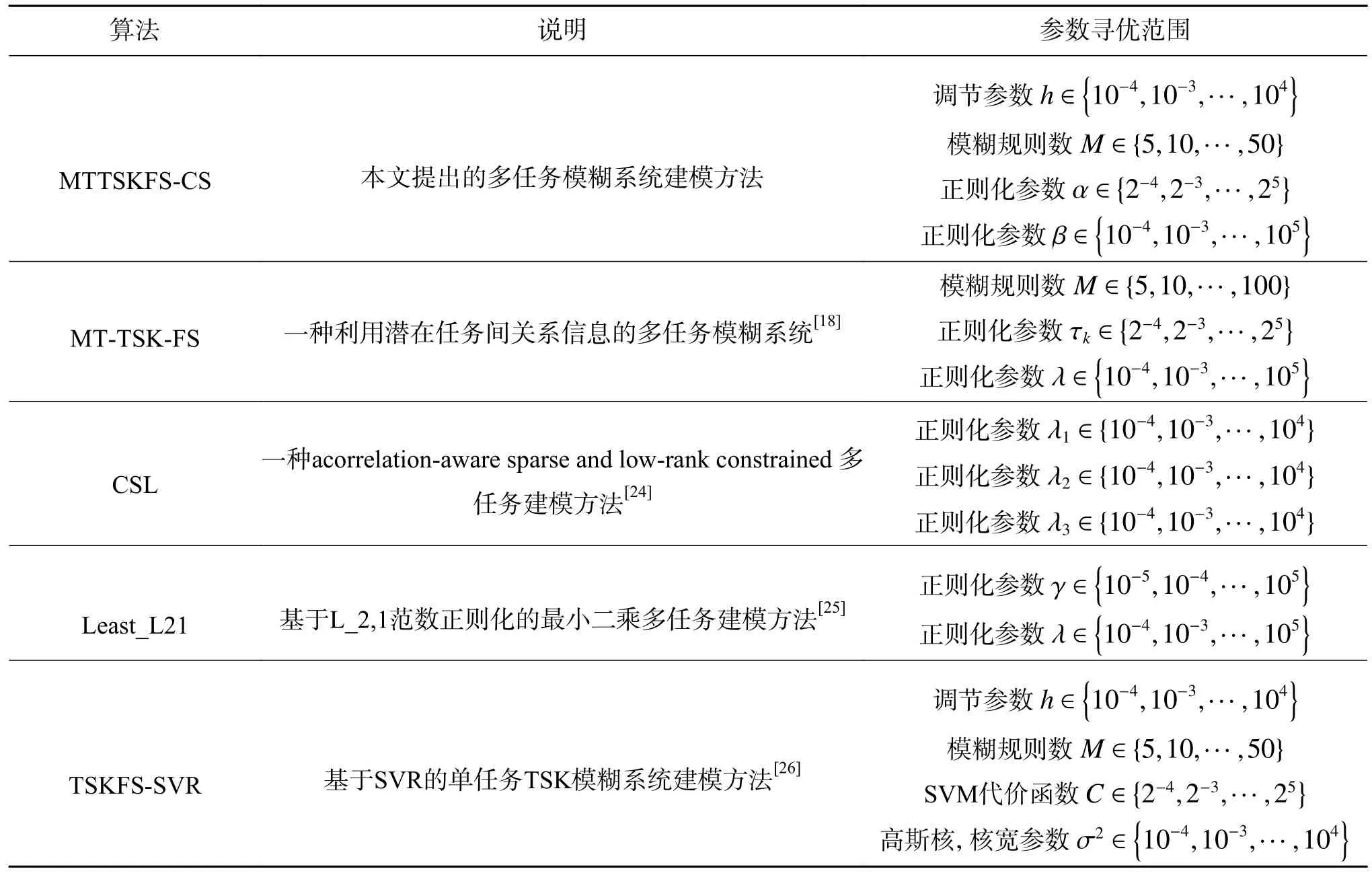
表2 实验中各算法参数的详细设置Table 2 Detailed settings of all algorithm’s parameters
本文选用RRSE 来评价各对比算法的泛化性能,定义如下:
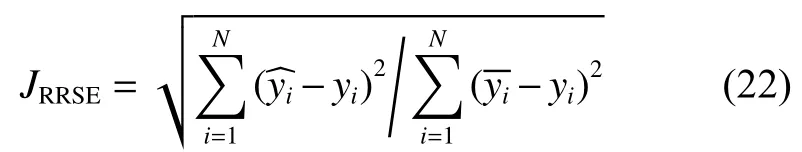
4.2 泛化性能实验
我们分别在每个数据集上验证了MTTSKFSCS 及对比算法。
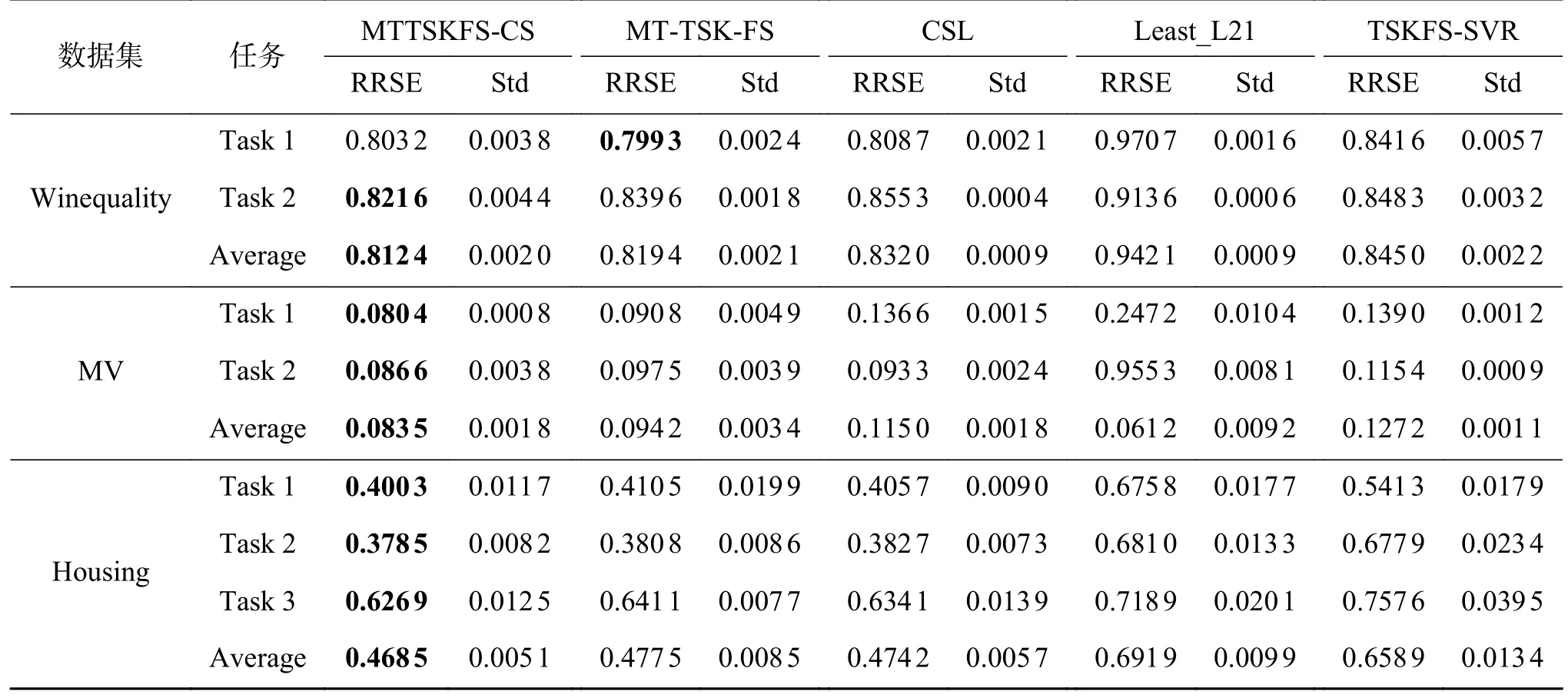
分别计算各模型在每个数据集的每个子任务上的泛化性能,其中“Average”表示算法在每个数据集的所有任务中的平均表现。若算法为单任务算法时,分别对每个子任务进行建模,来评价算法性能。本文提出的MTTSKFS-CS 建模方法与对比方法在真实数据集上的实验结果如表3 所示。
