基于语义相似的中文数据清洗方法
2021-09-09李碧秋王佳斌刘雪丽
李碧秋,王佳斌,刘雪丽
(华侨大学工学院,泉州 362000)
0 引言
数据清洗是发现并解决数据质量问题的过程,通常包含对相似重复数据、异常数据、不一致数据等的清洗,通过数据清洗提高数据质量,使得企业能够通过数据挖掘与数据分析做出科学判断。针对相似重复数据的清洗可以降低数据库的冗余度,提高数据库的利用率。目前关于相似重复中文文本数据清洗主要包括通过预处理将句子文本这种非结构化数据转化为结构化数据进行处理;基于词语共现度或基于词袋模型的词向量判断文本是否相似;针对不同领域的特点制定相应的清洗算法;考虑中英文的差异,从词语语义角度分析记录的相似性、精确度仍不够理想。可见已有研究对中文数据清洗效率问题、算法普适性及相似性检测的准确度方面还有很大提升空间。所以本文在现有研究基础上提出利用BERT模型改进文本向量化过程,将文本转化为计算机可理解的数学表达,再求可计算的文本之间的余弦相似度,利用K-means和Canopy算法将相似重复文本聚类,实现相似重复数据的清洗。
1 文本向量化
计算机不能直接对自然语言进行计算,所以需要将文本数据转化为向量形式,再对其做数学计算。常用的文本向量化方法包括TF-IDF[1]、Word2Vec模型[2]、GloVe模型[3]、ELMo模型[4]等,但是上述方法缺失文本语义信息、不具有上下文的“语义分析”能力。2018年谷歌AI团队发布的BERT模型[5]在问答任务与语言推理方面展示了骄人的成绩。其亮点在于,与传统双向模型只考虑句子左右两侧的上下文信息不同,BERT还将融合在所有层结构中共同依赖的左右两侧上下文信息。此模型主要基于双向Transformer编码器[6]实现。BERT模型结构如图1所示。
