基于RGB图像的冠层尺度水稻叶瘟病斑检测与抗性评估
2021-09-10谢鹏尧富昊伟唐政麻志宏岑海燕
谢鹏尧,富昊伟,唐政,麻志宏,岑海燕*
(1.浙江大学生物系统工程与食品科学学院,杭州 310058;2.农业农村部光谱检测重点实验室,杭州 310058;3.嘉兴市农业科学研究院,浙江 嘉兴 314016)
水稻是我国主要粮食作物之一,而病害侵染造成水稻品质下降和经济损失,因此,对水稻病害的有效防治在促进水稻增产、保障粮食安全方面具有重大意义[1]。稻瘟病是水稻的常见病害[2],根据水稻在不同时期不同部位的发病情况可分为叶瘟、节瘟和穗瘟。叶瘟多发生于三叶期后的秧苗或成株叶片上,一般在分蘖至拔节期盛发。植物病理学上常根据水稻对病害抗性的不同分为6级(高抗型、抗病型、中抗型、中感型、感病型、高感型)[3],以表征水稻个体和品系之间的抗病能力差异。
目前,对稻瘟病的识别主要以肉眼观察病斑的颜色和形状为主,并结合经验判别病害类型和发病程度。这种人工观察法存在工作效率低、劳动强度大、主观性强的缺点,且无法满足规模化植保精准作业的需求[4]。随着数字图像技术的不断发展,基于图像处理技术的作物病情识别检测以其省时、省力、高效的优势,得到了广泛的应用[5]。传统的图像处理技术针对病斑在叶片上易形成封闭边缘的特性,采用色度学模型、边缘提取和形态学等方法对病斑进行检测[6]。例如ABU BAKAR等[7]基于多级阈值的模式识别方法成功将水稻叶瘟分为感染阶段、传播阶段和最坏阶段3个类别。也有部分研究通过对病斑的形状进行规则图形拟合的方式,构建病害分级标准。例如PEYMAN等[8]通过提取4个无量纲的形态特征如圆度、长宽比、紧密度和面积比,并基于这些特征进行病害类型诊断,使得检测精度达到(97.4±1.4)%。随着机器学习、模式识别技术的快速发展,利用支持向量机(support vector machine,SVM)、贝叶斯分类器、无监督聚类等机器学习算法进行病斑智能诊断在实际应用上取得了很大成功。GAYATHRI DEVI等[9]将提取的特征提供给K-最近邻神经网络、反向传播(back propagation,BP)神经网络、朴素贝叶斯网络和多类SVM等并进行对比后发现,多类SVM的准确率更高,为98.63%;LARIJANI等[10]使用由K-均值改进的K-最近邻分类(K-nearest neighbor classification, KNN)算法对Lab 色彩空间中的田间图像进行分类以检测水稻病斑,准确率达到96%;KANG 等[11]采用BP 神经网络对稻瘟病进行了有效的识别。但是浅层的学习受到自身理论的限制,以及较依赖训练前预处理和训练过程中的技巧性,在一些复杂情况下(例如冠层尺度)的诊断结果并非最优。相比于叶片尺度,冠层尺度具有更复杂的背景和纹理特征,还存在遮挡、水体镜面反射等问题,仅仅依靠传统的图像处理方法和机器学习方法较难准确有效地识别检测。深度学习方法通过组合多个非线性处理层,对原始数据特征进行从浅层到深层的逐层抽象,这使得深度学习模型拟合复杂模型的能力大大增强。类似研究较为丰富,其中大部分是采用卷积神经网络(convolutional neural network, CNN)对叶片尺度的水稻病害进行分类[12-14]、检测[15-17]、分割[18-19],少部分是田间冠层尺度[20]、单穗尺度[21]或时间尺度[22],分类的准确率高达98.64%,但是缺少对单张图像不同病斑的分类和检测。由于矩形框的检测难以描述遮挡时的情况,因此,像素级别的分割方式将会有更大的实际应用效果。鉴于之前深度学习在复杂数据集上表现出的优异性能,引入基于深度学习的像素级别的分割方法来进行冠层尺度稻瘟病的识别检测具备可行性和实用性。为此,本文提出了一种基于水稻冠层尺度RGB 图像和掩膜区域卷积神经网络(mask regions with CNN features,Mask-RCNN)深度学习框架的水稻叶瘟病斑识别检测方法,通过分析水稻RGB图像中不同类别病斑的数量信息,构建多种分类模型来评估病斑数量和抗性水平之间的关联性。
