邻域互信息熵的混合型数据决策代价属性约简
2021-08-24熊菊霞吴尽昭王秋红
熊菊霞,吴尽昭,王秋红
1(中国科学院 成都计算机应用研究所,成都 610041)
2(中国科学院大学 成都计算机应用研究所,北京 100049)
3(广西民族大学 数学与物理学院,南宁 530006)
1 引 言
粗糙集理论是人工智能和智能计算领域的重要研究内容[1].由于现实环境下数据内容的复杂性,学者们将传统的粗糙集理论进行推广,提出了决策粗糙集模型[2],该模型通过引入阈值来限定粗糙集上下近似的范围,使得具有更高的泛化性能.决策粗糙集模型已成为目前粗糙集理论的研究热点[3,4].
属性约简是粗糙集理论的重要应用,在传统的粗糙集理论中,属性约简的目的是为了删除数据集中的不相关属性和冗余属性,使得提高数据的分类性能[5,6].然而在决策粗糙集中,决策区域不满足属性变化的单调性,因此传统的属性约简算法在决策粗糙集下并不适用[7].由于决策粗糙集是建立在代价理论基础上粗糙集模型,Jia等[8]学者在决策粗糙集模型中提出了最小化决策代价的属性约简方法,理论分析了这种属性约简方式的合理性.在Jia的基础上,其他学者进一步地提出了多种推广的属性约简算法,例如Song等[9]学者在模糊数据环境下提出了最小化代价的属性约简算法,彭莉莎等[10]学者提出了面向特定类的最小化代价属性约简,Li等[11]学者将决策粗糙集推广至混合型数据,提出一种邻域决策粗糙集的最小化代价属性约简算法.虽然决策粗糙集不满足属性变化的单调性,但是学者们提出了多种非单调性的属性约简,例如姚晟等[12]学者提出一种决策粗糙集的非单调决策区域的属性约简,Gao等[13]学者提出一种最大决策熵模型,并利用该熵模型去设计属性约简算法.
然而目前的决策粗糙集属性约简算法大多都是基于单独的视角进行属性约简,即决策代价或分类性能,实际应用中可能需要同时考虑多种情形[14],并且目前基于分类性能的属性约简都是直接利用启发式函数进行属性约简结果的搜索,没有考虑所选择属性之间的独立性,使得最终的结果可能包含一些冗余属性,因此也存在一定的缺陷.受这些局限因素的驱使,本文将对联合决策代价和分类性能两方面的属性约简进行探索,并且尽可能减少属性约简结果中的冗余属性.
互信息熵是度量属性之间依赖程度的一种常用方法,并且条件互信息熵也是对属性之间独立性的一种重要评估,是构造属性约简的一种重要方法[15-17].本文在混合型邻域粗糙集模型的基础上,分别提出了邻域信息熵、邻域联合熵和邻域条件熵,然后进一步提出了邻域互信息熵以及邻域条件互信息熵,理论分析了它们之间的关系,然后将邻域互信息熵理论融入邻域决策粗糙集的决策代价属性约简中,提出了基于邻域互信息熵的混合型数据决策代价属性约简算法,该属性约简方法选择出的属性子集可同时兼顾决策代价和分类性能,由于是利用邻域互信息熵去选择属性,使得属性约简结果中的属性具有很高的独立性,仿真实验表明了所提出属性约简算法的优越性.
2 相关理论
设混合型信息系统为S=(U,AT=C∪D),其中论域U={x1,x2,…,xn},xi(1≤i≤n)称为信息系统的对象.条件属性集C={a1,a2,…,am},其中C=Ca∪Cn,Ca和Cn分别称为条件属性集C中的离散型属性子集和连续型属性子集.决策属性D={d}表示信息系统S的类特征,信息系统中的每个对象都有一个唯一的类标记.对于∀x∈U在属性a∈C下的属性值表示为a(x).
定义1[18].设混合型信息系统S=(U,AT=C∪D),属性子集A⊆C并且A=Aa∪An,对于邻域半径δ,由属性子集A确定的邻域关系定义为:
(∀a∈Ac,a(x)=a(y))∧dAn(x,y)≤δ}.