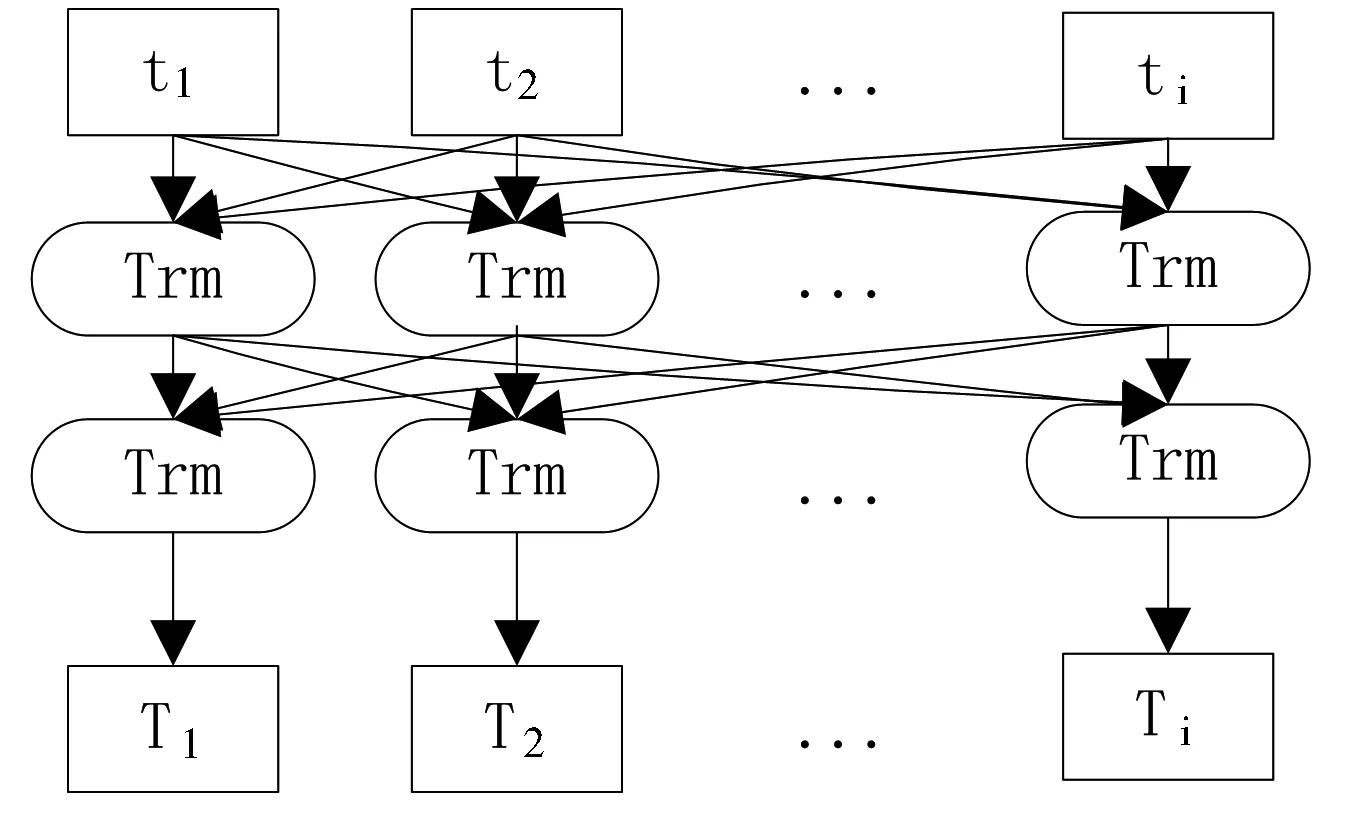
图1 BERT模型结构
t1,t2...ti代表文本输入,T1,T2...Ti代表经过Transformer处理后的文本向量化表示。
BERT主要用了Transformer的Encoder,而没有用其Decoder。Transformer模型中Encoder的结构如图2所示。
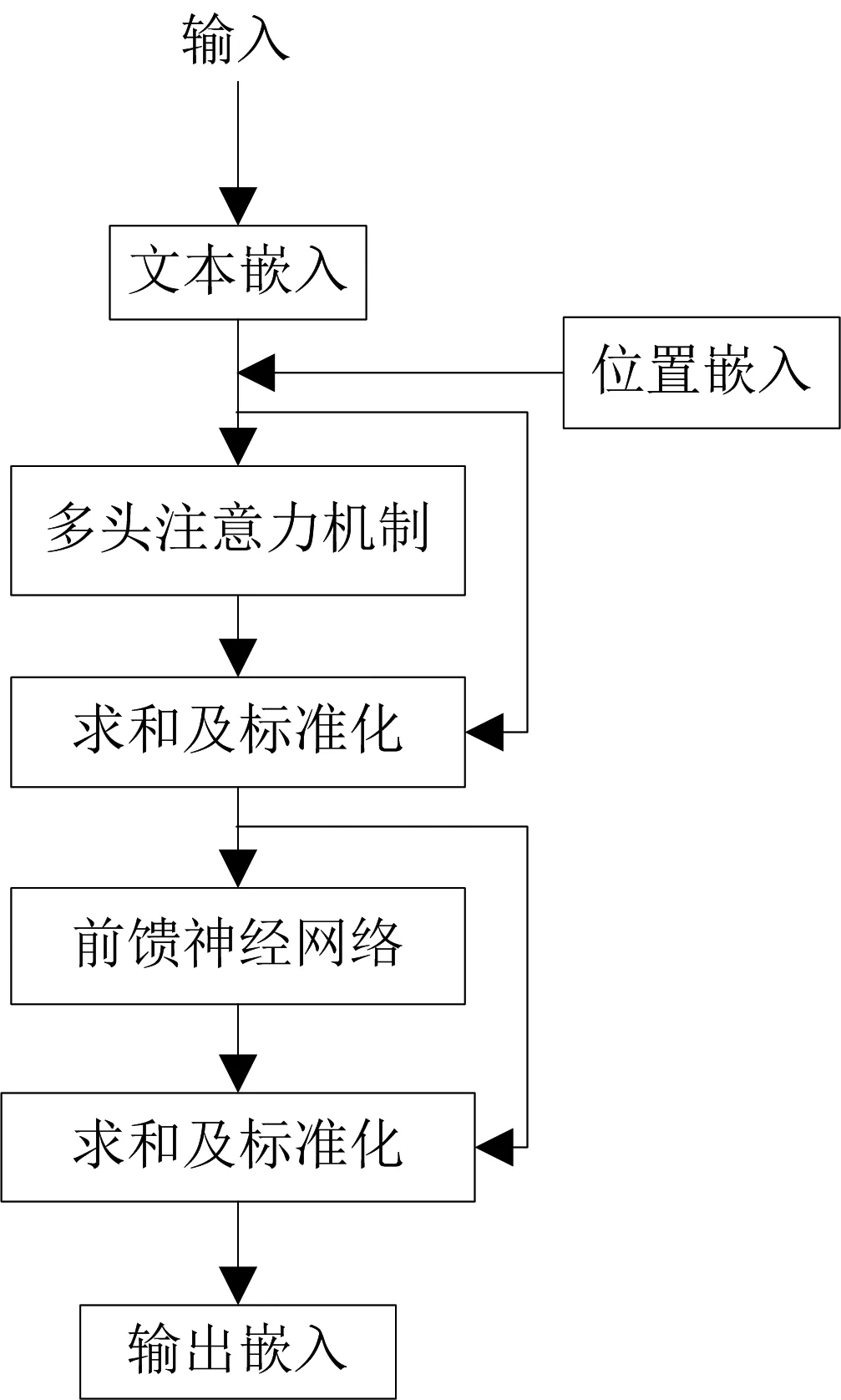
图2 Encoder结构
图2表示了自然语言序列经过计算得到文本的数学表达,Transformer模型没有循环神经网络的迭代操作,而是引入位置信息来识别语言中的顺序关系。
此外,在BERT中提出了两个新的预训练任务Masked LM(Masked Language Model)和Next Sentence Prediction。Masked LM即随机把一句话中15%的token替换成以下内容:
(1)这些token有80%的几率被替换成[mask];
(2)有10%的几率被替换成任意一个其他的token;
(3)有10%的几率原封不动。
在Next Sentence Prediction任务中选择一些句子对S1与S2,其中50%的数据S1与S2是一组有逻辑的句子,剩余50%的数据S2是随机选择的,学习其中的相关性,添加这样的预训练的目的是让模型更好地理解两个句子之间的关系。
基于以上理论,具体的向量化过程为:
Step1:文本预处理,去掉停用词与特殊符号,留下有实际意义的文本;
Step2:将超过512字符的长文本数据的前128个字符与后382个字符相加代替原文本,使其符合BERT可接受的文本序列范围;
Step3:构建字向量、位置向量、文本向量作为BERT模型的输入;
Step4:通过BERT模型中的Transformer编码器融合全文语义信息,得到文本向量。