1 材料与方法
1.1 实验设计
于2020年5月—6月在浙江省嘉兴市农业科学研究院开展相关实验。实验采用粳稻品系(HB)、早籼品系(QL)和籼型恢复系(W0)等不同品系的水稻育种材料,将稻谷催芽后于5月10日进行分区播种,并发育至秧苗期。将2019 年采自大田的稻瘟病标样(以穗颈瘟和节瘟为主)通过浸泡、除杂、纯化后获得纯化菌株,在大麦培养基中于27 ℃条件下培养10~12 d,获得足够的稻瘟病菌丝体,经过冲洗、揉搓破坏后,促进其从营养生长向生殖生长转化,然后在相对湿度>80%、温度28 ℃的条件下保湿培养36 h,获得稻瘟病孢子。最后用纯净水配制成适宜浓度的孢子悬浮液,在水稻秧苗上进行人工喷雾接种。接种后采用尼龙薄膜覆盖和黑布遮盖,以进行24 h 的保湿遮光,促进孢子的有效附着。然后去掉遮阴布,进行人工喷雾保湿4 d。1~2 d后调查发病率,对所有不同的区块进行采样,并根据病斑种类、大小和数量,确定所采水稻样本的稻瘟病抗性水平,进而确定当前区块品种的抗性水平(高抗型、抗病型、中抗型、中感型、感病型、高感型)。经人工调查,本实验采用的3 种水稻育种材料品系(W0、QL 和HB)包含4种抗性水平,分别是抗病型、中感型、感病型、高感型,分别标记为R、M、S和S+。而高抗型和中抗型样本在本次调查中未出现,因此,不把这2类纳入建模过程所需的样本分类结果中。
1.2 图像采集
在水稻发病情况调查完成15 d 后进行图像采集,该时段稻瘟病斑已经重发完毕,即处于充分拓展期。使用2 部单反相机(型号,Canon EOS 6D Mark-Ⅱ;镜头,适马24-70;光圈,2.8)按一定的拍摄规则和拍摄顺序获取所有区块的冠层尺度的水稻图像,使得每2 幅图像覆盖完整的单一区块;并连同3 部自动对焦的智能手机(OnePlus 7 Pro、OPPO R17 和HUAWEI nova 6)随机选取适宜拍摄水稻病斑的区域进行拍摄,使得图像中心局部聚焦于稻瘟病斑特征点。共采集到具有不同分辨率的局部稻瘟病斑图像760 幅(单反相机分辨率6 240×4 160,拍摄410 幅;OnePlus 7 Pro 分辨率3 456×4 608,拍摄147 幅;OPPO R17 分辨率4 000×3 000,拍摄169 幅;HUAWEI nova 6 分辨率2 736×3 648,拍摄34幅)。
1.3 数据处理
1.3.1 数据集制作
由于源自不同采集设备的原始图像大小不一致,不便于输入到神经网络中进行训练,并且原始图像尺寸较大,经过多层级的压缩后容易丢失局部特征。因此,对采集到的和不同区块相匹配的图像(每相邻2幅图像覆盖一个水稻品系)和聚焦于局部病斑特征的图像(随机选取合适的病斑拍摄)分别采用不同的图像分割方式,裁剪分割成1 500×1 500的正方形图像:对于和区块相匹配的图像(每幅图像覆盖3 个栽种行),先提取中间的单一栽种行,再将该栽种行分割成4幅1 500×1 500正方形子图像;对于聚焦于局部病斑的图像(图像中心为相机聚焦区域),只提取1 500×1 500 大小的中心聚焦区域。