二维线性鉴别分析和协同表示的面部识别方法
2021-08-25林克正张玉伦
林克正,邓 旭,张玉伦
(哈尔滨理工大学 计算机科学与技术学院,哈尔滨 150080)
1 引 言
面部识别在生物特征识别技术中占有重要的位置,同时,在实际应用中面部识别技术广泛地应用于交通安全、快捷支付和智能管理等领域内[1,2].然而,面部识别技术仍存在诸多挑战,如:不同光照、不同角度、变化表情和有无遮挡等.因此,如何更好的提取面部图像特征来表示图像成为研究人员研究的热点.
Liu等人提出了基于几何特征图像识别方法[3],该方法提取面部关键器官的位置信息进行识别,如人的眼睛、鼻子等.Gross等人提出基于表象(Appearance-based)的人脸识别方法[4],该方法将面部图像看作一个整体并利用面部的全部信息进行面部识别.主成分分析(Principal Component Analysis,PCA)是基于表象的面部识别方法之一[5],PCA也称为K-L变换,它的主要思想是将面部图像矩阵转换为一维向量.然而,PCA方法可能导致面部图像部分关键特性丢失,并且算法复杂度较高.因此Yang等人提出了二维主成分分析方法(Two-Dimensional Principal Component Analysis,2DPCA)[6].2DPCA方法不需要将图像矩阵转换为一维向量,该方法具有计算简便的显著特点,其计算代价远小于PCA方法.由于,通过2DPCA方法构建协方差矩阵提取的单一特征不能对所得图像都有较好的鲁棒性.因此,本文将通过二维线性鉴别分析方法提取两类特征,将在第2.1部分详细介绍.
此外,近年来提出的稀疏表示(Sparse Representation)方法[7]对于面部识别非常有效.该方法实现的主要思想是假设给定一个测试样本可以由所有类的全体训练样本线性组合来近似表示,进而获取稀疏表示系数,然后计算给定的测试样本和所有类的训练样本之间的残差,即残差最小的类别是该测试样本的类别.Wright等人提出测试样本可以由其同类训练样本线性表示,稀疏表示方法也称为稀疏表示分类(Sparse Representation based Classification,SRC)[8].SRC方法通过l1范数求得的稀疏解具有较好的稀疏性,然而,该方法具有较高的计算代价.为了解决上述这个问题,Zhang等人通过l2范数求稀疏解,l2范数较l1范数求得的稀疏解具有较弱的稀疏性,但在求解时可以大大降低其计算代价,此方法称为协同表示分类(Collaborative Representation based Classification,CRC)[9].本文将利用CRC作为分类器,将在第2.2节详细介绍.
Xu等人通常以得分层融合方法、特征层融合方法和决策层融合方法对两种特征进行融合[10-13].特征层融合方法是将全部生物特征看做一个样本进行识别,然而不同生物特征存在较大的差异影响其识别性能.决策层融合方法是最简单的一种融合方法,但是它的融合效果略差于其它两种融合方法.得分层融合方法[14,15]是将每个特征得出的各自得分(也称为距离)进行融合.因此,本文采用一种加权得分融合机制将类间虚拟图像、类内虚拟图像和原始图像[16-18]分别在CRC上的获得得分并进行融合,将在第2.3节详细介绍.为了验证本文方法的识别性能,分别在ORL、AR、GT不同数据库上进行实验.
本文的主要贡献如下:
1)本文首次提出对二维线性鉴别分析的类间散布矩阵和类内散布矩阵进行特征提取,进而得到两类特征,即类间特征和类内特征.有效缓解了单一特征不能很好地表示图像的问题.
2)本文所提出的类间特征和类内特征与原始图像是互补的.
3)本文采用新颖的加权得分融合机制将原始图像和2)中特征进行融合.
本文其余组织如下:第2部分详细介绍了提出方法;第3部分展示了提出方法的性能;第4部分提供了实验结果;第5部分给出了本文的结论.
2 提出的方法
本章涉及的基本符号如表1所示.