向量化结果为{词id:向量表示}
部分句子向量化结果如下:
{45466:11.464980125427246,45438:11.46498012
5427246,10419:3.8473434448242188,44612:11.46498
0125427246......7173:10.771833419799805}
2 相似重复数据聚类
经过向量化的文本即可进行余弦相似度的计算。用向量空间中的两个向量夹角的余弦值作为衡量两条记录间的差异大小的度量,余弦值越接近1,就说明向量夹角角度越接近0°,也就是两个向量越相似,就叫做余弦相似。计算方法为:
(1)
聚类算法是指将一堆没有标签的数据自动划分成几类的方法,这个方法要保证同一类数据有相似的特征,所以相似重复文本数据的清洗可以采用聚类的思路。K-means[7]首先随机初始化质心,然后重复执行以下两项操作:①计算每个成员与质心之间的距离,并将其分配给距离最近的质心;②使用每个质心的成员实例的坐标重新计算每个簇的质心坐标,直到类簇中心不再改变(或误差平方和最小或达到指定的迭代次数)。
K-means聚类原理简单,容易实现,聚类效果较优,可解释度较强,整个过程只需调整参数k。该算法简单的同时也带来了一定的麻烦:①人为选取k值不一定能得到理想的结果,不同的k得到的最终聚类结果相差明显,需要反复实验才能找到最佳k值,这样就会浪费大量的精力和时间,并且要求开发人员有相关的经验。②k值选取不当会导致聚类结果的不稳定。所以本文先采用Canopy粗聚类[8]确定聚类中心,获取聚类中心后执行K-means聚类算法,以此避免k值选取的随机性。
3 实验结果分析
本实验数据来自某平台运行过程中产生的日志数据,主要记录了该平台在运行过程中产生的业务流程信息,共317.11万条记录,其中包含了大量的相似重复记录。