P(D-|δA(x))=1-P(D+|δA(x)).
在邻域决策粗糙集模型中[11],当对象x属于对象集D+时,λPP,λBP和λNP分别表示对象x划分入D+的正区域POS(D+)、边界域BUN(D+)和负区域NEG(D+)所产生的代价;类似地,当对象x不属于对象集D+时,即对象x属于D-,λPN,λBN和λNN分别表示对象x划分入D-的正区域POS(D-)、边界域BUN(D-)和负区域NEG(D-)所产生的代价.
那么对象x∈U采取不同动作的决策代价表示为:
1)CostP(x)=λPP·P(D+|δA(x))+λPN·P(D-|δA(x));
2)CostB(x)=λBP·P(D+|δA(x))+λBN·P(D-|δA(x));
3)CostN(x)=λNP·P(D+|δA(x))+λNN·P(D-|δA(x)).
根据贝叶斯最小化决策代价规则,那么有:
1)当CostP(x)≤CostB(x)且CostP(x)≤CostN(x)时,即P(D+|δA(x))≥α且P(D+|δA(x))≥γ,则x∈POS(D+).
2)当CostB(x)≤CostP(x)且CostB(x)≤CostN(x)时,即P(D+|δA(x))≤α且P(D+|δA(x))≥β,则x∈BUN(D+).
3)当CostN(x)≤CostP(x)且CostN(x)≤CostB(x)时,即P(D+|δA(x))≤β且P(D+|δA(x))≤γ,则x∈NEG(D+).
其中:

1)当P(D+|δA(x))≥α时,那么x∈POS(D+);
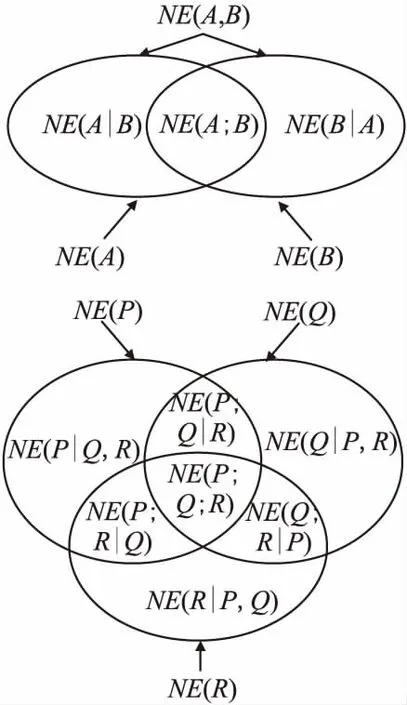
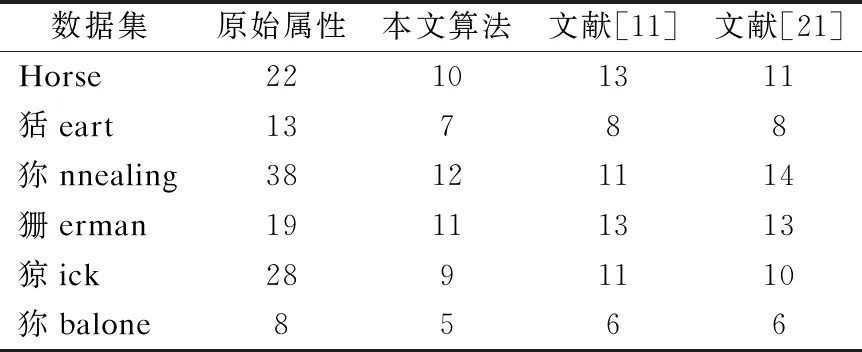
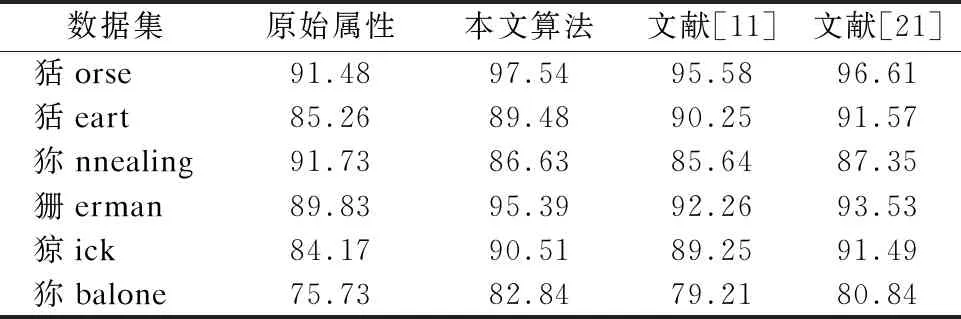
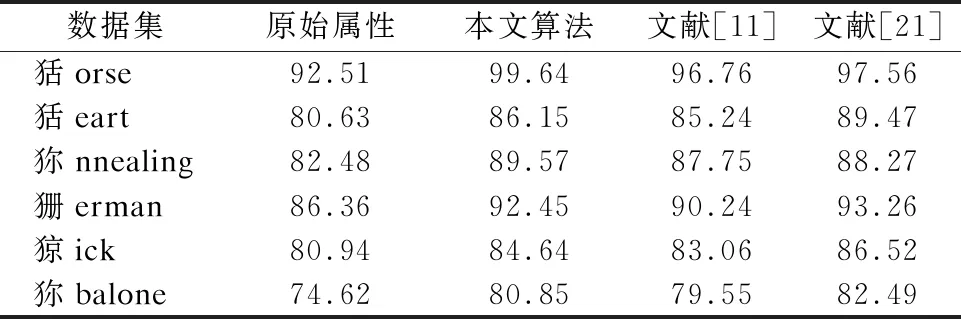
2)当β 3)当P(D+|δA(x))≤β时,那么x∈NEG(D+). 基于上述决策条件,接下来可以得到整个信息系统中所有对象进行决策时所产生的的代价结果. 其中P(x)=P(D+|δA(x));1-P(x)=P(D-|δA(x)). 考虑到正确的决策结果通常不产生任何代价,那么λPP=λNN=0.所以有: 利用定义3所示的决策代价,学者们定义了一种最小化决策代价的属性约简. 定义4[11].设混合型信息系统S=(U,AT=C∪D),邻域半径为δ,若属性子集red⊆C为信息系统S的最小决策代价属性约简,那么当且仅当: 2)∀red′⊂red,Costred′(U)>Costred(U). 在各类经典的粗糙集模型中,其中属性约简大多基于决策区域作为评价准则,即约简结果保持决策区域的大小不变.然而在决策粗糙集中,决策区域的划分是根据对象作出决策的最小代价来确定,因此在决策粗糙集中,基于最小化代价定义属性约简是合理的[11]. Jia等[8]学者提出的最小化代价属性约简只考虑风险,而不考虑条件属性子集对决策属性的分类能力.Yu等[19]学者在最小化代价属性约简中引入了属性重要性,但是这一属性重要度定义只考虑了单个属性对决策的分类能力.