表1 符号表
2.1 类间虚拟图像和类内虚拟图像
本文通过二维线性鉴别分析构建类间散布矩阵和类内散布矩阵,并且分别进行特征提取.定义类间散布矩阵Sb和类内散布矩阵Sw.分别从Sb中求解最优投影向量组u和Sw中求解最优投影向量组v,从而将所有面部图像分别对u和v作投影得到各自的特征向量,具体过程如下:
令样本类别有M个,第j类样本有N个图像:Aj1,Aj2,…,AjN,每幅图像均为m×n的矩阵.定义准则函数J1(x)=uTSbu,当uTSbu取最大时,图像矩阵对向量组u作投影获得特征向量的类别间分散程度最优.uTSbu最大取值问题可以转化为求解Sb中最大g个特征值所对应的特征向量问题.类间散布矩阵Sb可以表示为:
(1)
式中P(wj)表示为第j类的先验概率,一般令P(wj)=1/M.让j表示为第j(1≤j≤M)类样本图像矩阵的均值,表示为所有图像矩阵的均值,具体表现形式如下:
(2)
(3)
令类间散布矩阵Sb的最大g个特征值对应的特征向量为u(u1,u2,…,ug),图像样本A通过特征提取的方式进行图像重构,利用前g个特征向量重构出类间虚拟图像Y1,如公式(4)所示.
Y1=Au=A(u1,u2,…,ug)
(4)
同时,定义准则函数J2(x)=vTSwv,当vTSwv取最大时,图像矩阵对向量组v作投影获得特征向量最优.vTSwv最大取值问题可以转化为求解Sw中最大g个特征值所对应的特征向量问题.定义类内散布矩阵Sw为:
(5)

Y2=Av=A(v1,v2,…,vg)
(6)
2.2 协同表示分类
针对于面部识别中小样本问题,稀疏表示方法是解决这个问题最佳方法之一.稀疏表示方法核心思想是通过给定测试样本y由所有训练样本线性组合表示,并且求出稀疏系数,利用每类训练样本和稀疏系数重构后与所有测试样本进行分类.稀疏表示方法具体过程如下:
假设矩阵Aj表示第j类所有训练样本,样本类别个数为M.记A=[A1,A2,…,AM],A表示全体训练样本组成矩阵.给定一个测试样本y可用所有训练样本线性组合表示,即Aw=y.
一般认为w系数越稀疏,测试样本y的类别越容易判定.稀疏解可由下面公式得到,即:
(7)
式中‖ ‖1表示为l1范数,虽然通过l1范数求解具有较好的稀疏性,但是具有较高算法复杂度.因此通过l2范数求稀疏解,此方法也称为协同稀疏表示分类方法,即:
(8)
(9)
重建误差的具体表现形式如公式(10)所示:
(10)
式中Rj(y)可以认为是一种距离度量,表示测试样本y与第j(1≤j≤M)类训练样本相似性.求出Rj(y)最小的值即为测试样本y的类别(j-1)n+i表示Aj的第(j-1)n+i个元素.
2.3 得分融合与图像分类
根据本文前面介绍的理论,得分融合方法首先独立对待各生物特征,得出各自识别结果后再进行融合,得分融合方法比其它两类融合方法往往能取得较优鉴别性能.
本文采用一种新的加权得分融合方法,融合原始图像、类间虚拟图像和类内虚拟图像各自的得分,并利用最终得分进行分类,具体为:
S=q1R1+q2R2+q3R3
(11)
式中S表示最终的得分,R1表示原始图像利用CRC获取的得分,R2表示类间虚拟图像利用CRC获取的得分,R3表示类内虚拟图像利用CRC获取的得分.q1为R1的权重系数可以表示为:
(12)
q2为R2的权重系数可以表示为:
(13)
q3为R3的权重系数可以表示为q3=1-(q1+q2),使得3个权重系数的总和取值为1.
最后通过公式(14)得出的最终得分进行分类,测试样本y属于第g个个体的类别,即:
g=argminjSj(y)
(14)
3 算法的步骤及性能展示
3.1 算法步骤
根据第2部分的分析和推导,我们以ORL数据集为例,阐述本文方法的主要操作步骤.
步骤1.将ORL数据库分为训练样本集和测试样本集,如:每个类别选取前2-5张作为训练样本,其余作为测试样本.并将训练样本集和测试样本集的面部图像大小统一设置为50*50像素.
步骤2.利用公式(1)-公式(3)构造原始面部图像训练样本集的类间散布矩阵,通过特征提取方式提取相应特征向量,并且利用公式(4)将训练样本集和测试样本集分别向提取出来的特征向量作投影,得到对应训练样本的类间虚拟图像和测试样本的类间虚拟图像.
步骤3.利用公式(2)、公式(5)构造原始面部图像训练样本集的类内散布矩阵,通过特征提取方式提取与之对应的特征向量,并利用公式(6)将训练样本集和测试样本集分别向提取的特征向量作投影,获得对应训练样本的类内虚拟图像和测试样本的类内虚拟图像.
步骤4.利用稀疏解具体表现公式w=(ATA+γI)-1ATy和公式(10)分别获取原始面部图像中测试样本y的得分、类间虚拟图像中测试样本y的得分和类内虚拟图像中测试样本y的得分,其中γ表示一个很小的常量,I表示为单位矩阵.
步骤5.分别获取权重系数q1、q2和q3,并通过公式(11)融合原始图像的得分、类间虚拟图像的得分和类内虚拟图像的得分.
步骤6.通过公式(14)将融合后最终的得分进行面部图像识别.
3.2 算法性能展示
为了让读者更直观的了解本文原理,通过图1展示了本文提出的类间虚拟图像和类内虚拟图像示意图.本文通过2DLDA来提取图像的类间特征和类内特征,通过特征提取的方式重构类间虚拟图像和类内虚拟图像,类间虚拟图像和类内虚拟图像与原始图像是互补的.在图1中,第1行展示了原始图像,第2行展示了类间虚拟图像,第3行展示了类内虚拟图像.

