Spectre X RF在大规模RFIC设计中的应用
2021-08-29郭锡韧
郭锡韧 ,曾 义
(1.深圳市中兴微电子技术有限公司,广东 深圳 518055;2.上海楷登电子科技有限公司,上海 200120)
0 引言
随着模拟电路复杂性增大以及工艺尺寸不断减小,寄生规模不断增大。模拟下变频电路是通信链路中的接收机模块的重要电路模块,其中包含的射频前端电路,在设计过程中,代入后仿寄生参数后,还需要进行多次RF 仿真。仿真速度对设计影响较大,另一方面,受限于服务器性能限制,无法满足部分大规模小尺寸模拟射频电路内存需求。
Spectre X RF 仿真器是Cadence 于2020 年推出的新一代仿真器,能提升仿真速度、优化内存,能有效解决目前射频前端RF 仿真中仿真速度过慢、服务器性能需求过高的问题。
在应用Spectre X RF 之前,需对其进行评估,本文在三个主流工艺下,在模拟下变频模块中,对比Spectre APS RF 和Spectre X RF的精度、内存和速度。
1 模拟下变频电路
模拟下变频电路是通信系统中接收机模块中的重要模块,如图1 所示,本文中使用的模拟下变频电路包括射频前端以及后端中频模块,主要包括混频器、放大器、滤波器等结构。

图1 模拟下变频模块结构图
LO 信号为方波信号,在hb 仿真过程中,为了得到符合设计需求的精度,通常需要设置比较大的谐波数,导致速度过慢、内存需求过大。
随着电路性能需求的提升,模拟下变频电路规模不断增大,仿真器的精度和性能需求也随之提升。
OIP3(Output third Intercept Point)为射频电路系统中衡量线性度的重要指标。常规射频系统仿真中,得到OIP3有两种方法:hb+hbac,小信号输入,hbac 使用Rapid IP3模式;hb,LO 信号与双音信号交调。
本文利用OIP3 进行精度分析,在不同工艺中分别使用了两种常用仿真形式中的一种。
2 Spectre X RF
Spectre X RF 仿真器是Cadence 于2020 年推出的新一代仿真器,目的是解决使用Spectre APS 对大寄生射频电路仿真中内存过高、速度慢的问题。理论上与Spectre APS RF 精度相当,速度提高2~3 倍,内存减小。
Spectre X RF的使用模式与Spectre X 一致,对比Spectre APS的使用模式,Spectre X RF/X 更为简单,图2 为其不同模式的简要说明。对于一般的模拟射频电路,Cadence推荐使用Cx/Ax/Mx。本文使用了Cx、Ax、Mx 三种模式,APS RF 相应的模式为Conservatice/Moderate 和+postlayout=hpa/upa。

图2 Spectre X RF 使用模式说明
3 仿真结果
本文对比了TSMC 28 nm、SMIC 14 nm、TSMC 7 nm三种工艺中的Spectre X RF 与Spectre APS RF的速度、内存以及实际需求中性能参数的仿真精度。三种工艺中均使用接收机射频前端,即模拟下变频电路。
3.1 TSMC 28 nm
TSMC 28 nm工艺环境中,仿真使用的电路规模为1.971M N,103k bsim 4,5.616M C,2.573M R。Spectre APS RF 与Spectre X RF 均使用了16 线程。
对TSMC 28 nm工艺的模拟下变频电路做了hb+hbac仿真,hb 仿真中,为满足精度需求,LO 信号的谐波数与过采样因子分别设为15 与2,hbac 使用Rapid IP3 模式。APS+Conservative+UPA 仿真结果如图3 所示。

图3 TSMC 28 nm hbac Rapid IP3 仿真结果
TSMC 28 nm工艺中,Spectre APS RF 与Spectre X RF 仿真性能对比如表1 所示,其中,Spectre APS RF 使用Conservative、Moderate 两种精度,内存优化选择UPA(Ultra Precision Analog)与HPA(High Precision Analog);Spectre X RF使用CX、AX、MX 三种模式。精度为OIP3 相对于Conservative+UPA OIP3 偏差值。