图1展示了用不同设备获取的水稻图像和分割图像示例。从局部病斑图像中选取200幅细节呈现度较高的图像,使用Labelme 2016 工具对图像中的病斑进行多边形标注,并在病害专家的指导下按照水稻叶瘟病斑类型(图2)进行鉴定,最后形成了200幅带有数据标签和病斑掩膜(mask)的图像,作为本研究的数据集。该数据集所包含的200幅图像上总共有4 723处多边形病斑标注,单幅图像上最少的病斑标注个数为3,最多的病斑标注个数为42,平均每幅图像上拥有24个病斑标注。数据集按照训练集∶验证集∶测试集=8∶1∶1的比例进行划分。

图1 原始图像和分割图像示例Fig.1 Examples of original images and segmented images

图2 水稻叶瘟病斑类型Fig.2 Types of rice leaf blast spots
数据增强是提升模型泛化能力的切实可行的方法,对同一张图像的平移、旋转、放缩、仿射变换以及对亮度、对比度、色调、噪声的调节,可以看作是对不同的拍摄视角、拍摄条件以及相机设定的模拟,既可以扩增数据集,也可以提升模型的泛化能力,但是需要选取合适的增强倍数和变换范围,以免对模型产生干扰。在不同的变换下掩膜的变换也不尽相同:涉及像素位置的变换则掩膜需要进行相同的变换,而涉及像素值的变换则掩膜不需要进行变换。本研究采用上述变换方法将训练集和验证集进行5 倍扩增的增强处理,扩增后数据集总病斑标注数达23 615个,样本类间数量均衡。数据处理流程如图3所示。
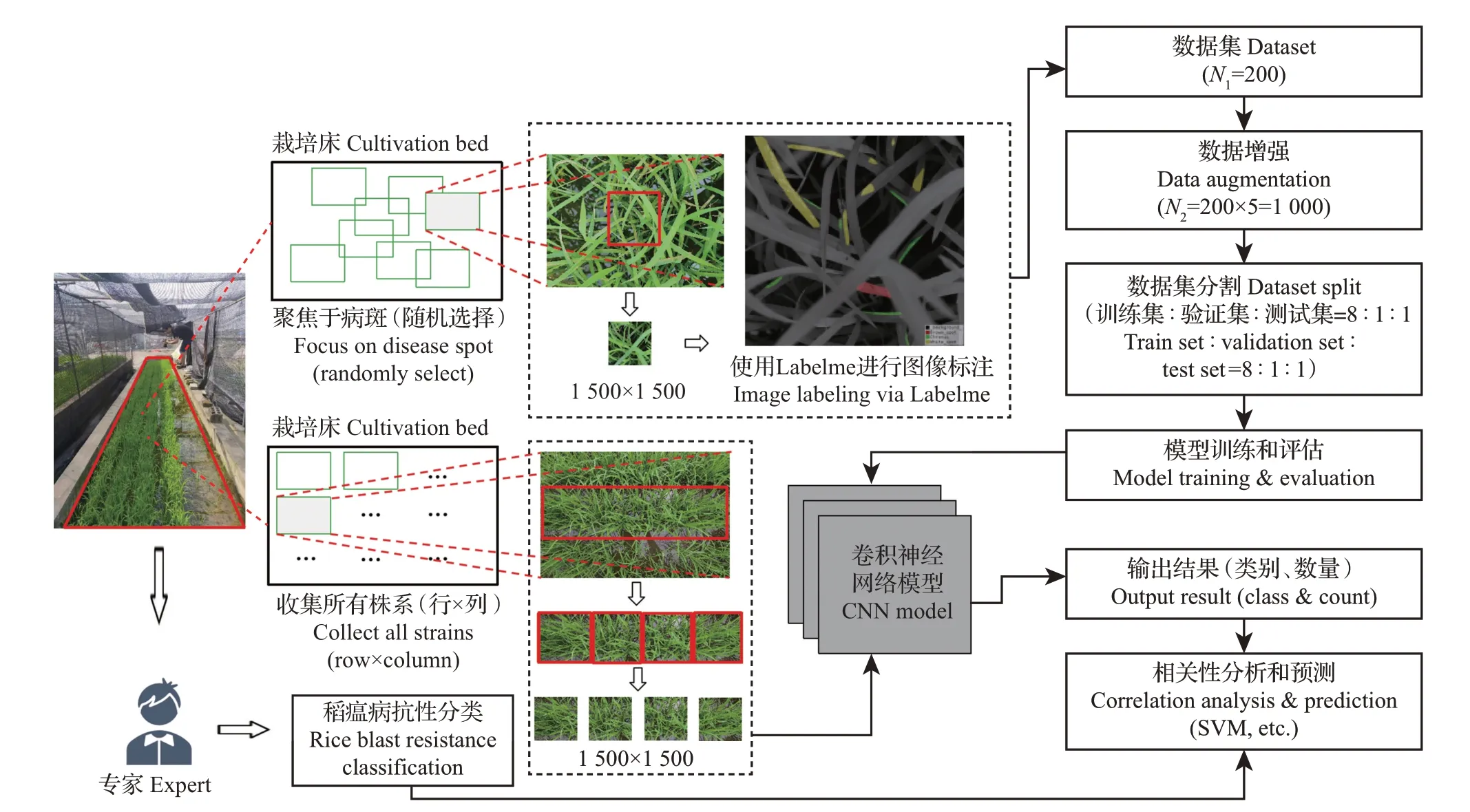
图3 数据处理流程Fig.3 Data processing flowchart
1.3.2 模型构建
本研究选用的深度学习模型是Mask-RCNN。Mask-RCNN是HE等[23]在2017年提出的目标检测算法,其网络架构如图4所示。该算法基于快速RCNN(Faster-RCNN)并将原来的感兴趣区域(region of interest,RoI)池化(pooling)改为了RoI对齐(align),以及增加了全卷积网络(fully convolutional network,FCN)。Mask-RCNN将分类预测和掩膜预测拆分为网络的2 个分支,其中:分类预测分支与Faster-RCNN相同,对感兴趣区域给出预测,产生类别标签以及矩形框坐标输出;而掩膜预测分支为每个类别产生独立的二值掩膜,避开了类间的竞争。
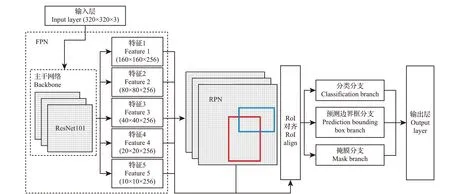
图4 Mask-RCNN模型架构Fig.4 Mask-RCNN model architecture
1.3.3 模型训练
Mask-RCNN 模型的初始权重使用的是在MS_COCO(Microsoft Common Objects in Context,2014)数据集上预训练好的权重,采用迁移学习的方式在水稻叶瘟病害数据集上进行全层级训练。神经网络训练所采用的输入图像的尺寸大小为320×320,由裁剪分割所得的尺寸大小为1 500×1 500的图像经过双线性插值方法调整尺寸得到,采用该尺寸作为输入图像的尺寸兼顾了原图像上病斑的必要清晰度,以及模型的收敛速度。模型训练环境是Ubuntu 18.04 系统,配置Intel(R)Core(TM)i7-4790 CPU@3.60 GHz,主存[随机存取存储器(random access memory,RAM)]16 GB,采用单块型号为GTX 1080Ti的图形处理器(graphics processing unit,GPU)加速,总共训练了200个轮次(epoch),每个轮次进行了10 次交叉验证,每个轮次步长为10,批训练数量大小为2,采用ResNet101 作为主干网络,总共耗时72 h。