图1 在ORL数据集上的原始图像、类间虚拟图像和类内虚拟图像
通过图2展示了选取不同特征向量个数下对应的识别错误率的直观图.从图2中可以看出,本文提出的方法在选取不同特征向量个数下,识别率的总体趋势是趋于平稳的,具有稳定性.当特征向量个数选为15时,本文方法面部识别错误率最低.

图2 在ORL数据集上选取不同特征向量个数对应的识别错误率
通过图3展示了不同训练样本个数下对应的识别错误率.从图3中可以看出,本文提出的方法有着较低的错误识别率,随着每类训练样本个数的增加,其面部识别错误率越来越低.

图3 在ORL数据集上每个类别训练样本数目对应的识别错误率
4 实验结果
为了进一步测试本文提出方法的性能,在ORL、AR及GT数据库上分别设计了实验.我们设计了协同表示分类方法、快速迭代算法(Fast Iterative Shrinkage Thresholding Algorithm,FISTA)、同伦法(Homotopy Method)和增广拉格朗日乘子法(Primal Augmented Lagrange Multiplier,PALM)来分别作为分类算法.
本章采用识别错误率来比较算法之间性能的好坏,识别错误率越低,算法的性能越好.表2-表4中,“本文方法”表示在ORL、AR和GT面部数据库上的识别精度,具体为将原始图像、类间虚拟图像和类内虚拟图像分别利用CRC进行得分,利用文中公式(11)所示的加权融合机制进行得分融合,并利用最终得分进行面部识别.“类间虚拟图像/类内虚拟图像/原始图像+CRC/FISTA/HOMOTOPY/PALM”分别表示在不同数据集上类间虚拟图像/类内虚拟图像/原始图像在分类算法为CRC/FISTA/HOMOTOPY/PALM上的识别结果;从表2-表4中可以看出,本文提出的方法对于面部图像识别具有较低的识别错误率.

表4 在GT数据集上的错误识别精度
4.1 在ORL面部数据上的实验
本部分将在ORL人脸数据库进行实验.ORL人脸数据库包含了40个人,每个人10幅图像,共400幅人脸图像.每幅人脸图像均在不同的光照、不同的表情变化、不同的角度条件下获得.在ORL人脸数据库中图像包括表情的变化(笑或不笑,睁眼或闭眼)及面部细节.每幅人脸图像分辨率均为50像素×50像素,每幅人脸图像的格式为′.bmp′.图4显示ORL人脸数据库的部分图像.