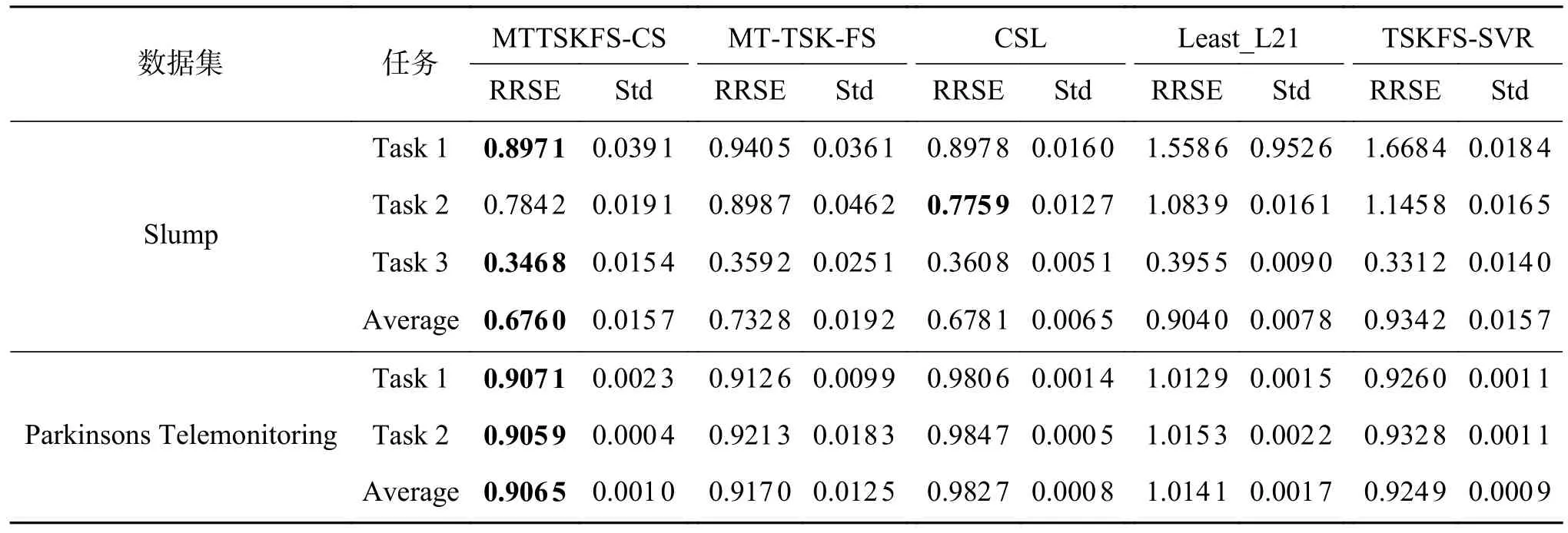
表3 所有算法在各数据集上的泛化性能比较Table 3 Comparison of generalization performance of all algorithms on datasets
续表 3
4.3 后件参数划分的可视化分析
为了进一步说明本文提出的对于后件参数矩阵的低秩和稀疏划分的重要作用,我们将模型在Parkinsons Telemonitoring 数据集上训练出的后件参数W、V、E进 行可视化。图2 展示了后件参数的可视化结果,从中可以看到,训练出的参数结果,基本符合图1 中的假设,W被划分为了低秩部分V和稀疏部分E。
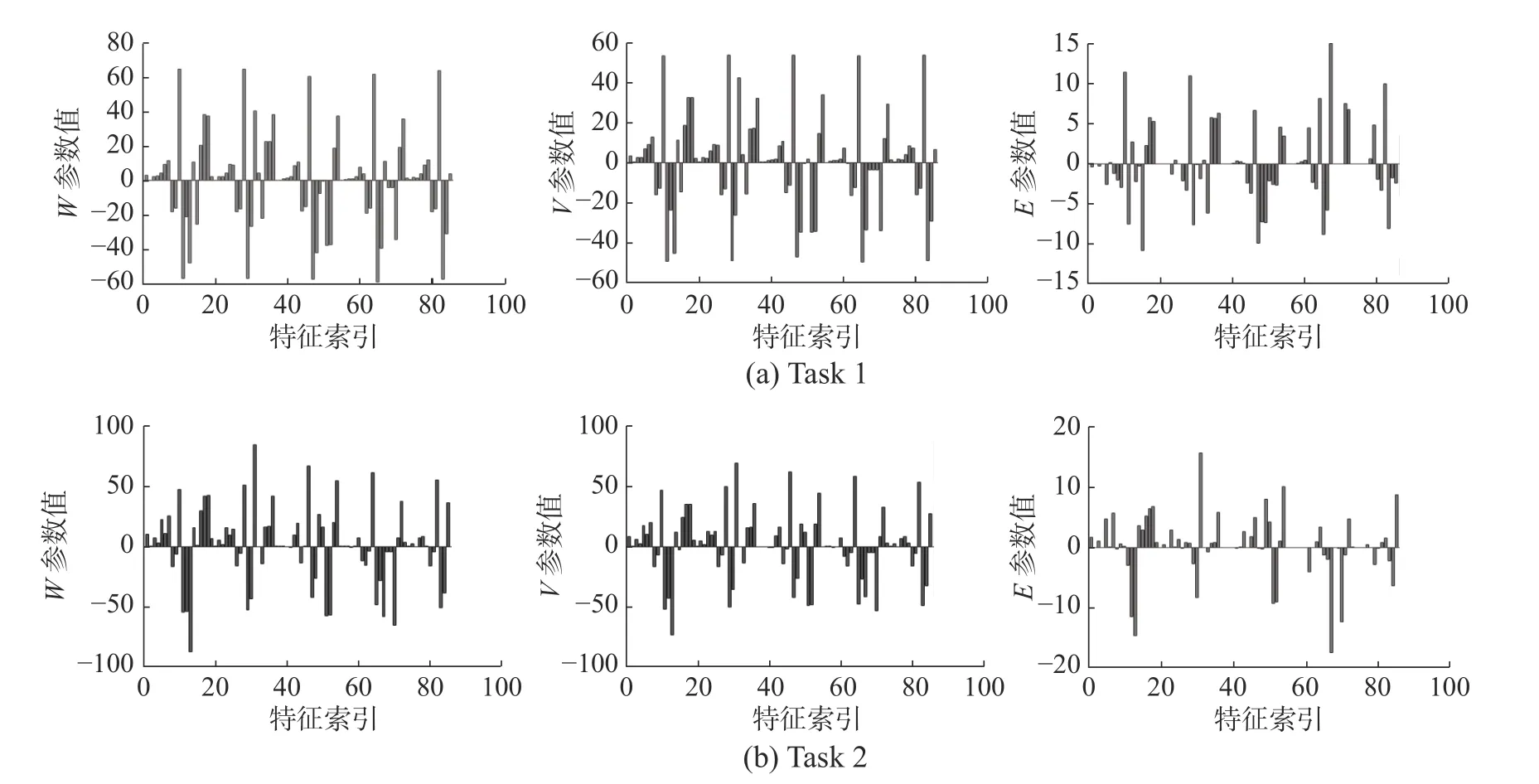
图2 W、V、E 的可视化结果Fig.2 Visualization ofW,V,E
4.4 算法收敛性分析