Mask-RCNN模型的多任务损失函数定义为类别预测部分损失(Lcls)、矩形框预测部分损失(Lbox)和掩膜预测部分损失(Lmask)的简单加和,即
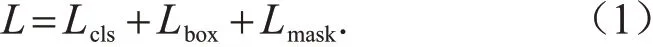
其中:类别和矩形框部分损失函数的计算参照Faster-RCNN;掩膜部分损失函数的计算采用对每一个像素计算二值Sigmoid交叉熵损失。由于将每个类别对应一个掩膜可以有效避免类间竞争,使得不同类别的掩膜不贡献损失。训练过程中模型在训练集和验证集上的总体损失函数变化曲线如图5所示。在整个训练过程中,模型各部分的任务损失函数在训练集和验证集上的变化趋势都是逐渐下降并趋于收敛,表明模型训练情况良好。
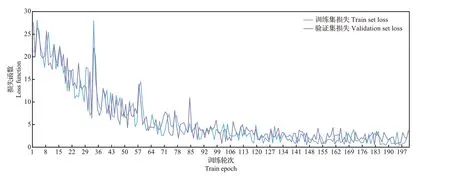
图5 Mask-RCNN损失函数变化曲线Fig.5 Mask-RCNN loss function change curve
所有分类模型在硬件配置为Intel (R) Core(TM) i7-4790 CPU@3.60 GHz、主存(RAM)16 GB的计算机上部署,采用MATLAB R2020a 软件(美国TMathWorks 公司)自带的“Statistics and Machine Learning Toolbox 11.7”中的“Classification Learner”并行计算,共耗时5.3 s。
2 结果与分析
2.1 深度学习模型效果评估
2.1.1 预测效果
将单幅测试集图像输入Mask-RCNN 模型后,输出的病斑预测结果如图6 所示,同一幅图像中包含多种类型的病斑。其中:慢性病斑边界清晰完整,单个病斑面积较大,预测掩膜基本能覆盖其病斑区域,置信度高于0.8。其他病斑(例如褐点病斑)由于自身形态多呈散点状分布,因而本研究采取标注散点病斑分布区域的方式进行标注。结果发现,预测掩膜同样能覆盖此类型病斑的发病区域,表明模型对RGB图像中较明显的病斑的检测效果较好。但由于散点状病斑区域的边界并不明晰,因而界定掩膜边界的主观性较大,造成置信度降低(低于0.8)。测试集中其他图像的检测效果类似,检测结果总体能够反映图像中存在的病斑类型和数量。

图6 Mask-RCNN预测结果示例Fig.6 Mask-RCNN prediction result examples
2.1.2 模型评价
目标检测任务中的模型评价方法通常采用的是混淆矩阵,其中,准确率(precision)和召回率(recall)是2个非常重要的指标,计算公式为:


在评价单个样本的目标检测结果质量的时候,常采用计算真值情况下生成的检测框和预测结果中检测框的交并比(intersection over union, IoU)作为单次预测的评价指标,其计算公式为:在测试集中,将每一类病斑的IoU 计算之后累加,再将来自各类别的IoU同权平均处理,得到的基于全局的目标检测评价指标平均交并比(mean intersection over union,mIoU)为0.603。不同病斑的IoU 大致围绕mIoU 上下波动,基于选定的IoU 阈值(一般为0.5),可以绘制出该阈值水平下的准确率-召回率曲线,并计算曲线下方的面积,作为单张图像的平均准确率(average precision,AP),计算公式如下:
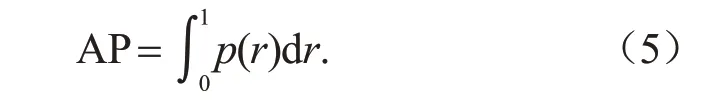
式中,p为准确率,r为召回率。
通常,AP 越大,目标检测模型的效果越好。对于整个数据集而言,可以通过计算多样本多类别的AP 均值(mean average precision,mAP)作为模型评价指标,计算公式如下:
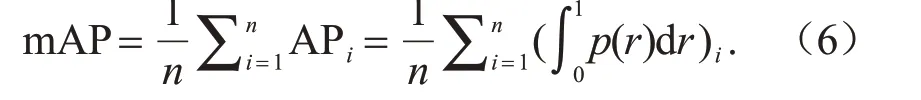
式中,n为数据集全样本数量。mAP 的数值大小一般在[0,1]之间。选择IoU=0.5 为阈值并基于该阈值评估测试集的预测结果,得到的mAP为0.716。
对于包含病斑数量较少、特征明显且叶片遮挡较少的图像而言,模型具有较高的识别检测准确率,计算所得到的AP值高于mAP;对于背景纹理较为复杂且包含较多病斑的单张图像而言,模型识别检测的能力将会受到挑战,计算所得到的AP 值将会偏低,表明模型在当前图像中的检测效果较差。面向单幅测试集图像的预测结果绘制预测值和真实值之间的匹配度热力图,并以IoU=0.5 为阈值确定是否匹配,结果如图7所示。可以看出:和图像中所有事先标注的病斑真实值相比,模型存在病斑漏检现象;已经给出的具有较高置信度的病斑预测结果仍然存在和真实值之间误匹配的可能性,从而造成模型检测结果的AP下降。水稻冠层结构的复杂性造成病斑的相互遮挡是病斑漏检的一个主要原因,病斑标注过程中的误差和水稻田镜面反射等干扰会造成预测与标注真值的误匹配。这也反映出模型预测准确度依旧有较大的提升空间。
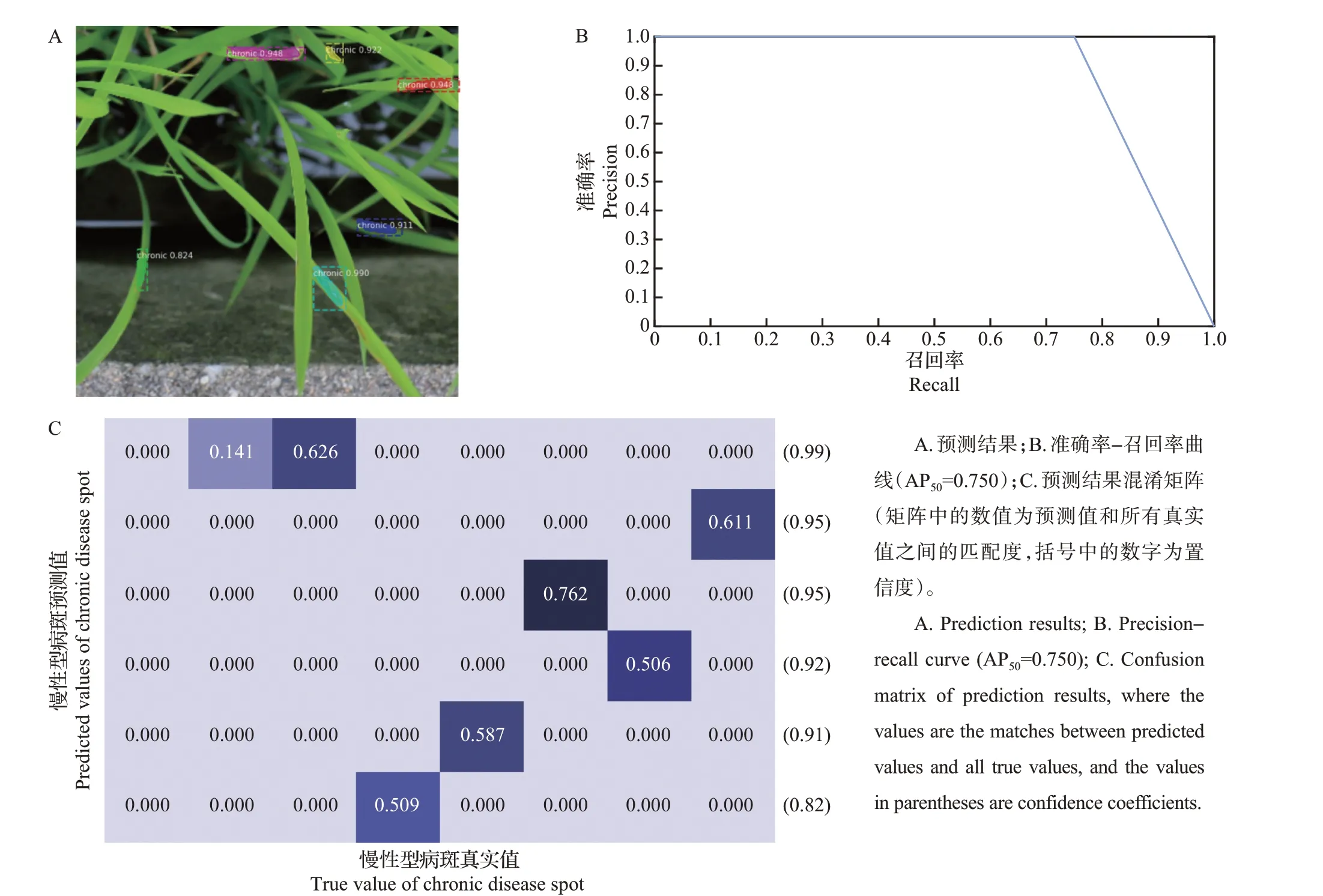
图7 Mask-RCNN在单幅测试集图像上的预测结果及评估Fig.7 Mask-RCNN prediction results and evaluation on a single test set image
2.1.3 模型解释
深度神经网络常常被视为“黑盒”问题,解决的方法是对Mask-RCNN 模型进行隐含层输出可视化,以此提升模型的可解释性[24-25]。本研究采取对Mask-RCNN 的主干网络以及Mask-RCNN 的掩膜预测分支网络的部分输出结果进行可视化处理(图8)。经过多层卷积和池化操作后,ResNet101 主干网络输出结果尺寸降为20×20,相同图像产生的不同输出表示在不同分支下对图像中的病斑特征的不同理解,输出结果中高亮的部分表明模型对该处的注意力较为集中,该处更有可能被判定为病斑区域。图像的纹理复杂度和输出结果中的高亮区域分布高度相关,具有较高的纹理复杂度的图像会导致模型的注意力分散,造成主干网络输出结果中高亮程度和高亮区域集中度较低,这也可以解释模型在同一IoU阈值下更容易输出“不自信”的预测结果(匹配度热力图中类别预测正确但是显示不匹配的淡蓝色区域)。掩膜预测分支网络输出的结果尺寸同样较小,为28×28,原因和主干网络的输出结果类似。此结果展现的是能够匹配局部特征的掩膜,其实质是模型对输入的局部图像的像素级理解和分类,蓝色的深浅程度表示模型对该像素的分类置信度高低,数值用0~1 的浮点数表示,最后再将大于一定置信度阈值的局部掩膜映射到原尺寸大小图像上,形成最终输出的掩膜(局部掩膜中存在的部分小于阈值的阴影没有被输出)。
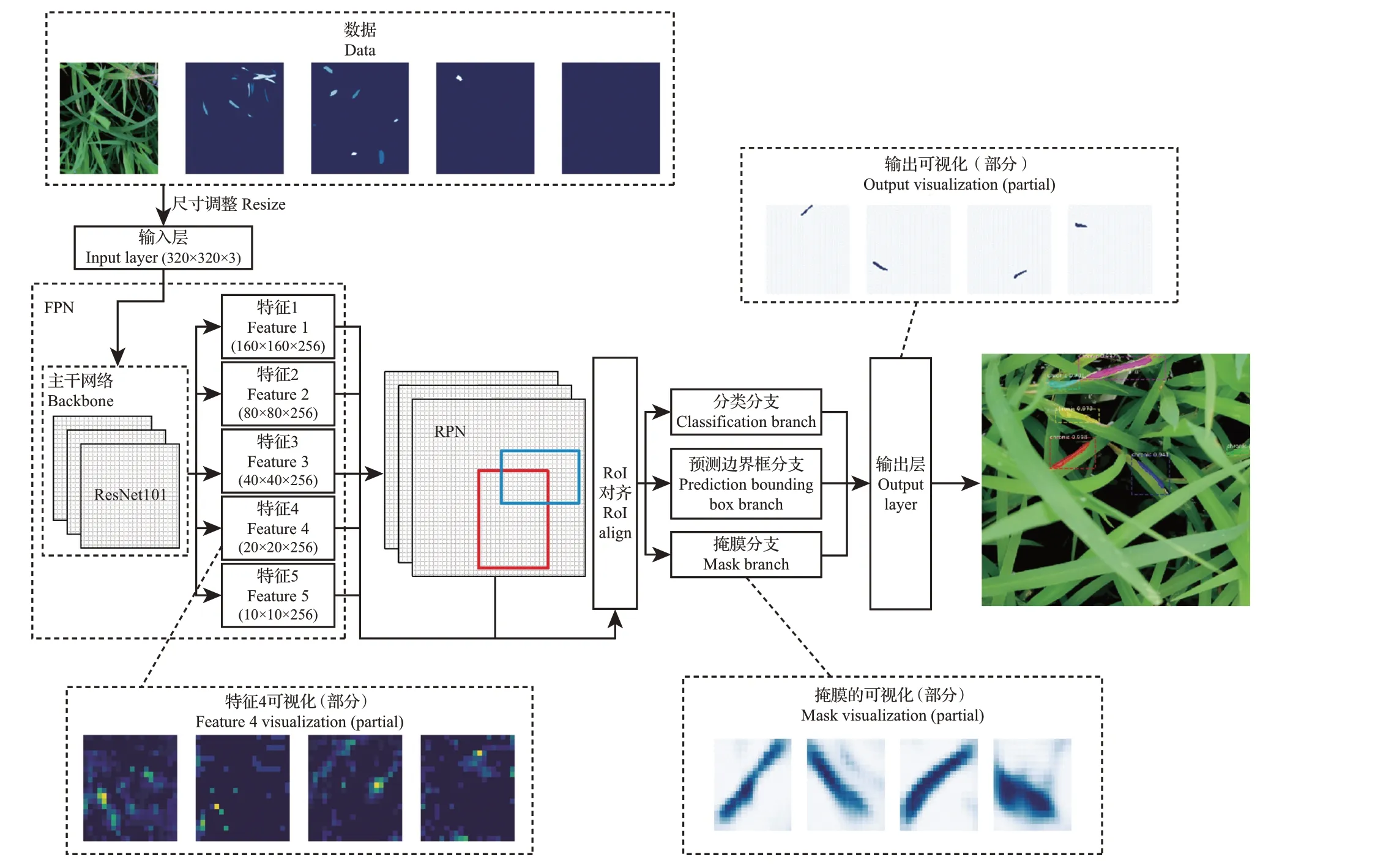
图8 Mask-RCNN模型输出部分可视化Fig.8 Partial visualization of Mask-RCNN model output