分别选择100万、150万、200万、250万、300万条数据作为实验数据,对通过TF-IDF向量化的K-means算法、Canopy+K-means算法与本文提出的基于BERT的Canopy+K-means算法就查准率、查全率、F1值进行对比。
(1)查准率
查准率以预测结果为计算范围,计算方法为预测为重复的记录中实际也为重复的记录与所有预测为重复记录的比值,取值在0到1之间,越接近1,说明聚类正确的命准率越高,效果越好。结果如表1所示。
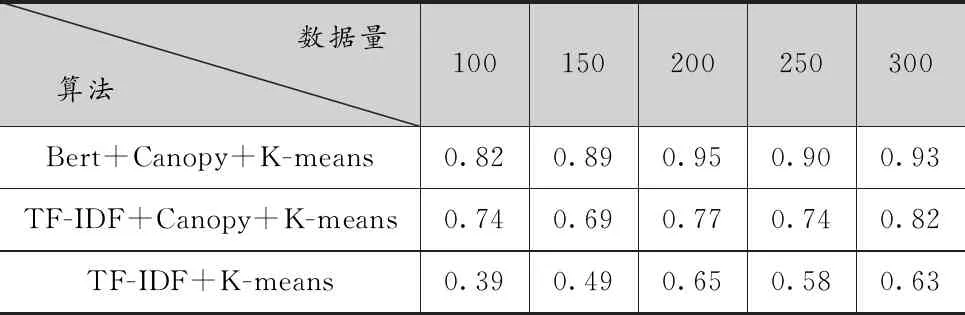
表1 查准率对比
从表1可以看出,经过BERT向量化的聚类结果准确率最高,而传统K-means聚类最差,且效果不太稳定,当k值恰好取到合适的值时,其效果最好,但仍不够理想,虽然经过Canopy大致确定k值,由于向量化不够准确,本不相似的数据被聚到一个类里,导致最终聚类结果排名没达到最优。出现以上结果的原因是,在日常表达中,同一个词在不同语境下代表不同的意思,如“在商店里买了一袋苹果”与“在商店里买了一部苹果手机”,两句话的词语共现度达到了80%,意思却明显不同,第一句话中的“苹果”代表一种水果,第二句话中的“苹果”代表一种手机品牌,按照传统的TF-IDF向量化表示,则将其识别为相似重复数据,而按照BERT模型学习之后,判断这两句话相似度很小,后续聚到不同的类里,准确度有所提升。再如“我比你高”与“你比我高”,两句话的意思完全相反,而按照TF-IDF得到的结果是两句话共同出现的字词达到100%,认为这两句话重复,这显然是错误的。而BERT引入位置信息,得到恰当的向量表达,进而在计算句子间的相似度时更加准确,聚类结果也更加可信。以上结果说明BERT对存在一词多义的文本进行相似性聚类有重要作用。
