基于代价敏感学习的遥感影像云检测方法
2021-08-24李乐林
杨 剑,颜 源,李乐林
(1.河南省自然资源厅,河南 郑州 450016;2.武汉大学测绘遥感信息工程国家重点实验室,湖北 武汉 430079;3.测绘遥感信息工程湖南省重点实验室,湖南 湘潭 411201)
遥感卫星在国土资源调查、环境监测等领域具有重要应用价值,但由于地球表面66%以上区域经常被云层覆盖,许多遥感影像都存在云层遮挡问题[1]。为了有效发挥遥感影像在自然资源管理中的作用,为遥感影像后续利用提供可靠的参考,云检测显得至关重要。
目前,影像云检测方法众多,其中应用最多的方法为物理阈值法[2],此类算法快速有效,但由于云种类和特征的复杂性,阈值不好把握,不可避免地会对积雪、建筑物、裸地等高亮目标产生误判[3]。近年来,深度学习理论和技术取得了长足的进步,使得从数据中自动提取多层次和隐含特征成为可能,尤其是深度卷积神经网络,在物体识别、目标检测等视觉任务中取得了重大突破[4-7]。有学者基于深度卷积网络提出了高分辨率遥感影像云检测算法,进行薄云和厚云检测[8]。
云在空间上分布具有不均匀性的特征,有的影像中无云或只有零散分布的云,有的影像中所有地物全部被云覆盖。而现有基于深度卷积网络的云检测算法未考虑云分布的不均匀性问题,若不对训练样本进行调整,将导致样本中云和背景两种类别出现严重不平衡问题,造成检测结果倾向于样本数更多的类别。对于类别不平衡问题,主要有两种处理方式:①对训练数据进行预处理,通过修改训练集的样本分布来降低数据的不平衡程度;②从算法层面进行改进,使之更倾向于少数类数据法[9]。
针对云检测网络训练中样本不平衡问题,本文使用两种手段予以克服。在卷积网络训练阶段,引入代价系数,使得损失函数更多关注小样本的检测精度;在模型选择方面,采用综合了查准率和查全率的F1分数代替总体精度作为卷积网络表现的评价指标。本文方法不仅能有效识别出云,对雪等高亮地物也具有较强的区分能力。
1 方 法
1.1 全卷积网络
遥感影像云检测可认为是云和背景的二类分割问题。全卷积网络(FCN)作为一种像素级分类网络,可用于图像语义分割任务[7]。全卷积神经网络由一系列卷积层、非线性激活层、池化层及上采样层构成。卷积层包含可训练参数,用于从影像中萃取地物特征。非线性激活层置于卷积层之后,用于增加网络的表达能力。池化层可以减少网络参数量和计算量,同时降低过拟合的风险。经过池化层后,特征图的尺寸减小,上采样层或反卷积层[10]用于提高特征图的分辨率,恢复图像尺寸。理论上,全卷积网络可以输出任意尺寸的图像。
1.2 网络架构
采用的网络基于U-Net[11]改进而来,网络架构如图 1所示。U-net具有典型的编码-解码结构[12],在编码阶段,使用卷积层逐步萃取特征并通过池化层逐步降低特征图分辨率,再通过解码过程逐步恢复特征细节和空间位置信息。本文基于U-net主要做了四方面改进:
1)由于仅需识别云和背景两种类别,网络的容量可大幅减少。将所有特征层数减半,减少参数量。
将除输出层外的卷积层后增加批标准化层[13],有利于深度网络的快速收敛,一定程度上起到正则化的效果,减少过拟合的风险等。
由于反卷积层的棋盘效应[14],用上采样层代替反卷积层,上采样方式采用最近邻内插。
对于超出卷积核的特征图(feature map)进行边缘补0,以保证输出特征图与上一层特征图尺寸相同,使得网络可以接受任意尺寸的图像输入。
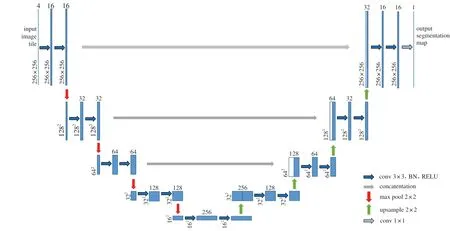
图 1 网络架构
改进后的U-Net网络编码阶段有10个卷积层, 4个池化层,解码阶段有4个上采样层,8个卷积层,卷积核的尺寸均为3×3,最后连接一个1×1尺寸的卷积层作为分类层。
1.3 代价损失函数
代价损失函数是在普通损失函数中引入代价系数,对不同错误使用不同惩罚力度,对我们关注的类别使用更大的代价值,使得错分类的损失函数值更大。本文在交叉熵损失函数[15]中引入代价系数,建立代价损失函数:
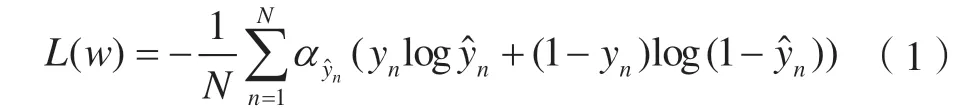
式中,L(w)为损失函数值;w表示卷积网络中待确定的权值;N为输入的样本包含的总像元数;n第n个像元预测为云的概率;yn是第n个像元的真值,yn∈{0,1};0表示背景;1表示云。
αn采用文献[16]方法计算:
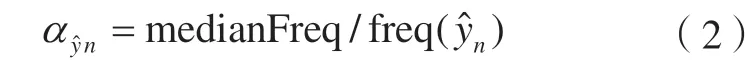
式中,freq(n)是类别n的频率,等于类别为n的像元数量占含类别n的训练样本总像元数量的比例;medianFreq是所有类别频率的中值。
1.4 模型选择
深度学习中广泛使用总体精度作为模型选择的评价指标,但对于云检测,由于样本存在严重类别不平衡问题,若使用总体精度进行模型选择会产生误导性的结果,导致选择的模型对背景识别精度高,而对云识别精度低。为了综合考虑对云的识别能力和对背景的抑制能力,本文使用F1作为性能度量指标,F1是
查准率和查全率的调和平均数。