2.2 抗性分类模型效果评估
按照病情统计数据进行抗病等级的划分,通常有2种方法:一是发病率,二是发病严重程度。在水稻育种过程中,研究人员通过主观经验判断确定某一区块中的品系发病水平,从而确定该品系的抗性水平。本研究中,单一区块中不同类别的水稻病斑数量可以反映发病率和发病的严重程度:在区块大小和水稻栽种数量一定时,不同类型的病斑数量分布代表水稻发病的严重程度,病斑的绝对数量则代表了水稻的总体发病率。将按照同样尺寸大小裁剪分割好的水稻图像数据输入到经充分训练的Mask-RCNN模型中,可以获得病斑掩膜和病斑分类结果,然后通过统计相同区块所有子图像中的全部病斑分类和相应的数量,可以大致确定当前区块的发病水平,进而和发病情况调查中的各区块品系的抗性水平相关联。由于每2幅图像覆盖1个栽种相同品系的区块,因此,每个区块中的病斑数量为2幅相邻图像病斑数量的加总。针对上述关联,本研究将4种不同类别的病斑数量构成的特征向量作为模型输入(维数:4),将调查的抗性水平作为模型输出(维数:1),选取多种常见的分类模型进行训练,如线性判别、决策树判别、朴素贝叶斯判别、K-最近邻判别和支持向量机等,并根据训练结果评价上述关联的可靠性以及模型的分类性能。选取3种水稻育种材料品系(W0、QL和HB)的抗性水平调查结果和相对应区块的病斑分类和数量进行关联,总共覆盖264个栽种不同品系水稻的小区块。不同品系和不同抗性水稻的区块数量分布情况,以及不同抗性水平的水稻所对应的病斑数量平均占比情况如图9所示。可以看出:HB为抗性较好的粳稻品系;QL为抗性好的早籼品系,在本次接种中表现的抗性最佳;W0是籼型恢复系材料,抗性参差不齐。该比例能够大致解释依据不同分类病斑的数量进行抗性鉴定的可行性,但是不足以对单一的数据样本进行准确的分类。
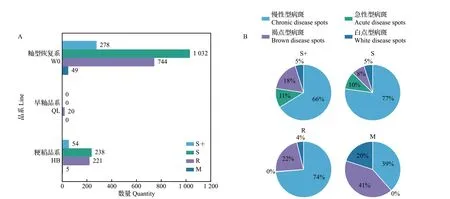
图9 分类数据集中数据分布情况Fig.9 Data distribution in classification dataset
将数据集按照训练集∶验证集∶测试集=8∶1∶1进行划分并用多种分类模型训练,结果如表1 所示。对于本研究所尝试过的分类模型而言,采用基于高斯核的高斯过程支持向量机模型在测试集上进行分类的准确率最高,为94.30%,这也证实了已有的研究对不同分类器性能测试的结果[26-27];其分类结果采用混淆矩阵表示。从图10 中可知:中感型(M)的真阳性率(true positive rate, TPR)大幅低于其他真值,可能的原因是训练集中的中感型(M)区块数量相比于其他类型少,训练样本的缺乏导致模型对于噪声干扰的鲁棒性下降,进而导致对该类抗性的分辨能力下降。高感型(S+)的阳性预测值(positive predictive value, PPV)以及TPR 比除中感型(M)之外的其他类型更低,并且从其他不同类型对高感型(S+)的假阴性率(false negative rate,FNR)和假发现率(false discovery rate,FDR)的贡献率可以估计其干扰主要来自于感病型(S)。从数据集的角度来看,高感型(S+)和感病型(S)品种具有较为相似的病斑数量分布特征。相对于感病型(S)区块,高感型(S+)区块的数量较少,可能存在非均衡训练的情况,进而弱化了用模型提取特征进行分类的能力。

表1 不同分类模型的分类结果Table 1 Classification results of different classification models