表1 TSMC 28 nm工艺仿真对比
从表中可看出,在TSMC 28 nm工艺中,Spectre X RF 对内存优化不太明显,仅在UPA 内存优化模式中,内存相对较大,运行时间相对较长。具体内存优化与运行时间优化如表5 所示。
以APS RF Conservative+UPA 作为标准,精度最低为Spectre X RF+MX,为98.87%,在射频电路系统中,为可接受的误差值。
以APS RF Conservative+UPA 运行时间为基准,Spectre X RF 整体提速约7 倍,以常用的Convervative+HPA 为基准,整体提速约2 倍多。
3.2 SMIC 14 nm
SMIC 14 nm工艺环境中,仿真使用的电路规模为0.388M N,82k bsimcmg,0.639 M C,1.03 M R。Spectre APS RF 与Spectre X RF 均使用了16 线程。
此工艺中使用了hb LO 信号与双音信号交调方式仿真OIP3,输入信号为频率相差1 MHz的双音信号,LO信号的谐波数与过采样因子为15 与2,双音信号的谐波数与过采样因子均为5 与1,各模式的时域输出波形如图4 所示。

图4 SMIC 14 nm 时域输出波形对比
各模式的频域输出波形如图5 所示。

图5 SMIC 14 nm 频域输出波形对比
SMIC 14 nm工艺中,Spectre APS RF 与Spectre X RF仿真性能对比如表2 所示,各仿真器使用模式与TSMC 28 nm 一致。

表2 SMIC 14 nm工艺仿真对比
在SMIC 14 nm工艺中,Spectre X RF 内存优化不太理想,运行时间有一定的优化,但未达到理论预期。
以Conservative+UPA 作为标准,精度最低为Spectre X RF+MX,为98.40%,在射频电路系统中,为可接受的误差值。
Cadence 研发已经在对该电路进行调查研究。
3.3 TSMC 7 nm
TSMC 7 nm工艺环境中,仿真使用的电路规模为994k N,33k bsource_rhim,50k tmibsimcmg,1.4M C,3.761M R。Spectre APS RF 与Spectre X RF 均使用了16 线程。
此工艺中使用了hb LO 信号与双音信号交调方式仿真OIP3,输入信号为频率相差1 MHz的双音信号,LO信号的谐波数与过采样因子为15 与2。
在仿真前的内存预估过程中,Spectre APS RF 预计使用内存如表3 所示。仿真使用服务器仅有1.4 TB 内存,无法满足内存使用需求。

表3 TSMC 7 nm Spectre APS RF 内存预估
Spectre APS RF 中打开lowmems开关,Conservative+HPA 内存减小至1.2 TB。
Spectre X RF的内存预估在服务器性能范围内,最终使用Spectre X RF 与Spectre APS RF 对电路进行了仿真。图6 与图7 分别为TSMC 7 nm工艺中各仿真模式输出端时域与频域的波形对比。TSMC 7 nm工艺仿真对比如表4 所示。