然而在一些实际的数据集中,条件属性之间往往存在着很强的相关性,可能存在两个属性,它们都具有较强的分类能力,但结合在一起不能提高分类性能.为了改善这一局限,本节将使用条件互信息熵的来定义属性的重要性. 互信息在含噪声的数据环境中具有良好得鲁棒性.在文献[20]中,Hu等学者将邻域融入信息熵,提出了连续型数据的信息熵模型,本文将该模型在混合型数据下进行推广,提出混合型信息系统下的信息熵以及互信息熵模型. 对于∀x∈U满足{x}⊆δA(x)⊆U,因此邻域信息熵满足0≤NEδ(A)≤logn,其中NEδ(A)=logn当且仅当∀x∈U,δA(x)={x}.其中NEδ(A)=0当且仅当∀x∈U,δA(x)=U. 类似于定义5,邻域联合信息熵同样满足关系0≤NEδ(A,B)≤logn. 定理1.NEδ(B|A)=NEδ(A,B)-NEδ(A). 证明:NEδ(A,B)-NEδ(A)= 定理2.设混合型信息系统为S=(U,AT=C∪D),|U|=n,属性子集A,B⊆C,那么如下等式成立: 1)NEδ(B;A)=NEδ(A;B); 2)NEδ(B;A)=NEδ(A)+NEδ(B)-NEδ(A,B); 3)NEδ(B;A)=NEδ(B)-NEδ(B|A)=NEδ(A)-NEδ(A|B); 证明: 1)根据定义8,即: 2)根据定义5和定义6有: NEδ(A)+NEδ(B)-NEδ(A,B)= 3)根据式(1)和式(2),联合定理1,可以得到式(3)成立. 在邻域互信息熵的基础上,可以进一步推广得到邻域条件互信息熵. 定义9.设混合型信息系统为S=(U,AT=C∪D),|U|=n,属性子集P,Q,R⊆C,那么定义属性集R下P与Q的邻域条件互信息熵为: 定理3.NEδ(P;Q|R)=NEδ(P,R)+NEδ(Q,R)-NEδ(R)-NEδ(P,Q,R); 证明: NEδ(P,R)+NEδ(Q,R)-NEδ(R)-NEδ(P,Q,R)= 图1的两幅图展示出了各类熵之间的相互关系,其中可以看出邻域互信息熵表示了两个属性集之间相互依赖的程度,而邻域条件互信息熵可以反映出其中两个属性之间的独立程度. 图1 各类熵之间的关系示意图 邻域互信息熵可以很好地表达混合型信息系统中两个属性之间的依赖程度,并且具有很高的鲁棒性.因此我们可以通过邻域互信息熵去定义混合型信息系统中条件属性子集与决策属性之间的关联程度,那么在属性约简的搜索过程中,需要选择出依赖程度最大的属性子集,即: maxφ(A,D); φ(A,D)即为属性子集A⊆C中所有属性与决策属性D之间邻域互信息熵的平均值,通过这个平均值来表达属性子集A整体关于决策属性D的依赖程度. 通过邻域互信息熵选择出的属性子集虽然有着较高的依赖程度,但是选择的属性子集中可能存在着冗余属性,即属性子集中的两个属性之间可能存在着依赖关系,删除其中任意一个而不会对最终的依赖度产生影响.