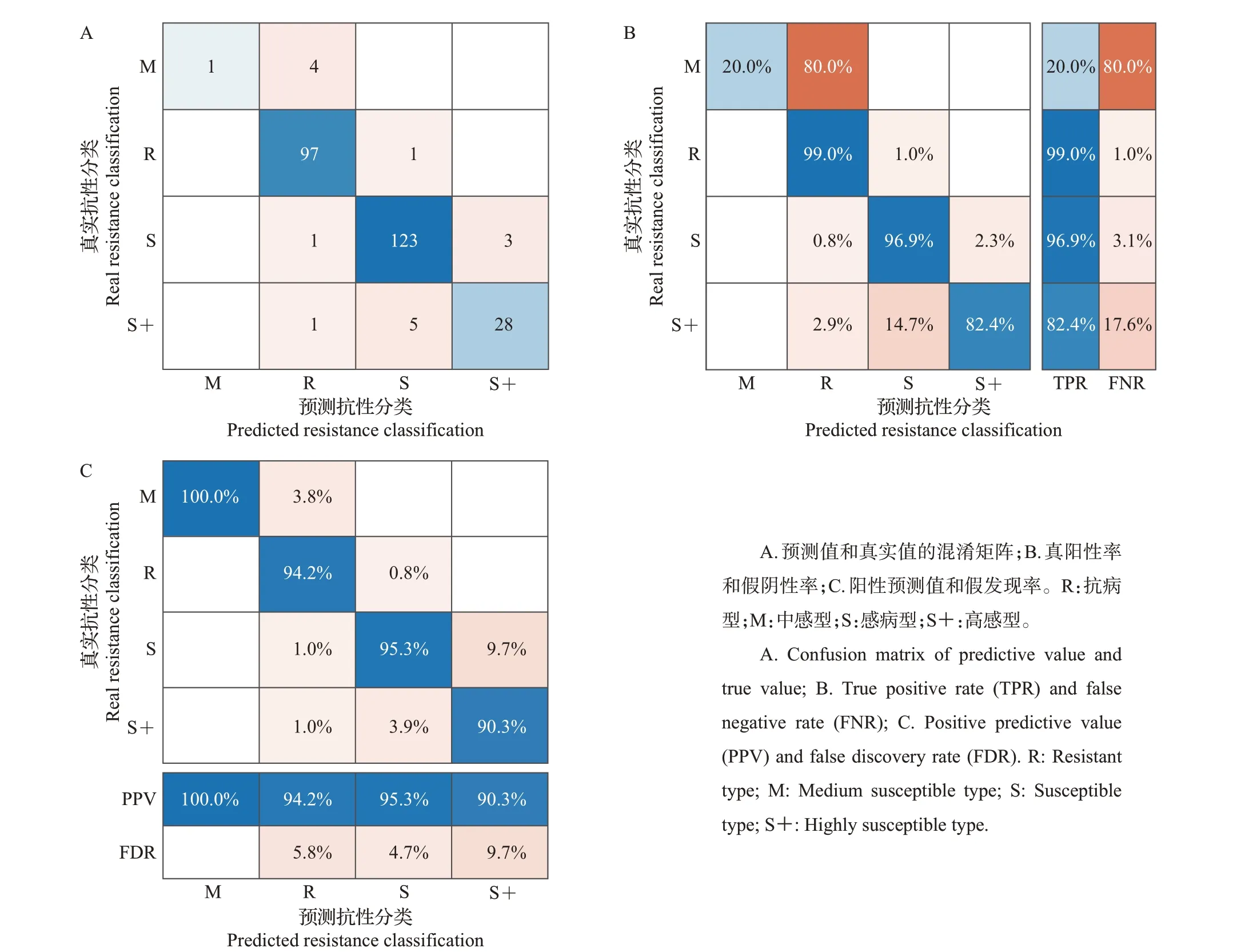
图10 高斯过程支持向量机分类结果混淆矩阵Fig.10 Confusion matrix of Gaussian process support vector machine classification results
从病斑特征角度来看,在自发形成的过程中,慢性型病斑由圆形或椭圆形逐渐变成梭形,两端出现沿叶脉延伸的褐色坏死线,病斑中央变成灰白色,周围出现黄色晕圈(图11),该特征在同类中具有高度的相似性。从图12 中可以看出,预测结果标记的掩膜大小通常小于人工标注掩膜,其主要原因在于存在对病斑的漏检。明显的边界对病斑标注是有利的,在病斑多边形标注的时候更容易将特征捕捉完整,卷积神经网络也将更容易捕捉到此类更加明显的病斑特征,因此,对于慢性型病斑,模型的检测性能要优于其他类型的病斑,如图12A所示的1和2处标记的褐点型病斑的标签掩膜大小和预测掩膜大小存在明显差异。人工标注掩膜和预测结果掩膜分别占图像总像素的比例如图12B 所示。可以看出,病斑越大,通常具有更大的像素占比。而慢性型病斑的人工标注掩膜和训练结果掩膜的差异不显著,可能的原因在于慢性型病斑比褐点型病斑边界更清晰,因此,人工标注的主观差异更小。从病斑数量角度来看,慢性型病斑的绝对数量占比较大,并且R、M 和S/S+的慢性型病斑数量占比差异显著,与其他病斑相比,慢性型病斑会对不同水稻品系抗性水平分类产生更大的影响。

图11 慢性型病斑特征Fig.11 Chronic disease spot features

图12 人工标注和预测结果生成的病斑掩膜对比分析Fig.12 Comparative analysis of spot masks generated by manual annotation and prediction results
3 讨论
上述模型用于冠层尺度的水稻病斑识别分割以及抗性分类的结果依旧存在提升的空间,这反映出冠层尺度的水稻病斑识别分割所面临的问题依旧具有挑战性。其一,冠层尺度水稻叶片之间的部分遮挡会对识别检测造成影响,进而影响病斑的分类和计数。这项工作主要的挑战来自于人工识别的不确定性,即对于不同遮挡情况下的病斑难以准确识别和标记。因此,在数据标注时,对于不存在遮挡的病斑可直接正常标注;对于存在仅有一侧被遮挡的病斑,可以仿照不存在遮挡的病斑进行标注,不必标注被遮挡的部分;对于存在遮挡并被分割成几个单独部分的较大或较为狭长的病斑,应分别标注单独的部分,但是需要标记为相同的实例,以免各个单独的部分被模型理解成不同的病斑实例,如图13中1~2处所示。其二,冠层尺度下背景噪声较为嘈杂,纹理特征复杂程度高,实际数据采集环境中存在较多干扰性因素,例如区块图像采集中的对焦问题,会导致在同一高度下拍摄具有不同高度分布的病斑时,病斑的清晰度差异较大;栽种环境中的水体增加了图像纹理复杂度,高亮的反光可能会导致模型误判,因此,单叶病害的检测方法不具有跨尺度通用性,检测准确度也会有所降低,如图13中3~4处所示。一种有效的办法是扩大数据集规模[28]。基于本研究采用的数据集规模和增强倍数,可以推测在更大规模的数据集上能够获得更好的预测效果。同时,鉴于农业病害数据集还不够规整和丰富,需要构建大型的标准化的农业病害图像数据集,从而为研究农业病害图像提供有价值的数据资源,以便实现农业场景的迁移学习[29]。

图13 冠层尺度水稻病斑识别分割面临的挑战Fig.13 Challenges in recognition and segmentation of rice disease spots at the canopy scale