(2)查全率
查全率以原样本为计算范围,计算方法为:预测为重复的记录中,实际也为重复的记录占样本所有重复记录的比例。取值在0到1之间,越接近1,说明聚类覆盖的越全面。结果如表2所示。
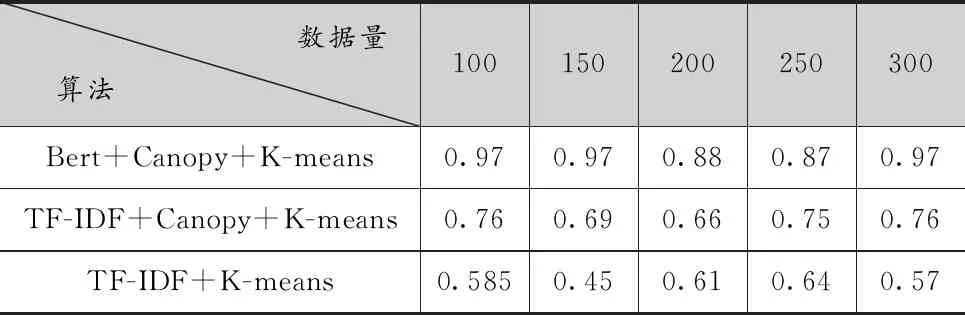
表2 查全率结果对比
从表2可以看出,K-means算法虽然在查准率上波动较大,但是在查全率大致稳定0.6附近,Canopy+K-means较之略有提升,大约在0.7附近,两种方法都未能将所有的相似重复数据聚到一类中。而经过BERT文本向量化处理后的聚类则有优秀的表现,这是因为对于两个文本,采用大量同义词来表达相近的意思时,其词语共现度很小,因此采用传统TF-IDF向量化的K-means聚类难以将全部相似的文本聚类到一起,而经过BERT模型处理后,充分理解句子语义,从而将字面上看似不同的相似文本检测出来并聚到一起。以上结果说明BERT对存在多词一义的文本进行相似性聚类有重要作用。
(3)F1值
查全率与查准率是一对互斥的量,一般不能同时得到最优值,F1值是二者调和平均值,计算公式为:
(2)
F1取值在0到1之间,越接近于1,聚类效果越好。结果如表3所示。
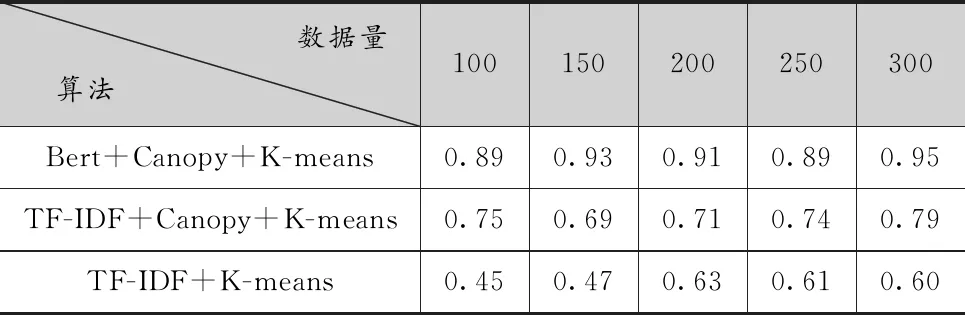
表3 F1值对比
F1值对前两个指标做了一个平衡,从表3可以得知,本文提出的基于BERT的相似重复聚类表现最好,Canopy+K-means次之,传统K-means最差。综上可以看出,中文文本通过BERT模型生成向量后再进行相似聚类能得到更好的清洗效果。
4 结语
本文充分考虑了中文文本存在的不同语境下一词多义与多词一义的情况,引入了BERT语言模型,改进文本向量化过程,使文本的向量化表达更能承载真实的语义信息,从而使后续相似文本聚类更加准确。