因此接下来利用邻域条件互信息熵去评估属性子集中属性之间的独立程度,即选择出的属性子集需满足: maxφ(A,D) 由于NE(aj;D|ai)和NE(ai;D|aj)是通过邻域条件互信息熵来反映属性ai与aj之间的独立程度,即独立程度大小可以表示为: NE(aj;D|ai)+NE(ai;D|aj). 那么对于属性子集A,任意选择其中两个属性进行独立程度的计算,将所有选择结果的独立程度累加起来,来衡量属性子集A的独立性,即: 最后再求取平均值,也就是: 因此φ(A,D)可以度量出属性子集A⊆C中属性之间的平均独立程度,其值越大说明属性子集A中属性之间的相互独立程度越高. 那么对于邻域互信息熵的属性约简,这里希望选择出的属性约简子集A满足: max[φ(A,D)+φ(A,D)]. 利用邻域互信息熵作为属性重要度的评估,这里定义一种属性重要度函数,具体如定义10所示. 定义10.设混合型信息系统为S=(U,AT=C∪D),邻域半径为δ和属性子集A⊆C,属性∀a∈C-A关于属性子集A的邻域互信息熵属性重要度定义为: sig(a,A)=ηδ(A∪{a},D)-ηδ(A,D), 这里的ηδ(A,D)=φ(A,D)+φ(A,D). 传统决策粗糙集下的属性约简主要集中于属性子集的决策代价,而未考虑属性子集的分类能力,因此接下来将本文提出的邻域互信息熵属性重要度引入决策代价属性约简中,提出一种新的改进属性约简算法. 算法1.基于邻域互信息熵的混合型数据决策代价属性约简算法. 输入:混合型信息系统S=(U,AT=C∪D),邻域半径δ,决策代价. 输出:属性约简结果red. 1.初始化red=Ø,ηδ(Ø,D)=0. 2.对于条件属性集中的每个属性ai∈C,其中i=1,2,…,|C|.计算属性ai的邻域互信息熵属性重要度sig(ai,red)=ηδ(red∪{ai},D)-ηδ(red,D), 找出sig(ai,red)最大值对应的属性,记为amax,并且red←red∪{amax}. 3.计算论域U在属性集red下的邻域粒化,并根据定义3得到整个论域U的决策代价Costred(U). 4.对于属性∀a∈C-red,计算其邻域互信息熵的属性重要度sig(a,red),选择C-red中属性重要度最大的属性amax,并且red′←red∪{amax}. 5.计算属性集red′下整个论域U的决策代价Costred′(U),若Costred′(U)≤Costred(U),那么进行red←red′,并且重新返回步骤4,否则进入步骤6. 6.返回属性约简结果red. 算法1所示的是一种启发式方法的属性约简算法,即通过决策代价函数和邻域互信息熵属性重要度一起进行信息系统属性的搜索.该算法主要通过邻域互信息熵去搜索出与决策属性具有较高依赖度的属性,并且选择出的属性与已选择的属性子集具有较高地独立性,当该属性能够进一步降低论域的决策代价时,那么将该属性添加至属性约简集中,重复上述流程直至完成最终的属性搜索.