为了进一步研究本文提出的MTTSKFSCS 建模方法的收敛性,我们选取了Multivalued(MV) Data Modeling、Parkinsons Telemonitoring 和House 3 个数据集,通过交叉验证寻优得到最优参数,并在最优参数的基础上进行收敛性实验。算法在3 个数据集上的收敛曲线如图3 所示。从收敛曲线中可以看到,算法在前期可以快速收敛,并迅速进入稳定状态。实验结果说明,本文第3 节提出的优化方法具有良好的收敛性能,能够真正达到模型最优化的目的,从而使模型获得较高的实用性。
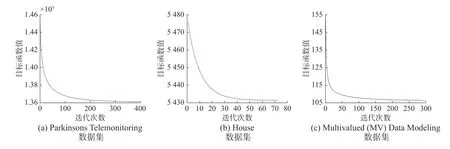
图3 MTTSKFS-CS 方法的收敛曲线Fig.3 Convergence curve of MTTSKFS-CS algorithm
4.5 实验结果分析
表3 的实验结果证明MTTSKFS-CS 方法在大多数任务上获得了比对比算法更好的性能表现。与单任务方法相比,多任务建模方法明显提升了每个任务的预测表现,拥有更好的泛化性能。与多任务算法的对比结果说明,本文提出的方法在利用了多任务之间的的共享信息的同时有效利用了单个任务自身的特有信息,从而获得了更好的表现。对于图2 的可视化结果,我们可以看到,后件参数联合矩阵W被划分为了低秩部分V和稀疏部分E,实现了本文提出的模型设想,也间接验证了MTTSKFS-CS 模型的有效性。
5 结束语
本文提出了一种新型多任务模糊系统建模方法,首先使用模糊聚类方法获得多任务的模糊前件,然后通过合理划分后件参数联合矩阵为共享参数矩阵和特有参数矩阵,同时兼顾多任务之间的共享信息和各任务的特有信息。最后通过ALM 方法求解最优化问题,获得模型的最优解。在多个真实多任务数据集上的实验结果说明了,本文提出的MTTSKFS-CS 建模方法能够有效解决传统多任务模型只着重于多任务共享信息的问题。在今后的工作中,如何更好地在建模中平衡共享信息和特有信息将是我们研究的重点。