式中,P和R分别表示查准率和查全率。
1.5 网络训练
采用keras[17]深度学习框架,keras后端使用Tensor Flow[18],显卡为TITAN X(Pascal)GPU,总训练次数设为50。通过在小数据集上反复训练和测试,最终将批量大小设为32,即一次输入32个样本,学习率设为0.001,使用Adam[19]作为求解器。采取早停策略,当验证集上的精度经过5个训练轮数不再上升则停止训练。本实验中,通过20次训练后,验证集上的F1分数值在0.97左右,并不再增加,以此时的网络权值作为最终云检测模型。
2 实验与分析
2.1 数据准备
本实验选取了15幅不同地区和季节的高分一号卫星影像多光谱数据,空间分辨率为8 m,影像尺寸为4 503×4 548,这些数据涵盖了不同下垫面类型,包括雪、冰、水体、植被、裸地、道路、居民区等,其中15幅图像中云含量最大的85%,最小为0。云标记图像通过ENVI软件进行监督分类和后处理获得,云像元标记为1,背景像元标记为0。由于原始影像直接输入网络会导致内存不足,实验中将原始影像裁剪为256×256的影像块,总样本数为4 335幅影像块,按照7∶2∶1比例将样本随机划分为训练集3 034幅、验证集867幅和测试集434幅,验证集用于模型选择,测试集用于精度评估。训练集中云像元数和背景像元数的比例为1∶3.64,验证中云像元数和背景像元数的比例为1∶3.52,测试集中云像元数和背景像元数的比为1∶3.58,训练集、验证集合测试集的样本都存在严重的类别不平衡问题。
2.2 定量评价
为了全面评估模型效果,本文采用的定量评价指标包括F1分数、查准率(P)、查全率(R)、总体精度和kappa系数,使用测试集进行预测并计算各评价指标值(见表 1)。

表 1 不同评价指标值
从表 1可知,该模型总体精度为98%,总体错误率在2%以下,查全率R为0.96,表明模型对云的识别精度高,影像中96%以上的云均可被准确识别,查准率P为0.97,表明背景被误识别为云的比例在3%以下。Kappa系数0.95,表明云检测结果与样本的一致性较高。
2.3 定性评价
使用训练得到的网络模型对3幅无云标记的高分一号多光谱影像进行预测,采用目视解译评价结果。为了全面检验模型抗干扰能力,选取的影像包含雪、冰、水体、植被、裸地、道路、居民区等不同地物类型。由于受GPU内存限制,采用分块预测的方法,将原始影像分为256×256的影像块逐个预测,为避免预测结果出现块状效应,各影像块间保留10%重叠部分,然后将所有块的预测结果拼接起来得到最终预测结果。图 2a采集时间为2015-01-29,无云覆盖,下垫面地物类型主要为植被、居民区。图 3a采集时间为2015-05-01,地物类型主要为雪、水体和冰。图 4a采集时间为2015-02-23,地物覆盖类型主要为雪。
对比云检测结果和其所对应的原始影像,其中图 2a云检测结果为无云,与实际相符。图 3a和图 4a中,云的下垫面有较大区域被积雪覆盖,其中图 3a的左下部分水体被冰雪混合物覆盖,冰雪在色调与亮度上和云极为相似,易被误识别,但从图 3b、 4b的云检测结果来看,冰雪混合物和雪均未被误识别为云,说明该云检测模型对云、雪的区分能力强,有较强抗干 扰性。

图 2 2015-01-29高分一号影像及云检测结果

图 3 2015-05-01高分一号影像及云检测结果

图 4 2015-02-23 高分一号影像及云检测结果
3 结 语
遥感影像云含量对于自然资源管理和利用具有重要的参考价值。本文将代价敏感学习方法应用于遥感影像云检测。通过在损失函数中引入代价系数,较好地克服了云检测任务中,云和背景两种类别不均衡的问题,使用综合了查准率和查全率的F1分数进行模型选择,有助于提高模型对云的识别能力和对冰、雪等高亮地物的区分能力。由于深度卷积网络的网络结构和训练方法都有大量可调节参数,如何确定这些参数还需要进一步研究。