算法1的计算量主要集中在邻域互信息熵的计算和论域决策代价的计算,这些计算主要是针对对象邻域类的计算,因此整个算法1的时间复杂度可表示为O(|C|2·|U|2). 为了进一步验证所提出属性约简算法的有效性,本实验从UCI机器学习公开数据集中选取了6个数据集,具体详情如表1所示,所列举的这些数据集均为离散型属性和连续型属性混合的类型,并且将连续型属性归一化至[0,1]区间.本实验将所提出的属性约简算法与文献[11]的决策代价属性约简算法和文献[21]的邻域粗糙熵属性约简算法分别进行实验,通过属性约简的长度、约简结果的分类精度、约简结果的决策代价以及约简用时4个方面来评价各个算法的优劣. 表1 实验数据集 在本文所提出的算法中,邻域半径δ是一个很重要的参数,其取值的不同将会对最终的实验结果产生很大的影响,本实验借鉴其他学者的处理方式[11,18,21],将邻域半径在一定区间内分别取值进行实验,每个邻域半径都会得到对应的属性约简结果,将该结果利用支持向量机分类器(SVM)和朴素贝叶斯分类器(NB)分别进行分类精度评估,然后对多组数据集的结果进行比较,选取出最佳的邻域半径.图2所示的是邻域半径在区间[0,0.3]下间隔取值得到的分类精度结果.综合各个数据集的结果,可以发现当邻域半径取值为0.12左右时得到的属性约简结果分类精度较高,因此本实验将邻域半径设置为0.12.另外本文的属性约简算法需要确定对象分类的决策代价,本实验这里基于文献[11]的代价关系,在0-1之间随机进行选取. 图2 各个数据集不同邻域半径下属性约简的分类精度结果 表2所示的是本文算法与文献[11]中的算法和文献[21]中的算法在各个数据集下属性约简结果的长度比较.观察表2可以发现本文算法在除数据集Annealing以外有着更小的约简长度,产生这一结果的主要原因是由于本文算法采用邻域互信息熵去搜索属性,每次选择出的属性与决策属性具有很强的相关性,并且与已经搜索到的属性之间也具有很强的独立性,最终得到的属性约简结果包含了较少的冗余和不相关属性,因此得到的约简属性要更少.而其余两种属性约简算法,虽然是基于不同的评价策略去进行属性的搜索,但是均未考虑属性的独立性因素,因此最终的属性约简结果包含了更多的属性. 表2 属性约简的长度比较 表3和表4分别所示的本文算法与对比算法在每个数据集下属性约简结果的SVM分类精度和NB分类精度比较.对比表3和表4的结果,可以发现文献[21]的属性约简算法在数据集Heart、Annealing和Sick下具有较高的SVM分类精度,本文算法和文献[11]算法在其余数据集下具有较高的SVM分类精度;文献[21]的属性约简算法在数据集Heart、German、Sick和Abalone下具有较高的NB分类精度,本文算法在其余数据集下具有较高的NB分类精度.综合比较起来,文献[21]的算法在较多的数据集下具有更高的分类精度,这主要是由于文献[21]的算法利用邻域粗糙信息熵作为启发式函数进行属性搜索,将属性子集的分类性能作为属性约简的重点,因而得到的约简结果分类性能更高,但是本文算法兼顾分类性能的同时,又考虑了属性子集的决策代价,因而分类性能略低于文献[21]的算法,但是本文算法在多数数据集下的分类精度与最高分类精度之间差距不是很大,因此说明本文算法得到的属性约简结果同样具有较高的分类性能. 