图6 TSMC 7 nm 时域输出波形对比

图7 TSMC 7 nm 频域输出波形对比
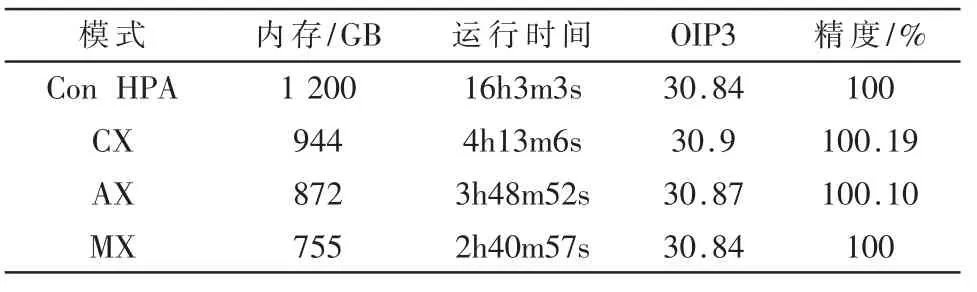
表4 TSMC 7 nm工艺仿真对比
TSMC 7 nm工艺环境中,Spectre X RF 内存优化、运行时间优化均高于预期,对比于降低内存的APS+Conservative+HPA OIP3 精度保持很好,且提速约4 倍,符合实际项目需求。如果Spectre X RF 也打开lowmem options,运行时间和内存使用应当还能进一步降低。
具体内存优化与运行时间优化如表5 所示。
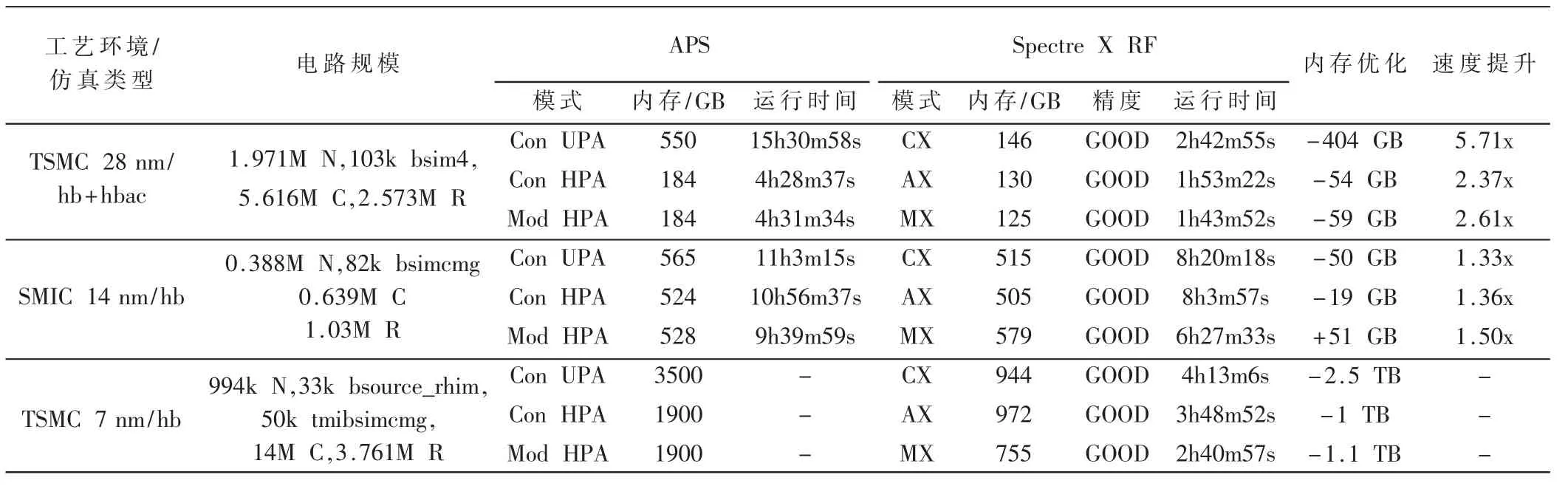
表5 各工艺仿真对比总结
4 结论
Spectre X RF 作为Cadence 推出的新一代RF 仿真器,默认使用方式相比于APS RF,更为简单,从而使得电路工程师能更多的聚焦于电路设计。
应用于本文的模拟下变频电路的仿真中,在TSMC 28 nm、SMIC 14 nm、TSMC 7 nm工艺环境中,内存与运行时间均有一定的优化。在小工艺TSMC 7 nm工艺中,内存与运行时间优化远超预期。
Spectre X RF 还存在改进空间。另外,Spectre X RF支持的distributed HB 分析对大内存需求的multi-tone HB 仿真帮助很大,但因为时间以及其他原因,本文没有进行太多的调查研究。