本研究聚焦于水稻叶瘟的识别检测,未来还可以拓展到其他时期的稻瘟病等的识别检测,例如穗瘟等。其他类型的水稻病害例如立枯病、细条病、纹枯病、穗枯病、秆腐病甚至虫害等具有显症的同样可以加入到数据集中[30]。对于其他禾本科作物如小麦等,可考虑采用迁移学习的方法训练新模型。但需要考虑不同物种的不同特性,以及该特性对于图像的影响,例如不同物种的叶片反射率、冠层结构不同[31],图像的亮度以及镜面反射造成的局部亮斑都有可能对识别检测造成影响。
相对于叶片尺度的病害识别检测,冠层尺度的识别检测具有更加广泛的应用。无论是结合手持式设备进行半自动化的病害识别检测还是结合田间表型机器人进行自动化的病害识别检测,都需要模型能够克服复杂的田间环境的影响而实现准确的病害类型判别和定位[32]。与农业从事者因知识缺乏和肉眼观测带来的不便相比,表型机器人可以利用模型预测的矩形框和掩膜,并结合RGB图像和深度图像之间的映射关系,确定病斑在三维空间中的位置,从而解决植物三维结构中的识别分割问题[33]。或者利用空间位置信息,确定采样位置,结合所搭载的其他传感器获取更加精细化的病害信息,例如获取植株的光谱响应以检测尚处在未显症阶段的稻瘟病[34-35]。
随着目标检测算法的不断更新,模型预测的准确度在不断提升,同时,模型的运行效率也越来越受到关注。一个比较关键的指标是模型检测的实时性。相比于单阶段模型(Yolo、SSD 和RetinaNet等),二阶段模型(RCNN等)在准确性方面更加具有优势,在检测少数类别时也更加可靠,但是需要较低分辨率的图像才能达到实时速度[36]。Mask-RCNN属于后者,本研究对单张水稻病害图像的检测时间在秒级水平,不具备较好的实时性,主要原因在于获取清晰病斑特征的高分辨率图像需求和保证实时性所需的低分辨率图像需求相矛盾。农业场景对于实时性的要求不高,但如果需要应用于特定的场景,则需要考虑模型的选择和架构的优化。
4 结论
本研究采用基于深度学习的实例分割方法对冠层尺度的显症水稻叶瘟病斑的RGB 图像进行病斑类型识别和定位,并将不同类别病斑数量和抗性水平相关联,通过构建多种分类模型进行分析。研究结果表明:1)利用深度学习方法对冠层尺度的水稻叶瘟的快速检测和定位具有可行性,本研究采用Mask-RCNN深度学习模型进行病斑分类和检测的方法,在自构建的基于高清相机和智能手机采集的冠层尺度水稻叶瘟数据集上显示出较好的效果,模型在具有高度复杂的纹理特征的冠层水稻图像中能够准确分割病斑像素并进行分类,平均交并比(mIoU)为0.603。以0.5的交并比(IoU)阈值评估测试集的预测结果,平均准确率均值(mAP)达到0.716。2)苗期水稻叶瘟的抗性水平和不同类别病斑的数量之间具有较高的关联度。本研究构建了在同一区块中不同抗性水平分类和不同类型病斑特征向量之间的关联对,并根据此关联构建了分类数据集。采用基于高斯核的高斯过程支持向量机模型在分类测试集上进行分类的准确率在本研究所尝试的模型中最高,为94.30%。
不同于已有的基于叶片尺度的水稻病害检测研究,本研究采用像素级分类的方法实现了冠层尺度的叶瘟病斑实例分割。当同一图像上出现不同类型的叶瘟病斑的时候,模型能够给出准确的定位及分类。水稻叶瘟抗性水平和病斑数量特征高度相关,根据水稻图像进行苗期稻瘟病抗性鉴定具有可行性。未来拟进一步探讨采用精度更高的识别检测模型以及拓展水稻不同生长阶段的病害数据集,提高模型的泛化能力和迁移能力,并考虑同机器人相结合的场景下的应用。