表3 各个算法属性约简的SVM分类精度比较(%) 表4 各个算法属性约简的NB分类精度比较(%) 表5所示的是本文算法与对比算法在每个数据集下属性约简结果的决策代价比较,对比表3和表4的结果可以发现,文献[11]中的算法在数据集Horse、Heart和German下具有更低的决策代价,本文算法在数据集Annealing、Sick和Abalone下具有更低的决策代价.这主要是由于本文算法和文献[11]的算法都通过考虑属性子集的决策代价进行属性约简,因此本文算法和文献[11]的算法有着较小的决策代价,而文献[21]的邻域粗糙熵属性约简未考虑属性的决策代价,因此得到的属性约简结果具有更高的决策代价. 表5 各个算法属性约简的决策代价比较 属性约简的用时也是衡量算法性能的重要指标,图3所示的是本文算法和对比算法在各个数据集下属性约简的用时比较结果.观察图3可以发现,文献[11]中的属性约简算法有着最多的约简用时,文献[21]中的属性约简算法有着最少的约简用时,本文算法的属性约简用时介于前两种算法之间.这主要是由于计算属性子集的决策代价具有较多的计算量,例如首先需要计算论域在属性子集下的邻域粒化,然后计算每个决策类的正区域、边界域和负区域,最后依据区域的划分计算最终的决策代价结果,而文献[21]的算法只需进行邻域粗糙熵的计算,因此计算量会少一些,而本文算法既进行了决策代价的部分计算也进行了邻域互信息熵的计算,因此计算量介于二者之间. 图3 各个算法属性约简的用时比较 综合比较本文算法与两种对比算法,可以证明本文算法在属性约简的长度、约简结果的分类精度、约简结果的决策代价以及约简用时4个方面上具有整体更优的属性约简性能. 属性约简是粗糙集理论的核心研究内容.传统的决策粗糙集模型通过决策代价的视角进行数据集的属性约简,使得选择出的属性子集在进行决策划分时具有最小的分类代价,然而这种属性约简方法未考虑属性子集的分类性能,并且已有的算法在考虑分类性能的同时,未考虑选择出属性的独立性,因而所得到的属性约简结果具有较高的冗余性,针对这一问题,提出一种基于邻域互信息熵的混合型数据决策代价属性约简算法,该算法在考虑属性约简结果的决策代价同时,利用邻域互信息熵去选择依赖度高且独立性强的属性,使得最终的属性约简结果具有更高的优越性,仿真实验证明了算法的有效性.在接下来的研究中,我们将进一步探索动态混合数据环境下的属性约简问题.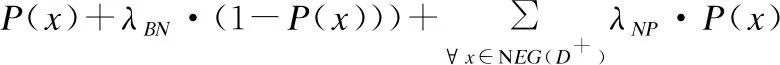
3 混合型信息系统下邻域互信息熵的决策代价属性约简
3.1 邻域互信息熵模型

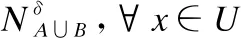
3.2 邻域互信息熵的决策代价属性约简算法

4 实验分析




5 总 结