图4 部分ORL数据集的图像
表2展示了在ORL数据库的识别错误率,每个受试者前2-5幅图像作为训练样本,其余图像作为测试样本.从表2中可以看出,本文方法在ORL数据库上具有较低的错误率.例如:当每类训练样本个数为2-5时,并且分类器选为CRC时,本文方法的识别错误率为14.06%,12.14%,8.33%,8.00%.然而,原始图像利用CRC进行分类时,它的识别错误率为16.25%,14.64%,10.83%,11.00%.由表2可知,当不同训练样本个数由2变化到5时,本文提出的方法也比文献[18]方法(2DPCA+Original images+CRC)、文献[17]方法(FFT+Original images+CRC)和文献[15]中的一般融合方法(Gabor+L1LS)效果要好.
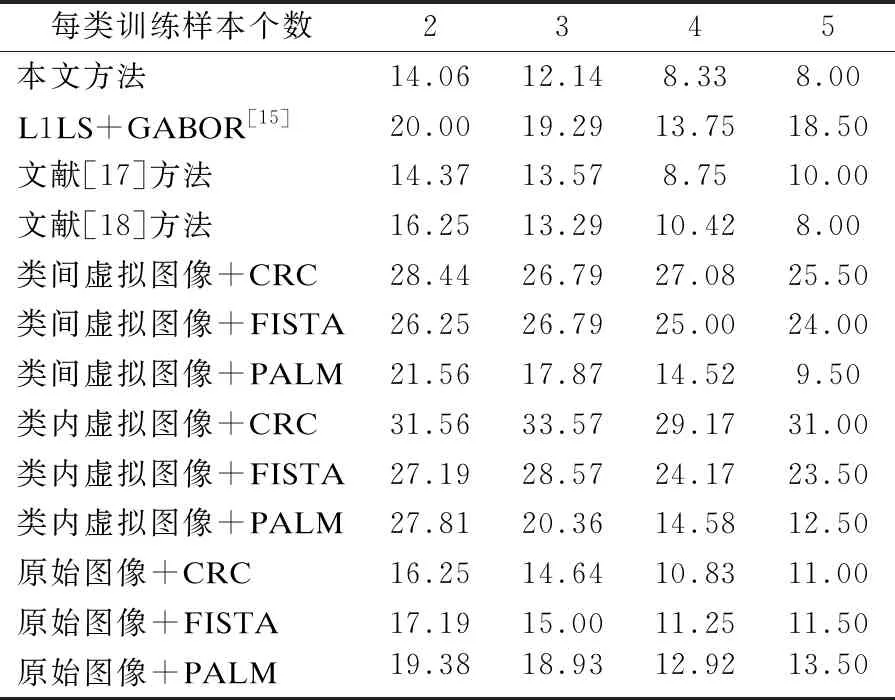
表2 在ORL数据集上的错误识别精度
4.2 在AR面部数据库上的实验
本部分将在AR人脸数据库进行实验.AR人脸数据库中包含了120个人,每个人26幅图像,共3120幅人脸图像.图像在不同光照、不同面部表情、不同角度和有无遮挡物(戴眼镜或围巾)条件下获得.每幅人脸图像的分辨率均为50像素×40像素,每幅人脸图像的格式均为′.tif′.图5显示AR人脸数据库的部分图像.

图5 部分AR数据集的图像
每个受试者前9-12幅图像作为训练样本,其余图像作为测试样本.例如:分类器选为CRC时,本文提出的方法错误率为30.74%,32.76%,23.11%,24.88%.然而,使用FISTA对原始图像进行分类并且每类训练样本个数为9-12时,它的识别错误率为44.95%,47.71%,34.33%,35.89%.由表3可知,当每个训练样本个数由9变化到12时,本文提出的方法在AR数据库上的识别错误率低于原始图像使用FISTA的识别错误率.

表3 在AR数据集上的错误识别精度
4.3 在GT面部数据库上的实验
本部分将在GT人脸数据库进行实验.GT人脸数据库中包含了50个人,每个人15幅彩色图像,共750幅图像.在GT人脸数据库中,每个人的面部细节和面部表情都存在着不同程度的变化.将每幅人脸图像的压缩为50像素×50像素,实验中将这些彩色图像转化为灰度图像.每幅人脸图像的格式均为′.jpg′.图6显示GT人脸数据库的部分图像.

图6 部分GT数据集的图像
在GT数据库中,每个受试者的前9-11幅图像作为训练样本,其余图像作为测试样本.通过表4的实验结果可知,当每类训练样本个数为9-11时并且分类器选为CRC时,本文提出的面部识别方法错误率为28.67%、26.80%、24.00%.文献[17]方法的识别错误率为31.67%、32.00%、27.50%,而文献[18]方法的识别错误率为32.67%、29.60%、29.50%.由表4可知,本文提出的方法与其他经典方法相比具有较低的识别错误率.
5 结束语
本文提出了二维线性鉴别分析和协同表示的面部识别方法.该方法在不同人脸数据库中可以获得较好的识别性能.在实际应用中,该方法具有有效性和可行性,不需要手动调整参数并且易于实现.本文方法可以获取类间虚拟图像和类内虚拟图像来表示原始图像,不仅保留了图像关键特征信息,并且在面部识别方面与原始图像具有一定的互补性,降低了图像识别错误率.通过实验表明,在面部识别中将类间虚拟图像、类内虚拟图像和原始图像的分类结果进行融合可以取得较好的识别效果.
